Tento obsah se vztahuje na: v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze: v3.1 (GA) :::moniker-end
v3.1 (GA) :::moniker-end
Tento obsah se vztahuje na:v3.1 (GA) | Nejnovější verze: v4.0 (GA)
v4.0 (GA)
Poznámka:
Možnosti doplňků jsou dostupné ve všech modelech s výjimkou modelu vizitky.
Možnosti
Funkce Document Intelligence podporuje sofistikovanější a modulární možnosti analýzy. Pomocí funkcí doplňku můžete výsledky rozšířit tak, aby zahrnovaly další funkce extrahované z dokumentů. Za některé funkce doplňku se účtují další náklady. Tyto volitelné funkce je možné povolit a zakázat v závislosti na scénáři extrakce dokumentů. Pokud chcete funkci povolit, přidejte název přidružené funkce do features vlastnosti řetězce dotazu. V požadavku můžete povolit více než jednu funkci doplňku tak, že poskytnete seznam funkcí oddělených čárkami. Následující možnosti doplňku jsou k dispozici pro 2023-07-31 (GA) a novější verze.
Poznámka:
Ne všechny modely nebo systém Microsoft Office typy souborů podporují možnosti doplňků. Další informace najdete v tématuextrakce dat modelu.
Dostupnost verzí
| Funkce doplňku |
Doplněk nebo zdarma |
2024-11-30 (GA) |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
| Extrakce čárových kódů |
Bezplatný |
✔️ |
✔️ |
Není k dispozici |
Není k dispozici |
| Rozpoznávání jazyka |
Bezplatný |
✔️ |
✔️ |
Není k dispozici |
Není k dispozici |
| Páry klíč-hodnota |
Bezplatný |
✔️ |
Není k dispozici |
– |
Není k dispozici |
| Prohledávatelný SOUBOR PDF |
Bezplatný |
✔️ |
Není k dispozici |
– |
Není k dispozici |
| Extrakce vlastností písma |
Doplněk |
✔️ |
✔️ |
Není k dispozici |
Není k dispozici |
| Extrakce vzorců |
Doplněk |
✔️ |
✔️ |
Není k dispozici |
Není k dispozici |
| Extrakce s vysokým rozlišením |
Doplněk |
✔️ |
✔️ |
Není k dispozici |
Není k dispozici |
| Pole dotazu |
Doplněk |
✔️ |
Není k dispozici |
– |
Není k dispozici |
✱ Doplňky – Pole dotazu se za ceny liší od ostatních funkcí doplňku. Podrobnosti najdete na stránce s cenami .
** Doplněk – Prohledávatelný soubor PDF je k dispozici pouze s modelem pro čtení jako doplňkovou funkcí.
✱ systém Microsoft Office soubory se v současné době nepodporují.
Úkolem rozpoznání malého textu z rozsáhlých dokumentů, jako jsou technické výkresy, je výzva. Text je často smíšený s jinými grafickými prvky a má různá písma, velikosti a orientace. Kromě toho lze text rozdělit do samostatných částí nebo spojit s jinými symboly. Funkce Document Intelligence teď podporuje extrakci obsahu z těchto typů dokumentů s ocr.highResolution možností. Díky povolení této možnosti doplňku získáte lepší kvalitu extrakce obsahu z dokumentů A1/A2/A3.
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=ocrHighResolution
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
"styles": [true],
"pages": [
{
"page_number": 1,
"width": 1000,
"height": 800,
"unit": "px",
"lines": [
{
"line_idx": 1,
"content": "This",
"polygon": [10, 20, 30, 40],
"words": [
{
"content": "This",
"confidence": 0.98
}
]
}
],
"selection_marks": [
{
"state": "selected",
"polygon": [50, 60, 70, 80],
"confidence": 0.91
}
]
}
],
"tables": [
{
"table_idx": 1,
"row_count": 3,
"column_count": 4,
"bounding_regions": [
{
"page_number": 1,
"polygon": [100, 200, 300, 400]
}
],
"cells": [
{
"row_index": 1,
"column_index": 1,
"content": "Content 1",
"bounding_regions": [
{
"page_number": 1,
"polygon": [110, 210, 310, 410]
}
]
}
]
}
]
{your-resource-endpoint}.cognitiveservices.azure.com/formrecognizer/documentModels/prebuilt-layout:analyze?api-version=2023-07-31&features=ocrHighResolution
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
"styles": [true],
"pages": [
{
"page_number": 1,
"width": 1000,
"height": 800,
"unit": "px",
"lines": [
{
"line_idx": 1,
"content": "This",
"polygon": [10, 20, 30, 40],
"words": [
{
"content": "This",
"confidence": 0.98
}
