Správa prostředků pro cluster Apache Spark ve službě Azure HDInsight
Zjistěte, jak získat přístup k rozhraním, jako je uživatelské rozhraní Apache Ambari , uživatelské rozhraní Apache Hadoop YARN a Server historie Sparku přidružený k vašemu clusteru Apache Spark a jak ladit konfiguraci clusteru pro optimální výkon.
Otevření serveru historie Sparku
Server historie Sparku je webové uživatelské rozhraní pro dokončené a spuštěné aplikace Spark. Jedná se o rozšíření webového uživatelského rozhraní Sparku. Úplné informace najdete v tématu Server historie Sparku.
Otevření uživatelského rozhraní Yarn
Uživatelské rozhraní YARN můžete použít k monitorování aplikací, které jsou aktuálně spuštěné v clusteru Spark.
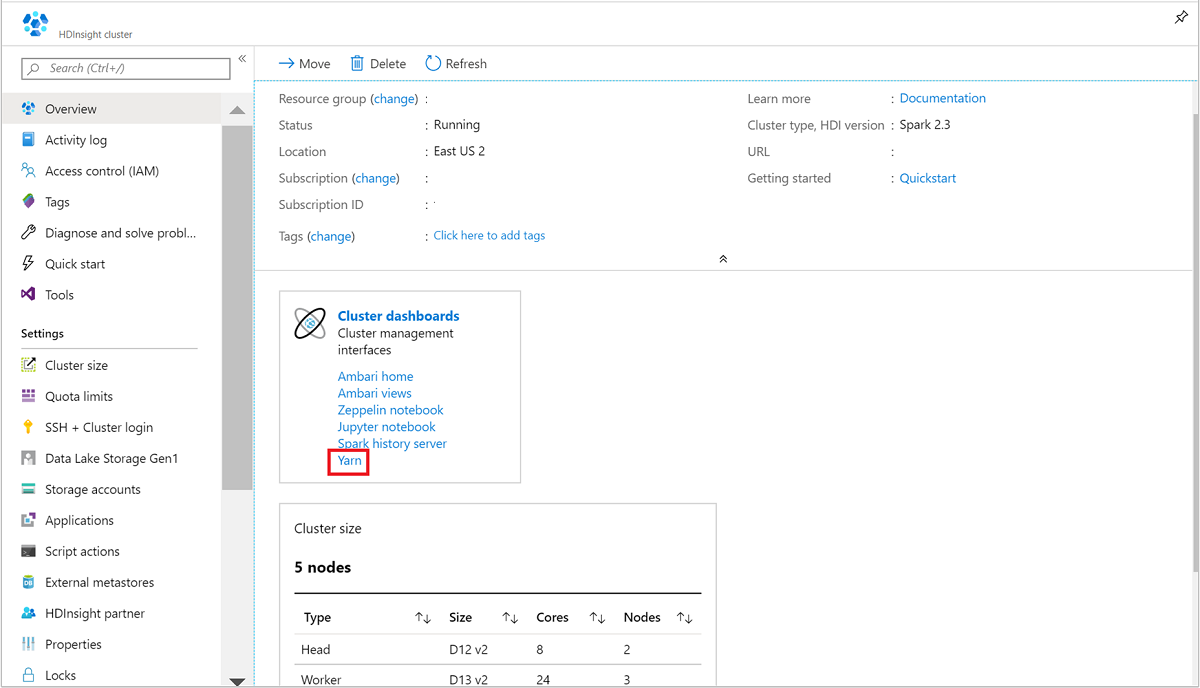
Na webu Azure Portal otevřete cluster Spark. Další informace najdete v tématu Seznam a zobrazení clusterů.
Na řídicích panelech clusteru vyberte Yarn. Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru Spark.
Tip
Případně můžete také spustit uživatelské rozhraní YARN z uživatelského rozhraní Ambari. V uživatelském rozhraní Ambari přejděte na rychlé odkazy>YARN>v uživatelském rozhraní Active>Resource Manageru.
Optimalizace clusterů pro aplikace Spark
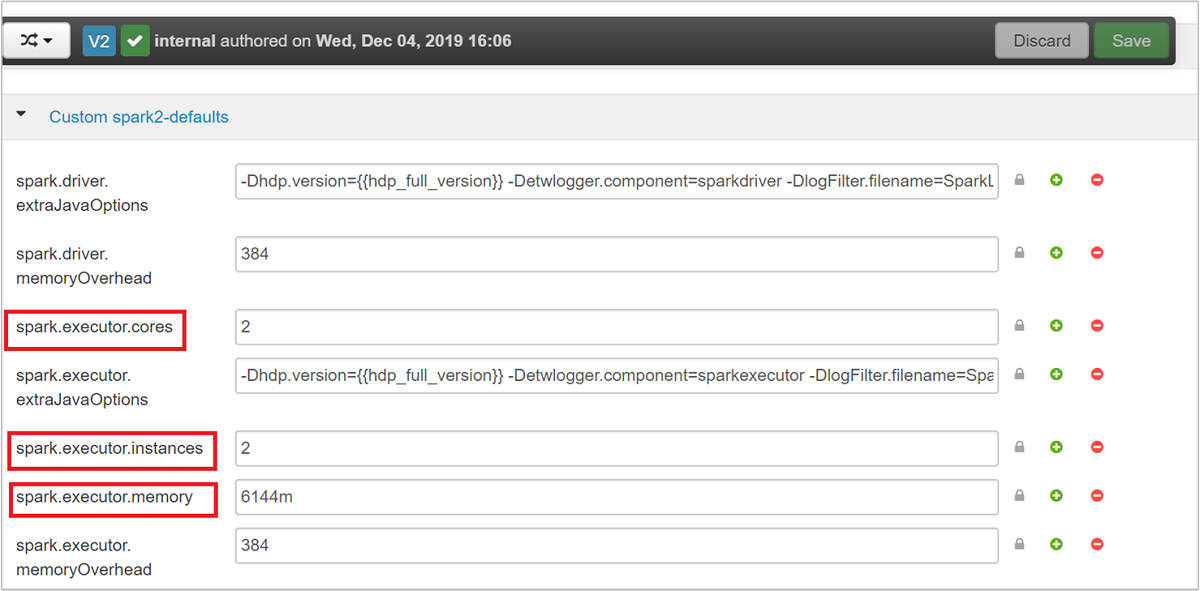
Tři klíčové parametry, které lze použít pro konfiguraci Sparku v závislosti na požadavcích aplikace, jsou spark.executor.instances, spark.executor.coresa spark.executor.memory. Exekutor je proces spuštěný pro aplikaci Spark. Běží na pracovním uzlu a zodpovídá za provádění úkolů pro aplikaci. Výchozí počet exekutorů a velikost exekutorů pro každý cluster se vypočítá na základě počtu pracovních uzlů a velikosti pracovního uzlu. Tyto informace jsou uložené v spark-defaults.conf hlavních uzlech clusteru.
Tyto tři parametry konfigurace je možné nakonfigurovat na úrovni clusteru (pro všechny aplikace, které běží v clusteru), nebo je možné zadat také pro každou jednotlivou aplikaci.
Změna parametrů pomocí uživatelského rozhraní Ambari
Z uživatelského rozhraní Ambari přejděte na konfigurace>Spark 2>Vlastní výchozí hodnoty Spark2.
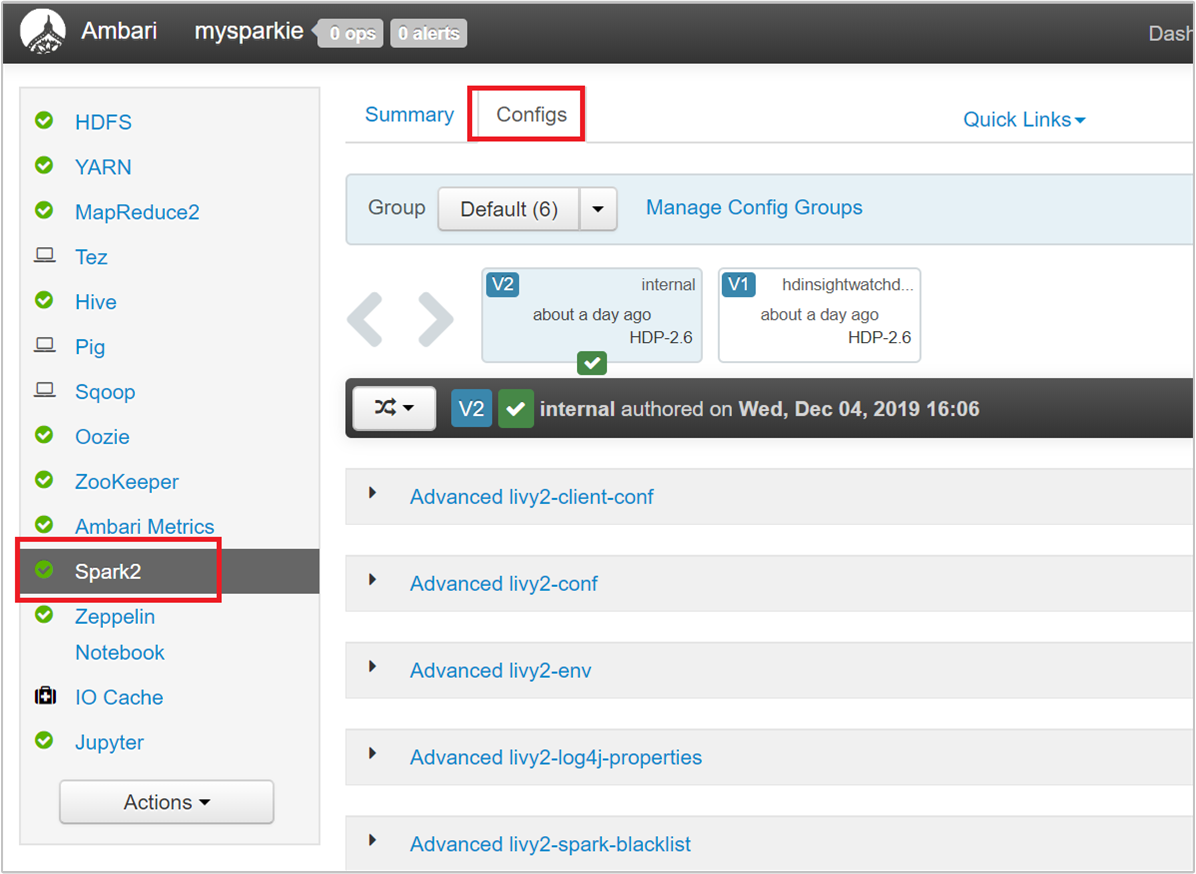
Výchozí hodnoty jsou vhodné pro souběžné spouštění čtyř aplikací Spark v clusteru. Tyto hodnoty můžete změnit z uživatelského rozhraní, jak je znázorněno na následujícím snímku obrazovky:
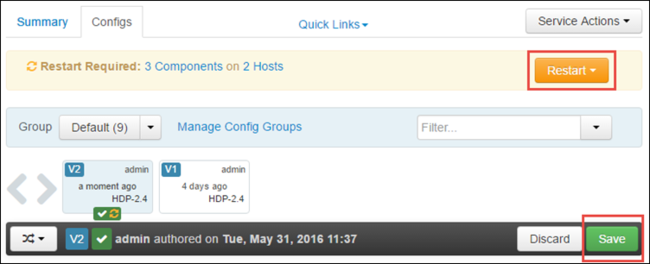
Výběrem možnosti Uložit uložte změny konfigurace. V horní části stránky se zobrazí výzva k restartování všech ovlivněných služeb. Vyberte Restartovat.
Změna parametrů pro aplikaci spuštěnou v Aplikaci Jupyter Notebook
U aplikací spuštěných v aplikaci Jupyter Notebook můžete pomocí %%configure magie provést změny konfigurace. V ideálním případě je nutné provést tyto změny na začátku aplikace před spuštěním první buňky kódu. Tím se zajistí, že se konfigurace použije v relaci Livy při jejím vytvoření. Pokud chcete v aplikaci změnit konfiguraci v pozdější fázi, musíte použít -f parametr. Tím se ale ztratí veškerý pokrok v aplikaci.
Následující fragment kódu ukazuje, jak změnit konfiguraci aplikace spuštěné v Jupyteru.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Parametry konfigurace musí být předány jako řetězec JSON a musí být na dalším řádku za magií, jak je znázorněno v ukázkovém sloupci.
Změna parametrů pro aplikaci odeslanou pomocí spark-submit
Následující příkaz je příkladem změny parametrů konfigurace dávkové aplikace, která je odeslána pomocí spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Změna parametrů pro aplikaci odeslanou pomocí cURL
Následující příkaz je příkladem toho, jak změnit parametry konfigurace pro dávkovou aplikaci, která je odeslána pomocí cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Poznámka:
Zkopírujte soubor JAR do účtu úložiště clusteru. Nekopírujte soubor JAR přímo do hlavního uzlu.
Změna těchto parametrů na serveru Spark Thrift
Spark Thrift Server poskytuje přístup JDBC/ODBC ke clusteru Spark a používá se ke službě dotazů Spark SQL. Nástroje, jako jsou Power BI, Tableau a tak dále, používají protokol ODBC ke komunikaci se Spark Thrift Serverem ke spouštění dotazů Spark SQL jako aplikace Spark. Při vytvoření clusteru Spark se spustí dvě instance serveru Spark Thrift, jedna na každém hlavním uzlu. Každý server Spark Thrift je viditelný jako aplikace Spark v uživatelském rozhraní YARN.
Spark Thrift Server používá přidělení dynamického exekutoru Sparku spark.executor.instances , a proto se nepoužívá. Místo toho Spark Thrift Server používá spark.dynamicAllocation.maxExecutors a spark.dynamicAllocation.minExecutors určuje počet exekutorů. Parametry konfigurace spark.executor.coresa spark.executor.memory slouží k úpravě velikosti exekutoru. Tyto parametry můžete změnit, jak je znázorněno v následujících krocích:
Rozbalte kategorii Advanced spark2-thrift-sparkconf a aktualizujte parametry
spark.dynamicAllocation.maxExecutorsaspark.dynamicAllocation.minExecutors.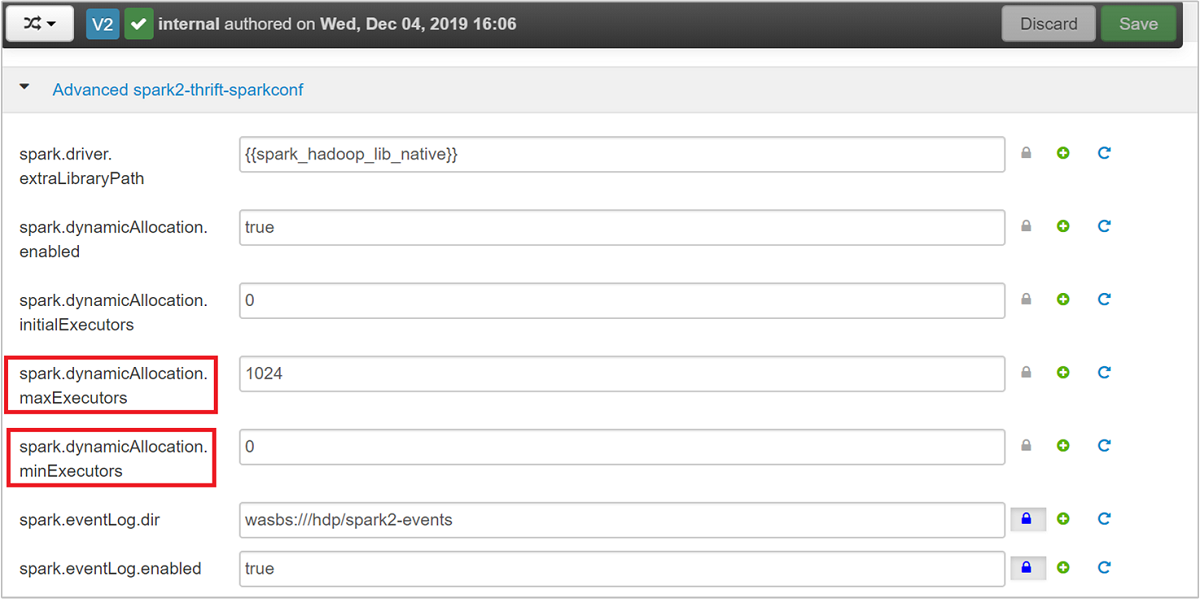
Rozbalte kategorii Custom spark2-thrift-sparkconf a aktualizujte parametry
spark.executor.coresaspark.executor.memory.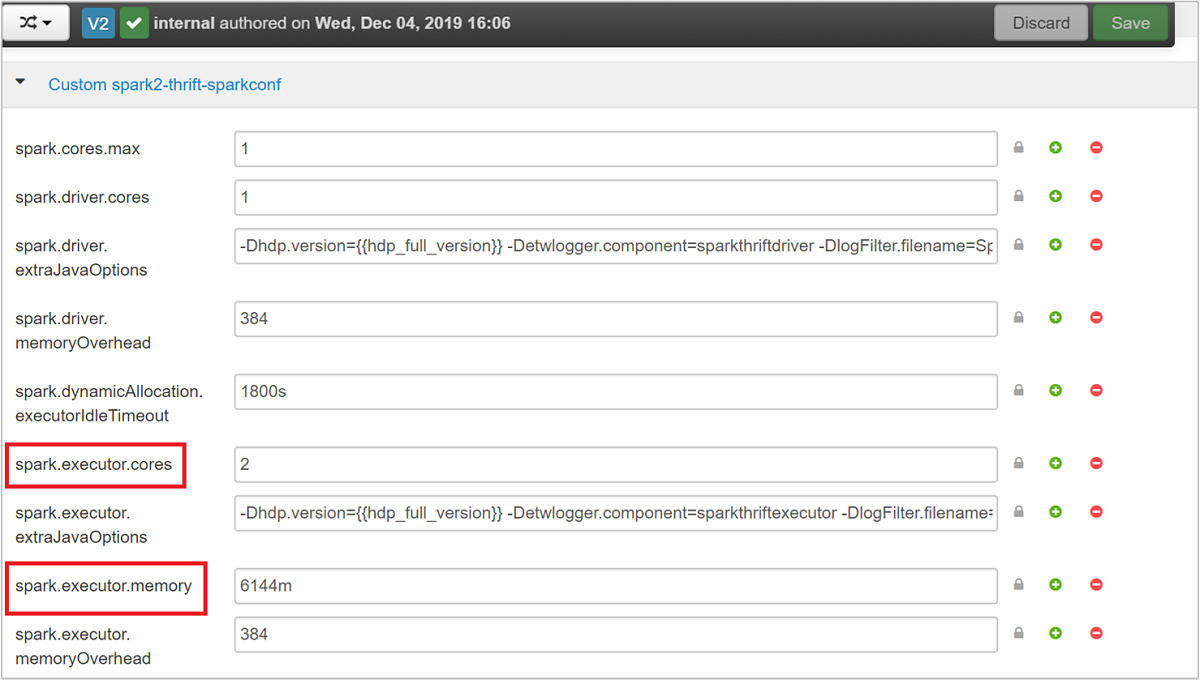
Změna paměti ovladače serveru Spark Thrift
Paměť ovladače serveru Spark Thrift je nakonfigurovaná na 25 % velikosti paměti RAM hlavního uzlu za předpokladu, že celková velikost paměti RAM hlavního uzlu je větší než 14 GB. Pomocí uživatelského rozhraní Ambari můžete změnit konfiguraci paměti ovladače, jak je znázorněno na následujícím snímku obrazovky:
V uživatelském rozhraní Ambari přejděte do konfigurace>Spark2>Advanced spark2-env. Potom zadejte hodnotu pro spark_thrift_cmd_opts.
Uvolnění prostředků clusteru Spark
Z důvodu dynamického přidělování Sparku jsou jedinými prostředky, které využívají server thrift, prostředky pro oba hlavní servery aplikací. Pokud chcete tyto prostředky uvolnit, musíte zastavit služby Serveru Thrift spuštěné v clusteru.
V uživatelském rozhraní Ambari v levém podokně vyberte Spark2.
Na další stránce vyberte Servery Spark 2 Thrift.
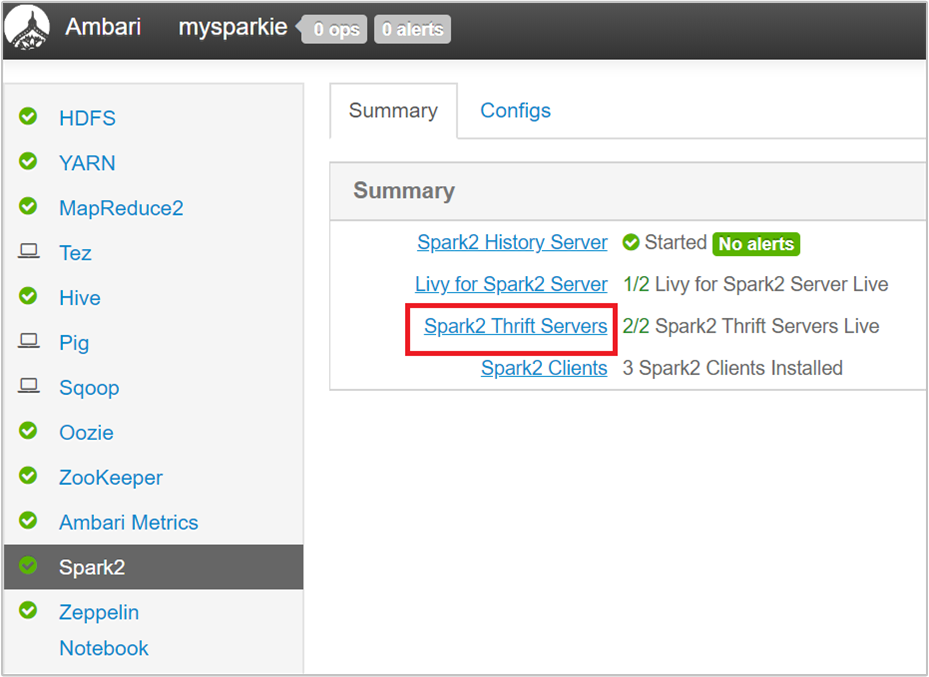
Měli byste vidět dva hlavní uzly, na kterých běží Server Spark 2 Thrift. Vyberte jeden z hlavních uzlů.
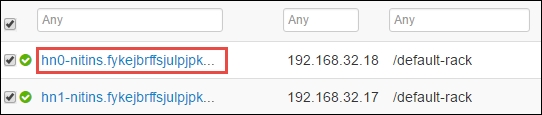
Na další stránce jsou uvedeny všechny služby spuštěné na hlavním uzlu. V seznamu vyberte rozevírací tlačítko vedle Spark 2 Thrift Serveru a pak vyberte Zastavit.
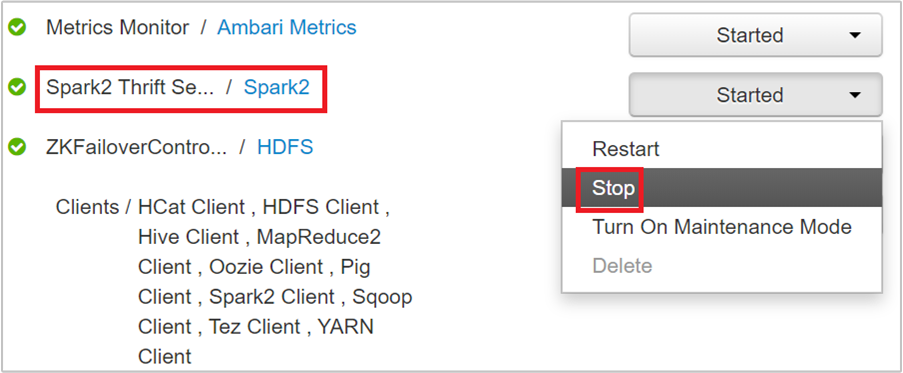
Tento postup opakujte i na druhém hlavním uzlu.
Restartujte službu Jupyter.
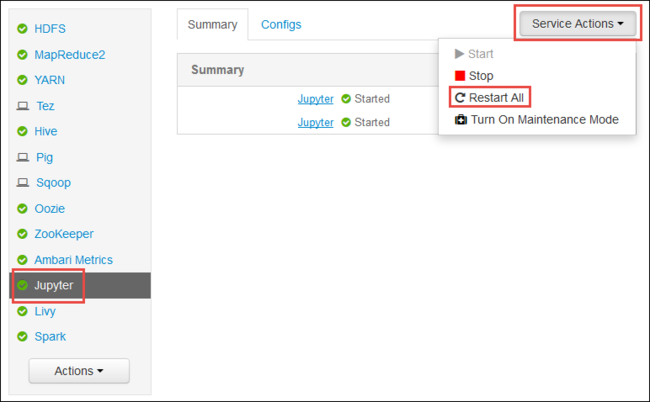
Spusťte webové uživatelské rozhraní Ambari, jak je znázorněno na začátku článku. V levém navigačním podokně vyberte Jupyter, vyberte Akce služby a pak vyberte Restartovat vše. Tím se spustí služba Jupyter na všech hlavních uzly.
Sledování prostředků
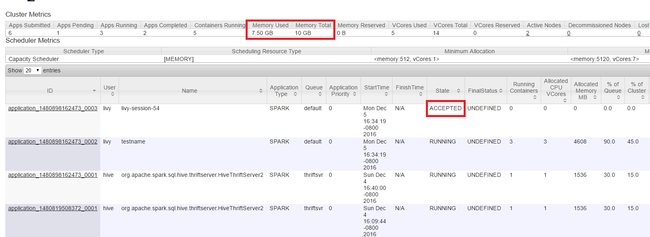
Spusťte uživatelské rozhraní Yarn, jak je znázorněno na začátku článku. V tabulce Metriky clusteru v horní části obrazovky zkontrolujte hodnoty sloupců Využití paměti a Celkový počet paměti. Pokud jsou dvě hodnoty zavřené, nemusí existovat dostatek prostředků pro spuštění další aplikace. Totéž platí pro sloupce Celkové využití virtuálních jader a virtuálních jader. V hlavním zobrazení také platí, že pokud je aplikace ve stavu AKCEPTOVANÁ a nepřechází do stavu SPUŠTĚNO ani SELHÁNÍ , může to také značit, že nemá dostatek prostředků ke spuštění.
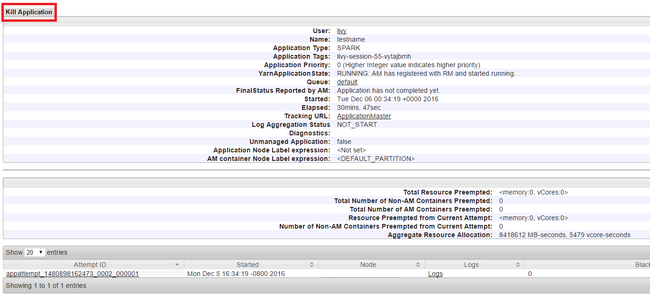
Ukončení spouštění aplikací
V uživatelském rozhraní Yarn na levém panelu vyberte Spuštěno. V seznamu spuštěných aplikací určete aplikaci, která se má zabít, a vyberte ID.
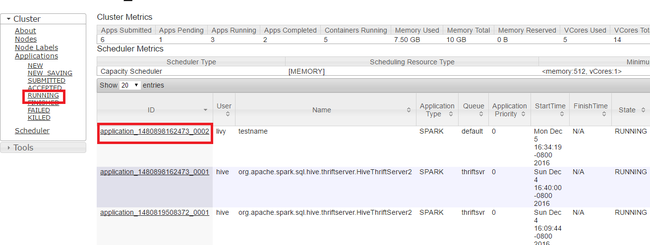
V pravém horním rohu vyberte Možnost Ukončovat aplikaci a pak vyberte OK.
Viz také
Pro datové analytiky
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
- Analýza telemetrických dat Application Insights pomocí Apache Sparku ve službě HDInsight
Pro vývojáře Apache Sparku
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
- Modul plug-in nástroje HDInsight pro IntelliJ IDEA pro vytvoření a odesílání aplikací Spark Scala
- Vzdálené ladění aplikací Apache Spark pomocí modulu plug-in nástrojů HDInsight pro IntelliJ IDEA
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Jádra dostupná pro Poznámkový blok Jupyter v clusteru Apache Spark pro HDInsight
- Použití externích balíčků s poznámkovými bloky Jupyter
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark