Tento článek popisuje některé strategie dělení dat v různých úložištích dat Azure. Obecné pokyny k rozdělení dat a osvědčených postupů najdete v tématu Dělení dat.
Dělení služby Azure SQL Database
Jedna databáze SQL má omezení objemu dat, která může obsahovat. Propustnost je omezená faktory architektury a počtem souběžných připojení, která podporuje.
elastické fondy podporují horizontální škálování pro databázi SQL. Pomocí elastických fondů můžete data rozdělit do horizontálních oddílů, které jsou rozložené do více databází SQL. Horizontální oddíly můžete přidávat nebo odebírat také v případě, že se objem dat, která potřebujete zpracovat, zvětšuje a zmenšuje. Elastické fondy také můžou pomoct snížit kolize tím, že zatížení distribuují mezi databáze.
Každý horizontální oddíl se implementuje jako databáze SQL. Horizontální oddíl může obsahovat více než jednu datovou sadu (označovanou jako shardlet). Každá databáze uchovává metadata, která popisují shardlety, které obsahuje. Shardlet může být jedna datová položka nebo skupina položek, které sdílejí stejný klíč shardletu. Například ve víceklientské aplikaci může být klíč shardletu ID tenanta a všechna data pro tenanta se dají uchovávat ve stejném shardletu.
Klientské aplikace zodpovídají za přidružení datové sady k klíči shardletu. Samostatná databáze SQL funguje jako globální správce mapování horizontálních oddílů. Tato databáze obsahuje seznam všech horizontálních oddílů a shardletů v systému. Aplikace se připojí k databázi správce mapování horizontálních oddílů a získá kopii mapy horizontálních oddílů. Mapování horizontálních oddílů ukládá do mezipaměti místně a pomocí mapy směruje žádosti o data do příslušného horizontálního oddílu. Tato funkce je skrytá za řadou rozhraní API obsažených v klientské knihovně Elastic Database, která je k dispozici pro Javu a .NET.
Další informace o elastických fondech najdete v tématu horizontální navýšení kapacity pomocí služby Azure SQL Database.
Pokud chcete snížit latenci a zlepšit dostupnost, můžete replikovat databázi globálního správce mapování horizontálních oddílů. S cenovými úrovněmi Premium můžete nakonfigurovat aktivní geografickou replikaci, která bude průběžně kopírovat data do databází v různých oblastech.
Alternativně můžete použít Synchronizace dat Azure SQL nebo azure Data Factory replikovat databázi správce mapování horizontálních oddílů napříč oblastmi. Tato forma replikace se spouští pravidelně a je vhodnější, pokud se mapa horizontálních oddílů změní zřídka a nevyžaduje úroveň Premium.
Elastic Database poskytuje dvě schémata pro mapování dat na shardlety a jejich ukládání do horizontálních oddílů:
Mapa horizontálních oddílů seznamu přidruží k shardletu jeden klíč. Například ve víceklientské soustavě můžou být data pro každého tenanta přidružená k jedinečnému klíči a uložená ve vlastním shardletu. Aby bylo možné zaručit izolaci, může být každý shardlet uložen v rámci svého vlastního horizontálního oddílu.

Stáhněte si soubor Visia tohoto diagramu.
Mapa horizontálních oddílů přidruží sadu souvislých hodnot klíče k shardletu. Data pro sadu tenantů (každý s vlastním klíčem) můžete například seskupit do stejného shardletu. Toto schéma je levnější než první, protože tenanti sdílejí úložiště dat, ale mají menší izolaci.

Stažení souboru Visia tohoto diagramu
Jeden horizontální oddíl může obsahovat data pro několik shardletů. Pomocí seznamů shardletů můžete například ukládat data pro různé nesouvislé tenanty ve stejném horizontálním oddílu. Můžete také kombinovat rozsahy shardletů a vypsat shardlety ve stejném horizontálním oddílu, i když budou adresovány prostřednictvím různých map. Následující diagram znázorňuje tento přístup:

Stáhněte si soubor Visia tohoto diagramu.
Elastické fondy umožňují přidávat a odebírat horizontální oddíly při zmenšení a růstu objemu dat. Klientské aplikace můžou dynamicky vytvářet a odstraňovat horizontální oddíly a transparentně aktualizovat správce mapování horizontálních oddílů. Odebrání horizontálního oddílu je ale destruktivní operace, která také vyžaduje odstranění všech dat v daném horizontálním oddílu.
Pokud aplikace potřebuje rozdělit horizontální oddíl do dvou samostatných horizontálních oddílů nebo kombinovat horizontální oddíly, použijte nástroj rozdělené sloučení. Tento nástroj běží jako webová služba Azure a migruje data bezpečně mezi horizontálními oddíly.
Schéma dělení může výrazně ovlivnit výkon systému. Může také ovlivnit rychlost přidání nebo odebrání horizontálních oddílů nebo opětovné rozdělení dat napříč horizontálními oddíly. Vezměte v úvahu následující body:
Seskupte data, která se používají společně ve stejném horizontálním oddílu, a vyhněte se operacím, které přistupují k datům z více horizontálních oddílů. Horizontální oddíl je databáze SQL sama o sobě a spojení mezi databázemi se musí provádět na straně klienta.
I když SQL Database nepodporuje spojení mezi databázemi, můžete pomocí nástrojů elastické databáze provádět dotazy s více horizontálními oddíly. Dotaz s více horizontálními oddíly odesílá jednotlivé dotazy do každé databáze a sloučí výsledky.
Nenavrhujte systém, který má závislosti mezi horizontálními oddíly. Omezení referenční integrity, triggery a uložené procedury v jedné databázi nemohou odkazovat na objekty v jiné.
Pokud máte referenční data, která se často používají dotazy, zvažte replikaci těchto dat napříč horizontálními oddíly. Tento přístup může odebrat potřebu spojení dat mezi databázemi. V ideálním případě by taková data měla být statická nebo pomalá, aby se minimalizovala úsilí replikace a snížila pravděpodobnost, že budou zastaralá.
