Model rozložení Document Intelligence
Tento obsah se vztahuje na: ![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Model rozložení Document Intelligence je pokročilé rozhraní API pro analýzu dokumentů založené na strojovém učení dostupné v cloudu Document Intelligence. Umožňuje přijímat dokumenty v různých formátech a vracet strukturované datové reprezentace dokumentů. Kombinuje vylepšenou verzi našich výkonných funkcí optického rozpoznávání znaků (OCR) s modely hloubkového učení k extrakci textu, tabulek, výběrových značek a struktury dokumentu.
Analýza rozložení dokumentu (v4)
Analýza rozložení struktury dokumentů je proces analýzy dokumentu za účelem extrakce oblastí zájmu a jejich vzájemných vztahů. Cílem je extrahovat text a strukturální prvky ze stránky, aby se vytvořily lepší sémantické modely porozumění. Rozložení dokumentu má dva typy rolí:
- Geometrické role: Příklady geometrických rolí jsou text, tabulky, obrázky a značky výběru.
- Logické role: Názvy, nadpisy a zápatí jsou příklady logických rolí textu.
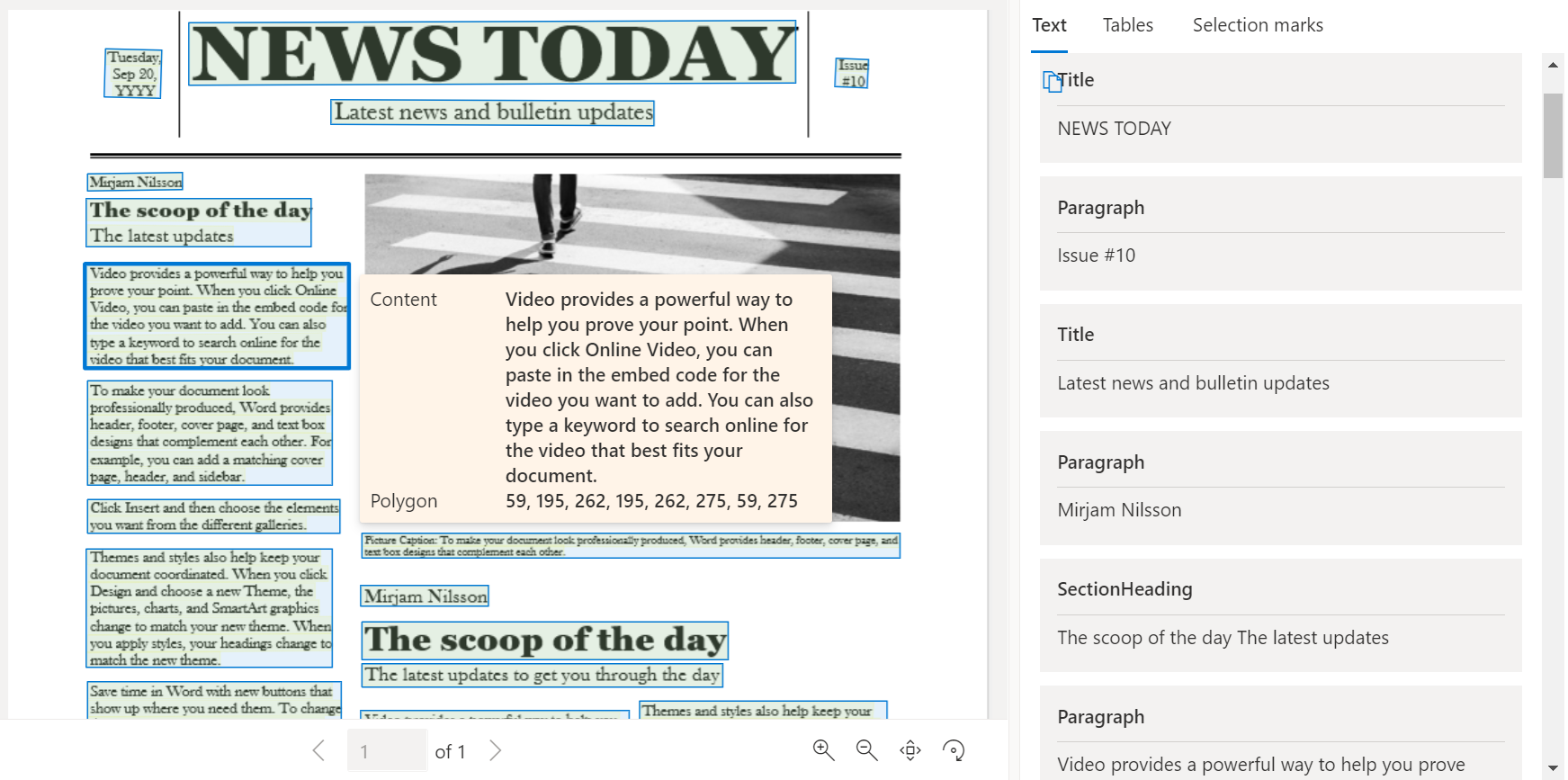
Následující obrázek znázorňuje typické součásti na obrázku ukázkové stránky.

Možnosti vývoje (v4)
Document Intelligence v4.0: 2024-11-30 (GA) podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model rozložení | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravené rozložení |
Požadavky na vstup (v4)
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
Začínáme s modelem rozložení
Podívejte se, jak se data, včetně textu, tabulek, záhlaví tabulky, značek výběru a informací o struktuře extrahují z dokumentů pomocí funkce Document Intelligence. Potřebujete následující zdroje informací:
Předplatné Azure – můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.
Poznámka:
Document Intelligence Studio je k dispozici s rozhraními API verze 3.0 a novějšími verzemi.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio
Na domovské stránce nástroje Document Intelligence Studio vyberte Rozložení.
Můžete analyzovat ukázkový dokument nebo nahrát vlastní soubory.
Vyberte tlačítko Spustit analýzu a v případě potřeby nakonfigurujte možnosti Analyzovat:

Podporované jazyky
Úplný seznam podporovaných jazyků najdete na stránce s modely analýzy dokumentů.
Extrakce dat (v4)
Model rozložení extrahuje text, značky výběru, tabulky, odstavce a typy odstavců (roles) z dokumentů.
Poznámka:
Document Intelligence v4.0 (2024-11-30 (GA)) a novější podporují soubory Microsoft Office (DOCX, XLSX, PPTX) a HTML. Následující funkce nejsou podporovány:
- Každý objekt stránky neobsahuje žádný úhel, šířku/výšku a jednotku.
- Pro každý zjištěný objekt neexistuje žádná ohraničení mnohoúhelníku ani ohraničující oblasti.
- Rozsah stránek (
pages) není podporován jako parametr. - Žádný
linesobjekt.
