Zlepšení kvality řetězce RAG
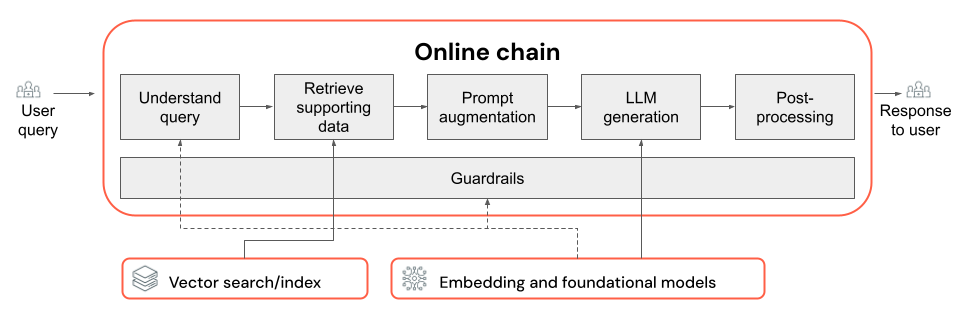
Tento článek popisuje, jak zlepšit kvalitu aplikace RAG pomocí součástí řetězce RAG.
Řetězec RAG přebírá uživatelský dotaz jako vstup, načítá relevantní informace vzhledem k danému dotazu a vygeneruje odpovídající odpověď na základě načtených dat. Přesný postup v řetězci RAG se může lišit v závislosti na případu použití a požadavcích, ale při sestavování řetězce RAG je potřeba vzít v úvahu následující klíčové komponenty:
- Porozumění dotazům: Analýza a transformace uživatelských dotazů za účelem lepší reprezentace záměru a extrakce relevantních informací, jako jsou filtry nebo klíčová slova, za účelem zlepšení procesu načítání.
- Načtení: Vyhledání nejrelevavantnějších bloků informací zadaných dotazem na načtení V případě nestrukturovaných dat to obvykle zahrnuje jednu nebo kombinaci sémantického vyhledávání nebo hledání založeného na klíčových slovech.
- Rozšíření výzvy: Kombinování uživatelského dotazu s načtenými informacemi a pokyny pro vedení LLM k generování vysoce kvalitních odpovědí.
- LLM: Výběr nejvhodnějšího modelu (a parametrů modelu) pro vaši aplikaci za účelem optimalizace/vyvážení výkonu, latence a nákladů.
- Následné zpracování a mantinely: Použití dalších kroků zpracování a bezpečnostních opatření k zajištění toho, aby odpovědi generované LLM byly na téma, fakticky konzistentní a dodržovaly konkrétní pokyny nebo omezení.
Iterativní implementace a vyhodnocení oprav kvality ukazuje, jak iterovat komponenty řetězu.
Principy dotazů
Použití uživatelského dotazu přímo jako vyhledávacího dotazu může u některých dotazů fungovat. Obecně je však užitečné dotaz před krokem načtení přeformátovat. Porozumění dotazům se skládá z kroku (nebo řady kroků) na začátku řetězu pro analýzu a transformaci uživatelských dotazů tak, aby lépe představovaly záměr, extrahovali relevantní informace a nakonec pomohli následnému procesu načítání. Mezi přístupy k transformaci uživatelského dotazu za účelem zlepšení načítání patří:
Přepsání dotazu: Přepsání dotazu zahrnuje překlad uživatelského dotazu do jednoho nebo více dotazů, které lépe představují původní záměr. Cílem je přeformátovat dotaz způsobem, který zvyšuje pravděpodobnost, že krok načítání vyhledá nejrelevavantnější dokumenty. To může být užitečné zejména při práci se složitými nebo nejednoznačnými dotazy, které nemusí přímo odpovídat terminologii použité v dokumentech načítání.
Příklady:
- Parafrázování historie konverzací v chatu s více možnostmi
- Oprava pravopisných chyb v dotazu uživatele
- Nahrazení slov nebo frází v uživatelském dotazu synonymy pro zachycení širšího rozsahu relevantních dokumentů
Důležité
Přepsání dotazu musí být provedeno ve spojení se změnami komponenty načítání.
Extrakce filtrů: V některých případech můžou dotazy uživatelů obsahovat konkrétní filtry nebo kritéria, která lze použít k zúžení výsledků hledání. Extrakce filtrů zahrnuje identifikaci a extrahování těchto filtrů z dotazu a jejich předání do kroku načtení jako další parametry. To může pomoct zlepšit význam načtených dokumentů tím, že se zaměříte na konkrétní podmnožinu dostupných dat.