Shardlety, které patří do stejné mapy horizontálních oddílů, by měly mít stejné schéma. Sql Database toto pravidlo nevynucuje, ale správa dat a dotazování se stává velmi složitou, pokud má každý shardlet jiné schéma. Místo toho vytvořte pro každé schéma samostatné mapy horizontálních oddílů. Mějte na paměti, že data patřící různým shardletům se dají uložit do stejného horizontálního oddílu.
Transakční operace jsou podporovány pouze pro data v rámci horizontálního oddílu, nikoli napříč horizontálními oddíly. Transakce mohou zahrnovat shardlety, pokud jsou součástí stejného horizontálního oddílu. Proto pokud vaše obchodní logika potřebuje provádět transakce, buď uložte data do stejného horizontálního oddílu nebo implementujte konečnou konzistenci.
Umístěte horizontální oddíly blízko uživatelům, kteří přistupují k datům v těchto horizontálních oddílech. Tato strategie pomáhá snížit latenci.
Vyhněte se kombinaci vysoce aktivních a relativně neaktivních horizontálních oddílů. Pokuste se rovnoměrně rozložit zatížení napříč horizontálními oddíly. To může vyžadovat hashování klíčů horizontálního dělení. Pokud geograficky lokujete horizontální oddíly, ujistěte se, že se klíče hash mapují na shardlety uložené v horizontálních oddílech uložených blízko uživatelům, kteří k datům přistupují.
Dělení služby Azure Table Storage
Azure Table Storage je úložiště klíč-hodnota, které je navržené pro dělení. Všechny entity jsou uložené v oddílu a oddíly se spravují interně službou Azure Table Storage. Každá entita uložená v tabulce musí obsahovat klíč se dvěma částmi, který zahrnuje:
klíč oddílu. Jedná se o řetězcovou hodnotu, která určuje oddíl, ve kterém azure Table Storage umístí entitu. Všechny entity se stejným klíčem oddílu jsou uložené ve stejném oddílu.
klíč řádku. Jedná se o řetězcovou hodnotu, která identifikuje entitu v rámci oddílu. Všechny entity v rámci oddílu jsou podle tohoto klíče seřazené ve vzestupném pořadí. Kombinace klíče oddílu nebo řádku klíče musí být jedinečná pro každou entitu a nesmí překročit délku 1 kB.
Pokud je entita přidána do tabulky s dříve nepoužitým klíčem oddílu, Azure Table Storage vytvoří pro tuto entitu nový oddíl. Ostatní entity se stejným klíčem oddílu budou uloženy ve stejném oddílu.
Tento mechanismus efektivně implementuje automatickou strategii horizontálního navýšení kapacity. Každý oddíl je uložený na stejném serveru v datacentru Azure, aby se zajistilo, že dotazy, které načítají data z jednoho oddílu, rychle poběží.
Společnost Microsoft publikovala cíle škálovatelnosti pro Azure Storage. Pokud váš systém pravděpodobně překročí tyto limity, zvažte rozdělení entit do více tabulek. Pomocí vertikálního dělení rozdělte pole do skupin, ke kterým se s největší pravděpodobností dostanete společně.
Následující diagram znázorňuje logickou strukturu ukázkového účtu úložiště. Účet úložiště obsahuje tři tabulky: Informace o zákazníci, Informace o produktu a Informace o objednávce.
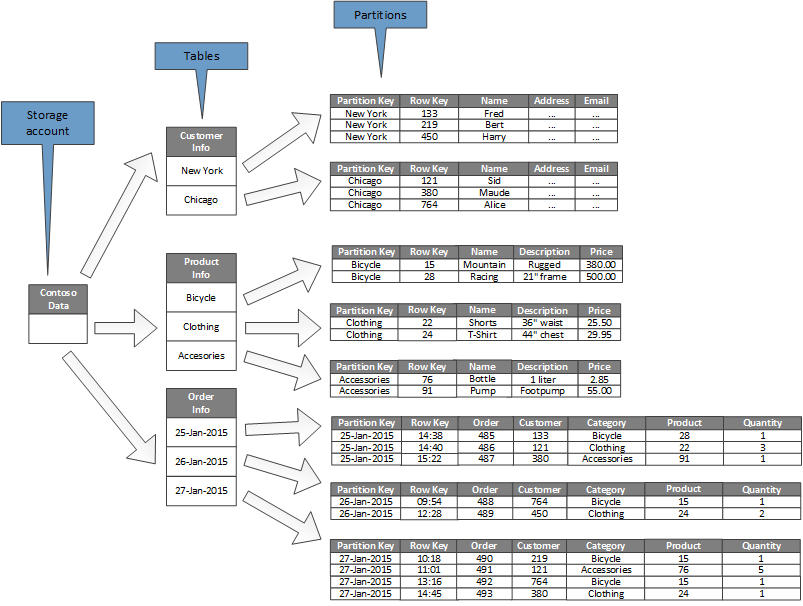
Každá tabulka má více oddílů.
- V tabulce Informace o zákazníci jsou data rozdělena podle města, ve kterém se zákazník nachází. Klíč řádku obsahuje ID zákazníka.
- V tabulce Informace o produktu jsou produkty rozdělené podle kategorie produktu a klíč řádku obsahuje číslo produktu.
- V tabulce Informace o objednávce jsou objednávky rozdělené podle data objednávky a klíč řádku určuje čas přijetí objednávky. Všechna data jsou seřazená podle klíče řádku v každém oddílu.
Při návrhu entit pro Azure Table Storage zvažte následující body:
Vyberte klíč oddílu a klíč řádku tím, jak se k datům přistupuje. Zvolte kombinaci klíče oddílu nebo řádku, která podporuje většinu dotazů. Nejúčinnější dotazy načítají data zadáním klíče oddílu a klíče řádku. Dotazy, které určují klíč oddílu a rozsah klíčů řádků, je možné dokončit prohledáváním jednoho oddílu. To je poměrně rychlé, protože data se uchovávají v pořadí klíčů řádků. Pokud dotazy nespecifikují, který oddíl se má zkontrolovat, musí se zkontrolovat každý oddíl.