Stránky
Kolekce stránek je seznam stránek v dokumentu. Každá stránka je reprezentována postupně v dokumentu a .. /zahrnuje úhel orientace označující, zda je stránka otočena a šířka a výška (rozměry v pixelech). Jednotky stránky ve výstupu modelu se počítají, jak je znázorněno níže:
| Formát souboru | Vypočítaná jednotka stránky | Celkový počet stránek |
|---|---|---|
| Obrázky (JPEG/JPG, PNG, BMP, HEIF) | Každý obrázek = 1 jednotka stránky | Celkový počet obrázků |
| Každá stránka v PDF = 1 jednotka stránky | Total pages in the PDF | |
| TIFF | Každý obrázek v jednotce TIFF = 1 stránka | Celkový počet obrázků ve formátu TIFF |
| Word (DOCX) | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
| Excel (XLSX) | Každý list = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet listů |
| PowerPoint (PPTX) | Každý snímek = 1 jednotka stránky, vložené nebo propojené obrázky se nepodporují. | Celkový počet snímků |
| HTML | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Extrahování vybraných stránek z dokumentů
U velkých vícestrákových dokumentů použijte pages parametr dotazu k označení konkrétních čísel stránek nebo rozsahů stránek pro extrakci textu.
Odstavce
Model rozložení extrahuje všechny identifikované bloky textu v paragraphs kolekci jako objekt nejvyšší úrovně v části analyzeResults. Každá položka v této kolekci představuje textový blok a .. /obsahuje extrahovaný text jakocontenta ohraničující polygon souřadnice. Informace span ukazují na fragment textu v rámci vlastnosti nejvyšší úrovně content , která obsahuje celý text z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Role odstavce
Nová detekce objektů stránky založená na strojovém učení extrahuje logické role, jako jsou názvy, nadpisy oddílů, záhlaví stránek, zápatí stránek a další. Model rozložení funkce Document Intelligence přiřazuje určité textové bloky v paragraphs kolekci se speciální rolí nebo typem předpověděným modelem. Nejlepší je použít role odstavců s nestrukturovanými dokumenty, které vám pomůžou pochopit rozložení extrahovaného obsahu pro bohatší sémantickou analýzu. Podporují se následující role odstavců:
| Předpovězená role | Popis | Podporované typy souborů |
|---|---|---|
title |
Hlavní nadpisy na stránce | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Jedna nebo více podnadpisů na stránce | pdf, image, docx, xlsx, html |
footnote |
Text v dolní části stránky | pdf, obrázek |
pageHeader |
Text poblíž horního okraje stránky | pdf, obrázek, docx |
pageFooter |
Text poblíž dolního okraje stránky | pdf, image, docx, pptx, html |
pageNumber |
Číslo stránky | pdf, obrázek |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Text, řádky a slova
Model rozložení dokumentu v nástroji Document Intelligence extrahuje text tištěného a rukou psaného stylu jako lines a words. Kolekce styles .. /obsahuje jakýkoli ručně psaný styl čar, pokud jsou zjištěny spolu s rozsahy odkazujícími na přidružený text. Tato funkce se vztahuje na podporované ručně psané jazyky.
Pro Microsoft Word, Excel, PowerPoint a HTML, Document Intelligence v4.0 2024-11-30 (GA) Layout model extrahuje veškerý vložený text tak, jak je. Texty se extrahují jako slova a odstavce. Vložené obrázky nejsou podporované.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Ručně psaný styl pro řádky textu
Odpověď .. /zahrnuje klasifikaci, zda je každý řádek textu ve stylu rukopisu nebo ne, spolu s skóre spolehlivosti. Další informace. Viz podpora ručně psaného jazyka. Následující příklad ukazuje příklad fragmentu kódu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Pokud povolíte funkci doplňku font/style, získáte také výsledek písma a stylu jako součást objektustyles.
Značky výběru
Model rozložení také extrahuje značky výběru z dokumentů. Extrahované značky výběru se zobrazí v kolekci pages pro každou stránku. Zahrnují ohraničující polygon, confidencea výběr state (selected/unselected). Textová reprezentace (tj :selected: . a :unselected) je také zahrnuta jako počáteční index (offset) a length odkazuje na vlastnost nejvyšší úrovně content , která obsahuje celý text z dokumentu.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Tabulky
Extrakce tabulek je klíčovým požadavkem pro zpracování dokumentů obsahujících velké objemy dat, které jsou obvykle formátované jako tabulky. Model rozložení extrahuje tabulky v pageResults části výstupu JSON. Extrahované informace o tabulce .. /zahrnuje počet sloupců a řádků, rozsah řádků a rozsah sloupců. Každá buňka s ohraničující mnohoúhelníkem je výstupem spolu s informacemi, jestli je oblast rozpoznána jako columnHeader nebo ne. Model podporuje extrakci tabulek, které jsou otočené. Každá buňka tabulky obsahuje index řádků a sloupců a ohraničující souřadnice mnohoúhelníku. Pro text buňky model vypíše span informace obsahující počáteční index (offset). Model také vypíše length obsah nejvyšší úrovně, který obsahuje celý text z dokumentu.
Při použití funkce extrakce balíků document intelligence je potřeba vzít v úvahu několik faktorů:
Jsou data, která chcete extrahovat jako tabulku, a je struktura tabulky smysluplná?
Dají se data vejít do dvojrozměrné mřížky, pokud data nejsou ve formátu tabulky?
Pokrývají vaše tabulky více stránek? Pokud ano, abyste nemuseli všechny stránky označovat, rozdělte soubor PDF na stránky před odesláním do funkce Document Intelligence. Po analýze po zpracování stránek do jedné tabulky.
Pokud vytváříte vlastní modely, projděte si tabulková pole . Dynamické tabulky mají pro každý sloupec proměnlivý počet řádků. Pevné tabulky mají konstantní počet řádků pro každý sloupec.
Poznámka:
- Analýza tabulky není podporována, pokud je vstupní soubor XLSX.
- V 30. 2024.11.30 (GA) pokrývají ohraničující oblasti pro obrázky a tabulky pouze základní obsah a vyloučí přidružené titulky a poznámky pod čarou.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Výstup do formátu markdownu
Rozhraní API rozložení může vyextrahovaný text ve formátu Markdownu vyextrahovat. outputContentFormat=markdown Použijte k určení výstupního formátu v markdownu. Obsah Markdownu je výstupem v rámci oddílu content .
Poznámka:
U verze 4.0 2024-11-30 (GA) se reprezentace tabulek změní na tabulky HTML, aby bylo možné vykreslovat sloučené buňky, záhlaví s více řádky atd. Další související změnou je použití znaků ☒ zaškrtávacího políčka Unicode a ☐ pro značky výběru místo :selected: a :unselected:. Všimněte si, že to znamená, že obsah polí značky výběru bude obsahovat :selected: i když jejich rozsahy odkazují na znaky Unicode v rozsahu nejvyšší úrovně.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Čísla
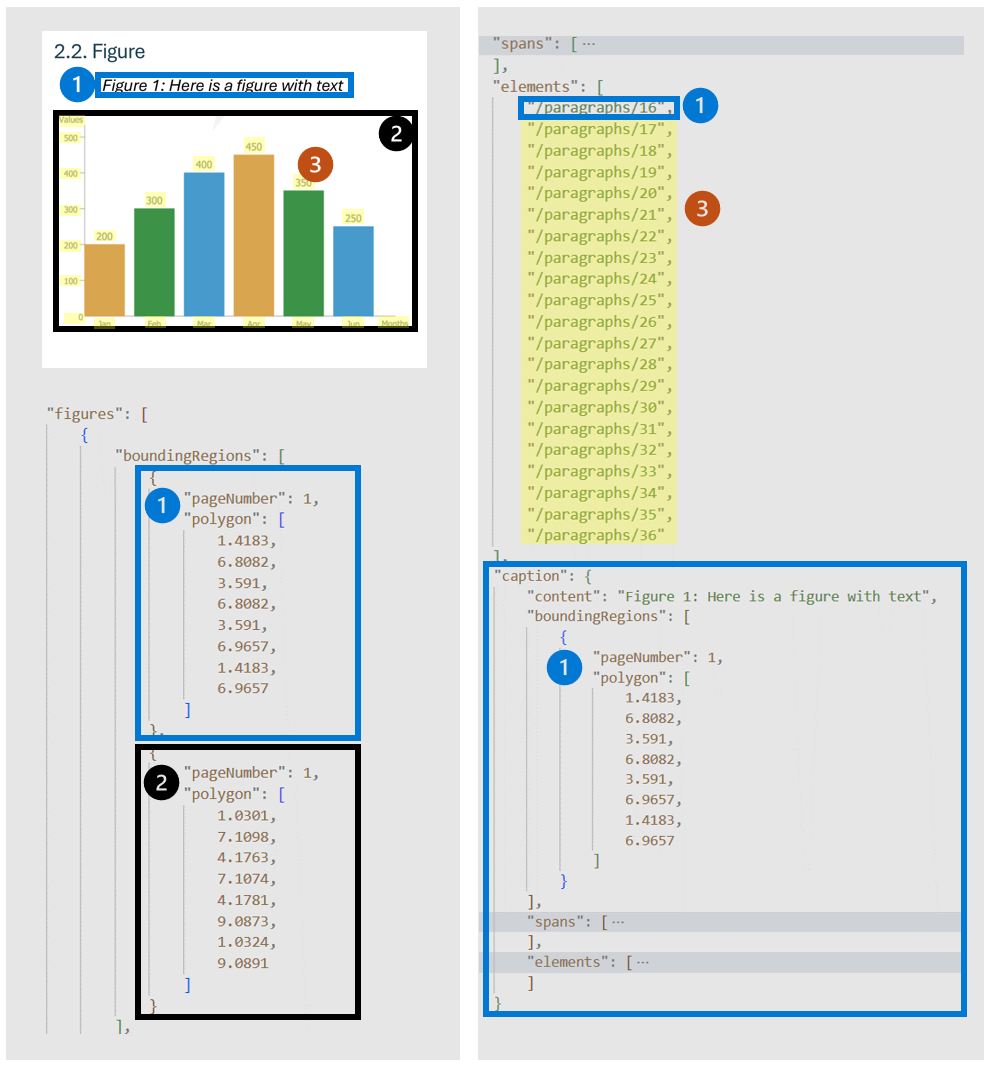
Obrázky (grafy, obrázky) v dokumentech hrají zásadní roli při doplňování a vylepšování textového obsahu a poskytují vizuální reprezentace, které pomáhají porozumět složitým informacím. Objekt obrázků zjištěný modelem rozložení má klíčové vlastnosti, jako boundingRegions jsou (prostorová umístění obrázku na stránkách dokumentu, včetně čísla stránky a mnohoúhelníku, které znázorňují hranici obrázku), spans (podrobnosti o rozsahu textu souvisejícího s obrázkem, určení jejich posunů a délek v textu dokumentu. Toto připojení pomáhá při přidružování obrázku k příslušnému textovému kontextu) elements (identifikátory textových prvků nebo odstavců v dokumentu, které souvisejí s obrázkem nebo popisují) a caption pokud nějaké existují.
Pokud je během počáteční operace analýzy zadán výstup =obrázky, služba generuje oříznuté obrázky pro všechny zjištěné obrázky, ke kterým je možné získat přístup./analyeResults/{resultId}/figures/{figureId}
FigureId je součástí každého objektu obrázku, který následuje po nezdokumentované konvenci {pageNumber}.{figureIndex} , kde figureIndex se obnoví na jednu stránku.
Poznámka:
V případě verze 4.0 2024-11-30 (GA) pokrývají ohraničující oblasti pro obrázky a tabulky pouze základní obsah a vyloučí přidružené titulky a poznámky pod čarou.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Oddíly
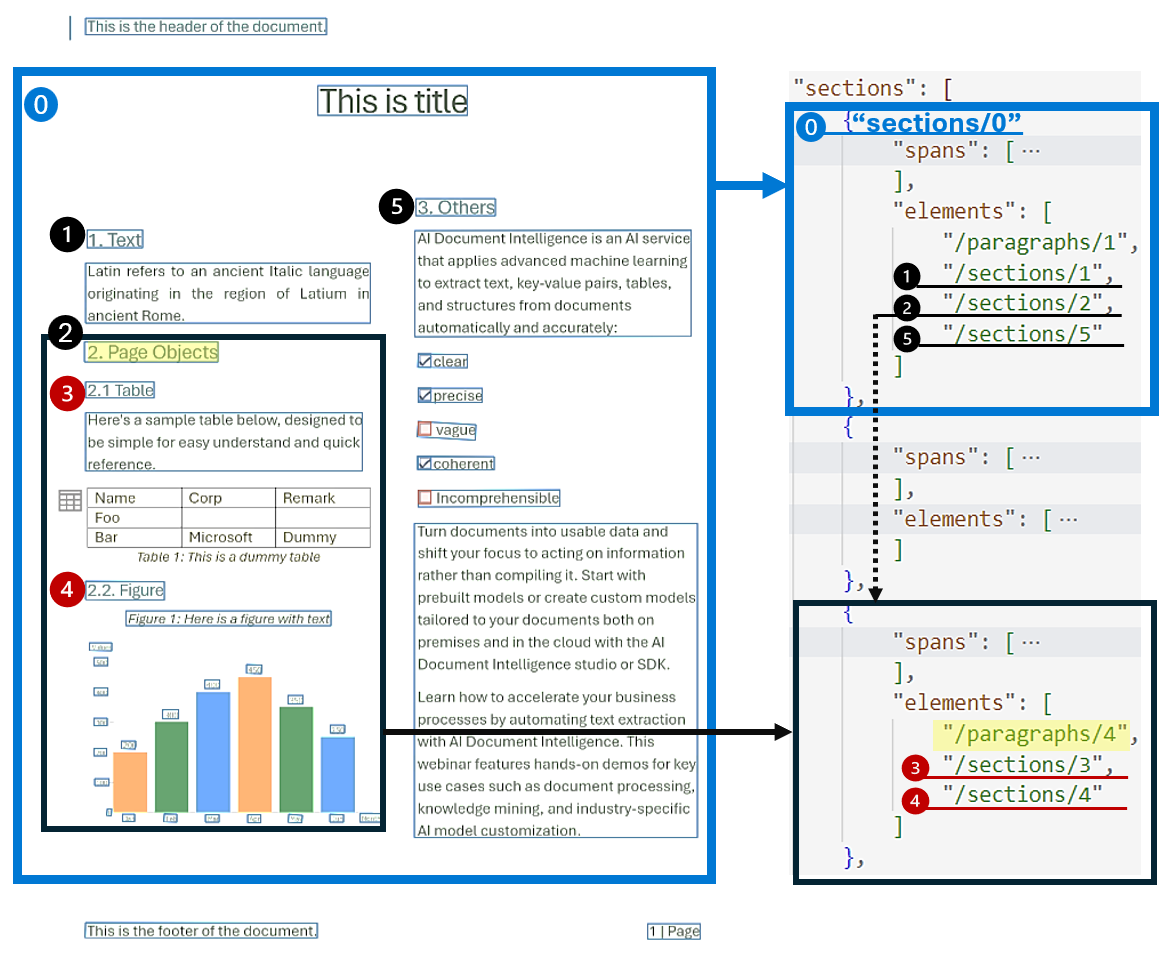
Hierarchická analýza struktury dokumentů je klíčová při uspořádání, pochopení a zpracování rozsáhlých dokumentů. Tento přístup je nezbytný pro séanticky segmentace dlouhých dokumentů, aby se zvýšila porozumění, usnadnila navigace a zlepšila načítání informací. Nástup načítání rozšířené generace (RAG) v dokumentu generující AI podtržítka význam hierarchické analýzy struktury dokumentů. Model rozložení podporuje oddíly a pododdíly ve výstupu, které identifikují vztah oddílů a objektů v jednotlivých oddílech. Hierarchická struktura se udržuje v elements každé části. Pomocí výstupu můžete formát markdownu snadno získat oddíly a pododdíly v markdownu.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Tento obsah se vztahuje na: ![]() v2.1 | Nejnovější verze:
v2.1 | Nejnovější verze: ![]() v4.0 (GA)
v4.0 (GA)
Model rozložení Document Intelligence je pokročilé rozhraní API pro analýzu dokumentů založené na strojovém učení dostupné v cloudu Document Intelligence. Umožňuje přijímat dokumenty v různých formátech a vracet strukturované datové reprezentace dokumentů. Kombinuje vylepšenou verzi našich výkonných funkcí optického rozpoznávání znaků (OCR) s modely hloubkového učení k extrakci textu, tabulek, výběrových značek a struktury dokumentu.
Analýza rozložení dokumentu
Analýza rozložení struktury dokumentů je proces analýzy dokumentu za účelem extrakce oblastí zájmu a jejich vzájemných vztahů. Cílem je extrahovat text a strukturální prvky ze stránky, aby se vytvořily lepší sémantické modely porozumění. Rozložení dokumentu má dva typy rolí:
- Geometrické role: Příklady geometrických rolí jsou text, tabulky, obrázky a značky výběru.
- Logické role: Názvy, nadpisy a zápatí jsou příklady logických rolí textu.
Následující obrázek znázorňuje typické součásti na obrázku ukázkové stránky.
Možnosti vývoje
Document Intelligence v3.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model rozložení | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravené rozložení |
Document Intelligence v3.0 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model rozložení | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravené rozložení |
Document Intelligence v2.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací |
|---|---|
| Model rozložení | • Nástroj pro popisování document intelligence• REST API • sada SDK klientské knihovny• Kontejner Document Intelligence Dockeru |
Požadavky na vstup
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
- Podporované formáty souborů: JPEG, PNG, PDF a TIFF.
- Podporovaný počet stránek: Pro PDF a TIFF se zpracovává až 2 000 stránek. Pro předplatitele úrovně Free se zpracovávají pouze první dvě stránky.
- Podporovaná velikost souboru: Velikost souboru musí být menší než 50 MB a rozměry nejméně 50 × 50 pixelů a maximálně 10 000 × 10 000 pixelů.
Začínáme s modelem rozložení
Podívejte se, jak se data, včetně textu, tabulek, záhlaví tabulky, značek výběru a informací o struktuře extrahují z dokumentů pomocí funkce Document Intelligence. Potřebujete následující zdroje informací:
Předplatné Azure – můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.
Poznámka:
Document Intelligence Studio je k dispozici s rozhraními API verze 3.0 a novějšími verzemi.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio
Na domovské stránce nástroje Document Intelligence Studio vyberte Rozložení.
Můžete analyzovat ukázkový dokument nebo nahrát vlastní soubory.
Vyberte tlačítko Spustit analýzu a v případě potřeby nakonfigurujte možnosti Analyzovat:
Nástroj Document Intelligence Sample Labeling
Na domovské stránce ukázkového nástroje vyberte Použít rozložení k získání textu, tabulek a značek výběru.
Do pole koncový bod služby Document Intelligence vložte koncový bod, který jste získali s předplatným Document Intelligence.
Do pole s klíčem vložte klíč, který jste získali z prostředku Document Intelligence.
V poli Zdroj vyberte adresu URL z rozevírací nabídky. Můžete použít náš ukázkový dokument:
Vyberte tlačítko Načíst.
Vyberte Spustit rozložení. Nástroj Document Intelligence Sample Labeling volá
Analyze Layoutrozhraní API k analýze dokumentu.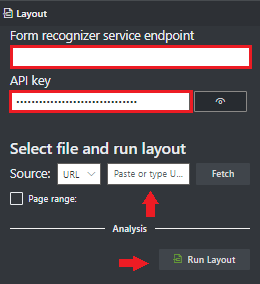
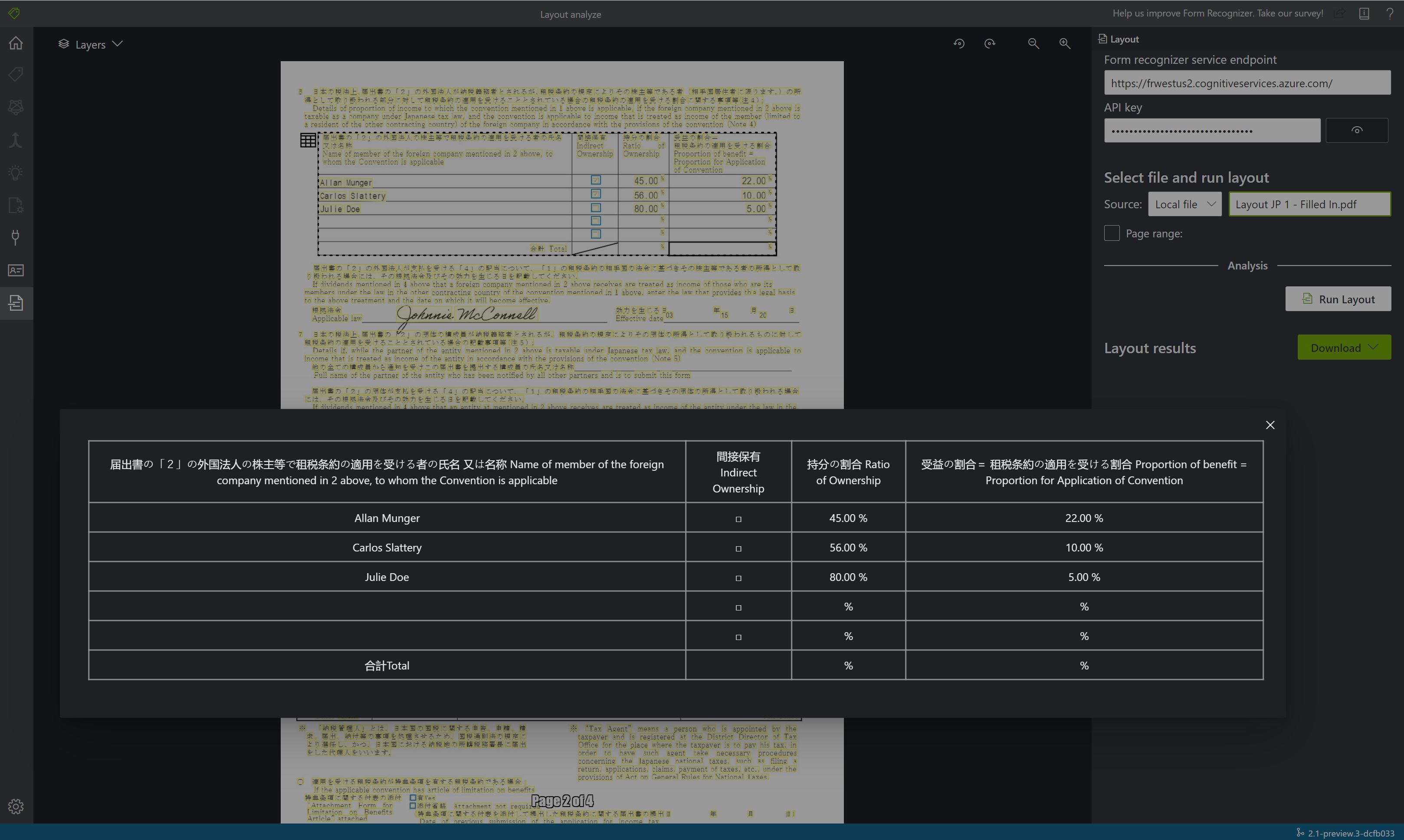
Prohlédněte si výsledky – podívejte se na zvýrazněný extrahovaný text, zjištěné značky výběru a zjištěné tabulky.
{kind=link}
Podporované jazyky a národní prostředí
Úplný seznam podporovaných jazyků najdete na stránce s modely analýzy dokumentů.
Document Intelligence v2.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací |
|---|---|
| Rozhraní API rozložení | • Nástroj pro popisování document intelligence• REST API • sada SDK klientské knihovny• Kontejner Document Intelligence Dockeru |
Extrakce dat
Model rozložení extrahuje text, značky výběru, tabulky, odstavce a typy odstavců (roles) z dokumentů.
Poznámka:
Document Intelligence v4.0 2024-11-30 (GA) podporuje soubory Microsoft Office (DOCX, XLSX, PPTX) a HTML. Následující funkce nejsou podporovány:
- Každý objekt stránky neobsahuje žádný úhel, šířku/výšku a jednotku.
- Pro každý zjištěný objekt neexistuje žádná ohraničení mnohoúhelníku ani ohraničující oblasti.
- Rozsah stránek (
pages) není podporován jako parametr. - Žádný
linesobjekt.
Stránky
Kolekce stránek je seznam stránek v dokumentu. Každá stránka je reprezentována postupně v dokumentu a .. /zahrnuje úhel orientace označující, zda je stránka otočena a šířka a výška (rozměry v pixelech). Jednotky stránky ve výstupu modelu se počítají, jak je znázorněno níže:
| Formát souboru | Vypočítaná jednotka stránky | Celkový počet stránek |
|---|---|---|
| Obrázky (JPEG/JPG, PNG, BMP, HEIF) | Každý obrázek = 1 jednotka stránky | Celkový počet obrázků |
| Každá stránka v PDF = 1 jednotka stránky | Total pages in the PDF | |
| TIFF | Každý obrázek v jednotce TIFF = 1 stránka | Celkový počet obrázků ve formátu TIFF |
| Word (DOCX) | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
| Excel (XLSX) | Každý list = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet listů |
| PowerPoint (PPTX) | Každý snímek = 1 jednotka stránky, vložené nebo propojené obrázky se nepodporují. | Celkový počet snímků |
| HTML | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Extrahování vybraných stránek z dokumentů
U velkých vícestrákových dokumentů použijte pages parametr dotazu k označení konkrétních čísel stránek nebo rozsahů stránek pro extrakci textu.
Odstavce
Model rozložení extrahuje všechny identifikované bloky textu v paragraphs kolekci jako objekt nejvyšší úrovně v části analyzeResults. Každá položka v této kolekci představuje textový blok a .. /obsahuje extrahovaný text jakocontenta ohraničující polygon souřadnice. Informace span ukazují na fragment textu v rámci vlastnosti nejvyšší úrovně content , která obsahuje celý text z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Role odstavce
Nová detekce objektů stránky založená na strojovém učení extrahuje logické role, jako jsou názvy, nadpisy oddílů, záhlaví stránek, zápatí stránek a další. Model rozložení funkce Document Intelligence přiřazuje určité textové bloky v paragraphs kolekci se speciální rolí nebo typem předpověděným modelem. Nejlepší je použít role odstavců s nestrukturovanými dokumenty, které vám pomůžou pochopit rozložení extrahovaného obsahu pro bohatší sémantickou analýzu. Podporují se následující role odstavců:
| Předpovězená role | Popis | Podporované typy souborů |
|---|---|---|
title |
Hlavní nadpisy na stránce | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Jedna nebo více podnadpisů na stránce | pdf, image, docx, xlsx, html |
footnote |
Text v dolní části stránky | pdf, obrázek |
pageHeader |
Text poblíž horního okraje stránky | pdf, obrázek, docx |
pageFooter |
Text poblíž dolního okraje stránky | pdf, image, docx, pptx, html |
pageNumber |
Číslo stránky | pdf, obrázek |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Text, řádky a slova
Model rozložení dokumentu v nástroji Document Intelligence extrahuje text tištěného a rukou psaného stylu jako lines a words. Kolekce styles .. /obsahuje jakýkoli ručně psaný styl čar, pokud jsou zjištěny spolu s rozsahy odkazujícími na přidružený text. Tato funkce se vztahuje na podporované ručně psané jazyky.
Pro Microsoft Word, Excel, PowerPoint a HTML, Document Intelligence v4.0 2024-11-30 (GA) Layout model extrahuje veškerý vložený text tak, jak je. Texty se extrahují jako slova a odstavce. Vložené obrázky nejsou podporované.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Ručně psaný styl pro řádky textu
Odpověď .. /zahrnuje klasifikaci, zda je každý řádek textu ve stylu rukopisu nebo ne, spolu s skóre spolehlivosti. Další informace. Viz podpora ručně psaného jazyka. Následující příklad ukazuje příklad fragmentu kódu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Pokud povolíte funkci doplňku font/style, získáte také výsledek písma a stylu jako součást objektustyles.
Značky výběru
Model rozložení také extrahuje značky výběru z dokumentů. Extrahované značky výběru se zobrazí v kolekci pages pro každou stránku. Zahrnují ohraničující polygon, confidencea výběr state (selected/unselected). Textová reprezentace (tj :selected: . a :unselected) je také zahrnuta jako počáteční index (offset) a length odkazuje na vlastnost nejvyšší úrovně content , která obsahuje celý text z dokumentu.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tabulky
Extrakce tabulek je klíčovým požadavkem pro zpracování dokumentů obsahujících velké objemy dat, které jsou obvykle formátované jako tabulky. Model rozložení extrahuje tabulky v pageResults části výstupu JSON. Extrahované informace o tabulce .. /zahrnuje počet sloupců a řádků, rozsah řádků a rozsah sloupců. Každá buňka s ohraničující mnohoúhelníkem je výstupem spolu s informacemi, jestli je oblast rozpoznána jako columnHeader nebo ne. Model podporuje extrakci tabulek, které jsou otočené. Každá buňka tabulky obsahuje index řádků a sloupců a ohraničující souřadnice mnohoúhelníku. Pro text buňky model vypíše span informace obsahující počáteční index (offset). Model také vypíše length obsah nejvyšší úrovně, který obsahuje celý text z dokumentu.
Při použití funkce extrakce balíků document intelligence je potřeba vzít v úvahu několik faktorů:
Jsou data, která chcete extrahovat jako tabulku, a je struktura tabulky smysluplná?
Dají se data vejít do dvojrozměrné mřížky, pokud data nejsou ve formátu tabulky?
Pokrývají vaše tabulky více stránek? Pokud ano, abyste nemuseli všechny stránky označovat, rozdělte soubor PDF na stránky před odesláním do funkce Document Intelligence. Po analýze po zpracování stránek do jedné tabulky.
Pokud vytváříte vlastní modely, projděte si tabulková pole . Dynamické tabulky mají pro každý sloupec proměnlivý počet řádků. Pevné tabulky mají konstantní počet řádků pro každý sloupec.
Poznámka:
- Analýza tabulky není podporována, pokud je vstupní soubor XLSX.
- Funkce Document Intelligence v4.0 2024-11-30 (GA) podporuje ohraničující oblasti pro obrázky a tabulky, které pokrývají pouze základní obsah a vyloučení přidružených titulků a poznámek pod čarou.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Poznámky (dostupné jenom v 2023-02-28-preview rozhraní API))
Model rozložení extrahuje poznámky v dokumentech, jako jsou kontroly a křížky. Odpověď .. /zahrnuje druh anotace spolu s skóre spolehlivosti a ohraničující mnohoúhelník.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Výstup přirozeného pořadí čtení (pouze latinka)
Pomocí parametru dotazu můžete zadat pořadí, ve kterém jsou textové řádky výstupem readingOrder . Použije se natural pro popisnější výstup pořadí čtení, jak je znázorněno v následujícím příkladu. Tato funkce je podporována pouze pro jazyky latinky.

Výběr čísel stránek nebo oblastí pro extrakci textu
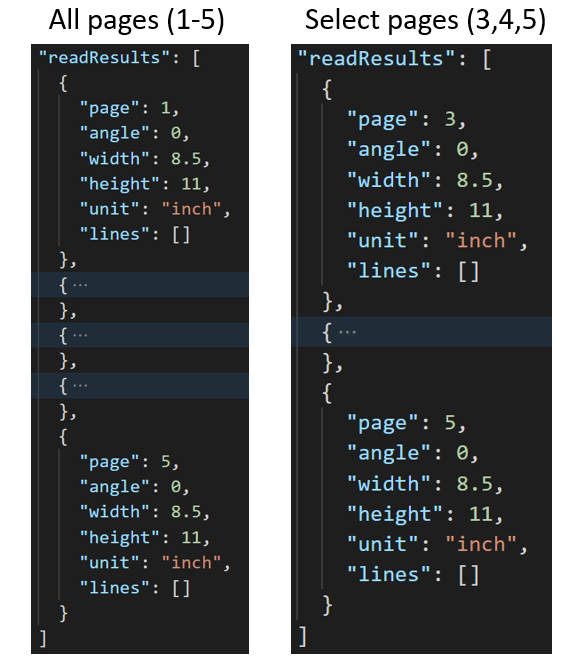
U velkých vícestrákových dokumentů použijte pages parametr dotazu k označení konkrétních čísel stránek nebo rozsahů stránek pro extrakci textu. Následující příklad ukazuje dokument s 10 stránkami s textem extrahovaným pro oba případy – všechny stránky (1–10) a vybrané stránky (3–6).
Operace Získání výsledku analýzy rozložení
Druhým krokem je volání operace Získat analýzu výsledku rozložení. Tato operace přebírá jako vstup ID výsledku, které Analyze Layout operace vytvořila. Vrátí odpověď JSON, která obsahuje pole stavu s následujícími možnými hodnotami.
| Pole | Typ | Možné hodnoty |
|---|---|---|
| stav | string | notStarted: Operace analýzy není spuštěna.running: Probíhá operace analýzy. failed: Operace analýzy selhala. succeeded: Operace analýzy byla úspěšná. |
Tuto operaci volejte iterativním způsobem, dokud nevrátí succeeded hodnotu. Pokud se chcete vyhnout překročení rychlosti žádostí za sekundu (RPS), použijte interval 3 až 5 sekund.
Pokud pole stavu obsahuje succeeded hodnotu, odpověď JSON .. /zahrnuje extrahované rozložení, text, tabulky a značky výběru. Extrahovaná data . /zahrnuje extrahované textové řádky a slova, ohraničující pole, vzhled textu s rukou psanou indikací, tabulkami a značkami výběru s vybranou/nevybranou.
Ručně psaná klasifikace pro textové řádky (jenom latinka)
Odpověď .. /zahrnuje klasifikaci, zda je každý řádek textu ve stylu rukopisu nebo ne, spolu s skóre spolehlivosti. Tato funkce je podporována pouze pro jazyky latinky. Následující příklad ukazuje rukou psanou klasifikaci textu na obrázku.

Ukázkový výstup JSON
Odpověď na operaci Get Analyze Layout Result je strukturovaná reprezentace dokumentu se všemi extrahovanými informacemi. Tady najdete ukázkový soubor dokumentu a výstup rozložení ukázky strukturovaného výstupu.
Výstup JSON má dvě části:
readResultsuzel obsahuje veškerý rozpoznaný text a značku výběru. Hierarchie textových prezentací je stránka, potom řádek a potom jednotlivá slova.pageResultsUzel obsahuje tabulky a buňky extrahované s ohraničujícími poli, jistotou a odkazem na řádky a slova v poli readResults.