Příklady:
- Extrahování konkrétních časových období uvedených v dotazu, například "články z posledních 6 měsíců" nebo "sestavy z roku 2023".
- Identifikace zmínek o konkrétních produktech, službách nebo kategoriích v dotazu, například "Databricks Professional Services" nebo "notebooky".
- Extrahování geografických entit z dotazu, jako jsou názvy měst nebo kódy zemí.
Poznámka:
Extrakce filtru musí být provedena ve spojení se změnami datového kanálu extrakce metadat a komponent řetězu retrieveru. Krok extrakce metadat by měl zajistit, aby příslušná pole metadat byla k dispozici pro každý dokument nebo blok dat a že by se měl implementovat krok načítání, aby bylo možné přijmout a použít extrahované filtry.
Kromě přepisování dotazů a extrakce filtrů je dalším důležitým aspektem porozumění dotazům, jestli se má použít jedno volání LLM nebo více volání. Použití jednoho volání s pečlivě vytvořenou výzvou může být efektivní, nicméně existují případy, kdy rozdělení procesu pochopení dotazu do několika volání LLM může vést k lepším výsledkům. To je mimochodem obecně použitelné pravidlo palce, když se pokoušíte implementovat řadu složitých kroků logiky do jediné výzvy.
Můžete například použít jedno volání LLM ke klasifikaci záměru dotazu, jiné k extrakci relevantních entit a třetí k přepsání dotazu na základě extrahovaných informací. I když tento přístup může do celkového procesu přidat určitou latenci, může to umožnit jemněji odstupňované řízení a potenciálně zlepšit kvalitu načtených dokumentů.
Principy vícekrokových dotazů pro robota podpory
Tady je postup, jak může komponenta pro porozumění více krokům hledat robota zákaznické podpory:
- Klasifikace záměru: Pomocí LLM klasifikujte dotaz uživatele do předdefinovaných kategorií, jako jsou "informace o produktu", "řešení potíží" nebo "správa účtů".
- Extrakce entit: Na základě zjištěného záměru použijte další volání LLM k extrakci relevantních entit z dotazu, jako jsou názvy produktů, nahlášené chyby nebo čísla účtů.
- Přepsání dotazu: Pomocí extrahovaného záměru a entit přepište původní dotaz do konkrétnějšího a cílového formátu, například "Můj řetězec RAG se nedaří nasadit ve službě Model Serving, zobrazuje se následující chyba...".
Načtení
Součást načítání řetězce RAG je zodpovědná za nalezení nejrelevavantnějších bloků informací při načtení dotazu. V kontextu nestrukturovaných dat obvykle načtení zahrnuje jednu nebo kombinaci sémantického vyhledávání, vyhledávání založeného na klíčových slovech a filtrování metadat. Volba strategie načítání závisí na konkrétních požadavcích vaší aplikace, povaze dat a typech dotazů, které očekáváte zpracovat. Pojďme porovnat tyto možnosti:
- Sémantické vyhledávání: Sémantické vyhledávání používá vložený model k převodu každého bloku textu na vektorovou reprezentaci, která zachycuje jeho sémantický význam. Porovnáním vektorové reprezentace dotazu načítání s vektorovými reprezentacemi bloků dat může sémantické vyhledávání načíst koncepčně podobné dokumenty, i když neobsahují přesná klíčová slova z dotazu.
- Hledání založené na klíčových slovech: Hledání založené na klíčových slovech určuje význam dokumentů analýzou četnosti a distribuce sdílených slov mezi dotazem načítání a indexovanými dokumenty. Čím častěji se stejná slova zobrazují v dotazu i v dokumentu, tím vyšší je skóre relevance přiřazené danému dokumentu.
- Hybridní vyhledávání: Hybridní vyhledávání kombinuje silné stránky sémantického vyhledávání i vyhledávání založeného na klíčových slovech pomocí dvoustupňového procesu načítání. Nejprve provede sémantické vyhledávání a načte sadu koncepčně relevantních dokumentů. Potom použije vyhledávání založené na klíčových slovech na této omezené sadě, aby se výsledky dále upřesní na základě přesných shod klíčových slov. Nakonec zkombinuje skóre z obou kroků do pořadí dokumentů.