Pokud má entita jeden přirozený klíč, použijte ho jako klíč oddílu a jako klíč řádku zadejte prázdný řetězec. Pokud má entita složený klíč skládající se ze dvou vlastností, vyberte nejpomalejší změnu vlastnosti jako klíč oddílu a druhý jako klíč řádku. Pokud má entita více než dvě vlastnosti klíče, pomocí zřetězení vlastností zadejte klíče oddílu a řádku.
Pokud pravidelně provádíte dotazy, které vyhledávají data pomocí jiných polí než klíčů oddílů a řádků, zvažte implementaci vzor tabulky indexunebo zvažte použití jiného úložiště dat, které podporuje indexování, jako je Azure Cosmos DB.
Pokud vygenerujete klíče oddílů pomocí monotónní sekvence (například 0001, 0002, 0003) a každý oddíl obsahuje jenom omezené množství dat, azure Table Storage může tyto oddíly fyzicky seskupit na stejném serveru. Azure Storage předpokládá, že aplikace s největší pravděpodobností provádí dotazy v souvislém rozsahu oddílů (dotazů na rozsah) a je optimalizovaná pro tento případ. Tento přístup však může vést k hotspotům, protože všechny vložení nových entit budou pravděpodobně soustředěny na jednom konci souvislého rozsahu. Může také snížit škálovatelnost. Pokud chcete zatížení rovnoměrněji rozložit, zvažte zatřiďování klíče oddílu.
Azure Table Storage podporuje transakční operace pro entity, které patří do stejného oddílu. Aplikace může provádět více operací vložení, aktualizace, odstranění, nahrazení nebo sloučení jako atomické jednotky, pokud transakce neobsahuje více než 100 entit a datová část požadavku nepřekračuje 4 MB. Operace, které zahrnují více oddílů, nejsou transakční a můžou vyžadovat implementaci konečné konzistence. Další informace o tabulkovém úložišti a transakcích naleznete v tématu Provádění transakcí skupin entit.
Zvažte členitost klíče oddílu:
Použití stejného klíče oddílu pro každou entitu vede k jednomu oddílu, který je uložený na jednom serveru. Tím zabráníte horizontálnímu navýšení kapacity oddílu a zaměříte se na zatížení na jeden server. V důsledku toho je tento přístup vhodný pouze pro ukládání malého počtu entit. Zajišťuje však, aby se všechny entity mohly účastnit transakcí skupin entit.
Použití jedinečného klíče oddílu pro každou entitu způsobí, že služba Table Storage vytvoří pro každou entitu samostatný oddíl, což může mít za následek velký počet malých oddílů. Tento přístup je škálovatelný než použití jednoho klíče oddílu, ale transakce skupin entit nejsou možné. Dotazy, které načítají více než jednu entitu, mohou také zahrnovat čtení z více než jednoho serveru. Pokud ale aplikace provádí dotazy na rozsah, může s optimalizací těchto dotazů pomoct použití monotónní sekvence klíčů oddílů.
Sdílení klíče oddílu mezi podmnožinou entit umožňuje seskupit související entity ve stejném oddílu. Operace zahrnující související entity je možné provádět pomocí transakcí skupiny entit a dotazy, které načítají sadu souvisejících entit, mohou být splněny přístupem k jednomu serveru.
Další informace najdete v průvodci návrhem tabulek Azure Storage a škálovatelnou strategii dělení.
Dělení služby Azure Blob Storage
Azure Blob Storage umožňuje uchovávat velké binární objekty. Objekty blob bloku používejte ve scénářích, kdy potřebujete rychle nahrát nebo stáhnout velké objemy dat. Objekty blob stránky použijte pro aplikace, které vyžadují náhodný přístup místo sériového přístupu k částem dat.
Každý objekt blob (blok nebo stránka) se uchovává v kontejneru v účtu služby Azure Storage. Kontejnery můžete použít k seskupení souvisejících objektů blob, které mají stejné požadavky na zabezpečení. Toto seskupení je logické místo fyzické. V kontejneru má každý objekt blob jedinečný název.
Klíč oddílu objektu blob je název účtu + název kontejneru + název objektu blob. Klíč oddílu slouží k rozdělení dat do rozsahů a tyto rozsahy jsou v systému vyrovnávané zatížením. Objekty blob je možné distribuovat napříč mnoha servery, aby bylo možné škálovat přístup k nim, ale jeden objekt blob může obsluhovat jenom jeden server.
Pokud vaše schéma pojmenování používá časové razítko nebo číselné identifikátory, může vést k nadměrnému provozu do jednoho oddílu, což omezuje systém z efektivního vyrovnávání zatížení. Pokud máte například každodenní operace, které používají objekt blob s časovým razítkem, jako je například yyyy-mm-dd, veškerý provoz pro danou operaci by šel na jeden server oddílů. Místo toho zvažte předponu názvu trojcifernou hodnotou hash. Další informace najdete v tématu Konvence vytváření názvů oddílů .
Akce zápisu jednoho bloku nebo stránky jsou atomické, ale operace, které zahrnují bloky, stránky nebo objekty blob, nejsou. Pokud potřebujete zajistit konzistenci při provádění operací zápisu mezi bloky, stránkami a objekty blob, vynechejte zámek zápisu pomocí zapůjčení objektu blob.
Dělení front Azure Storage
Fronty azure Storage umožňují implementovat asynchronní zasílání zpráv mezi procesy. Účet Azure Storage může obsahovat libovolný počet front a každá fronta může obsahovat libovolný počet zpráv. Jediným omezením je prostor, který je k dispozici v účtu úložiště. Maximální velikost jednotlivých zpráv je 64 kB. Pokud požadujete zprávy větší, zvažte místo toho použití front služby Azure Service Bus.
Každá fronta úložiště má jedinečný název v rámci účtu úložiště, který ho obsahuje. Fronty oddílů Azure na základě názvu. Všechny zprávy pro stejnou frontu jsou uloženy ve stejném oddílu, který je řízen jedním serverem. Různé fronty můžou spravovat různé servery, které pomáhají vyrovnávat zatížení. Přidělování front serverům je pro aplikace a uživatele transparentní.