]
}
],
"selection_marks": [
{
"state": "selected",
"polygon": [50, 60, 70, 80],
"confidence": 0.91
}
]
}
],
"tables": [
{
"table_idx": 1,
"row_count": 3,
"column_count": 4,
"bounding_regions": [
{
"page_number": 1,
"polygon": [100, 200, 300, 400]
}
],
"cells": [
{
"row_index": 1,
"column_index": 1,
"content": "Content 1",
"bounding_regions": [
{
"page_number": 1,
"polygon": [110, 210, 310, 410]
}
]
}
]
}
]
Funkce ocr.formula extrahuje všechny identifikované vzorce, jako jsou matematické rovnice, v formulas kolekci jako objekt nejvyšší úrovně v části content. Uvnitř content, zjištěné vzorce jsou reprezentovány jako :formula:. Každá položka v této kolekci představuje vzorec, který obsahuje typ vzorce jako inline nebo displaya jeho reprezentaci LaTeX stejně jako value souřadnice polygon . Na začátku se vzorce zobrazí na konci každé stránky.
Poznámka:
Skóre confidence je pevně zakódované.
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=formulas
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
{your-resource-endpoint}.cognitiveservices.azure.com/formrecognizer/documentModels/prebuilt-layout:analyze?api-version=2023-07-31&features=formulas
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Funkce ocr.font extrahuje všechny vlastnosti písma textu extrahovaného v kolekci jako objekt nejvyšší úrovně v styles části content. Každý objekt stylu určuje jednu vlastnost písma, rozsah textu, na který se vztahuje, a odpovídající skóre spolehlivosti. Existující vlastnost stylu je rozšířena o další vlastnosti písma, například similarFontFamily pro písmo textu, pro styly, fontStyle jako je kurzíva a normální, pro tučné nebo normální, colorfontWeight pro barvu textu a backgroundColor barvu ohraničujícího pole textu.
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=styleFont
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
"content": "Foo bar",
"styles": [
{
"similarFontFamily": "Arial, sans-serif",
"spans": [ { "offset": 0, "length": 3 } ],
"confidence": 0.98
},
{
"similarFontFamily": "Times New Roman, serif",
"spans": [ { "offset": 4, "length": 3 } ],
"confidence": 0.98
},
{
"fontStyle": "italic",
"spans": [ { "offset": 1, "length": 2 } ],
"confidence": 0.98
},
{
"fontWeight": "bold",
"spans": [ { "offset": 2, "length": 3 } ],
"confidence": 0.98
},
{
"color": "#FF0000",
"spans": [ { "offset": 4, "length": 2 } ],
"confidence": 0.98
},
{
"backgroundColor": "#00FF00",
"spans": [ { "offset": 5, "length": 2 } ],
"confidence": 0.98
}
]
{your-resource-endpoint}.cognitiveservices.azure.com/formrecognizer/documentModels/prebuilt-layout:analyze?api-version=2023-07-31&features=styleFont
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
"content": "Foo bar",
"styles": [
{
"similarFontFamily": "Arial, sans-serif",
"spans": [ { "offset": 0, "length": 3 } ],
"confidence": 0.98
},
{
"similarFontFamily": "Times New Roman, serif",
"spans": [ { "offset": 4, "length": 3 } ],
"confidence": 0.98
},
{
"fontStyle": "italic",
"spans": [ { "offset": 1, "length": 2 } ],
"confidence": 0.98
},
{
"fontWeight": "bold",
"spans": [ { "offset": 2, "length": 3 } ],
"confidence": 0.98
},
{
"color": "#FF0000",
"spans": [ { "offset": 4, "length": 2 } ],
"confidence": 0.98
},
{
"backgroundColor": "#00FF00",
"spans": [ { "offset": 5, "length": 2 } ],
"confidence": 0.98
}
]
Funkce ocr.barcode extrahuje všechny identifikované čárové kódy v kolekci jako objekt nejvyšší úrovně v barcodes části content.
contentUvnitř , zjištěné čárové kódy jsou reprezentovány jako :barcode:. Každá položka v této kolekci představuje čárový kód a zahrnuje typ čárového kódu jako kind a vložený obsah čárového kódu spolu value s jeho polygon souřadnicemi. Na začátku se na konci každé stránky zobrazí čárové kódy. Kód confidence je pevně zakódován jako 1.
Podporované typy čárových kódů
|
Typ čárového kódu |
Příklad |
QR Code |

|
Code 39 |

|
Code 93 |

|
Code 128 |

|
UPC (UPC-A & UPC-E) |

|
PDF417 |

|
EAN-8 |

|
EAN-13 |
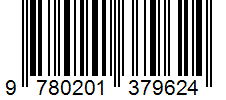
|
Codabar |

|
Databar |

|
Databar Rozšířený |

|
ITF |

|
Data Matrix |

|
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=barcodes
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-read",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
if page.barcodes:
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {barcode.polygon}")
----Barcodes detected from page #1----
Detected 2 barcodes:
- Barcode #0: 123456
Kind: QRCode
Confidence: 0.95
Bounding regions: [10.5, 20.5, 30.5, 40.5]
- Barcode #1: 789012
Kind: QRCode
Confidence: 0.98
Bounding regions: [50.5, 60.5, 70.5, 80.5]
{your-resource-endpoint}.cognitiveservices.azure.com/formrecognizer/documentModels/prebuilt-layout:analyze?api-version=2023-07-31&features=barcodes
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
----Barcodes detected from page #1----
Detected 2 barcodes:
- Barcode #0: 123456
Kind: QRCode
Confidence: 0.95
Bounding regions: [10.5, 20.5, 30.5, 40.5]
- Barcode #1: 789012
Kind: QRCode
Confidence: 0.98
Bounding regions: [50.5, 60.5, 70.5, 80.5]
Rozpoznávání jazyka
languages Přidání funkce do analyzeResult požadavku předpovídá rozpoznaný primární jazyk pro každý řádek textu spolu s textem confidence v kolekci languages v části analyzeResult.
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=languages
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
"languages": [
{
"spans": [
{
"offset": 0,
"length": 131
}
],
"locale": "en",
"confidence": 0.7
},
]
{your-resource-endpoint}.cognitiveservices.azure.com/formrecognizer/documentModels/prebuilt-layout:analyze?api-version=2023-07-31&features=languages
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
"languages": [
{
"spans": [
{
"offset": 0,
"length": 131
}
],
"locale": "en",
"confidence": 0.7
},
]
Prohledávatelný SOUBOR PDF
Funkce prohledávatelného PDF umožňuje převést analogové SOUBORY PDF, jako jsou naskenované soubory PDF, do PDF s vloženým textem. Vložený text umožňuje hloubkové vyhledávání textu v extrahovaném obsahu PDF tak, že překryjí zjištěné textové entity nad soubory obrázků.
Důležité
- V současné době podporuje prohledávatelný formát PDF pouze model
prebuilt-read pro čtení. Při použití této funkce zadejte modelId jako prebuilt-read.
- Prohledávatelný SOUBOR PDF je součástí
2024-11-30 modelu (GA) prebuilt-read bez nákladů na využití pro obecnou spotřebu PDF.
Použití prohledávatelného PDF
Pokud chcete použít prohledávatelný SOUBOR PDF, vytvořte POST požadavek pomocí Analyze operace a zadejte výstupní formát takto pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Analyze Po dokončení operace vytvořte GET požadavek na načtení Analyze výsledků operace.
Po úspěšném dokončení lze soubor PDF načíst a stáhnout jako application/pdf. Tato operace umožňuje přímé stažení vloženého textového formátu PDF místo formátu JSON s kódováním Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Páry klíč-hodnota
V dřívějších verzích prebuilt-document rozhraní API model extrahovali páry klíč-hodnota z formulářů a dokumentů. S přidáním keyValuePairs funkce k předem sestaveným rozložením teď model rozložení vytvoří stejné výsledky.
Páry klíč-hodnota jsou specifické rozsahy v dokumentu, které identifikují popisek nebo klíč a jeho přidruženou odpověď nebo hodnotu. Ve strukturovaném formuláři můžou být tyto páry popiskem a hodnotou, kterou uživatel zadal pro toto pole. V nestrukturovaném dokumentu můžou být datum, kdy byla smlouva provedena na základě textu v odstavci. Model AI se vytrénuje tak, aby extrahovala identifikovatelné klíče a hodnoty na základě široké škály typů dokumentů, formátů a struktur.
Klíče mohou existovat také izolovaně, když model zjistí, že klíč existuje, bez přidružené hodnoty nebo při zpracování volitelných polí. Například pole s prostředním názvem může být v některých případech prázdné ve formuláři. Páry klíč-hodnota jsou rozsahy textu obsaženého v dokumentu. U dokumentů, ve kterých je stejná hodnota popsaná různými způsoby, například zákazník/uživatel, je přidruženým klíčem zákazník nebo uživatel (na základě kontextu).
REST API
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=keyValuePairs
Pole dotazu
Pole dotazů jsou doplňkovou funkcí pro rozšíření schématu extrahovaného z libovolného předem vytvořeného modelu nebo definování konkrétního názvu klíče, pokud je název klíče proměnný. Pokud chcete použít pole dotazu, nastavte funkce tak, aby queryFields ve vlastnosti poskytovaly čárkami oddělený seznam názvů queryFields polí.
Funkce Document Intelligence teď podporuje extrakce polí dotazu. Pomocí extrakce polí dotazu můžete do procesu extrakce přidat pole pomocí požadavku na dotaz, aniž by bylo potřeba přidat trénování.
Pole dotazu použijte v případě, že potřebujete rozšířit schéma předem vytvořeného nebo vlastního modelu nebo potřebujete extrahovat několik polí s výstupem rozložení.
Pole dotazů jsou funkce doplňku Premium. Nejlepších výsledků dosáhnete tak, že definujete pole, která chcete extrahovat pomocí názvů polí velbloudí nebo Pascal pro názvy polí s více slovy.
Pole dotazu podporují maximálně 20 polí na požadavek. Pokud dokument obsahuje hodnotu pole, vrátí se pole a hodnota.
Tato verze obsahuje novou implementaci schopností polí dotazů, která má nižší cenu než předchozí implementace, a měla by být ověřena.
Poznámka:
Extrakce polí dotazu Document Intelligence Studio je aktuálně dostupná s rozhraním API pro rozložení a předem připravené modely 2024-11-30 (GA) s výjimkou daňových modelů USA W2, 1098 a 1099.
Pro extrakci polí dotazu zadejte pole, která chcete extrahovat, a funkce Document Intelligence dokument odpovídajícím způsobem analyzuje. Tady je příklad:
Pokud zpracováváte kontrakt v sadě Document Intelligence Studio, použijte verzi ga ( 2024-11-30):
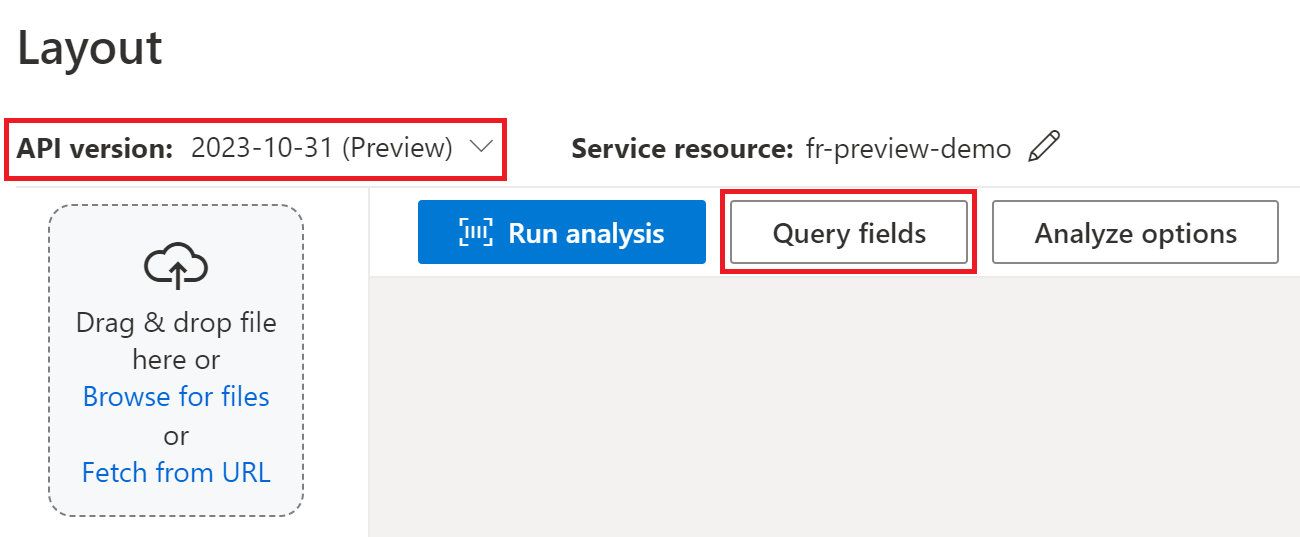
Můžete předat seznam popisků polí, jako Party1je , Party2, TermsOfUsePaymentTerms, PaymentDate, a TermEndDate jako součást analyze document požadavku.
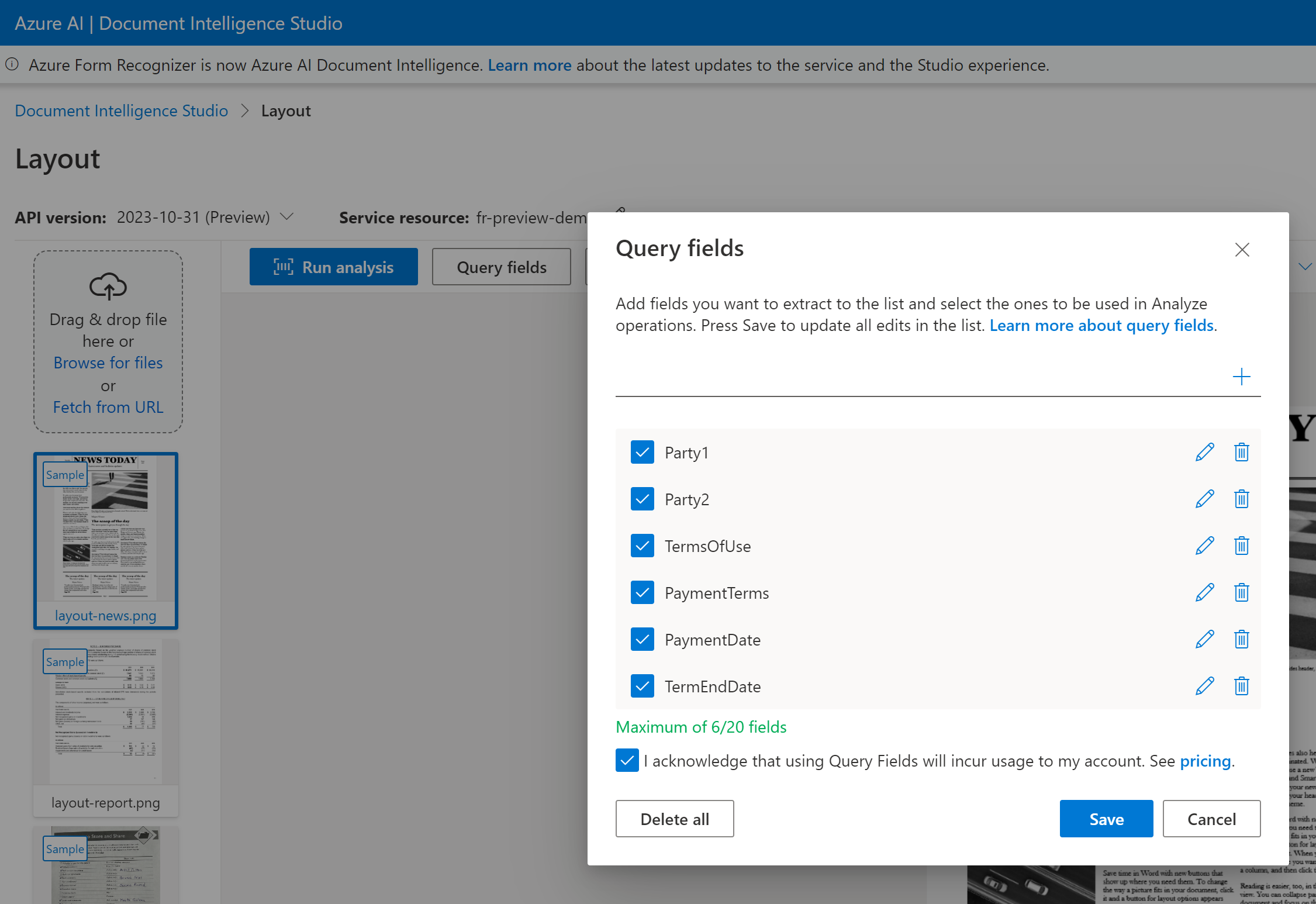
Funkce Document Intelligence dokáže analyzovat a extrahovat data polí a vracet hodnoty ve strukturovaném výstupu JSON.
Kromě polí dotazu odpověď zahrnuje text, tabulky, značky výběru a další relevantní data.
{your-resource-endpoint}.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-layout:analyze?api-version=2024-11-30&features=queryFields&queryFields=TERMS
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")
Address: 1 Redmond way Suite 6000 Redmond, WA Sunnayvale, 99243
Invoice number: 34278587
Další kroky