Použití rozšířených funkcí Serveru historie Apache Sparku k ladění a diagnostice aplikací Spark
V tomto článku se dozvíte, jak pomocí rozšířených funkcí serveru historie Apache Sparku ladit a diagnostikovat dokončené nebo spuštěné aplikace Spark. Toto rozšíření zahrnuje kartu Data , kartu Graf a kartu Diagnostika . Na kartě Data můžete zkontrolovat vstupní a výstupní data úlohy Sparku. Na kartě Graph můžete zkontrolovat tok dat a znovu přehrát graf úlohy. Na kartě Diagnostika můžete odkazovat na funkce Analýzy využití dat, nerovnoměrné distribuce času a exekutoru.
Získání přístupu k serveru historie Sparku
Server historie Sparku je webové uživatelské rozhraní pro dokončené a spuštěné aplikace Spark. Můžete ho otevřít z webu Azure Portal nebo z adresy URL.
Otevření webového uživatelského rozhraní Serveru historie Sparku na webu Azure Portal
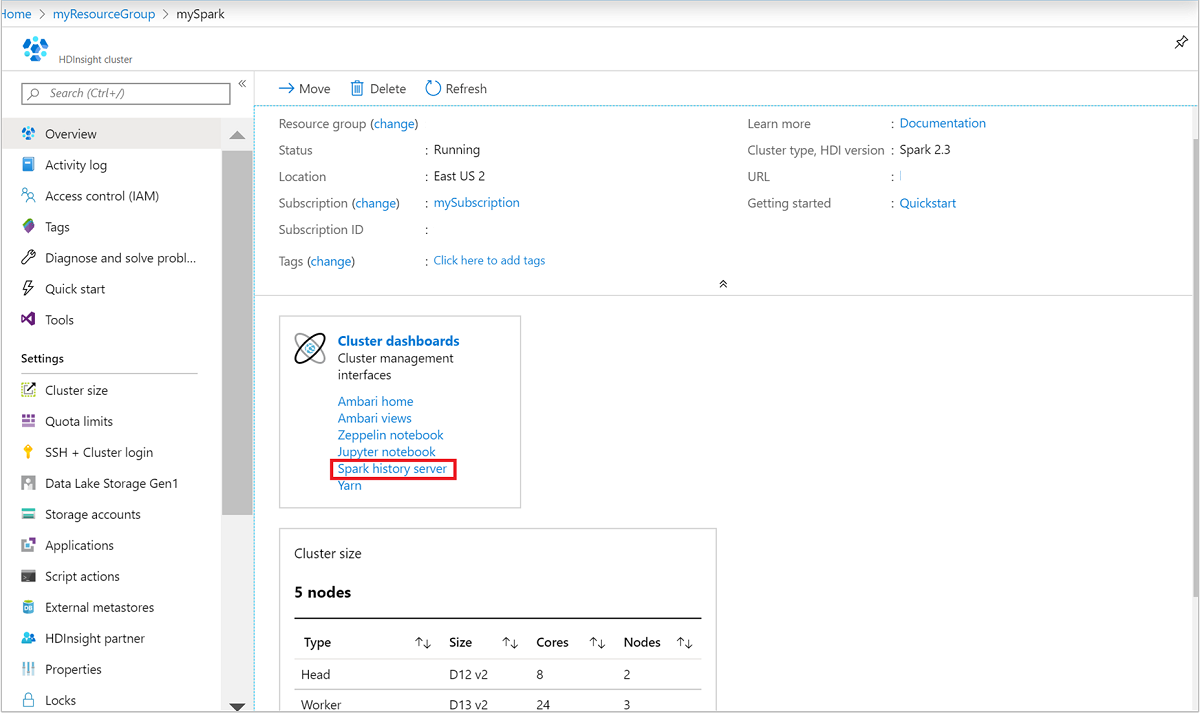
Na webu Azure Portal otevřete cluster Spark. Další informace najdete v tématu Seznam a zobrazení clusterů.
Na řídicích panelech clusteru vyberte server historie Sparku. Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru Spark.
 azure Portal." border="true":::
azure Portal." border="true":::
Otevření webového uživatelského rozhraní Serveru historie Sparku podle adresy URL
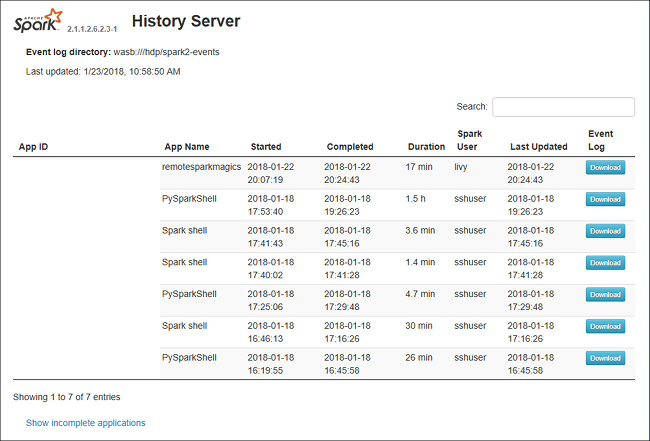
Otevřete Server historie Sparku tak, že přejdete na https://CLUSTERNAME.azurehdinsight.net/sparkhistorymísto CLUSTERNAME název vašeho clusteru Spark.
Webové uživatelské rozhraní Serveru historie Sparku může vypadat podobně jako na tomto obrázku:
Použití karty Data na serveru historie Sparku
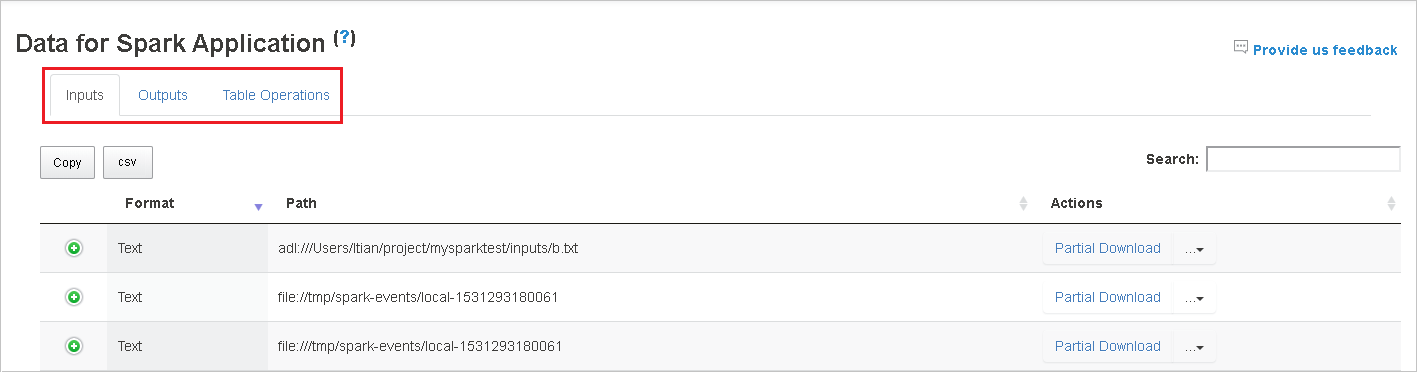
Vyberte ID úlohy a potom v nabídce nástrojů vyberte Data , aby se zobrazilo zobrazení dat.
Zkontrolujte vstupy, výstupy a operace tabulky výběrem jednotlivých karet.
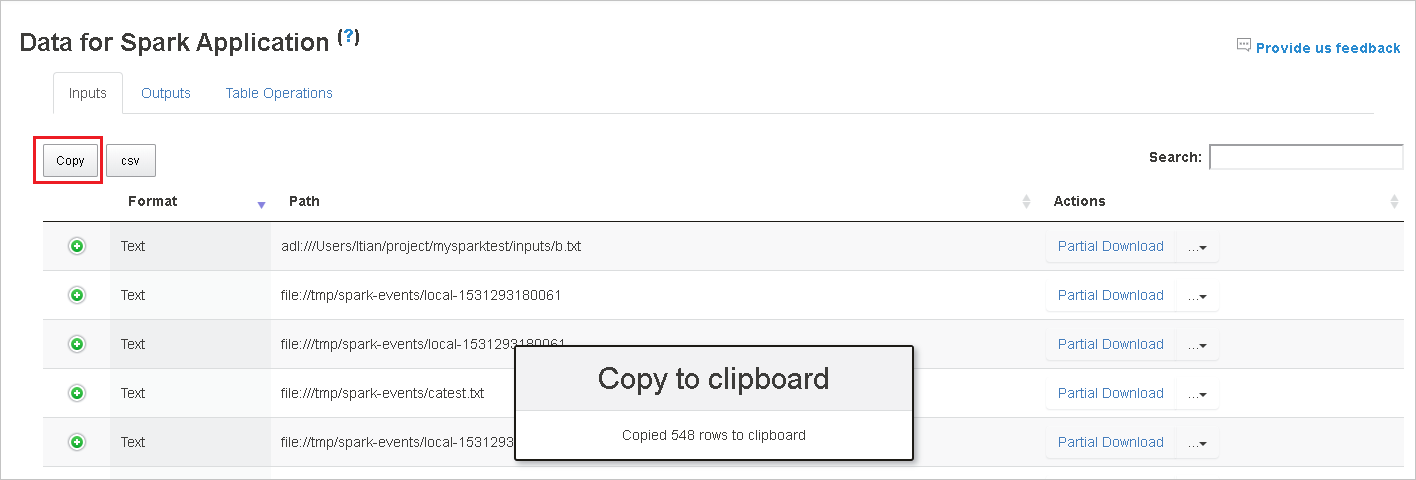
Výběrem tlačítka Kopírovat zkopírujte všechny řádky.
Uložte všechna data jako . Soubor CSV výběrem tlačítka CSV .
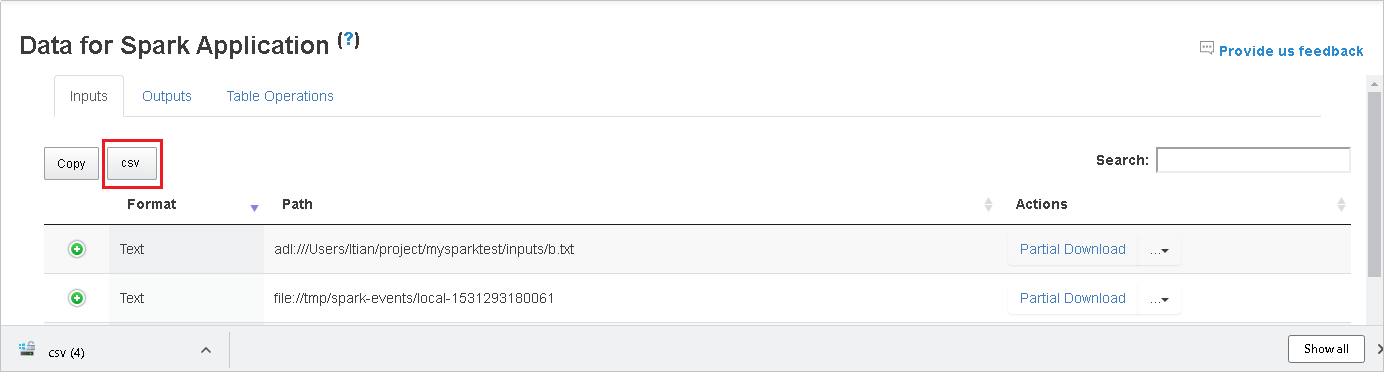
Data můžete prohledávat zadáním klíčových slov do vyhledávacího pole. Výsledky hledání se zobrazí okamžitě.
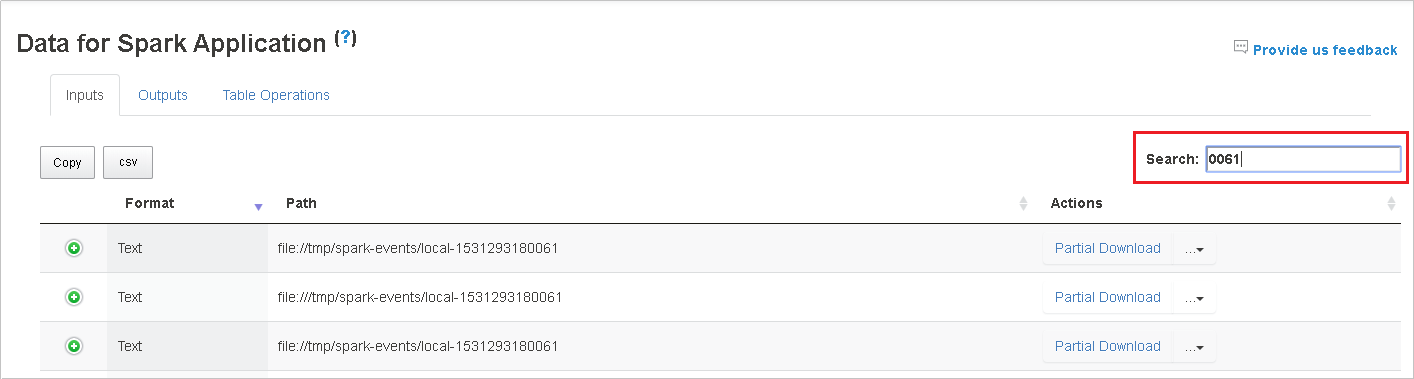
Výběrem záhlaví sloupce tabulku seřadíte. Výběrem znaménka plus rozbalte řádek, aby se zobrazily další podrobnosti. Pokud chcete řádek sbalit, vyberte znaménko mínus.
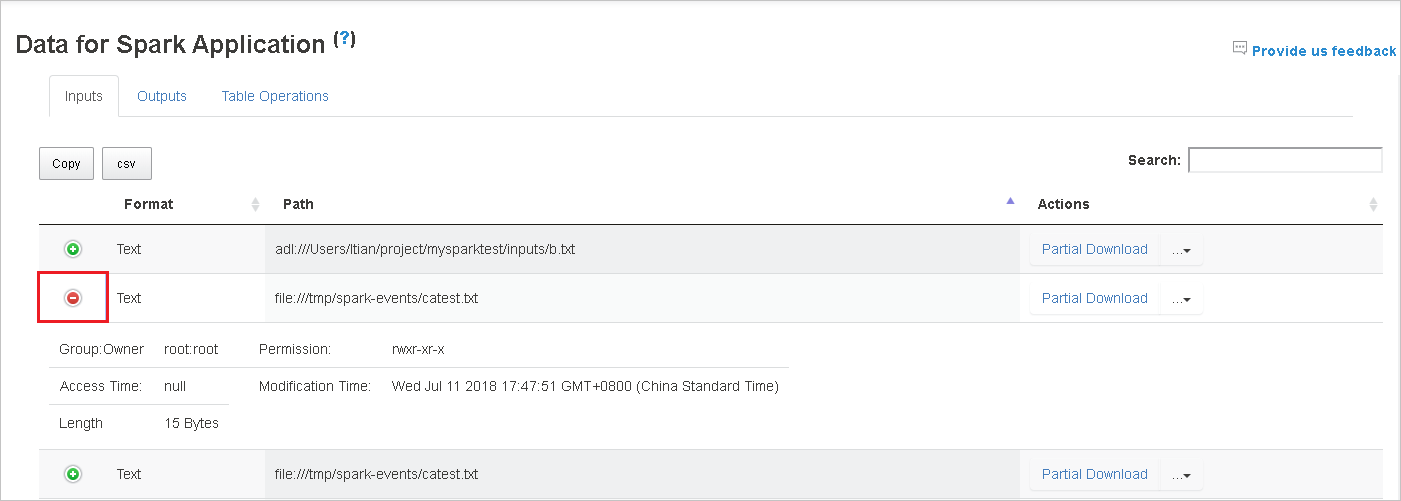
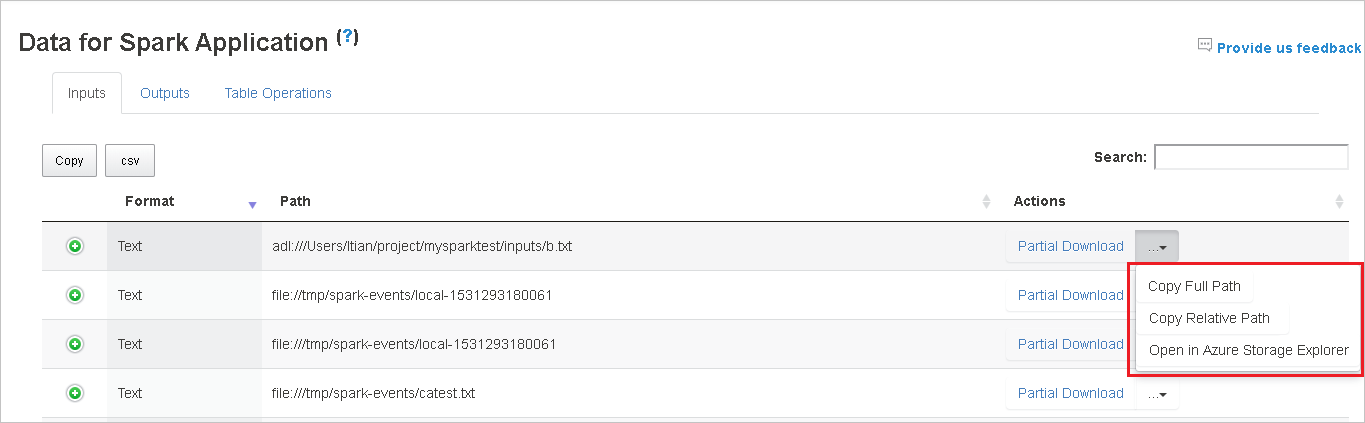
Stáhněte si jeden soubor tak , že vpravo vyberete tlačítko Částečné stažení . Vybraný soubor se stáhne místně. Pokud soubor už neexistuje, otevře se nová karta, která zobrazí chybové zprávy.
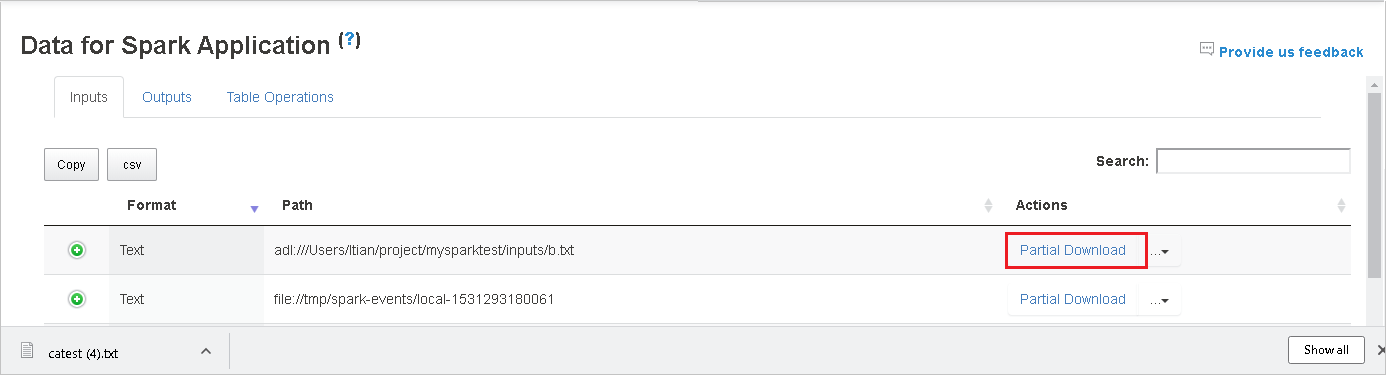
Zkopírujte úplnou cestu nebo relativní cestu výběrem možnosti Kopírovat úplnou cestu nebo Kopírovat relativní cestu, která se rozbalí z nabídky stahování. V případě souborů Azure Data Lake Storage vyberte Otevřít v Průzkumník služby Azure Storage spusťte Průzkumník služby Azure Storage a vyhledejte složku po přihlášení.
Pokud je na jedné stránce zobrazeno příliš mnoho řádků, vyberte čísla stránek v dolní části tabulky, abyste mohli přecházet.

Další informace zobrazíte tak, že najedete myší nebo vyberete otazník vedle položky Data for Spark Application .
Pokud chcete poslat zpětnou vazbu k problémům, vyberte Poskytnout nám zpětnou vazbu.
Použití karty Graph na serveru historie Sparku
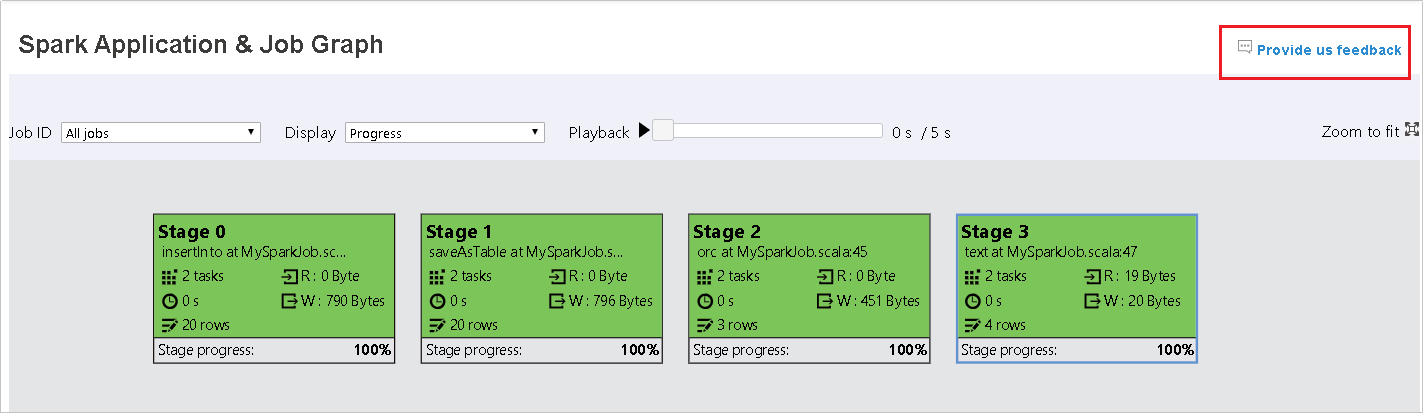
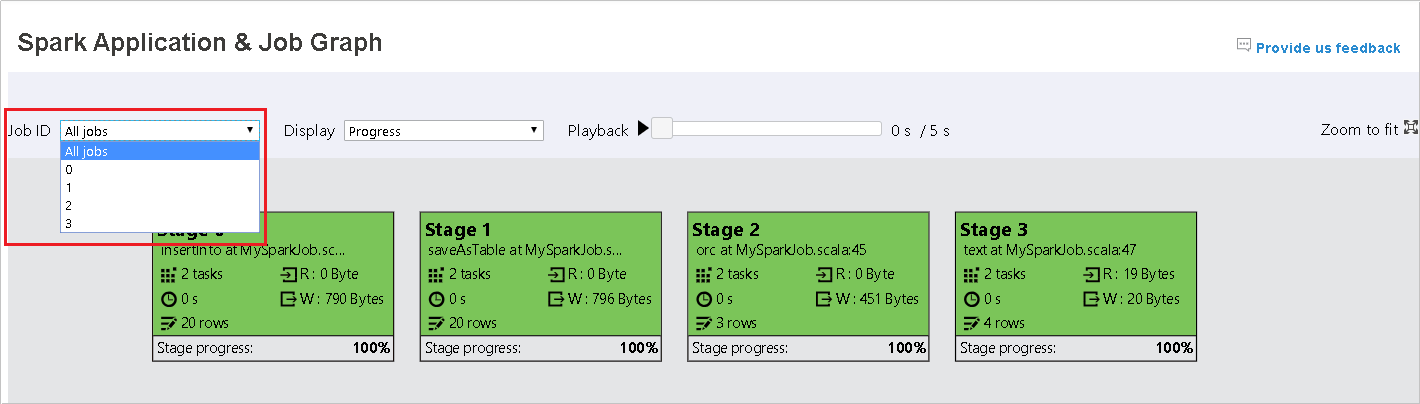
Vyberte ID úlohy a pak v nabídce nástrojů vyberte Graph , aby se zobrazil graf úlohy. Ve výchozím nastavení graf zobrazí všechny úlohy. Výsledky můžete filtrovat pomocí rozevírací nabídky ID úlohy.
Průběh je ve výchozím nastavení vybraný. Tok dat můžete zkontrolovat tak, že v rozevírací nabídce Zobrazení vyberete možnost Číst nebo Zapisovat.
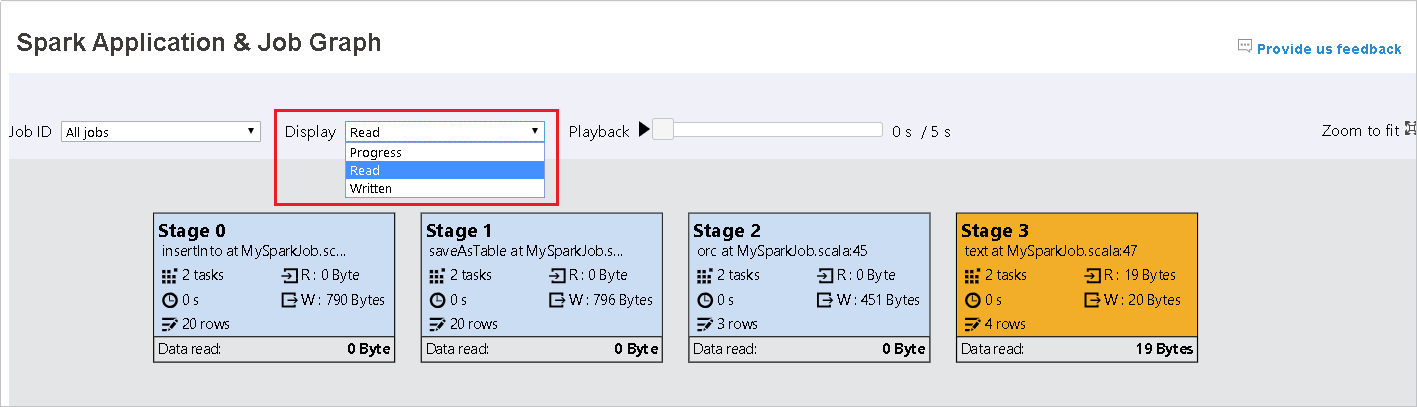
Barva pozadí každého úkolu odpovídá heat mapě.

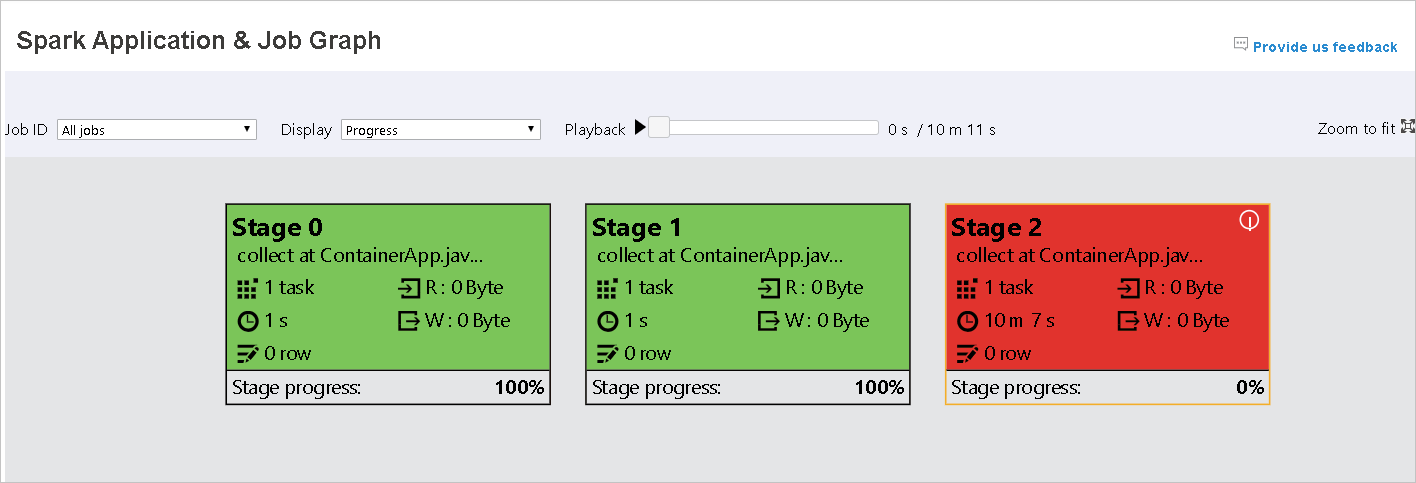
Color Popis Zelený Úloha byla úspěšně dokončena. Orange Úkol selhal, ale nemá vliv na konečný výsledek úlohy. Tyto úlohy mají duplicitní instance nebo opakovat instance, které mohou být později úspěšné. Modrý Úloha je spuštěná. Bílá Úloha čeká na spuštění nebo se fáze přeskočí. Červený Úkol se nezdařil. 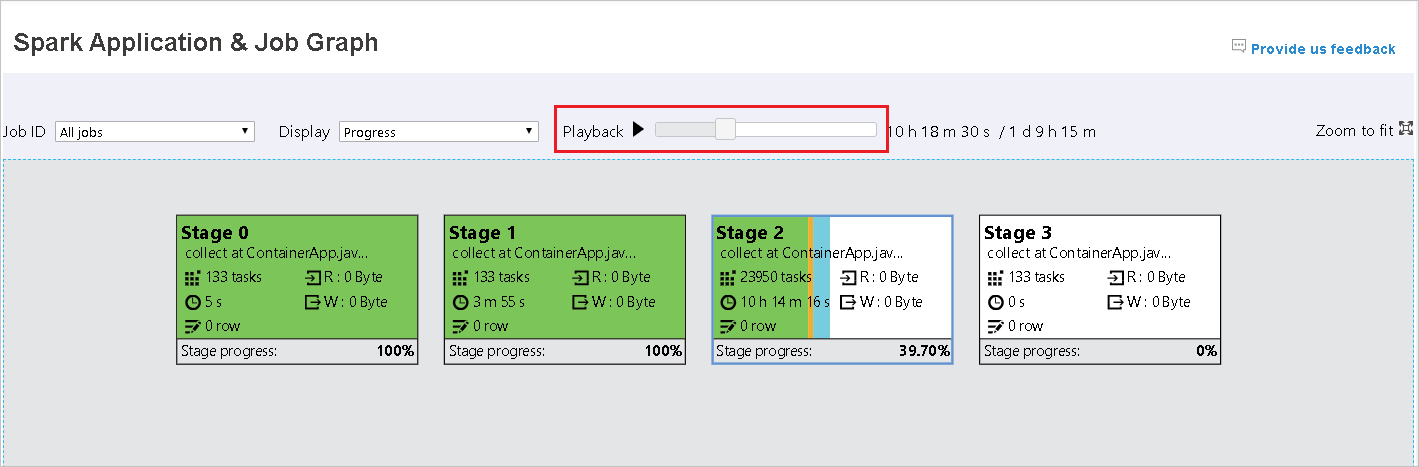
Přeskočené fáze se zobrazují bíle.
Poznámka:
Přehrávání je k dispozici pro dokončené úlohy. Vyberte tlačítko Přehrávání a přehrajte úlohu zpět. Úlohu můžete kdykoli zastavit tak, že vyberete tlačítko Zastavit. Když se úloha přehraje, zobrazí se každý úkol podle barvy. Přehrávání není podporováno pro neúplné úlohy.
Posuňte se, pokud chcete graf úloh přiblížit nebo oddálit, nebo vyberte Lupa, aby se vešla na obrazovku.
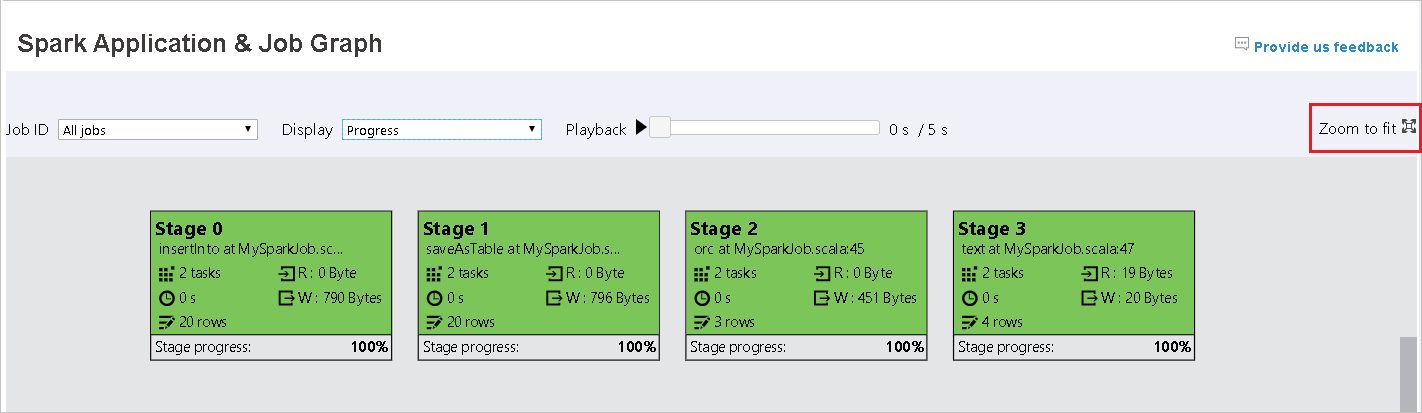
Když úkoly selžou, najeďte myší na uzel grafu, aby se zobrazil popis, a pak vyberte fázi, aby se otevřela na nové stránce.
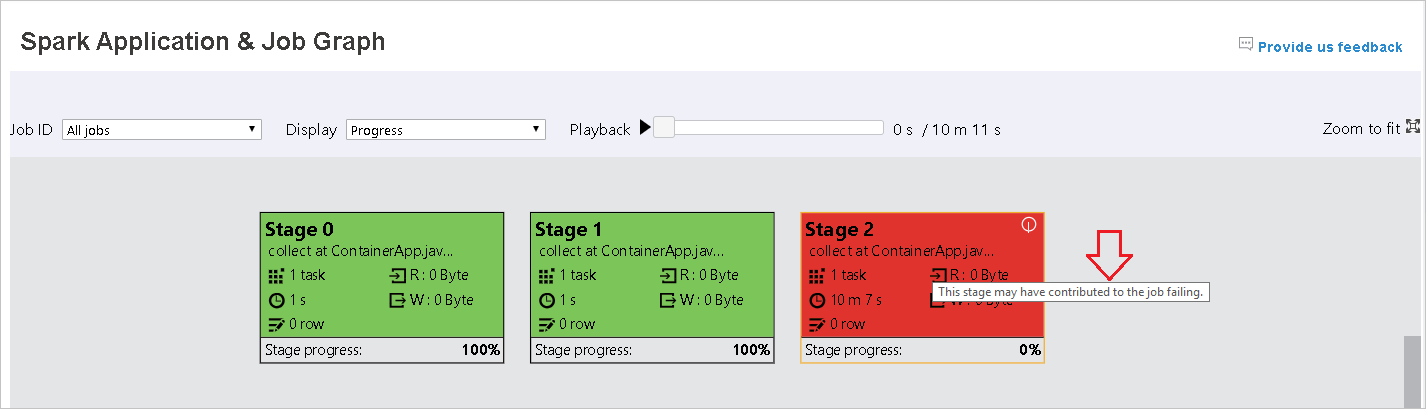
Na stránce Graf úloh a aplikací Sparku se ve fázích zobrazí popisy tlačítek a malé ikony, pokud úkoly splňují tyto podmínky:
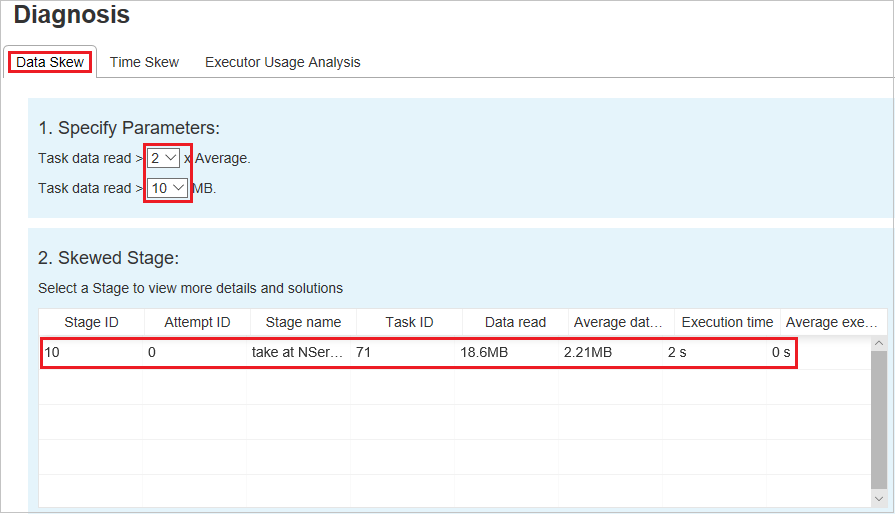
Nerovnoměrná distribuce dat: Průměrná velikost čtení > dat u všech úkolů uvnitř této fáze * 2 a velikost > čtení dat 10 MB.
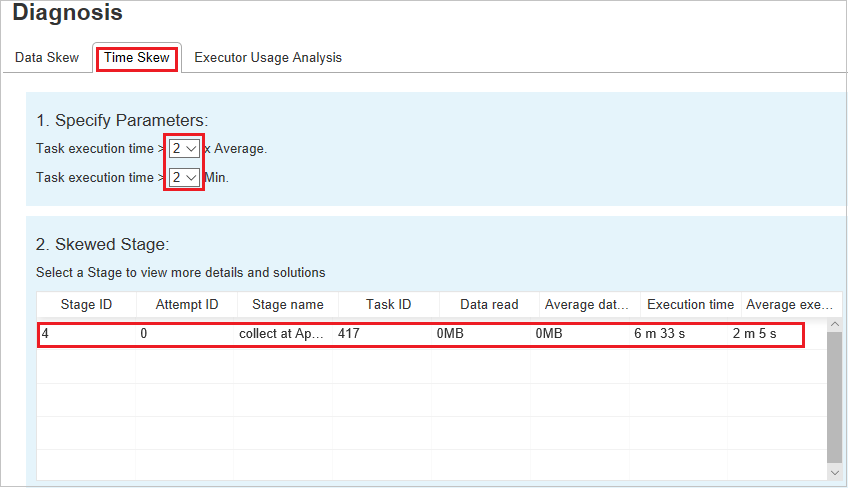
Časová nerovnoměrná distribuce: Průměrná doba > provádění všech úkolů v této fázi * 2 a doba > provádění 2 min.
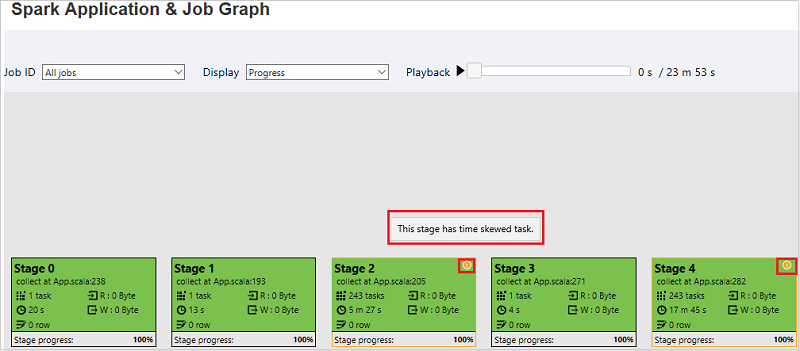
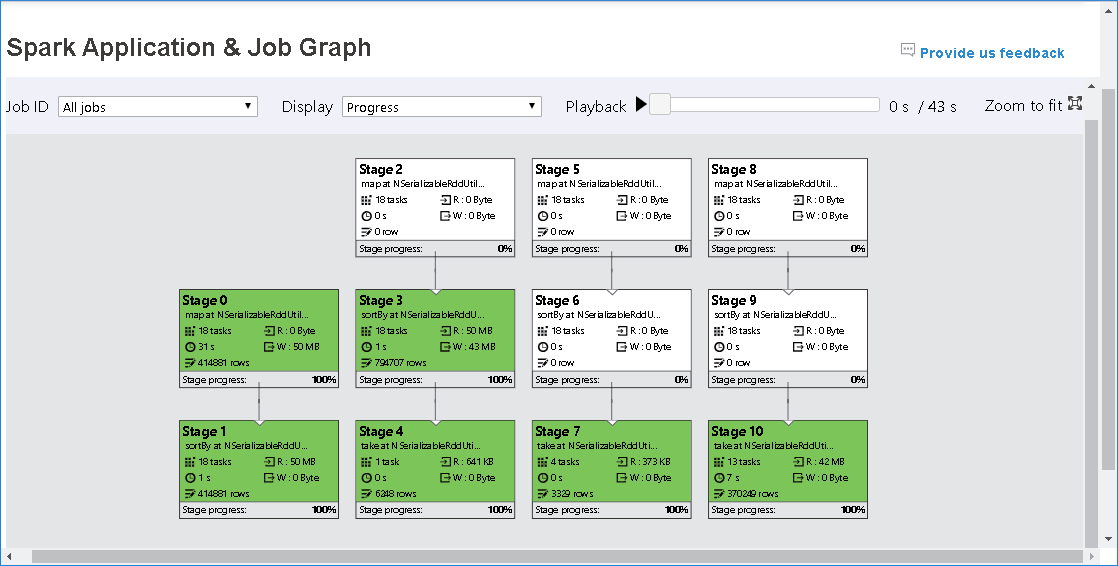
Uzel grafu úloh zobrazí následující informace o jednotlivých fázích:
ID
Název nebo popis
Celkový počet úkolů
Čtení dat: součet velikosti vstupu a náhodného náhodného čtení
Zápis dat: součet velikosti výstupu a velikosti náhodného zápisu
Doba provádění: čas mezi časem spuštění prvního pokusu a časem dokončení posledního pokusu
Počet řádků: součet vstupních záznamů, výstupních záznamů, náhodného čtení záznamů a zahazování záznamů zápisu
Průběh
Poznámka:
Ve výchozím nastavení se v uzlu grafu úlohy zobrazí informace z posledního pokusu o každou fázi (s výjimkou doby provádění fáze). Během přehrávání ale uzel grafu úlohy zobrazí informace o každém pokusu.
Poznámka:
U velikostí čtení dat a zápisu dat používáme 1 MB = 1000 kB = 1000 × 1 000 bajtů.
Pošlete nám svůj názor na problémy tak, že vyberete Zadat zpětnou vazbu.
Použití karty Diagnostika na serveru historie Sparku
Vyberte ID úlohy a pak v nabídce nástrojů vyberte Diagnostika , abyste viděli zobrazení diagnostiky úlohy. Karta Diagnostika zahrnuje nerovnoměrnou distribuci dat, nerovnoměrnou distribuci času a analýzu využití exekutoru.
Zkontrolujte nerovnoměrnou distribuci dat, nerovnoměrnou distribuci času a analýzu využití exekutoru tak, že vyberete karty.
Nerovnoměrná distribuce dat
Vyberte kartu Nerovnoměrná distribuce dat. Odpovídající nerovnoměrné úlohy se zobrazí na základě zadaných parametrů.
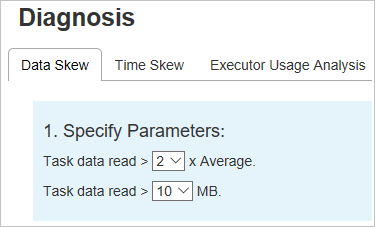
Zadání parametrů
V části Zadat parametry se zobrazí parametry, které se používají k detekci nerovnoměrné distribuce dat. Výchozí pravidlo je: Čtení dat úkolů je větší než třikrát průměrného čtení dat úkolu a čtení dat úkolu je větší než 10 MB. Pokud chcete definovat vlastní pravidlo pro zkosené úkoly, můžete zvolit parametry. Oddíly zkosené fáze a zkosené grafy se odpovídajícím způsobem aktualizují.
Zkosené fáze
Oddíl Zkosené fáze zobrazuje fáze, které mají zkosené úkoly, které splňují zadaná kritéria. Pokud je ve fázi více než jeden zkosený úkol, zobrazí se v části Zkosené dílčí fáze jenom nejšikmější úkol (to znamená největší data pro nerovnoměrnou distribuci dat).
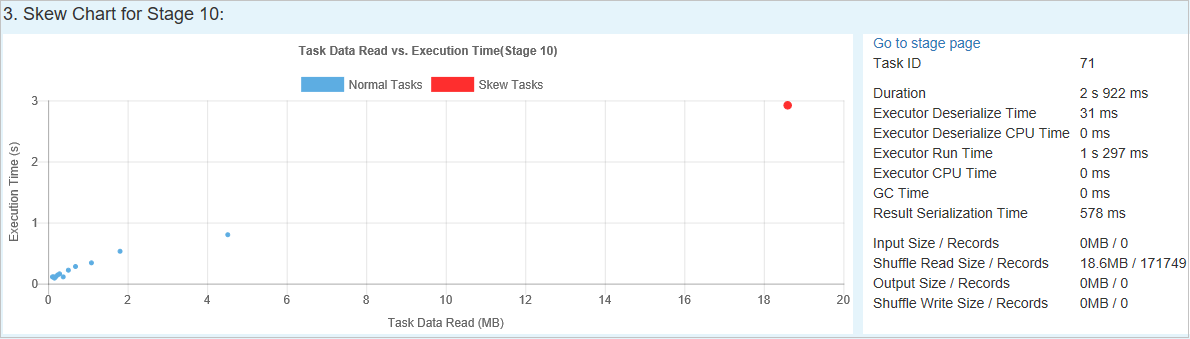
Zkosený graf
Když vyberete řádek v tabulce Zkosená fáze , zobrazí graf nerovnoměrné distribuce úkolů další podrobnosti o distribuci úkolů na základě času čtení a spuštění dat. Šikmé úkoly jsou označené červeně a normální úkoly jsou označené modře. Z hlediska výkonu graf zobrazuje až 100 ukázkových úloh. Podrobnosti úkolu se zobrazí na pravém dolním panelu.
Nerovnoměrná distribuce času
Na kartě Nerovnoměrná distribuce času se zobrazují nerovnoměrné úkoly na základě času provádění úkolu.
Zadání parametrů
V části Zadat parametry se zobrazí parametry, které se používají k detekci nerovnoměrné distribuce času. Výchozí pravidlo je: Doba provádění úlohy je větší než třikrát průměrné doby provádění a doba provádění úkolů je větší než 30 sekund. Parametry můžete změnit podle svých potřeb. Nerovnoměrná fáze a zkosený graf zobrazují odpovídající fáze a informace o úkolech, stejně jako na kartě Nerovnoměrná distribuce dat.
Když vyberete Nerovnoměrná distribuce času, filtrovaný výsledek se zobrazí v oddílu Zkosené fáze podle parametrů nastavených v části Zadat parametry . Když vyberete jednu položku v oddílu Zkosené dílčí fáze , v třetí části se zobrazí odpovídající graf a podrobnosti úkolu se zobrazí v pravém dolním panelu.
Grafy analýzy využití exekutoru
Graf využití exekutoru zobrazuje skutečné přidělení exekutoru a stav spuštění úlohy.
Když vyberete analýzu využití exekutoru, jsou koncepty čtyř různých křivek o využití exekutoru: přidělené exekutory, spuštěné exekutory, nečinné exekutory a instance Max Executor. Každá přidaná nebo odebraná událost Exekutoru zvýší nebo sníží přidělené exekutory. Další porovnání můžete zkontrolovat na časové ose události na kartě Úlohy .
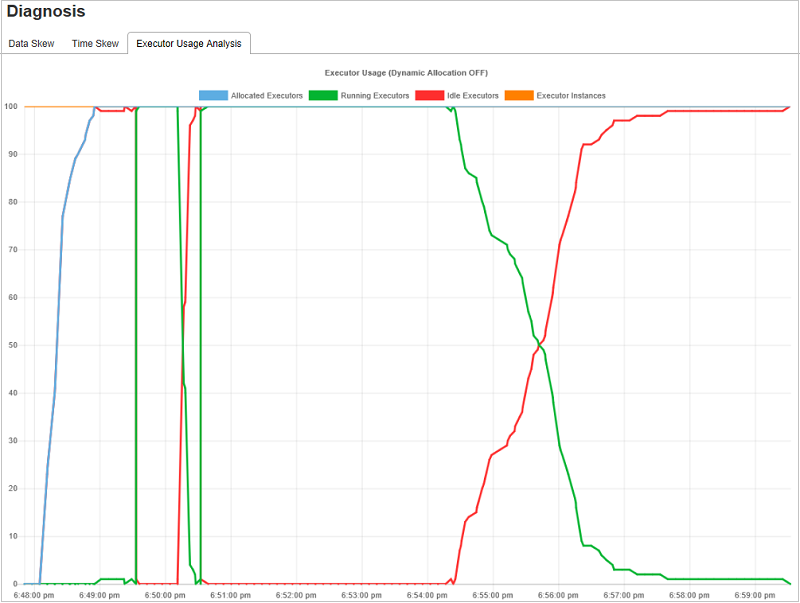
Výběrem ikony barvy vyberte nebo zrušte výběr odpovídajícího obsahu ve všech konceptech.
Často kladené dotazy
Návody se vrátit k verzi komunity?
Pokud se chcete vrátit k verzi komunity, postupujte následovně.
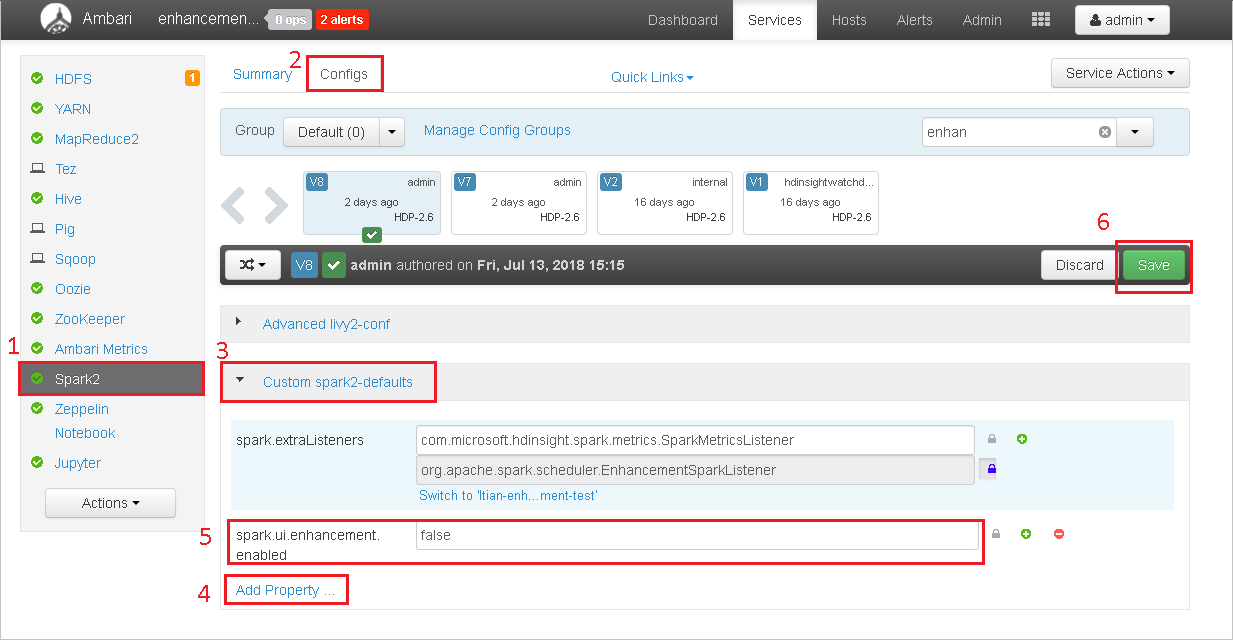
Otevřete cluster v Ambari.
Přejděte do konfigurací Spark2>.
Vyberte Vlastní výchozí hodnoty Spark2.
Vyberte Přidat vlastnost ....
Přidejte spark.ui.enhancement.enabled=false a uložte ho.
Vlastnost se teď nastaví na false .
Výběrem tlačítka Uložit konfiguraci uložte.
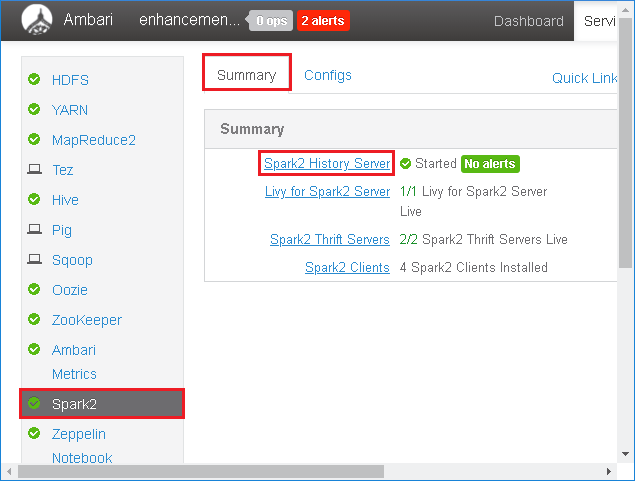
Na levém panelu vyberte Spark2 . Potom na kartě Souhrn vyberte Server historie Spark2.
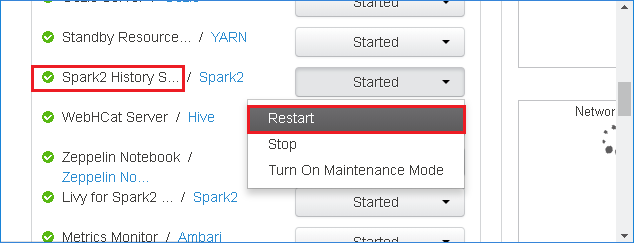
Pokud chcete restartovat Server historie Sparku, vyberte tlačítko Spuštěno napravo od Serveru historie Spark2 a pak v rozevírací nabídce vyberte Restartovat .
Aktualizujte webové uživatelské rozhraní Serveru historie Sparku. Vrátí se k verzi komunity.
Návody nahrání události Serveru historie Sparku, aby se hlásil jako problém?
Pokud na serveru historie Sparku narazíte na chybu, nahlásíte událost následujícím postupem.
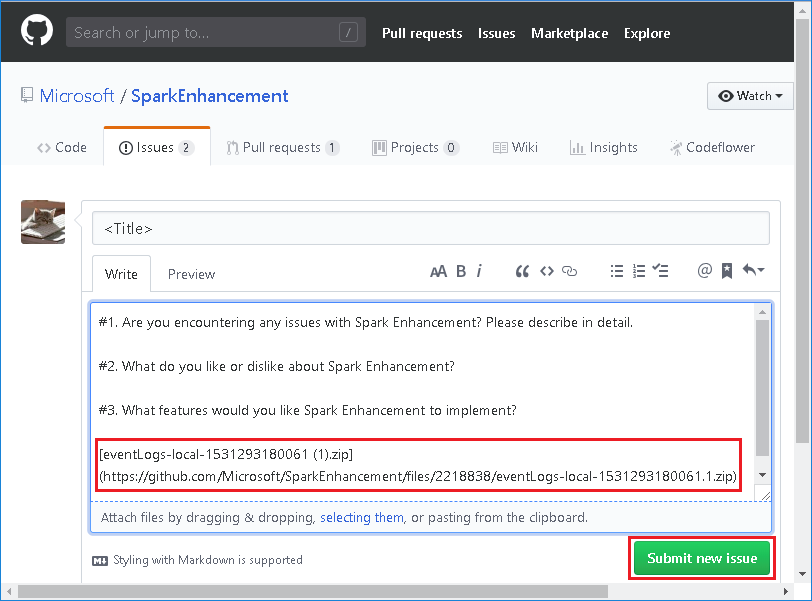
Stáhněte událost výběrem možnosti Stáhnout ve webovém uživatelském rozhraní Serveru historie Sparku.
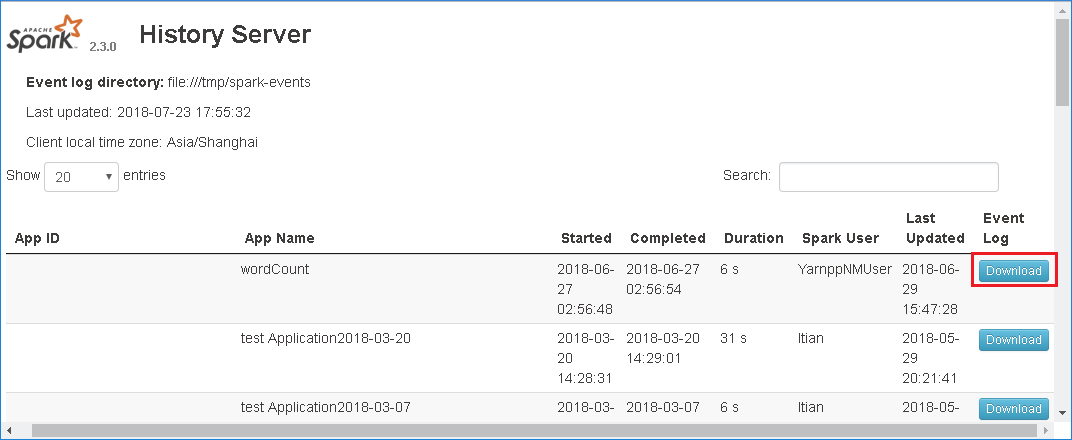
Na stránce Graf úloh a aplikací Sparku nám můžete poslat zpětnou vazbu.
Zadejte název a popis chyby. Potom přetáhněte soubor .zip do pole pro úpravy a vyberte Odeslat nový problém.
Návody upgradovat soubor .jar ve scénáři opravy hotfix?
Pokud chcete upgradovat pomocí opravy hotfix, použijte následující skript, který bude upgradovat spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Využití
upgrade_spark_enhancement.sh https://${jar_path}
Příklad
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Použití souboru Bash z webu Azure Portal
Spusťte Azure Portal a pak vyberte svůj cluster.
Dokončete akci skriptu s následujícími parametry.
Vlastnost Hodnota Typ skriptu -Vlastní Název UpgradeJar Identifikátor URI skriptu Bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shTypy uzlů Vedoucí, Pracovník Parametry https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar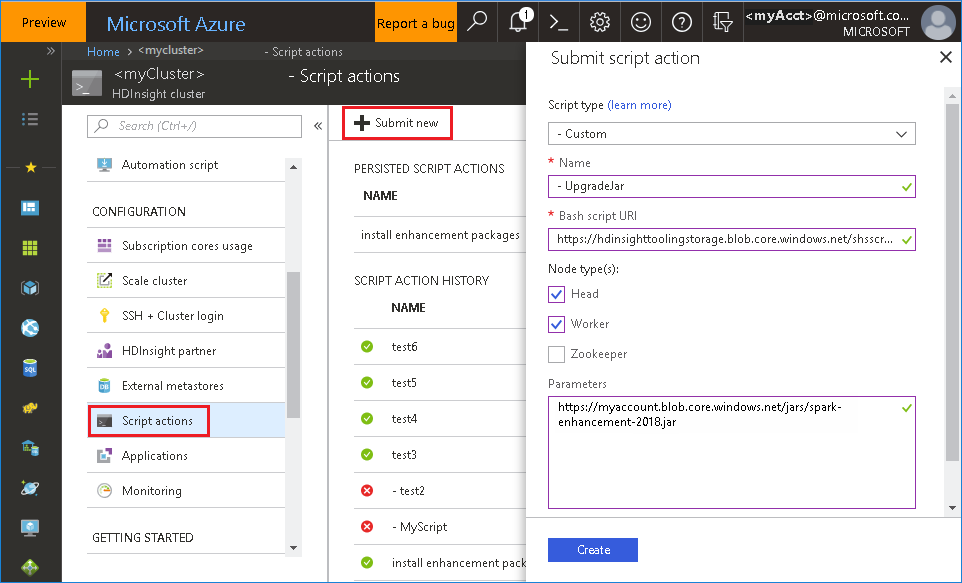
Známé problémy
Server historie Sparku v současné době funguje jenom pro Spark 2.3 a 2.4.
Vstupní a výstupní data, která používají sadu RDD, se na kartě Data nezobrazí.
Další kroky
Návrhy
Pokud máte zpětnou vazbu nebo při používání tohoto nástroje narazíte na nějaké problémy, pošlete e-mail na adresu (hdivstool@microsoft.com).