Příklad výstupu
Text
Rozhraní API rozložení extrahuje text z dokumentů a obrázků s několika úhly a barvami textu. Přijímá fotky dokumentů, faxů, tištěných a/nebo rukou psaných (pouze v angličtině) a smíšených režimů. Text se extrahuje s informacemi zadanými na řádcích, slovech, ohraničujících polích, skóre spolehlivosti a stylu (ručně psané nebo jiné). Všechny textové informace jsou součástí readResults části výstupu JSON.
Tabulky se záhlavími
Rozhraní API rozložení extrahuje tabulky v pageResults části výstupu JSON. Dokumenty lze naskenovat, fotografovat nebo digitalizovat. Tabulky můžou být složité se sloučenými buňkami nebo sloupci, s ohraničeními nebo bez ohraničení a s lichými úhly. Extrahované informace o tabulce .. /zahrnuje počet sloupců a řádků, rozsah řádků a rozsah sloupců. Každá buňka s ohraničujícím rámečkem je výstupem spolu s tím, jestli je oblast rozpoznána jako součást záhlaví nebo ne. Předpovězené buňky záhlaví modelu můžou zahrnovat více řádků a nemusí být nutně prvními řádky v tabulce. Pracují také s otočenými tabulkami. Každá buňka tabulky také .. /obsahuje celý text s odkazy na jednotlivá slova v oddílu readResults .
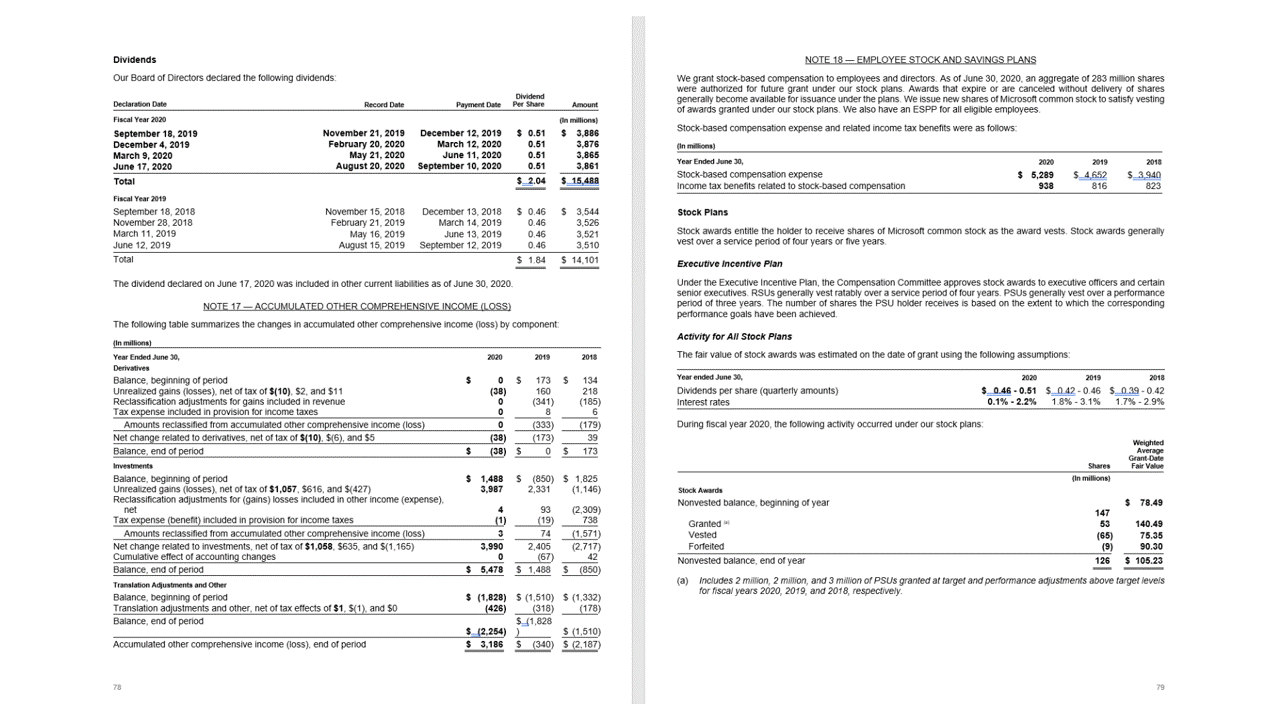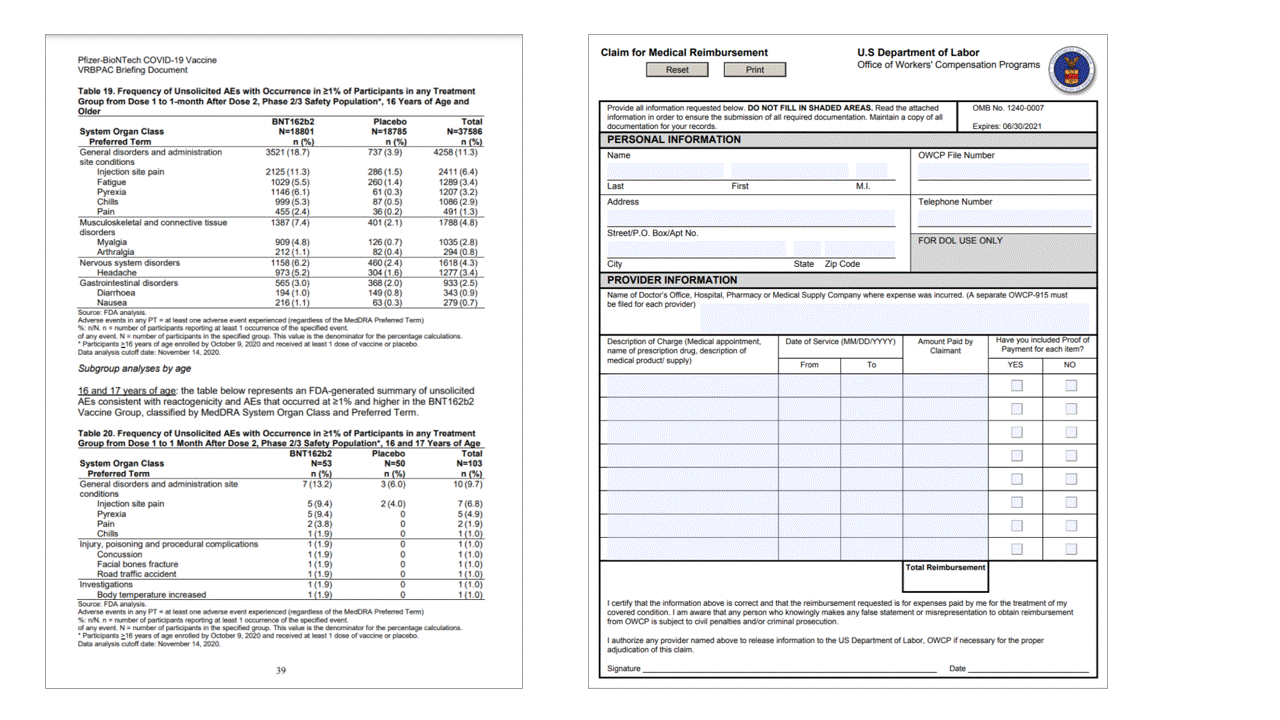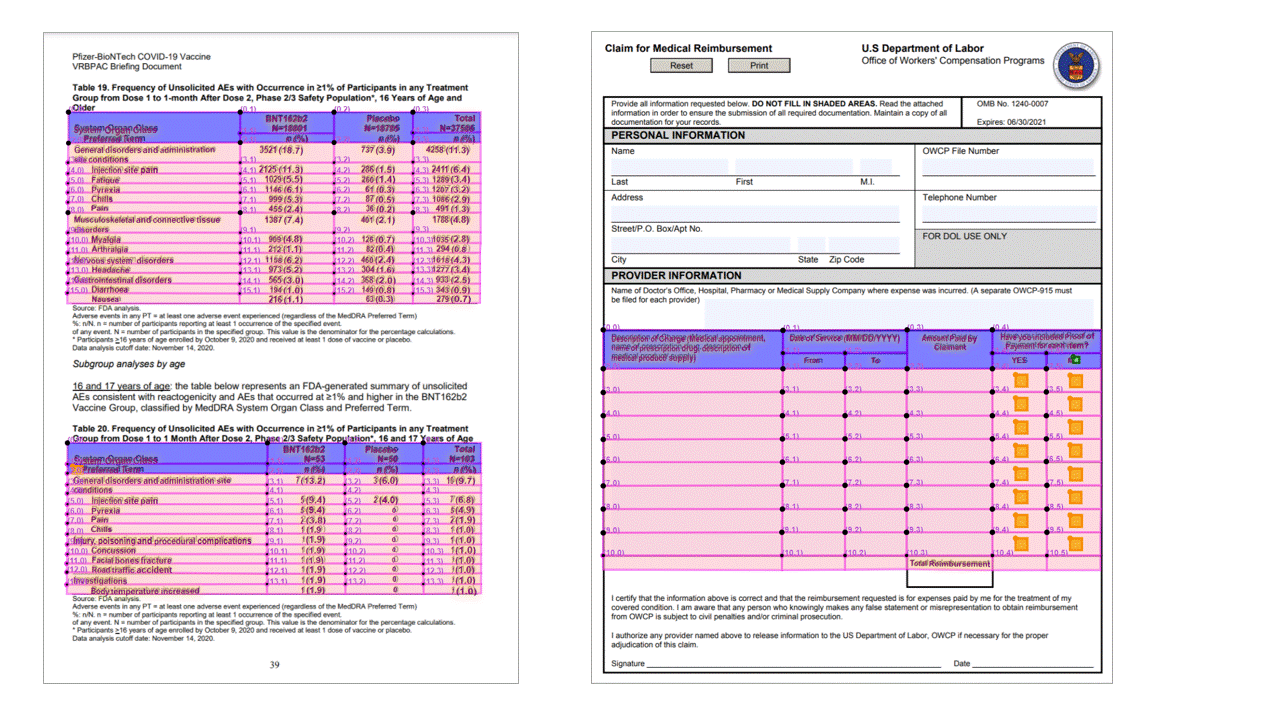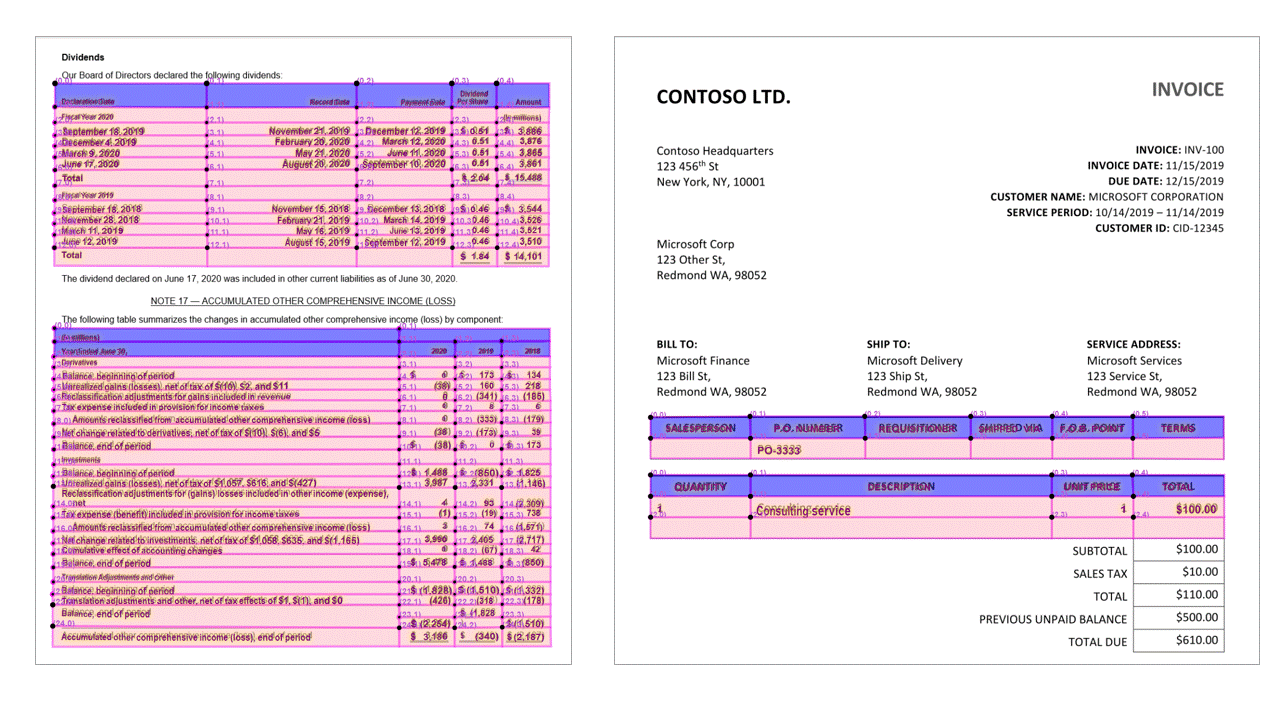
Značky výběru
Rozhraní API rozložení také extrahuje značky výběru z dokumentů. Extrahované značky výběru zahrnují ohraničující rámeček, spolehlivost a stav (vybrané nebo nevybrané). Informace o značce výběru se extrahují v readResults části výstupu JSON.
Průvodce migrací
- Postupujte podle našeho průvodce migrací Document Intelligence v3.1 a zjistěte, jak používat verzi v3.1 ve vašich aplikacích a pracovních postupech.
Další kroky
Naučte se zpracovávat vlastní formuláře a dokumenty pomocí nástroje Document Intelligence Studio.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.
Naučte se zpracovávat vlastní formuláře a dokumenty pomocí nástroje Popisování ukázek funkce Document Intelligence.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.