Model čtení funkce Document Intelligence
Tento obsah se vztahuje na:![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Tento obsah se vztahuje na:![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Poznámka:
Pro extrahování textu z externích obrázků, jako jsou popisky, znaky ulice a plakáty, použijte funkci Analýzy obrázků Azure AI v4.0 optimalizovanou pro obecné obrázky bez dokumentu s využitím synchronního rozhraní API s vylepšeným výkonem, které usnadňuje vkládání OCR ve scénářích uživatelského prostředí v reálném čase.
Model OCR (Document Intelligence Read Optické rozpoznávání znaků) běží s vyšším rozlišením než Azure AI Vision Read a extrahuje tisk a rukou psaný text z dokumentů PDF a naskenovaných obrázků. Obsahuje také podporu pro extrahování textu z dokumentů Microsoft Wordu, Excelu, PowerPointu a HTML. Rozpozná odstavce, řádky textu, slova, umístění a jazyky. Model pro čtení je podkladovým modulem OCR pro další předem vytvořené modely document intelligence, jako jsou rozložení, obecný dokument, faktura, potvrzení, dokument identity (ID), karta zdravotní pojištění, W2 kromě vlastních modelů.
Co je optické rozpoznávání znaků?
Optické rozpoznávání znaků (OCR) pro dokumenty je optimalizované pro velké textové dokumenty ve více formátech souborů a globálních jazycích. Obsahuje funkce, jako je skenování obrázků dokumentů s vyšším rozlišením pro lepší zpracování