Vytváří indexy přes pole v úložištích dat, na která často odkazují dotazy. Tento model může zlepšit výkon dotazů, protože aplikacím umožňuje rychleji vyhledat potřebná data k načtení z úložiště dat.
Kontext a problém
V mnoha úložištích dat jsou data uspořádaná pro kolekci entit s využitím primárního klíče. Aplikace může tento klíč použít k vyhledání a načtení dat. Na obrázku je příklad úložiště dat s informacemi o zákaznících. Primárním klíčem je ID zákazníka. Obrázek ukazuje informace o zákaznících uspořádané podle primárního klíče (ID zákazníka).
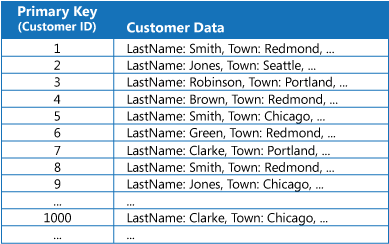
I když je primární klíč cenný pro dotazy, které na základě jeho hodnoty načítají data, aplikace nemusí být schopná primární klíč použít, pokud potřebuje načíst data na základě některého jiného pole. V příkladu se zákazníky nemůže aplikace primární klíč ID zákazníka k načtení zákazníků použít, pokud se na data dotazuje výhradně s využitím hodnoty jiného atributu, třeba města, kde se zákazník nachází. K provedení takového dotazu aplikace pravděpodobně bude muset načíst a zkontrolovat všechny záznamy zákazníků a to může být pomalý proces.
Řada systémů pro správu relačních databází podporuje sekundární indexy. Sekundární index je samostatná datová struktura, která je seřazená podle polí jednoho nebo více neprimárních (sekundárních) klíčů, kde jsou data pro každou indexovanou hodnotu uložená. Položky v sekundárním indexu jsou obvykle seřazené podle hodnoty sekundárních klíčů, aby umožňovaly rychlé vyhledávání dat. Tyto indexy jsou obvykle spravované automaticky správcem databáze.
Můžete vytvořit tolik sekundárních indexů, kolik jich potřebujete pro podporu různých dotazů, které vaše aplikace provádí. Třeba v tabulce zákazníků v relační databázi, kde je primárním klíčem ID zákazníka, je vhodné přidat sekundární index pro pole města, pokud aplikace často vyhledává zákazníky podle města, ve kterém se nacházejí.
I když jsou sekundární indexy v relačních systémech běžné, některá úložiště dat NoSQL používaná cloudovými aplikacemi neposkytují ekvivalentní funkci.
Řešení
Pokud úložiště dat nepodporuje sekundární indexy, můžete je emulovat ručně tak, že vytvoříte vlastní tabulky indexů. Tabulka indexu uspořádá data podle zadaného klíče. Ke strukturování tabulky indexu se běžně používají tři strategie v závislosti na počtu sekundárních indexů, které jsou požadované, a povaze dotazů, které aplikace provádí.
První strategií je duplikovat data v každé tabulce indexu, ale uspořádat je podle různých klíčů (úplná denormalizace). Následující obrázek znázorňuje tabulky indexu, kde jsou stejné informace o zákaznících uspořádané podle města (Town) a příjmení (LastName).
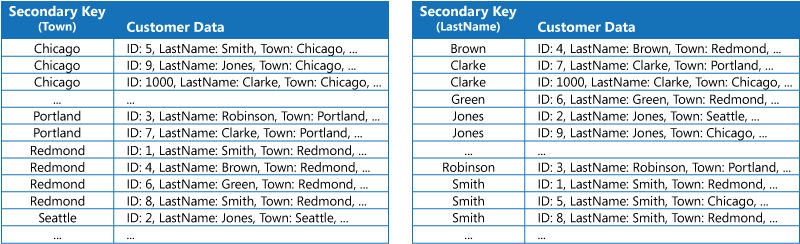
Tato strategie je vhodná v případě, že jsou data relativně statická ve srovnání s tím, jak často jsou pomocí každého klíče dotazovaná. Pokud jsou data dynamičtější, nároky na zpracování při udržování každé tabulky indexu se příliš zvýší na to, aby byl tento přístup užitečný. Navíc pokud je objem dat velmi velký, významnou roli hraje množství místa potřebného pro uložení duplicitních dat.