V rozsáhlé aplikaci nepoužívejte stejnou frontu úložiště pro všechny instance aplikace, protože tento přístup může způsobit, že server, který je hostitelem fronty, se stane horkým místem. Místo toho použijte různé fronty pro různé funkční oblasti aplikace. Fronty Azure Storage nepodporují transakce, takže směrování zpráv do různých front by mělo mít malý vliv na konzistenci zasílání zpráv.
Fronta Azure Storage dokáže zpracovat až 2 000 zpráv za sekundu. Pokud potřebujete zpracovávat zprávy větším tempem, zvažte vytvoření více front. Například v globální aplikaci vytvořte samostatné fronty úložiště v samostatných účtech úložiště pro zpracování instancí aplikací spuštěných v jednotlivých oblastech.
Dělení služby Azure Service Bus
Azure Service Bus používá zprostředkovatele zpráv ke zpracování zpráv odesílaných do fronty nebo tématu služby Service Bus. Ve výchozím nastavení se všechny zprávy odesílané do fronty nebo tématu zpracovávají stejným procesem zprostředkovatele zpráv. Tato architektura může omezit celkovou propustnost fronty zpráv. Frontu nebo téma ale můžete také rozdělit do oddílů při jeho vytvoření. Provedete to nastavením vlastnosti EnablePartitioning popisu fronty nebo tématu tak, aby true.
Dělená fronta nebo téma je rozdělena do několika fragmentů, z nichž každá je založená na samostatném úložišti zpráv a zprostředkovateli zpráv. Service Bus zodpovídá za vytváření a správu těchto fragmentů. Když aplikace publikuje zprávu do dělené fronty nebo tématu, Service Bus přiřadí zprávu fragmentu této fronty nebo tématu. Když aplikace obdrží zprávu z fronty nebo odběru, Service Bus zkontroluje všechny fragmenty další dostupné zprávy a pak ji předá aplikaci ke zpracování.
Tato struktura pomáhá distribuovat zatížení mezi zprostředkovatele zpráv a úložiště zpráv, což zvyšuje škálovatelnost a zlepšuje dostupnost. Pokud je zprostředkovatel zpráv nebo úložiště zpráv pro jeden fragment dočasně nedostupné, může Service Bus načíst zprávy z jednoho ze zbývajících dostupných fragmentů.
Service Bus přiřadí fragmentu zprávu následujícím způsobem:
Pokud zpráva patří do relace, všechny zprávy se stejnou hodnotou pro SessionId vlastnost se odešlou do stejného fragmentu.
Pokud zpráva nepatří do relace, ale odesílatel zadal hodnotu pro PartitionKey vlastnost, všechny zprávy se stejným PartitionKey se odešlou do stejného fragmentu.
Poznámka:
Pokud jsou SessionId a PartitionKey vlastnosti zadány, musí být nastaveny na stejnou hodnotu nebo zpráva bude odmítnuta.
Pokud nejsou zadány vlastnosti SessionId a PartitionKey zprávy, ale je povoleno vyhledávání duplicit, použije se vlastnost MessageId. Všechny zprávy se stejným MessageId budou směrovány do stejného fragmentu.
Pokud zprávy neobsahují vlastnost SessionId, PartitionKey, nebo MessageId, pak Service Bus postupně přiřazuje zprávy fragmentům. Pokud je fragment nedostupný, služba Service Bus přejde na další. To znamená, že dočasná chyba v infrastruktuře zasílání zpráv nezpůsobí selhání operace odesílání zpráv.
Při rozhodování, jestli nebo jak rozdělit frontu zpráv nebo téma služby Service Bus, zvažte následující body:
Fronty a témata služby Service Bus se vytvářejí v oboru názvů služby Service Bus. Service Bus v současné době umožňuje až 100 dělených front nebo témat na obor názvů.
Každý obor názvů služby Service Bus ukládá kvóty dostupných prostředků, jako je počet odběrů na téma, počet souběžných požadavků na odesílání a přijímání za sekundu a maximální počet souběžných připojení, která je možné navázat. Tyto kvóty jsou popsané v kvótách služby Service Bus. Pokud očekáváte, že tyto hodnoty překročíte, vytvořte další obory názvů s vlastními frontami a tématy a rozdělte práci mezi tyto obory názvů. Například v globální aplikaci vytvořte samostatné obory názvů v každé oblasti a nakonfigurujte instance aplikace tak, aby používaly fronty a témata v nejbližším oboru názvů.
Zprávy odeslané v rámci transakce musí určovat klíč oddílu. Může to být Id relace, PartitionKeynebo vlastnost MessageId. Všechny zprávy odeslané jako součást stejné transakce musí zadat stejný klíč oddílu, protože musí být zpracovány stejným procesem zprostředkovatele zpráv. Zprávy nelze odesílat do různých front nebo témat ve stejné transakci.
Dělené fronty a témata nelze nakonfigurovat tak, aby se automaticky odstranily, když se stanou nečinnými.
Dělené fronty a témata se momentálně nedají používat s protokolem AMQP (Advanced Message Queuing Protocol), pokud vytváříte multiplatformní nebo hybridní řešení.
Dělení služby Azure Cosmos DB
azure Cosmos DB for NoSQL je databáze NoSQL pro ukládání dokumentů JSON. Dokument v databázi Azure Cosmos DB je serializovaná reprezentace objektu nebo jiné části dat ve formátu JSON. Žádná pevná schémata se nevynucují s tím rozdílem, že každý dokument musí obsahovat jedinečné ID.
Dokumenty jsou uspořádané do kolekcí. Související dokumenty můžete seskupit do kolekce. Například v systému, který udržuje blogové příspěvky, můžete obsah každého blogového příspěvku uložit jako dokument v kolekci. Můžete také vytvořit kolekce pro každý typ předmětu. Alternativně můžete ve víceklientských aplikacích, jako je systém, ve kterém různí autoři řídí a spravují vlastní blogové příspěvky, rozdělit blogy podle autora a vytvořit samostatné kolekce pro každého autora. Prostor úložiště přidělený kolekcím je elastický a podle potřeby se může zmenšit nebo zvětšit.
Azure Cosmos DB podporuje automatické dělení dat na základě klíče oddílu definovaného aplikací. logický oddíl je oddíl, který ukládá všechna data pro jednu hodnotu klíče oddílu. Všechny dokumenty, které sdílejí stejnou hodnotu klíče oddílu, se umístí do stejného logického oddílu. Azure Cosmos DB distribuuje hodnoty podle hodnoty hash klíče oddílu. Logický oddíl má maximální velikost 20 GB. Proto je volba klíče oddílu důležitým rozhodnutím v době návrhu. Zvolte vlastnost s širokou škálou hodnot a dokonce i přístupovými vzory. Další informace najdete v tématu Dělení a škálování ve službě Azure Cosmos DB.
Poznámka:
Každá databáze Azure Cosmos DB má úroveň výkonu, která určuje množství prostředků, které získá. Úroveň výkonu je přidružená k jednotce žádosti (RU) limitu rychlosti. Limit rychlosti RU určuje objem prostředků, které jsou rezervované a dostupné pro výhradní použití v dané kolekci. Náklady na kolekci závisí na úrovni výkonu vybrané pro danou kolekci. Čím vyšší je úroveň výkonu (a limit rychlosti RU), tím vyšší je poplatek. Úroveň výkonu kolekce můžete upravit pomocí webu Azure Portal. Další informace najdete v tématu jednotky žádostí ve službě Azure Cosmos DB.
Pokud mechanismus dělení, který služba Azure Cosmos DB poskytuje, nestačí, možná budete muset data horizontálně rozdělit na úrovni aplikace. Kolekce dokumentů poskytují přirozený mechanismus pro dělení dat v rámci jedné databáze. Nejjednodušší způsob, jak implementovat horizontální dělení, je vytvořit kolekci pro každý horizontální oddíl. Kontejnery jsou logické prostředky a mohou zahrnovat jeden nebo více serverů. Kontejnery s pevnou velikostí mají maximální limit 20 GB a propustnost 10 000 RU/s. Neomezené kontejnery nemají maximální velikost úložiště, ale musí zadat klíč oddílu. Při horizontálním dělení aplikace musí klientská aplikace směrovat požadavky na příslušný horizontální oddíl, obvykle implementací vlastního mechanismu mapování na základě některých atributů dat, které definují klíč horizontálního dělení.
Všechny databáze se vytvářejí v kontextu účtu databáze Azure Cosmos DB. Jeden účet může obsahovat několik databází a určuje, ve kterých oblastech se databáze vytvářejí. Každý účet také vynucuje vlastní řízení přístupu. Účty Služby Azure Cosmos DB můžete použít k geografickému vyhledání horizontálních oddílů (kolekcí v databázích) blízko uživatelů, kteří k nim potřebují přístup, a vynutit omezení, aby se k nim mohli připojit jenom tito uživatelé.
Při rozhodování o tom, jak rozdělit data pomocí služby Azure Cosmos DB for NoSQL, zvažte následující body:
Prostředky dostupné pro databázi Azure Cosmos DB podléhají omezením kvóty účtu. Každá databáze může obsahovat řadu kolekcí a každá kolekce je přidružená k úrovni výkonu, která řídí limit rychlosti RU (vyhrazenou propustnost) pro danou kolekci. Další informace najdete v tématu limity, kvóty a omezení předplatného a služeb Azure.
Každý dokument musí mít atribut, který lze použít k jedinečné identifikaci daného dokumentu v kolekci, ve které je uložen. Tento atribut se liší od klíče horizontálního dělení, který definuje, která kolekce obsahuje dokument. Kolekce může obsahovat velký počet dokumentů. Teoreticky je omezena pouze maximální délkou ID dokumentu. ID dokumentu může být až 255 znaků.
Všechny operace s dokumentem se provádějí v kontextu transakce. Transakce jsou vymezeny na kolekci, ve které je dokument obsažen. Pokud se operace nezdaří, práce, kterou provedl, se vrátí zpět. Zatímco dokument podléhá nějaké operaci, všechny provedené změny podléhají izolaci na úrovni snímku. Tento mechanismus zaručuje, že pokud například požadavek na vytvoření nového dokumentu selže, jiný uživatel, který dotazuje databázi současně, neuvidí částečný dokument, který se pak odebere.
Databázové dotazy jsou také vymezeny na úroveň kolekce. Jeden dotaz může načíst data pouze z jedné kolekce. Pokud potřebujete načíst data z více kolekcí, musíte se na každou kolekci dotazovat jednotlivě a sloučit výsledky v kódu aplikace.
Azure Cosmos DB podporuje programovatelné položky, které je možné uložit v kolekci spolu s dokumenty. Patří mezi ně uložené procedury, uživatelem definované funkce a triggery (napsané v JavaScriptu). Tyto položky mají přístup k libovolnému dokumentu ve stejné kolekci. Tyto položky navíc běží buď uvnitř rozsahu okolí transakce (v případě triggeru, který se aktivuje v důsledku operace vytvoření, odstranění nebo nahrazení provedené v dokumentu), nebo spuštěním nové transakce (v případě uložené procedury, která se spouští v důsledku explicitní žádosti klienta). Pokud kód v programovatelné položce vyvolá výjimku, transakce se vrátí zpět. Uložené procedury a triggery můžete použít k zachování integrity a konzistence mezi dokumenty, ale všechny tyto dokumenty musí být součástí stejné kolekce.
Kolekce, které chcete v databázích uchovávat, by neměly překročit limity propustnosti definované úrovněmi výkonu kolekcí. Další informace najdete v tématu jednotky žádostí ve službě Azure Cosmos DB. Pokud předpokládáte dosažení těchto limitů, zvažte rozdělení kolekcí mezi databázemi v různých účtech, abyste snížili zatížení na kolekci.
Dělení služby Azure AI Search
Schopnost hledat data je často primární metodou navigace a průzkumu, která je poskytována mnoha webovými aplikacemi. Pomáhá uživatelům rychle najít prostředky (například produkty v aplikaci elektronického obchodování) na základě kombinací kritérií hledání. Služba AI Search poskytuje funkce fulltextového vyhledávání na webovém obsahu a zahrnuje funkce, jako je typ dopředu, navrhované dotazy založené na téměř shodách a fasetové navigaci. Další informace najdete v tématu Co je vyhledávání AI?.
AI Search ukládá prohledávatelný obsah jako dokumenty JSON v databázi. Definujete indexy, které určují prohledávatelná pole v těchto dokumentech a poskytují tyto definice službě AI Search. Když uživatel odešle žádost o hledání, služba AI Search vyhledá odpovídající položky pomocí příslušných indexů.
Kvůli omezení kolizí je možné úložiště používané vyhledáváním AI rozdělit do 1, 2, 3, 4, 6 nebo 12 oddílů a každý oddíl je možné replikovat až 6krát. Součin počtu oddílů vynásobených počtem replik se nazývá jednotka vyhledávání (SU). Jedna instance služby AI Search může obsahovat maximálně 36 jednotek SU (databáze s 12 oddíly podporuje maximálně 3 repliky).
Účtuje se vám každý SU, který je přidělen vaší službě. S rostoucím objemem prohledávatelného obsahu nebo rostoucím tempem žádostí o vyhledávání můžete přidat SU do existující instance vyhledávání AI a zpracovat tak dodatečné zatížení. AI Search sám distribuuje dokumenty rovnoměrně mezi oddíly. V současné době nejsou podporovány žádné strategie ručního dělení.
Každý oddíl může obsahovat maximálně 15 milionů dokumentů nebo zabírat 300 GB úložného prostoru (podle toho, co je menší). Můžete vytvořit až 50 indexů. Výkon služby se liší a závisí na složitosti dokumentů, dostupných indexech a vlivech latence sítě. V průměru by měla být jedna replika (1 SU) schopná zpracovat 15 dotazů za sekundu (QPS), ale doporučujeme provést srovnávací testy s vlastními daty, abyste získali přesnější míru propustnosti. Další informace najdete v tématu Omezení služby ve službě AI Search.
Poznámka:
Do prohledávatelných dokumentů můžete uložit omezenou sadu datových typů, včetně řetězců, logických hodnot, číselných dat, dat data data a času a některých geografických dat. Další informace najdete na stránce podporované datové typy (AI Search) na webu Microsoftu.
Máte omezenou kontrolu nad tím, jak služba AI Search rozděluje data pro každou instanci služby. V globálním prostředí ale můžete být schopni zvýšit výkon a dále snížit latenci a kolizí rozdělením samotné služby pomocí některé z následujících strategií:
Vytvořte instanci vyhledávání AI v každé geografické oblasti a ujistěte se, že jsou klientské aplikace směrovány na nejbližší dostupnou instanci. Tato strategie vyžaduje, aby se všechny aktualizace prohledávatelného obsahu replikovaly včas napříč všemi instancemi služby.
Vytvořte dvě úrovně vyhledávání AI:
- Místní služba v každé oblasti, která obsahuje data, která uživatelé v dané oblasti nejčastěji používají. Uživatelé zde můžou směrovat žádosti o rychlé, ale omezené výsledky.
- Globální služba, která zahrnuje všechna data. Uživatelé můžou směrovat požadavky na pomalejší, ale přesnější výsledky.
Tento přístup je nejvhodnější v případě, že se prohledávají významná regionální variace dat.
Dělení služby Azure Cache for Redis
Azure Cache for Redis poskytuje sdílenou službu ukládání do mezipaměti v cloudu založenou na úložišti dat klíč-hodnota Redis. Jak už název napovídá, služba Azure Cache for Redis je určená jako řešení ukládání do mezipaměti. Používejte ho jenom pro uchovávání přechodných dat, ne jako trvalé úložiště dat. Aplikace, které používají Azure Cache for Redis, by měly být schopné dál fungovat, pokud mezipaměť není k dispozici. Azure Cache for Redis podporuje primární nebo sekundární replikaci, která poskytuje vysokou dostupnost, ale v současné době omezuje maximální velikost mezipaměti na 53 GB. Pokud potřebujete více místa, musíte vytvořit další mezipaměti. Další informace najdete v článku, který se věnuje službě Azure Cache for Redis.
Dělení úložiště dat Redis zahrnuje rozdělení dat mezi instance služby Redis. Každá instance představuje jeden oddíl. Azure Cache for Redis abstrahuje služby Redis za fasádou a nezpřístupňuje je přímo. Nejjednodušší způsob, jak implementovat dělení, je vytvořit několik instancí Azure Cache for Redis a rozdělit data mezi ně.
Každou datovou položku můžete přidružit k identifikátoru (klíč oddílu), který určuje, která mezipaměť ukládá datovou položku. Logika klientské aplikace pak může tento identifikátor použít ke směrování požadavků do příslušného oddílu. Toto schéma je velmi jednoduché, ale pokud se schéma dělení změní (například pokud se vytvoří další instance Azure Cache for Redis), může být potřeba překonfigurovat klientské aplikace.
Nativní Redis (nikoli Azure Cache for Redis) podporuje dělení na straně serveru na základě clusteringu Redis. V tomto přístupu můžete data rovnoměrně rozdělit mezi servery pomocí mechanismu hash. Každý server Redis ukládá metadata, která popisují rozsah klíčů hash, které oddíl obsahuje, a obsahuje také informace o tom, které klíče hash se nacházejí v oddílech na jiných serverech.
Klientské aplikace jednoduše odesílají požadavky na některý ze zúčastněných serverů Redis (pravděpodobně nejbližšího serveru). Server Redis prozkoumá požadavek klienta. Pokud se dá vyřešit místně, provede požadovanou operaci. V opačném případě předá požadavek na příslušný server.