menšího a zhuštěného textu; detekce odstavce; a správu vyplnitelných formulářů. Funkce OCR také zahrnují pokročilé scénáře, jako jsou pole s jedním znakem a přesná extrakce klíčových polí běžně zjištěných v fakturách, účtech a dalších předem připravených scénářích.
Možnosti vývoje (v4)
Document Intelligence v4.0: 2024-11-30 (GA) podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Čtení modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená čtení |
Požadavky na vstup (v4)
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
Začínáme s modelem čtení (v4)
Zkuste extrahovat text z formulářů a dokumentů pomocí nástroje Document Intelligence Studio. Potřebujete následující prostředky:
Předplatné Azure – můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.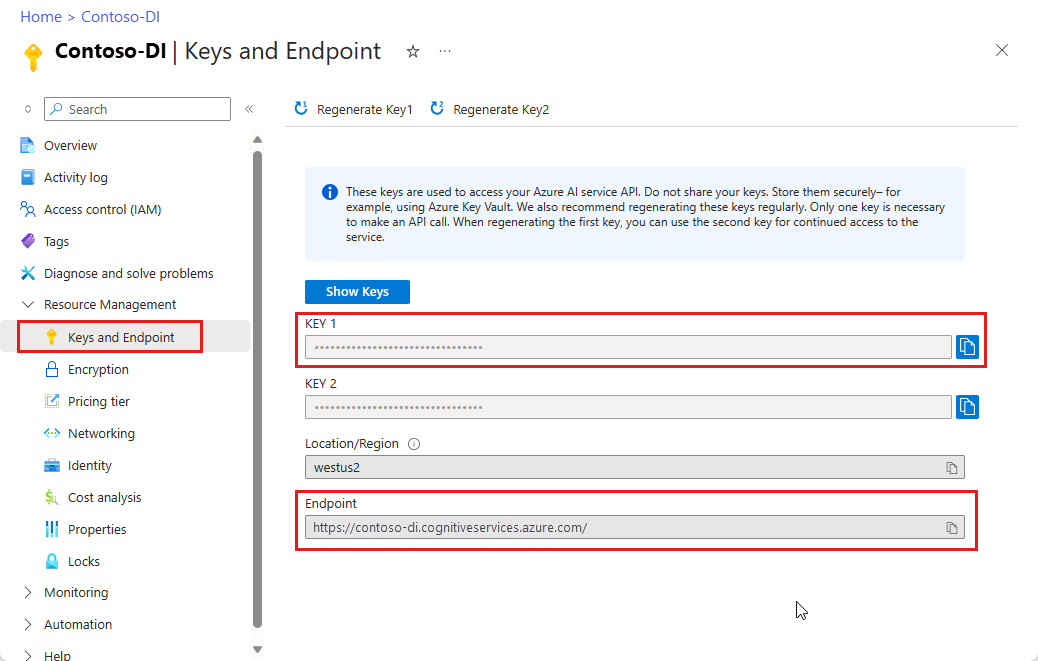
Poznámka:
Sada Document Intelligence Studio v současné době nepodporuje formáty souborů Microsoft Wordu, Excelu, PowerPointu a HTML.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio
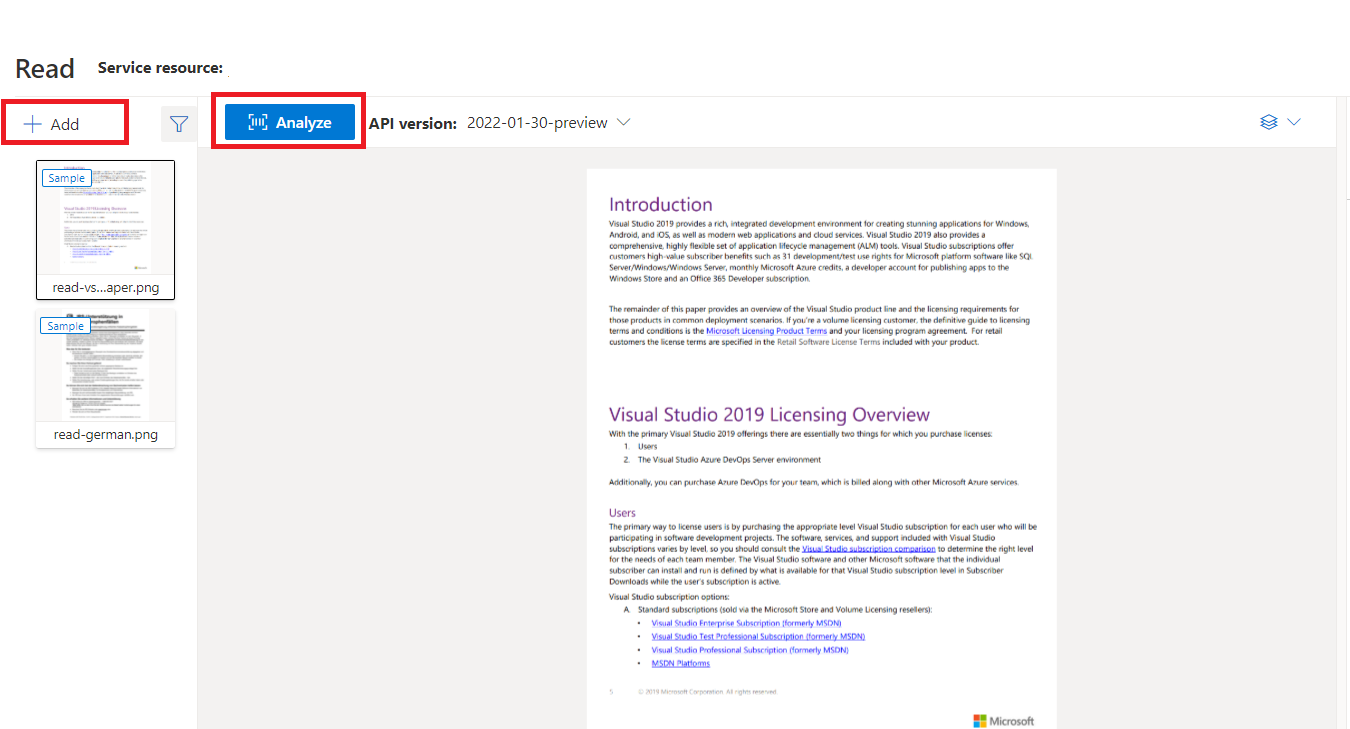
Na domovské stránce nástroje Document Intelligence Studio vyberte Číst.
Můžete analyzovat ukázkový dokument nebo nahrát vlastní soubory.
Vyberte tlačítko Spustit analýzu a v případě potřeby nakonfigurujte možnosti Analyzovat:

Podporované jazyky a národní prostředí (v4)
Úplný seznam podporovaných jazyků najdete na stránce s modely analýzy dokumentů.