Druhou strategií je vytvořit normalizované tabulky indexů uspořádané podle různých klíčů a na původní data odkazovat pomocí primárního klíče místo jejich duplikování, jak je vidět na následujícím obrázku. Původní data se nazývají tabulka faktů.
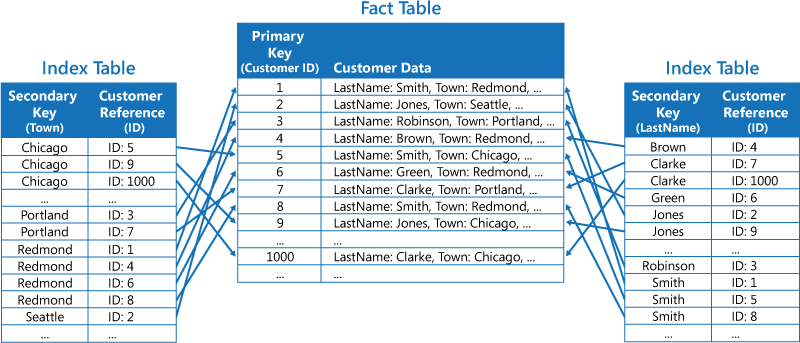
Tato metoda šetří místo a snižuje nároky na údržbu duplicitních dat. Nevýhodou je, že aplikace musí provést dvě operace vyhledávání, aby našla data pomocí sekundárního klíče. Musí najít primární klíč pro data v tabulce indexu a pak primární klíč použít k vyhledávání dat v tabulce faktů.
Třetí strategií je vytvořit částečně normalizované tabulky indexů uspořádané podle různých klíčů, které duplikují často načítaná pole. Přístup k méně často používaným polím je zajištěný odkazováním na tabulku faktů. Na dalším obrázku je vidět, jak jsou v každé tabulce indexu často používaná data duplikována.
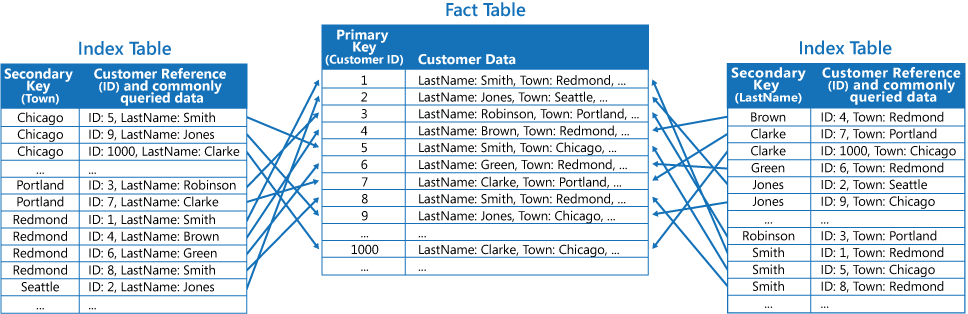
Tato strategie dosahuje rovnováhy mezi prvními dvěma přístupy. Data pro běžné dotazy se dají rychle načíst pomocí jediného vyhledání, ale nároky na místo a údržbu nejsou tak významné jako při duplikování celé sady dat.