Tento model se implementuje pomocí clusteringu Redis a podrobněji se popisuje v kurzu clusteru Redis stránce na webu Redis. Clustering Redis je pro klientské aplikace transparentní. Do clusteru je možné přidat další servery Redis (a data je možné předělovat) bez nutnosti překonfigurovat klienty.
Důležité
Azure Cache for Redis v současné době podporuje clustering Redis pouze na úrovni Premium.
Stránka Dělení: jak rozdělit data mezi více instancí Redis na webu Redis poskytuje další informace o implementaci dělení pomocí Redis. Zbývající část této části předpokládá, že implementujete dělení na straně klienta nebo proxy serveru.
Při rozhodování o tom, jak rozdělit data do služby Azure Cache for Redis, zvažte následující body:
Azure Cache for Redis není zamýšlený jako trvalé úložiště dat, takže bez ohledu na schéma dělení, které implementujete, musí být kód aplikace schopný načíst data z umístění, které není mezipamětí.
Data, ke kterým se často přistupuje společně, by se měla uchovávat ve stejném oddílu. Redis je výkonné úložiště klíč-hodnota, které poskytuje několik vysoce optimalizovaných mechanismů pro strukturování dat. Tyto mechanismy můžou být jedním z následujících způsobů:
- Jednoduché řetězce (binární data o délce až 512 MB)
- Agregované typy, jako jsou seznamy (které můžou fungovat jako fronty a zásobníky)
- Sady (seřazené a neuspořádané)
- Hodnoty hash (které můžou seskupit související pole dohromady, například položky představující pole v objektu)
Agregační typy umožňují přidružit mnoho souvisejících hodnot ke stejnému klíči. Klíč Redis identifikuje seznam, sadu nebo hodnotu hash místo datových položek, které obsahuje. Všechny tyto typy jsou dostupné ve službě Azure Cache for Redis a jsou popsané na stránce Datové typy na webu Redis. Například v části systému elektronického obchodování, který sleduje objednávky, které zákazníci umisťují, můžou být podrobnosti o každém zákazníkovi uloženy v hodnotě hash Redis, která je klíčována pomocí ID zákazníka. Každá hodnota hash může obsahovat kolekci ID objednávek pro zákazníka. Samostatná sada Redis může obsahovat objednávky, znovu strukturované jako hodnoty hash a klíčované pomocí ID objednávky. Obrázek 8 znázorňuje tuto strukturu. Mějte na paměti, že Redis neimplementuje žádnou formu referenční integrity, takže je zodpovědností vývojáře udržovat vztahy mezi zákazníky a objednávkami.
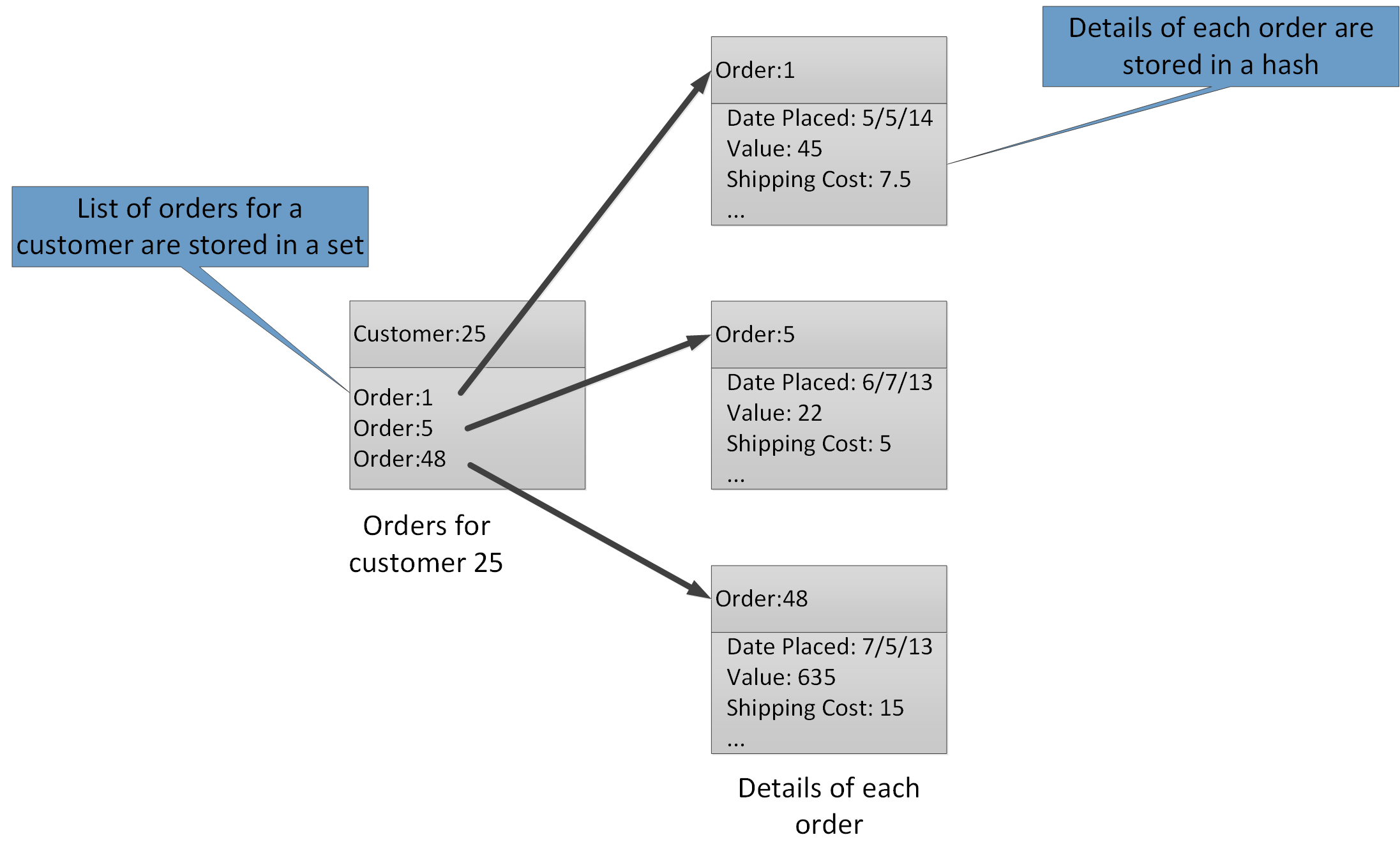
Obrázek 8 Navrhovaná struktura v úložišti Redis pro zaznamenávání objednávek zákazníků a jejich podrobností
Poznámka:
Ve službě Redis jsou všechny klíče binárními datovými hodnotami (jako jsou řetězce Redis) a mohou obsahovat až 512 MB dat. Teoreticky může klíč obsahovat téměř jakékoli informace. Doporučujeme však přijmout konzistentní zásady vytváření názvů pro klíče, které jsou popisné typu dat a identifikují entitu, ale nejsou příliš dlouhé. Běžným přístupem je použití klíčů formuláře "entity_type:ID". Můžete například použít "customer:99" k označení klíče zákazníka s ID 99.