Porovnání strategií načítání
Následující tabulka porovnává každou z těchto strategií načítání mezi sebou:
| Sémantické vyhledávání | Vyhledávání klíčových slov | Hybridní vyhledávání | |
|---|---|---|---|
| Jednoduché vysvětlení | Pokud se v dotazu a potenciálním dokumentu zobrazí stejné koncepty , jsou relevantní. | Pokud se v dotazu a potenciálním dokumentu zobrazí stejná slova , jsou relevantní. Čím více slov z dotazu v dokumentu, tím relevantnější je dokument. | Spustí sémantické vyhledávání a hledání klíčových slov a pak výsledky zkombinuje. |
| Příklad případu použití | Zákaznická podpora, kde se dotazy uživatelů liší od slov v příručkách k produktu. Příklad: "jak můžu zapnout telefon?" a ruční část se nazývá "přepínání napájení". | Zákaznická podpora, kde dotazy obsahují konkrétní, ne popisné technické termíny. Příklad: "co dělá model HD7-8D?" | Dotazy zákaznické podpory, které kombinují sémantické i technické termíny. Příklad: Jak můžu zapnout HD7-8D? |
| Technické přístupy | Používá vkládání k reprezentaci textu v souvislém vektorovém prostoru, což umožňuje sémantické vyhledávání. | Spoléhá na diskrétní metody založené na tokenech, jako jsou bag-of-words, TF-IDF, BM25 pro porovnávání klíčových slov. | Pomocí přístupu k opětovnému řazení zkombinujte výsledky, například reciproční fúzi pořadí nebo model opětovného řazení. |
| Síly | Načítání kontextově podobných informací dotazu, i když se nepoužívají přesná slova. | Scénáře vyžadující přesné shody klíčových slov, ideální pro konkrétní dotazy zaměřené na termíny, jako jsou názvy produktů. | Kombinuje to nejlepší z obou přístupů. |
Způsoby vylepšení procesu načítání
Kromě těchto základních strategií načítání existuje několik technik, které můžete použít k dalšímu vylepšení procesu načítání:
- Rozšíření dotazu: Rozšíření dotazu může pomoct zachytit širší rozsah relevantních dokumentů pomocí více variant načítaného dotazu. Toho lze dosáhnout buď provedením individuálního hledání každého rozšířeného dotazu, nebo pomocí zřetězení všech rozbalených vyhledávacích dotazů v jednom dotazu načítání.
Poznámka:
Rozšíření dotazu musí být provedeno ve spojení se změnami komponenty pro porozumění dotazům (RAG chain). V tomto kroku se obvykle vygenerují různé varianty dotazu načítání.
- Opětovné řazení: Po načtení počáteční sady bloků dat použijte další kritéria řazení (například řazení podle času) nebo model přeřaďte výsledky. Opětovné hodnocení může pomoct určit prioritu nejrelevavantnějších bloků dat zadaných konkrétním vyhledávacím dotazem. Změna pořadí pomocí modelů křížového kodéru, jako je mxbai-rerank a ColBERTv2 , může přinést zvýšení výkonu načítání.
- Filtrování metadat: Pomocí filtrů metadat extrahovaných z kroku porozumění dotazu můžete zúžit vyhledávací prostor na základě konkrétních kritérií. Filtry metadat můžou zahrnovat atributy, jako je typ dokumentu, datum vytvoření, autor nebo značky specifické pro doménu. Kombinováním filtrů metadat s sémantickým vyhledáváním nebo vyhledáváním založeným na klíčových slovech můžete vytvořit cílenější a efektivnější načítání.
Poznámka:
Filtrování metadat se musí provádět ve spojení se změnami komponent pro porozumění dotazům (RAG chain) a extrakci metadat (datový kanál).
Rozšíření výzvy
Rozšíření výzvy je krok, ve kterém se uživatelský dotaz zkombinuje s načtenými informacemi a pokyny v šabloně výzvy, která provede jazykový model směrem k generování vysoce kvalitních odpovědí. Iterování v této šabloně za účelem optimalizace výzvy určené pro LLM (aka výzvy) je nutné k zajištění toho, aby model byl veden k vytvoření přesných, zasazených do kontextu a koherentních odpovědí.
Při iteraci šablony výzvy je potřeba vzít v úvahu celé příručky pro přípravu, ale tady jsou některé aspekty, které je potřeba vzít v úvahu:
- Uveďte příklady
- Uveďte příklady dobře vytvořených dotazů a jejich odpovídajících ideálních odpovědí v samotné šabloně výzvy (několik snímků učení). To pomáhá modelu porozumět požadovanému formátu, stylu a obsahu odpovědí.
- Jedním z užitečných způsobů, jak přijít s dobrými příklady, je identifikovat typy dotazů, se kterými váš řetěz bojuje. Vytvořte pro tyto dotazy zlaté standardní odpovědi a do výzvy je zahrňte jako příklady.
- Ujistěte se, že příklady, které zadáte, představují uživatelské dotazy, které očekáváte při odvozování. Snažte se pokrýt širokou škálu očekávaných dotazů, které modelu pomůžou lépe zobecnit.
- Parametrizace šablony výzvy
- Navrhněte šablonu výzvy tak, aby byla flexibilní tím, že ji parametrizujete tak, aby zahrnovala další informace nad rámec načtených dat a dotazu uživatele. Může se jednat o proměnné, jako jsou aktuální datum, kontext uživatele nebo jiná relevantní metadata.
- Vložení těchto proměnných do příkazového řádku v době odvozování může povolit přizpůsobenější odpovědi nebo odpovědi pracující s kontextem.
- Zvažte možnost řetězení myšlenkových výzev.
- U složitých dotazů, kde nejsou přímé odpovědi snadno zřejmé, zvažte řetězec myšlenek (CoT) jako výzvu. Tato strategie přípravy výzvy rozdělí složité otázky do jednodušších, sekvenčních kroků a provede LLM logickým procesem odůvodnění.
- Po zobrazení výzvy, aby model "krok za krokem promyslel problém", doporučujeme, aby poskytoval podrobnější a dobře zdůvodněné odpovědi, které můžou být zvláště efektivní pro zpracování vícekrokových nebo otevřených dotazů.
- Výzvy se nemusí přenášet mezi modely
- Uvědomte si, že výzvy se často nepřenášejí hladce napříč různými jazykovými modely. Každý model má své vlastní jedinečné vlastnosti, kdy výzva, která dobře funguje pro jeden model, nemusí být tak efektivní pro jiný.
- Experimentujte s různými formáty a délkami výzvy, přečtěte si online příručky (například Kuchařka OpenAI nebo Anthropic cookbook) a připravte se na přizpůsobení a upřesnění výzev při přepínání mezi modely.
LLM
Komponenta generování řetězce RAG převezme rozšířenou šablonu výzvy z předchozího kroku a předá ji do LLM. Při výběru a optimalizaci LLM pro součást generování řetězce RAG zvažte následující faktory, které jsou stejně použitelné pro všechny další kroky, které zahrnují volání LLM:
- Experimentujte s různými modely off-the-police.
- Každý model má své vlastní jedinečné vlastnosti, silné a slabé stránky. Některé modely můžou lépe porozumět určitým doménám nebo lépe provádět konkrétní úlohy.
- Jak už bylo zmíněno dříve, mějte na paměti, že volba modelu může ovlivnit také proces přípravy výzvy, protože různé modely můžou reagovat odlišně na stejné výzvy.
- Pokud je ve vašem řetězu několik kroků, které vyžadují LLM, například volání pro pochopení dotazů kromě kroku generování, zvažte použití různých modelů pro různé kroky. Dražší, obecnější modely můžou být pro úlohy nadměrné, jako je určení záměru uživatelského dotazu.
- Podle potřeby spusťte malé a vertikálně navyšte kapacitu.
- I když může být lákavé okamžitě dosáhnout nejvýkonnějších a nejvýkonnějších dostupných modelů (např. GPT-4, Claude), je často efektivnější začít s menšími a jednoduššími modely.
- V mnoha případech můžou menší opensourcové alternativy, jako je Llama 3 nebo DBRX, poskytovat uspokojivé výsledky s nižšími náklady a rychleji odvozovat. Tyto modely můžou být zvláště účinné pro úlohy, které nevyžadují velmi složité uvažování nebo rozsáhlé světové znalosti.
- Při vývoji a upřesňování řetězce RAG průběžně vyhodnocujte výkon a omezení zvoleného modelu. Pokud zjistíte, že model má potíže s určitými typy dotazů nebo neposkytuje dostatečně podrobné nebo přesné odpovědi, zvažte vertikální navýšení kapacity na model, který je schopnější.
- Sledujte dopad změn modelů na klíčové metriky, jako je kvalita odezvy, latence a náklady, abyste zajistili správnou rovnováhu pro požadavky konkrétního případu použití.
- Optimalizace parametrů modelu
- Experimentujte s různými nastaveními parametrů a najděte optimální rovnováhu mezi kvalitou odezvy, rozmanitostí a soudržností. Například úprava teploty může řídit náhodnost vygenerovaného textu, zatímco max_tokens může omezit délku odpovědi.
- Mějte na paměti, že optimální nastavení parametrů se může lišit v závislosti na konkrétním stylu úkolu, výzvy a požadovaného stylu výstupu. Iterativní testování a upřesnění těchto nastavení na základě vyhodnocení vygenerovaných odpovědí.
- Vyladění specifického úkolu
- Při zpřesnění výkonu zvažte vyladění menších modelů pro konkrétní dílčí úlohy v rámci řetězu RAG, jako je například porozumění dotazům.
- Trénováním specializovaných modelů pro jednotlivé úlohy s řetězem RAG můžete potenciálně zlepšit celkový výkon, snížit latenci a snížit náklady na odvozování v porovnání s použitím jednoho velkého modelu pro všechny úlohy.
- Pokračování v předškolení
- Pokud vaše aplikace RAG pracuje se specializovanou doménou nebo vyžaduje znalosti, které nejsou dobře reprezentované v předem natrénované LLM, zvažte provádění průběžného předběžného trénování (CPT) u dat specifických pro doménu.
- Pokračování předběžného trénování může zlepšit pochopení konkrétní terminologie nebo konceptů, které jsou jedinečné pro vaši doménu. To zase může snížit potřebu rozsáhlého technického inženýrství nebo několika snímků příkladů.
Následné zpracování a mantinely
Jakmile LLM vygeneruje odpověď, je často nutné použít techniky následného zpracování nebo mantinely, aby se zajistilo, že výstup splňuje požadované požadavky na formát, styl a obsah. Tento poslední krok (nebo více kroků) v řetězci může pomoct udržet konzistenci a kvalitu vygenerovaných odpovědí. Pokud implementujete po zpracování a mantinely, zvažte některé z těchto věcí:
- Vynucení výstupního formátu
- V závislosti na vašem případu použití můžete vyžadovat, aby vygenerované odpovědi dodržovaly určitý formát, například strukturovanou šablonu nebo určitý typ souboru (například JSON, HTML, Markdown atd.).
- Pokud se vyžaduje strukturovaný výstup, knihovny jako instruktor nebo osnovy poskytují dobré výchozí body pro implementaci tohoto typu kroku ověření.
- Při vývoji chvíli zajistěte, aby byl krok následného zpracování dostatečně flexibilní, aby zvládl varianty v generovaných odpovědích při zachování požadovaného formátu.
- Zachování konzistence stylu
- Pokud má vaše aplikace RAG specifické pokyny ke stylu nebo požadavky na tón (např. formální vs. neformální, stručné a podrobné), může krok následného zpracování kontrolovat a vynucovat tyto atributy stylu napříč vygenerovanými odpověďmi.
- Filtry obsahu a bezpečnostní mantinely
- V závislosti na povaze vaší aplikace RAG a potenciálních rizicích spojených s vygenerovaným obsahem může být důležité implementovat filtry obsahu nebo bezpečnostní mantinely , aby se zabránilo výstupu nevhodných, urážlivých nebo škodlivých informací.
- Zvažte použití modelů, jako jsou llama Guard nebo rozhraní API speciálně navržená pro kon režim stanu race a bezpečnost, jako je rozhraní API moderování OpenAI, k implementaci bezpečnostních mantinely.
- Zpracování halucinací
- Obrana před halucinacemi je také možné implementovat jako krok následného zpracování. To může zahrnovat křížové odkazování na vygenerovaný výstup s načtenými dokumenty nebo použití dalších LLM k ověření faktické přesnosti odpovědi.
- Vyvíjejte náhradní mechanismy pro zpracování případů, kdy vygenerovaná odpověď nesplňuje požadavky na faktickou přesnost, jako je generování alternativních odpovědí nebo poskytnutí právní omezení pro uživatele.
- Zpracování chyb
- Při jakýchkoli krocích následného zpracování implementujte mechanismy pro řádné řešení případů, kdy krok narazí na problém nebo se nepodaří vygenerovat uspokojivou odpověď. To může zahrnovat vygenerování výchozí odpovědi nebo eskalaci problému k obsluze pro ruční kontrolu.