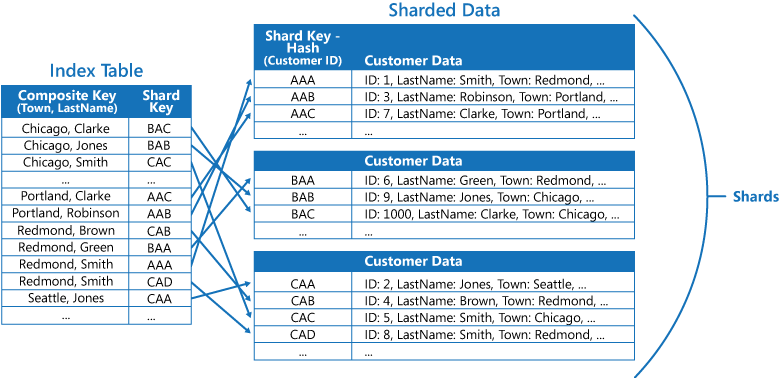
Pokud aplikace často dotazuje data zadáním kombinace hodnot (například "Najít všechny zákazníky, kteří žijí v Redmondu a které mají příjmení Smith"), můžete implementovat klíče k položkám v tabulce indexu jako zřetězení atributu Město a atribut LastName. Následující obrázek ukazuje tabulku indexu založenou na složených klíčích. Klíče jsou seřazené podle města a pak podle příjmení pro záznamy, které mají stejnou hodnotu pro město.

Tabulky indexů můžou urychlit operace dotazů na horizontálně dělená data a jsou zvlášť užitečné, když je klíč horizontálního dělení hodnotou hash. Následující obrázek ukazuje příklad, kdy je klíč horizontálního dělení hodnotou hash ID zákazníka. Tabulka indexu může data uspořádat podle hodnoty, která není hodnotou hash (město a příjmení), a poskytnout klíč horizontálního dělení, který je hodnotou hash, jako vyhledávaná data. To může aplikaci ušetřit opakované výpočty klíčů hash (náročná operace), pokud potřebuje načíst data, která spadají do rozsahu, nebo potřebuje načíst data v pořadí podle klíče, který není hodnotou hash. Například dotaz "Najít všechny zákazníky, kteří žijí v Redmondu", se dá rychle vyřešit vyhledáním odpovídajících položek v tabulce indexu, kde jsou všechny uložené v souvislém bloku. Pak se použijí odkazy na data zákazníků pomocí klíčů horizontálního dělení uložených v tabulce indexu.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
Nároky na údržbu sekundárních indexů můžou být významné. Musíte analyzovat a chápat dotazy, které vaše aplikace používá. Tabulky indexů vytvářejte jenom v případě, že se pravděpodobně budou používat pravidelně. Nevytvářejte spekulativní tabulky indexů k podpoře dotazů, které aplikace neprovádí nebo prování jenom občas.
Duplikace dat v tabulce indexu může významně navýšit náklady na úložiště a úsilí potřebné k udržování více kopií dat.
Implementace tabulky indexu jako normalizované struktury, která odkazuje na původní data, vyžaduje, aby aplikace k nalezení dat prováděla dvě operace vyhledávání. První operace prohledá tabulku indexu, aby načetla primární klíč, a druhá primární klíč využije k načtení dat.
Pokud systém zahrnuje řadu tabulek indexů a velmi velké sady dat, může být obtížné zachovat konzistenci mezi tabulkami indexů a původními daty. Může být možné navrhnout aplikaci kolem modelu konzistence typu Případné. Třeba k vložení, aktualizaci nebo odstranění dat může aplikace přidat zprávu do fronty a nechat operaci provést samostatnou úlohou a udržovat tabulky indexů, které na tato data odkazují, asynchronně. Další informace o implementaci konzistence typu Případné najdete v úvodu ke konzistenci dat.
Tip
Tabulky úložiště Microsoft Azure podporují transakční aktualizace pro změny dat, která jsou uložená ve stejném oddílu (označované jako transakce skupiny entit). Pokud můžete data pro tabulku faktů a jednu nebo více tabulek indexu uložit do stejného oddílu, můžete tuto funkci využít k zajištění konzistence.
Tabulky indexů můžou být samy rozdělené na oddíly nebo horizontálně dělené.
Kdy se má tento model použít
Tento model můžete použít ke zlepšení výkonu dotazů, když aplikace často potřebuje načítat data pomocí jiného než primárního klíče (nebo klíče horizontálního dělení).
Tento model nebude pravděpodobně vhodný v následujících případech:
- Data jsou nestálá. Tabulka indexu může hodně rychle zastarat, takže se stane neefektivní nebo se nároky na údržbu tabulky indexu stanou vyššími než úspory dosažené jejím využíváním.
- Pole vybrané jako sekundární klíč pro tabulku indexu je nerozlišující a může mít jenom malou sadu hodnot (třeba pohlaví).
- Používání datových hodnot pro pole vybrané jako sekundární klíč pro tabulku indexu je velmi nevyvážené. Pokud třeba 90 % záznamů obsahuje v poli stejnou hodnotu, pak vytvoření a údržba tabulky indexu pro vyhledávání dat na základě tohoto pole může být náročnější než postupné prohledání dat. Pokud ale dotazy velmi často cílí na hodnoty, které se nacházejí ve zbývajících 10 %, může být tento index užitečný. Dotazům, které aplikace provádí, a tomu, jak často se provádějí, byste měli rozumět.
Návrh úloh
Architekt by měl vyhodnotit způsob použití vzoru indexové tabulky v návrhu úloh k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Vzhledem k tomu, že klienti prostřednictvím procesu vyhledávání odkazují na jejich horizontální oddíl, oddíl nebo koncový bod, můžete tento model použít k usnadnění přístupu k datům při selhání. - RE:06 Dělení dat - RE:09 Zotavení po havárii |
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Klienti odkazují na jejich horizontální oddíl, oddíl nebo koncový bod, což umožňuje dynamické dělení dat pro optimalizaci výkonu. - PE:05 Škálování a dělení - Výkon dat PE:08 |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Tabulky v úložišti Azure poskytují vysoce škálovatelné úložiště dat klíč/hodnota pro aplikace běžící v cloudu. Aplikace hodnoty dat ukládají a načítají zadáním klíče. Hodnoty dat můžou obsahovat více polí, ale struktura datové položky je pro úložiště tabulky nesrozumitelná, takže úložiště datovou položku zpracovává jednoduše jako pole bajtů.
Tabulky v úložišti Azure také podporují horizontální dělení. Klíč horizontálního dělení obsahuje dva prvky, klíč oddílu a klíč řádku. Položky, které mají stejný klíč oddílu, jsou uložené ve stejném oddílu (horizontálním oddílu) a v horizontálním oddílu jsou položky uložené v pořadí podle klíčů řádků. Úložiště tabulek je optimalizované pro provádění dotazů, které načítají data spadající do souvislého rozsahu hodnot klíčů řádků v rámci oddílu. Pokud vytváříte cloudové aplikace, které ukládají informace do tabulek Azure, měli byste data strukturovat s ohledem na tuto funkci.
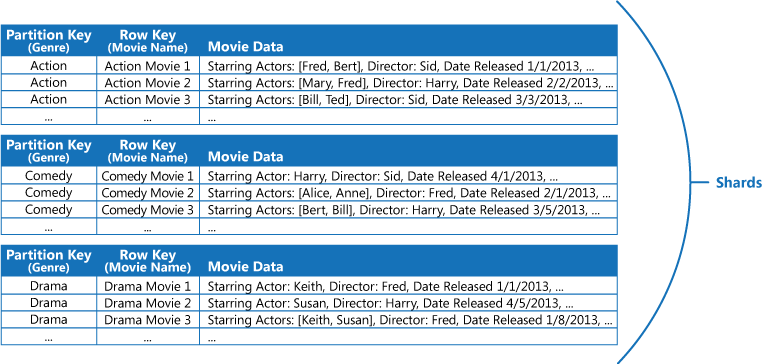
Představme si třeba aplikaci, která uchovává informace o filmech. Aplikace se často dotazuje na filmy podle žánru (akční, dokument, historický, komedie, drama a podobně). Můžete vytvořit tabulku Azure s oddíly pro každý žánr tak, že žánr použijete jako klíč oddílu, a název filmu zadáte jako klíč řádku, jak ukazuje následující obrázek.
