Popis a kroky zpracování datového kanálu RAG
V tomto článku se dozvíte o přípravě nestrukturovaných dat pro použití v aplikacích RAG. Nestrukturovaná data odkazují na data bez konkrétní struktury nebo organizace, jako jsou dokumenty PDF, které můžou obsahovat text a obrázky, nebo multimediální obsah, jako je zvuk nebo videa.
Nestrukturovaná data nemají předdefinovaný datový model nebo schéma, což znemožňuje dotazování pouze na základě struktury a metadat. V důsledku toho nestrukturovaná data vyžadují techniky, které dokážou pochopit a extrahovat sémantický význam z nezpracovaného textu, obrázků, zvuku nebo jiného obsahu.
Během přípravy dat přebírá datový kanál aplikace RAG nezpracovaná nestrukturovaná data a transformuje je na diskrétní bloky dat, které je možné dotazovat na základě jejich relevance pro dotaz uživatele. Hlavní kroky předběžného zpracování dat jsou popsané níže. Každý krok má řadu uzlů, které je možné ladit – podrobnější diskuzi o těchto uzlích najdete v tématu Zlepšení kvality aplikace RAG.
Příprava nestrukturovaných dat pro načtení
Ve zbývající části této části popisujeme proces přípravy nestrukturovaných dat pro načtení pomocí sémantického vyhledávání. Sémantické vyhledávání rozumí kontextovým významům a záměru uživatelského dotazu, aby poskytoval relevantnější výsledky hledání.
Sémantické vyhledávání je jedním z několika přístupů, které je možné provést při implementaci komponenty načítání aplikace RAG nad nestrukturovanými daty. Tyto dokumenty se týkají alternativních strategií načítání v části načítání knobs.
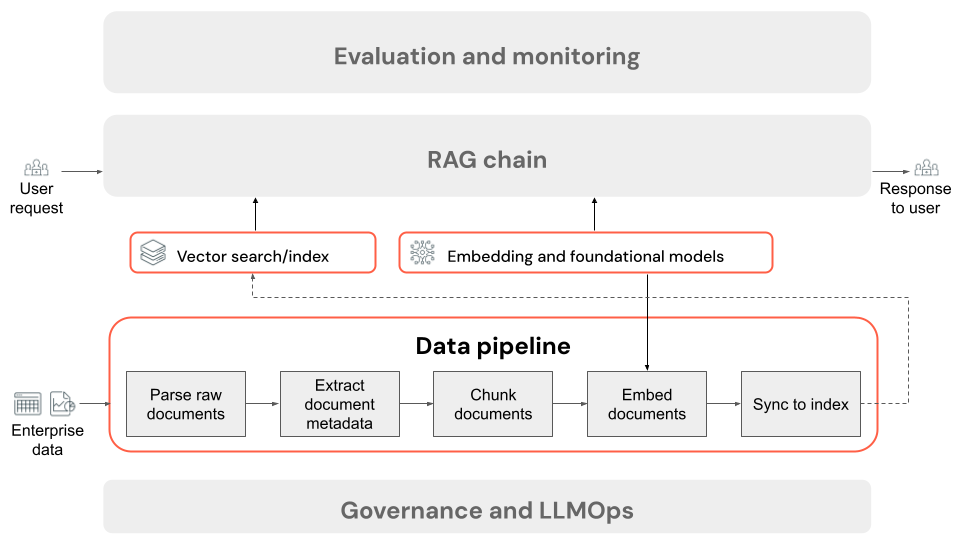
Kroky datového kanálu aplikace RAG
Následuje typický postup datového kanálu v aplikaci RAG, který používá nestrukturovaná data:
- Parsování nezpracovaných dokumentů: Počáteční krok zahrnuje transformaci nezpracovaných dat do použitelného formátu. To může zahrnovat extrakci textu, tabulek a obrázků z kolekce souborů PDF nebo použití technik optického rozpoznávání znaků (OCR) k extrakci textu z obrázků.
- Extrahování metadat dokumentu (volitelné):: V některých případech extrakce a používání metadat dokumentu, jako jsou názvy dokumentů, čísla stránek, adresy URL nebo jiné informace, můžou pomoct s přesnějším dotazováním správných dat.
- Dokumenty bloků dat: Aby se parsované dokumenty vešly do modelu vkládání a kontextového okna LLM, rozdělíme parsované dokumenty do menších samostatných bloků dat. Načtení těchto zaměřených bloků dat, nikoli celých dokumentů, dává LLM cílenější kontext, ze kterého se generují odpovědi.
- Vkládání bloků dat: V aplikaci RAG, která používá sémantické vyhledávání, speciální typ jazykového modelu označovaného jako vložený model transformuje každý blok dat z předchozího kroku na číselné vektory nebo seznamy čísel, které zapouzdřují význam jednotlivých částí obsahu. Zásadní je, že tyto vektory představují sémantický význam textu, nejen klíčová slova na úrovni povrchu. To umožňuje vyhledávání na základě významu, nikoli shody literálů textu.
- Bloky dat indexu v vektorové databázi: Posledním krokem je načtení vektorových reprezentací bloků dat spolu s textem bloku dat do vektorové databáze. Vektorová databáze je specializovaný typ databáze navržený tak, aby efektivně ukládaly a hledaly vektorová data, jako jsou vkládání. Aby se zachoval výkon s velkým počtem bloků dat, vektorové databáze často zahrnují vektorový index, který používá různé algoritmy k uspořádání a mapování vektorových vkládání způsobem, který optimalizuje efektivitu vyhledávání. V době dotazu se požadavek uživatele vloží do vektoru a databáze využívá vektorový index k nalezení nejvíce podobných vektorů bloků dat, které vrací odpovídající původní textové bloky.
Proces výpočetní podobnosti může být výpočetně nákladný. Vektorové indexy, jako je například Databricks Vector Search, urychlují tento proces tím, že poskytují mechanismus pro efektivní uspořádání a navigaci vložených funkcí, často prostřednictvím sofistikovaných metod aproximace. To umožňuje rychlé řazení nejrelevantních výsledků bez porovnání jednotlivých vkládání s dotazem uživatele.
Každý krok v datovém kanálu zahrnuje technická rozhodnutí, která mají vliv na kvalitu aplikace RAG. Například výběr správné velikosti bloku dat v kroku 3 zajistí, že LLM obdrží konkrétní kontextové informace, zatímco výběr vhodného modelu vložení v kroku 4 určuje přesnost bloků dat vrácených během načítání.
Tento proces přípravy dat se označuje jako offline příprava dat, protože probíhá před dotazy na systém, na rozdíl od online kroků aktivovaných při odeslání dotazu uživatelem.