Vertikální dělení můžete implementovat uložením souvisejících informací do různých agregací ve stejné databázi. Například v aplikaci elektronického obchodování můžete ukládat běžně používané informace o produktech v jedné hodnotě hash Redis a méně často používané podrobné informace v jiné. Obě hodnoty hash můžou používat stejné ID produktu jako součást klíče. Můžete například použít "product: nn" (kde nn je ID produktu) pro informace o produktu a "product_details: nn" pro podrobná data. Tato strategie může pomoct snížit objem dat, která většina dotazů pravděpodobně načte.
Úložiště dat Redis můžete předělovat, ale mějte na paměti, že se jedná o složitou a časově náročnou úlohu. Clustering Redis může automaticky předělovat data, ale tato funkce není v Azure Cache for Redis dostupná. Proto při návrhu schématu dělení zkuste nechat v každém oddílu dostatek volného místa, aby bylo možné v průběhu času dosáhnout očekávaného růstu dat. Mějte ale na paměti, že Azure Cache for Redis je určen k dočasnému ukládání dat do mezipaměti a že data uložená v mezipaměti můžou mít omezenou životnost určenou jako hodnotu TTL (Time to Live). U relativně nestálých dat může být hodnota TTL krátká, ale u statických dat může být hodnota TTL mnohem delší. Pokud je pravděpodobné, že objem těchto dat naplní mezipaměť, vyhněte se ukládání velkých objemů dlouhodobých dat do mezipaměti. Můžete zadat zásady vyřazení, které způsobí, že Azure Cache for Redis odebere data, pokud je prostor na úrovni Premium.
Poznámka:
Když použijete Azure Cache for Redis, zadáte maximální velikost mezipaměti (od 250 MB do 53 GB) výběrem příslušné cenové úrovně. Po vytvoření služby Azure Cache for Redis ale nemůžete zvětšit (nebo zmenšit) jeho velikost.
Dávky a transakce Redis nemohou zahrnovat více připojení, takže všechna data ovlivněná dávkou nebo transakcí by se měla uchovávat ve stejné databázi (horizontální oddíl).
Poznámka:
Posloupnost operací v transakci Redis není nutně atomická. Příkazy, které tvoří transakci, jsou ověřeny a zařazeny do fronty před jejich spuštěním. Pokud během této fáze dojde k chybě, zahodí se celá fronta. Po úspěšném odeslání transakce se však příkazy zařazené do fronty spouštějí postupně. Pokud některý z příkazů selže, zastaví se pouze tento příkaz. Všechny předchozí a následné příkazy ve frontě se provádějí. Další informace najdete na stránce Transakce na webu Redis.
Redis podporuje omezený počet atomických operací. Jedinými operacemi tohoto typu, které podporují více klíčů a hodnot, jsou operace MGET a MSET. Operace MGET vrací kolekci hodnot pro zadaný seznam klíčů a operace MSET ukládají kolekci hodnot pro zadaný seznam klíčů. Pokud tyto operace potřebujete použít, musí být páry klíč-hodnota, na které odkazují příkazy MSET a MGET, uloženy ve stejné databázi.
Dělení Azure Service Fabric
Azure Service Fabric je platforma mikroslužeb, která poskytuje modul runtime pro distribuované aplikace v cloudu. Service Fabric podporuje spustitelné soubory hosta .NET, stavové a bezstavové služby a kontejnery. Stavové služby poskytují spolehlivé shromažďování k trvalému ukládání dat do kolekce klíč-hodnota v clusteru Service Fabric. Další informace o strategiích pro dělení klíčů ve spolehlivé kolekci najdete v tématu Pokyny a doporučení pro spolehlivé kolekce ve službě Azure Service Fabric.
Další kroky
Přehled služby Azure Service Fabric představuje úvod do Azure Service Fabric.
dělení spolehlivých služeb Service Fabric poskytuje další informace o spolehlivých službách v Azure Service Fabric.
Dělení služby Azure Event Hubs
služba Azure Event Hubs je navržená pro streamování dat ve velkém měřítku a dělení je integrované do služby, aby bylo možné horizontální škálování. Každý příjemce čte pouze určitý oddíl streamu zpráv.
Zdroj události zná jenom svůj klíč oddílu, a ne oddíl, do kterého se události publikují. Díky tomuto oddělení klíče a oddílu odesílatel toho nepotřebuje vědět o zpracování příjmu dat příliš mnoho. (Je také možné odesílat události přímo do daného oddílu, ale obecně to nedoporučujeme.)
Pokud vyberete počet oddílů, zvažte dlouhodobé škálování. Po vytvoření centra událostí nemůžete změnit počet oddílů.
Další kroky
Další informace o používání oddílů ve službě Event Hubs najdete v tématu Co je Event Hubs?.
Důležité informace o kompromisech mezi dostupností a konzistencí najdete v tématu Dostupnost a konzistence ve službě Event Hubs.