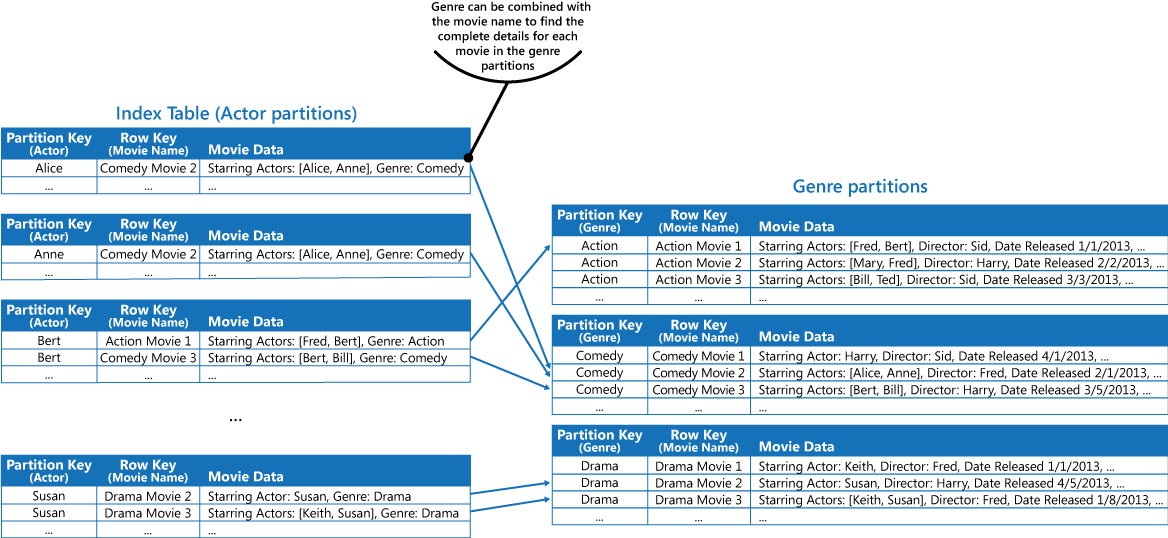
Tento přístup je méně účinný, pokud se aplikace potřebuje na filmy dotazovat také podle herců v hlavních rolích. V takovém případě můžete vytvořit samostatnou tabulku Azure, která funguje jako tabulka indexu. Klíč oddílu je herec a klíč řádku je název filmu. Data pro každého herce budou uložená v samostatných oddílech. Pokud je ve filmu více herců v hlavních rolích, stejný film se bude vyskytovat ve více oddílech.
Data o filmech v hodnotách uložených v každém oddílu můžete duplikovat pomocí prvního postupu popsaného v části Řešení výše. Je ale pravděpodobné, že každý film bude několikrát replikovaný (jednou pro každého herce). Efektivnější by proto mohlo být data částečně denormalizovat, aby se podpořily nejčastější dotazy (jako jména dalších herců), a umožnit aplikaci načítat zbývající údaje díky zahrnutí klíče oddílu, který je potřeba k nalezení úplných informací v oddílech žánrů. Tento postup je popsaný ve třetí možnosti v části Řešení. Je znázorněný na následujícím obrázku.
Další kroky
- Úvod do konzistence dat. Tabulka indexu se musí udržovat s tím, jak se mění data, která indexuje. V cloudu nemusí být možné nebo vhodné provádět operace, které aktualizují index, v rámci stejné transakce, která upravuje data. V takovém případě je vhodnější přístup využívající konzistence typu Případné. Obsahuje informace o problémech spojených s konzistencí typu Případné.
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující vzory:
- Model Horizontální dělení. Model Tabulka indexu se často používá ve spojení s daty rozdělenými pomocí horizontálních oddílů. Model Horizontální dělení poskytuje další informace o tom, jak úložiště dat rozdělit na sadu horizontálních oddílů.
- Model Materializované zobrazení. Místo indexování dat k podpoře dotazů, které data shrnují, může být vhodnější vytvořit materializované zobrazení dat. Popisuje, jak podporovat efektivní souhrnné dotazy vygenerováním předem vyplněných zobrazení nad daty.