Extrakce dat (v4)
Poznámka:
Soubor Microsoft Word a HTML jsou podporovány ve verzi 4.0. Ve srovnání s PDF a obrázky nejsou podporovány následující funkce:
- Každý objekt stránky neobsahuje žádný úhel, šířku/výšku a jednotku.
- Pro každý zjištěný objekt neexistuje žádná ohraničení mnohoúhelníku ani ohraničující oblasti.
- Rozsah stránek (
pages) není podporován jako parametr. - Žádný
linesobjekt.
Prohledávatelné soubory PDF
Funkce prohledávatelného PDF umožňuje převést analogové SOUBORY PDF, jako jsou naskenované soubory PDF, do PDF s vloženým textem. Vložený text umožňuje hloubkové vyhledávání textu v extrahovaném obsahu PDF tak, že překryjí zjištěné textové entity nad soubory obrázků.
Důležité
- V současné době je prohledávatelná funkce PDF podporována pouze pro čtení modelu
prebuilt-readOCR . Při použití této funkce zadejtemodelIdjakoprebuilt-read, protože jiné typy modelů vrátí chybu pro tuto verzi Preview. - Prohledávatelný PDF je součástí modelu GA
prebuilt-readverze 2024-11-30 bez dalších nákladů na generování prohledávatelného výstupu PDF.
Použití prohledávatelných souborů PDF
Pokud chcete použít prohledávatelný SOUBOR PDF, vytvořte POST požadavek pomocí Analyze operace a zadejte výstupní formát takto pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Hlasování o dokončení Analyze operace. Po dokončení operace vyžádejte GET požadavek na načtení formátu Analyze PDF výsledků operace.
Po úspěšném dokončení lze soubor PDF načíst a stáhnout jako application/pdf. Tato operace umožňuje přímé stažení vloženého textového formátu PDF místo formátu JSON s kódováním Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Parametr Pages
Kolekce stránek je seznam stránek v dokumentu. Každá stránka je v dokumentu reprezentována postupně a zahrnuje úhel orientace označující, jestli je stránka otočena, a šířku a výšku (rozměry v pixelech). Jednotky stránky ve výstupu modelu se počítají, jak je znázorněno níže:
| Formát souboru | Vypočítaná jednotka stránky | Celkový počet stránek |
|---|---|---|
| Obrázky (JPEG/JPG, PNG, BMP, HEIF) | Každý obrázek = 1 jednotka stránky | Celkový počet obrázků |
| Každá stránka v PDF = 1 jednotka stránky | Total pages in the PDF | |
| TIFF | Každý obrázek v jednotce TIFF = 1 stránka | Celkový počet obrázků ve formátu TIFF |
| Word (DOCX) | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
| Excel (XLSX) | Každý list = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet listů |
| PowerPoint (PPTX) | Každý snímek = 1 jednotka stránky, vložené nebo propojené obrázky se nepodporují. | Celkový počet snímků |
| HTML | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Použití stránek pro extrakci textu
U velkých vícestrákových dokumentů PDF použijte pages parametr dotazu k označení konkrétních čísel stránek nebo rozsahů stránek pro extrakci textu.
Extrahování odstavců
Model Read OCR v document Intelligence extrahuje všechny identifikované bloky textu v paragraphs kolekci jako objekt nejvyšší úrovně v části analyzeResults. Každá položka v této kolekci představuje blok textu a zahrnuje extrahovaný text jakocontent a ohraničující polygon souřadnice. Informace span ukazují na fragment textu v rámci vlastnosti nejvyšší úrovně content , která obsahuje celý text z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Extrakce textu, řádků a slov
Model Read OCR extrahuje text tištěného a rukou psaného stylu jako lines a words. Model vypíše ohraničující polygon souřadnice a confidence pro extrahovaná slova. Kolekce styles obsahuje všechny ručně psané styly čar, pokud jsou zjištěny spolu s rozsahy odkazujícími na přidružený text. Tato funkce se vztahuje na podporované ručně psané jazyky.
V případě Microsoft Wordu, Excelu, PowerPointu a HTML extrahuje model Document Intelligence Read v3.1 a novější verze veškerý vložený text tak, jak je. Texty jsou extenzované jako slova a odstavce. Vložené obrázky nejsou podporované.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Extrakce ručně psaného stylu
Odpověď zahrnuje klasifikaci, jestli je každý řádek textu ve stylu rukopisu nebo ne, spolu se skóre spolehlivosti. Další informace najdete v tématu podpora rukou psaného jazyka. Následující příklad ukazuje příklad fragmentu kódu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Pokud jste povolili funkci doplňku font/style, získáte také výsledek písma a stylu jako součást objektustyles.
Další kroky v4.0
Dokončení rychlého startu pro funkci Document Intelligence:
Prozkoumejte naše rozhraní REST API:
Další ukázky najdete na GitHubu:
Poznámka:
Pokud chcete extrahovat text z externích obrázků, jako jsou popisky, znaky ulice a plakáty, použijte funkci Analýzy obrázků Azure AI v4.0 optimalizovanou pro obecné obrázky bez dokumentu s vylepšeným synchronním rozhraním API s výkonem, které usnadňuje vkládání OCR do scénářů uživatelského prostředí.
Model OCR (Document Intelligence Read Optické rozpoznávání znaků) běží s vyšším rozlišením než Azure AI Vision Read a extrahuje tisk a rukou psaný text z dokumentů PDF a naskenovaných obrázků. Obsahuje také podporu pro extrahování textu z dokumentů Microsoft Wordu, Excelu, PowerPointu a HTML. Rozpozná odstavce, řádky textu, slova, umístění a jazyky. Model pro čtení je podkladovým modulem OCR pro další předem vytvořené modely document intelligence, jako jsou rozložení, obecný dokument, faktura, potvrzení, dokument identity (ID), karta zdravotní pojištění, W2 kromě vlastních modelů.
Co je OCR pro dokumenty?
Optické rozpoznávání znaků (OCR) pro dokumenty je optimalizované pro velké textové dokumenty ve více formátech souborů a globálních jazycích. Obsahuje funkce, jako je skenování obrázků dokumentů s vyšším rozlišením pro lepší zpracování menšího a zhuštěného textu; detekce odstavce; a správu vyplnitelných formulářů. Funkce OCR také zahrnují pokročilé scénáře, jako jsou pole s jedním znakem a přesná extrakce klíčových polí běžně zjištěných v fakturách, účtech a dalších předem připravených scénářích.
Možnosti vývoje
Document Intelligence v3.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Čtení modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená čtení |
Document Intelligence v3.0 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Čtení modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená čtení |
Požadavky na vstup
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
Začínáme s modelem čtení
Zkuste extrahovat text z formulářů a dokumentů pomocí nástroje Document Intelligence Studio. Potřebujete následující prostředky:
Předplatné Azure – můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.
Poznámka:
Sada Document Intelligence Studio v současné době nepodporuje formáty souborů Microsoft Wordu, Excelu, PowerPointu a HTML.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio
Na domovské stránce nástroje Document Intelligence Studio vyberte Číst.
Můžete analyzovat ukázkový dokument nebo nahrát vlastní soubory.
Vyberte tlačítko Spustit analýzu a v případě potřeby nakonfigurujte možnosti Analyzovat:
Podporované jazyky a národní prostředí
Úplný seznam podporovaných jazyků najdete na stránce s modely analýzy dokumentů.
Extrakce dat
Poznámka:
Soubor Microsoft Word a HTML jsou podporovány ve verzi 3.1 a novějších verzích. Ve srovnání s PDF a obrázky nejsou podporovány následující funkce:
- Každý objekt stránky neobsahuje žádný úhel, šířku/výšku a jednotku.
- Pro každý zjištěný objekt neexistuje žádná ohraničení mnohoúhelníku ani ohraničující oblasti.
- Rozsah stránek (
pages) není podporován jako parametr. - Žádný
linesobjekt.
Prohledávatelný SOUBOR PDF
Funkce prohledávatelného PDF umožňuje převést analogové SOUBORY PDF, jako jsou naskenované soubory PDF, do PDF s vloženým textem. Vložený text umožňuje hloubkové vyhledávání textu v extrahovaném obsahu PDF tak, že překryjí zjištěné textové entity nad soubory obrázků.
Důležité
- V současné době je prohledávatelná funkce PDF podporována pouze pro čtení modelu
prebuilt-readOCR . Při použití této funkce zadejtemodelIdjakoprebuilt-read, protože jiné typy modelů vrátí chybu. - Prohledávatelné PDF je součástí modelu 2024-11-30
prebuilt-readbez dalších nákladů na generování prohledávatelného výstupu PDF.- Formát PDF, který lze prohledávat, momentálně jako vstup podporuje jenom soubory PDF. Podpora jiných typů souborů, například souborů obrázků, bude k dispozici později.
Použití prohledávatelného PDF
Pokud chcete použít prohledávatelný SOUBOR PDF, vytvořte POST požadavek pomocí Analyze operace a zadejte výstupní formát takto pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Hlasování o dokončení Analyze operace. Po dokončení operace vyžádejte GET požadavek na načtení formátu Analyze PDF výsledků operace.
Po úspěšném dokončení lze soubor PDF načíst a stáhnout jako application/pdf. Tato operace umožňuje přímé stažení vloženého textového formátu PDF místo formátu JSON s kódováním Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Stránky
Kolekce stránek je seznam stránek v dokumentu. Každá stránka je v dokumentu reprezentována postupně a zahrnuje úhel orientace označující, jestli je stránka otočena, a šířku a výšku (rozměry v pixelech). Jednotky stránky ve výstupu modelu se počítají, jak je znázorněno níže:
| Formát souboru | Vypočítaná jednotka stránky | Celkový počet stránek |
|---|---|---|
| Obrázky (JPEG/JPG, PNG, BMP, HEIF) | Každý obrázek = 1 jednotka stránky | Celkový počet obrázků |
| Každá stránka v PDF = 1 jednotka stránky | Total pages in the PDF | |
| TIFF | Každý obrázek v jednotce TIFF = 1 stránka | Celkový počet obrázků ve formátu TIFF |
| Word (DOCX) | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
| Excel (XLSX) | Každý list = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet listů |
| PowerPoint (PPTX) | Každý snímek = 1 jednotka stránky, vložené nebo propojené obrázky se nepodporují. | Celkový počet snímků |
| HTML | Až 3 000 znaků = 1 jednotka stránky, vložené nebo propojené obrázky nejsou podporovány. | Celkový počet stránek až 3 000 znaků |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Výběr stránek pro extrakci textu
U velkých vícestrákových dokumentů PDF použijte pages parametr dotazu k označení konkrétních čísel stránek nebo rozsahů stránek pro extrakci textu.
Odstavce
Model Read OCR v document Intelligence extrahuje všechny identifikované bloky textu v paragraphs kolekci jako objekt nejvyšší úrovně v části analyzeResults. Každá položka v této kolekci představuje blok textu a zahrnuje extrahovaný text jakocontent a ohraničující polygon souřadnice. Informace span ukazují na fragment textu v rámci vlastnosti nejvyšší úrovně content , která obsahuje celý text z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Text, řádky a slova
Model Read OCR extrahuje text tištěného a rukou psaného stylu jako lines a words. Model vypíše ohraničující polygon souřadnice a confidence pro extrahovaná slova. Kolekce styles obsahuje všechny ručně psané styly čar, pokud jsou zjištěny spolu s rozsahy odkazujícími na přidružený text. Tato funkce se vztahuje na podporované ručně psané jazyky.
V případě Microsoft Wordu, Excelu, PowerPointu a HTML extrahuje model Document Intelligence Read v3.1 a novější verze veškerý vložený text tak, jak je. Texty jsou extenzované jako slova a odstavce. Vložené obrázky nejsou podporované.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Ručně psaný styl pro řádky textu
Odpověď zahrnuje klasifikaci, jestli je každý řádek textu ve stylu rukopisu nebo ne, spolu se skóre spolehlivosti. Další informace najdete v tématu podpora rukou psaného jazyka. Následující příklad ukazuje příklad fragmentu kódu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Pokud jste povolili funkci doplňku font/style, získáte také výsledek písma a stylu jako součást objektustyles.
Další kroky
Dokončení rychlého startu pro funkci Document Intelligence:
Prozkoumejte naše rozhraní REST API:
Další ukázky najdete na GitHubu: