Kurz: Vytvoření aplikace Scala Maven pro Apache Spark ve službě HDInsight pomocí IntelliJ
V tomto kurzu se dozvíte, jak vytvořit aplikaci Apache Spark napsanou v jazyce Scala pomocí Apache Mavenu s IntelliJ IDEA. Tento článek používá Jako systém sestavení Apache Maven. A začíná existujícím archetypem Maven pro Scala, který poskytuje IntelliJ IDEA. Vytvoření aplikace Scala v IntelliJ IDEA zahrnuje následující kroky:
- Použití Mavenu jako sestavovacího systému
- Aktualizace souboru POM (Project Object Model) pro zajištění převodu závislostí modulů Sparku
- Napsání aplikace v jazyce Scala
- Vygenerování souboru JAR, který je možné odeslat do clusterů HDInsight Spark
- Spuštění aplikace v clusteru Spark pomocí Livy
V tomto kurzu se naučíte:
- Instalace modulu plug-in Scala pro IntelliJ IDEA
- Vývoj aplikace Scala Maven pomocí IntelliJ
- Vytvoření samostatného projektu Scala
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
Oracle Java Development Kit. V tomto kurzu se používá Java verze 8.0.202.
Prostředí Java IDE. Tento článek používá IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Viz Instalace sady Azure Toolkit for IntelliJ.
Instalace modulu plug-in Scala pro IntelliJ IDEA
Pomocí následujících kroků nainstalujte modul plug-in Scala:
Otevřete IntelliJ IDEA.
Na úvodní obrazovce přejděte na Konfigurovat>moduly plug-in a otevřete okno Moduly plug-in.
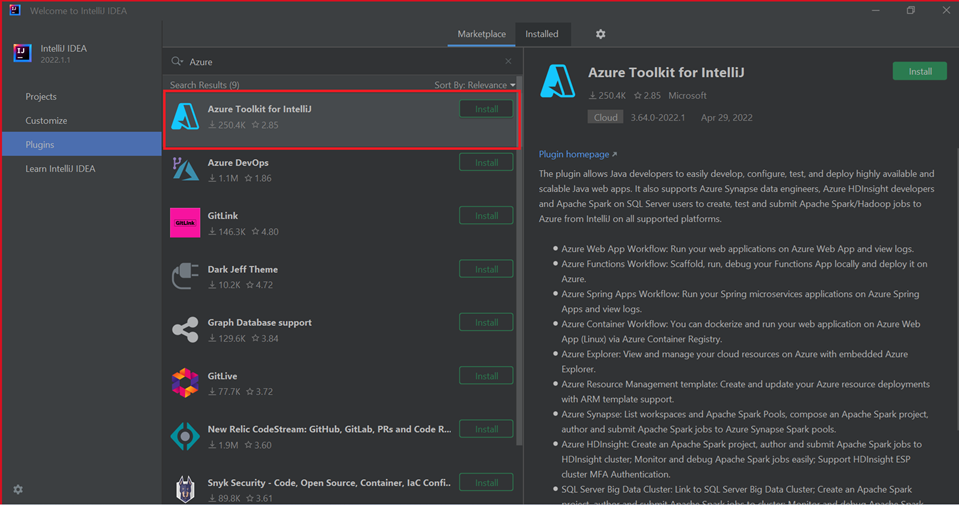
Vyberte Nainstalovat pro sadu Azure Toolkit for IntelliJ.
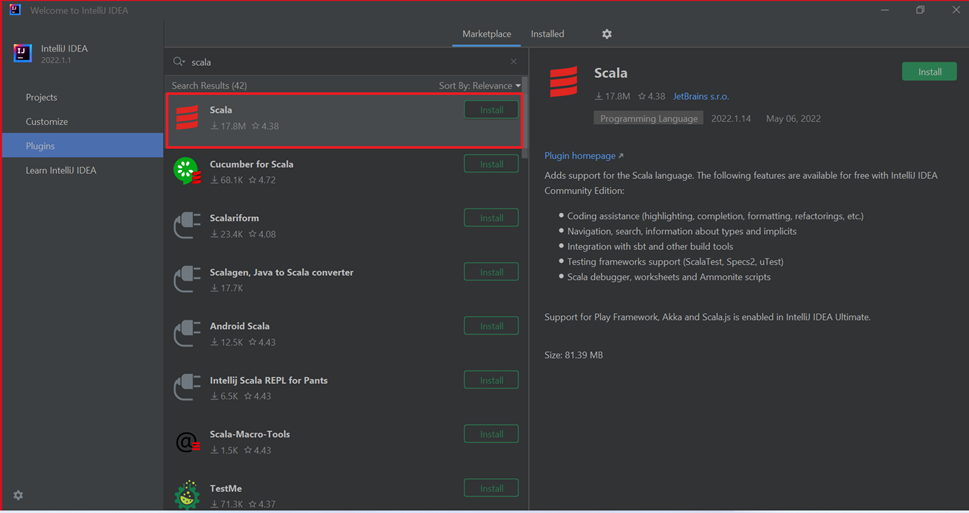
Vyberte Nainstalovat pro modul plug-in Scala, který je doporučený v novém okně.
Po úspěšné instalaci modulu plug-in je potřeba restartovat integrované vývojové prostředí (IDE).
Použití IntelliJ k vytvoření aplikace
Spusťte IntelliJ IDEA a výběrem možnosti Vytvořit nový projekt otevřete okno Nový projekt.
V levém podokně vyberte Apache Spark/HDInsight .
V hlavním okně vyberte Spark Project (Scala ).
V rozevíracím seznamu Nástroje sestavení vyberte jednu z následujících hodnot:
- Podpora Průvodce vytvořením projektu Maven pro Scala
- SBT pro správu závislostí a sestavování pro projekt Scala.
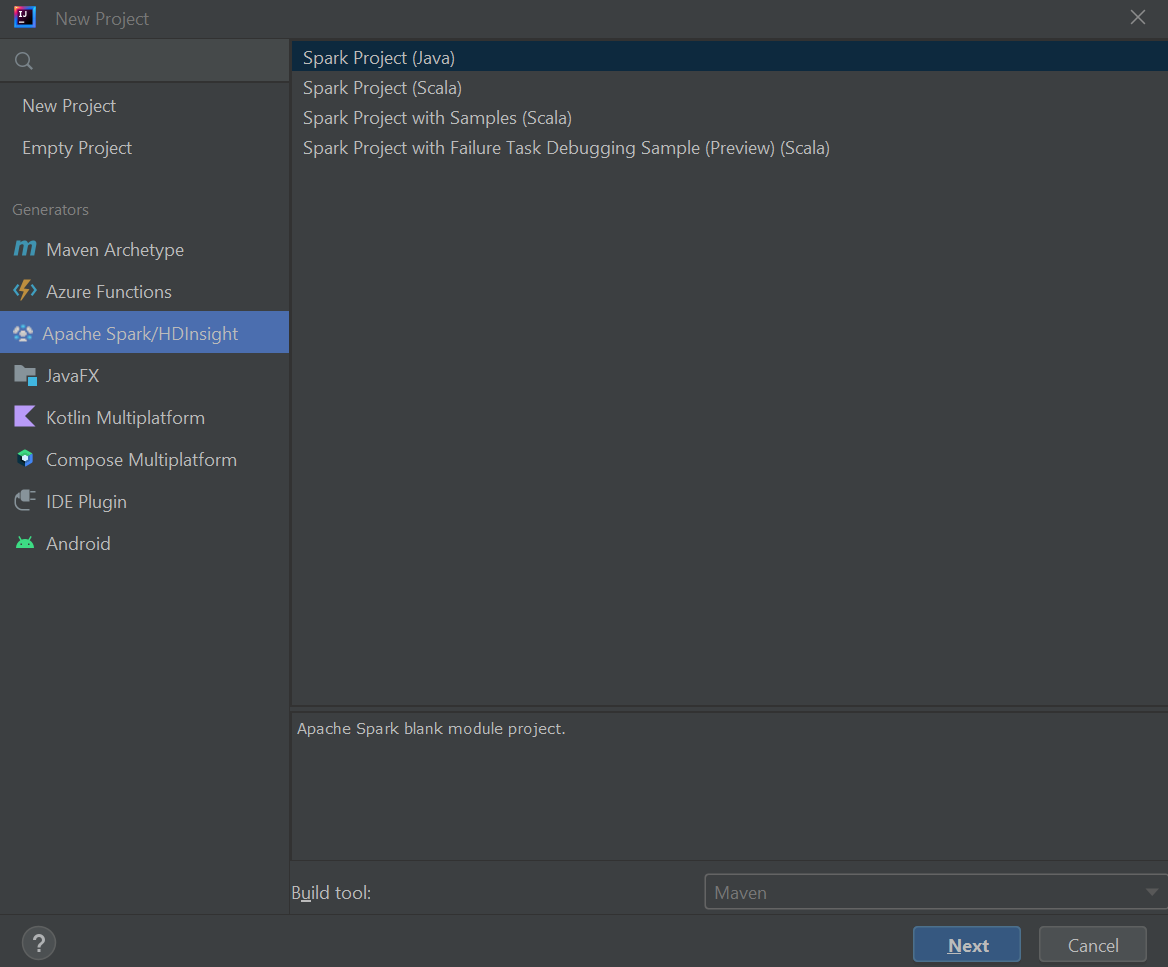
Vyberte Další.
V okně Nový projekt zadejte následující informace:
Vlastnost Popis Název projektu Zadejte název. Umístění projektu Zadejte umístění pro uložení projektu. Project SDK Toto pole bude prázdné při prvním použití funkce IDEA. Vyberte Nový... a přejděte na sadu JDK. Verze Sparku Průvodce vytvořením integruje správnou verzi sady Spark SDK a Scala SDK. Pokud je verze clusteru Spark nižší než 2.0, vyberte Spark 1.x. V opačném případě vyberte Spark 2.x. V tomto příkladu se používá Spark 2.3.0 (Scala 2.11.8). 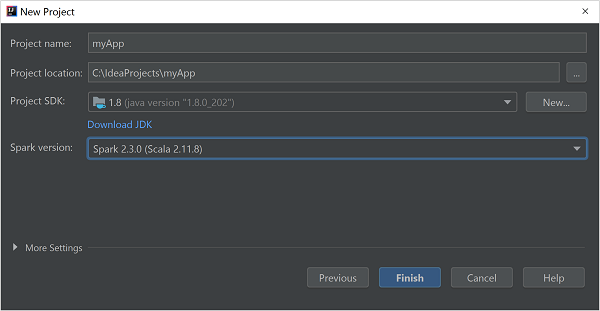
Vyberte Dokončit.
Vytvoření samostatného projektu Scala
Spusťte IntelliJ IDEA a výběrem možnosti Vytvořit nový projekt otevřete okno Nový projekt.
V levém podokně vyberte Maven .
Zadejte Project SDK (Sada SDK projektu). Pokud je tato hodnota prázdná, vyberte Nový... a přejděte do instalačního adresáře Java.
Zaškrtněte políčko Vytvořit z archetypu.
Ze seznamu archetypů vyberte
org.scala-tools.archetypes:scala-archetype-simple. Tento archetyp vytvoří správnou adresářovou strukturu a stáhne požadované výchozí závislosti pro zápis programu Scala.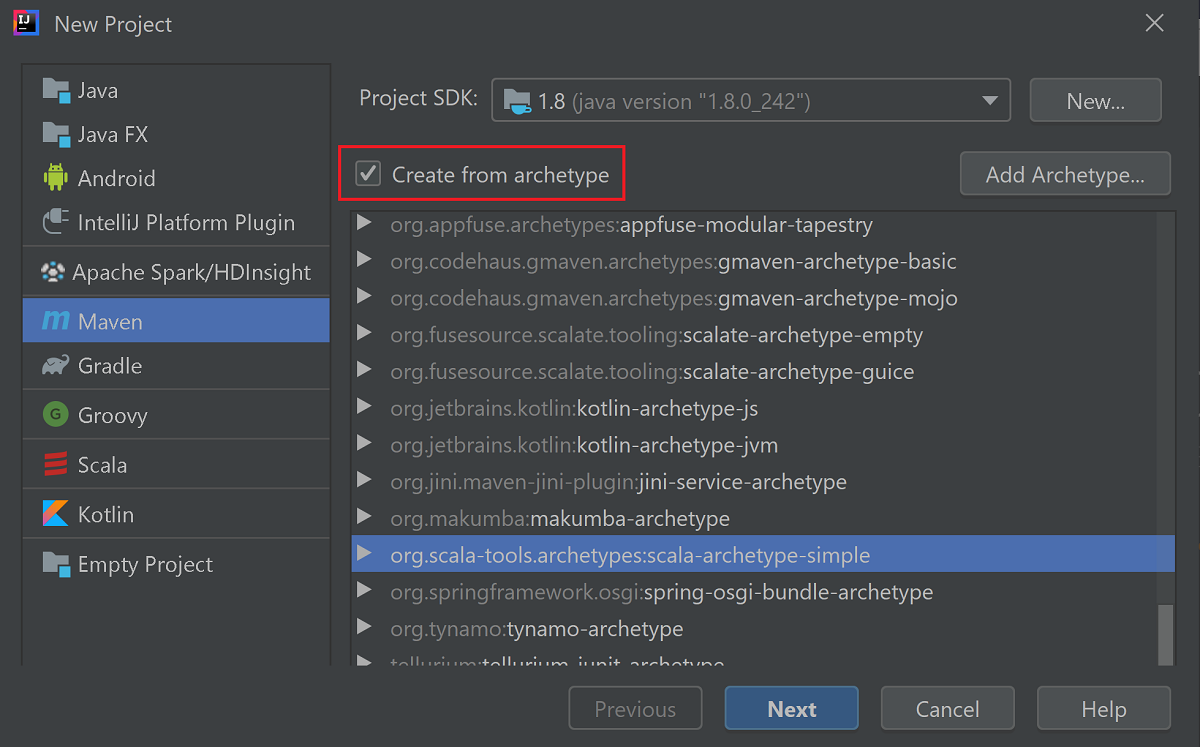
Vyberte Další.
Rozbalit souřadnice artefaktů Zadejte relevantní hodnoty pro GroupId a ArtifactId. Název a umístění se automaticky vyplní. V tomto kurzu se používají následující hodnoty:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
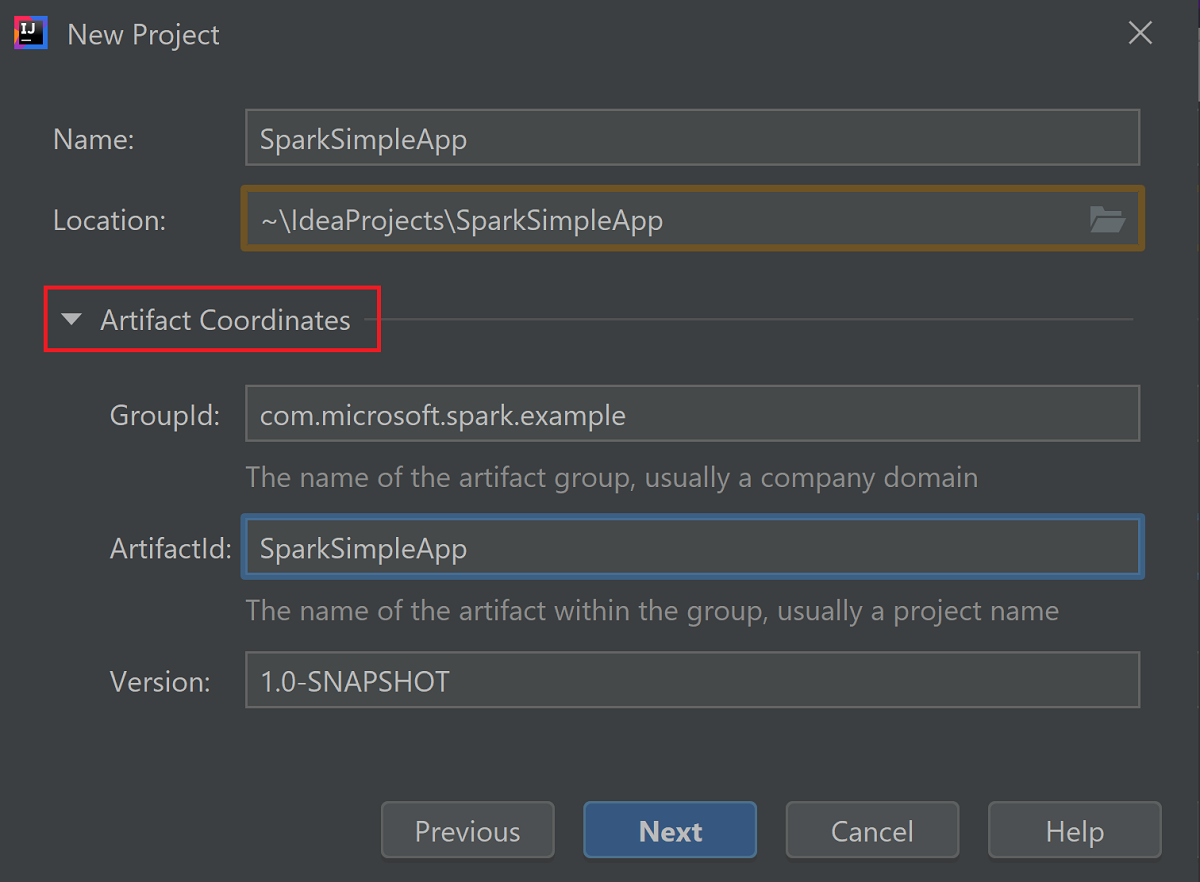
Vyberte Další.
Zkontrolujte nastavení a pak vyberte Next (Další).
Ověřte název a umístění projektu a pak vyberte Finish (Dokončit). Import projektu bude trvat několik minut.
Po importu projektu přejděte z levého podokna na příklad testovací>scala>com>microsoft>sparku>sparku Sparku na SparkSimpleApp.>> Klikněte pravým tlačítkem myši na MySpec a pak vyberte Odstranit.... Tento soubor pro aplikaci nepotřebujete. V dialogovém okně vyberte OK .
V pozdějších krocích aktualizujete pom.xml , abyste definovali závislosti pro aplikaci Spark Scala. Aby se tyto závislosti stahovaly a přeložily automaticky, musíte nakonfigurovat Maven.
V nabídce Soubor vyberte Nastavení a otevřete okno Nastavení.
V okně Nastavení přejděte do importu nástroje sestavení sestavení sestavení sestavení Sestavení Nástroje nástroje nástroje pro sestavení>>v Nastavení.>
Zaškrtněte políčko Automaticky importovat projekty Maven.
Vyberte Apply (Použít) a pak vyberte OK. Pak se vrátíte do okna projektu.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::V levém podokně přejděte na hlavní>scala>src>com.microsoft.spark.example a poklikáním na aplikaci otevřete App.scala.
Nahraďte stávající vzorový kód následujícím kódem a uložte změny. Tento kód čte data z HVAC.csv (k dispozici ve všech clusterech HDInsight Spark). Načte řádky, které mají v šestém sloupci pouze jednu číslici. Zapíše výstup do /HVACOut pod výchozím kontejnerem úložiště clusteru.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }V levém podokně dvakrát klikněte na soubor pom.xml.
Mezi
<project>\<properties>přidejte následující segmenty:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Mezi
<project>\<dependencies>přidejte následující segmenty:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Vytvořte soubor .jar. IntelliJ IDEA umožňuje vytvoření souboru JAR jako artefaktu projektu. Proveďte následující kroky.
V nabídce Soubor vyberte Projektová struktura....
V okně Struktura projektu přejděte na Artefakty>symbol plus +>JAR>z modulů se závislostmi....
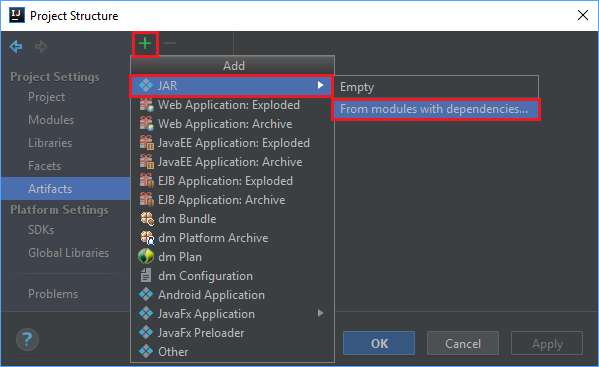
V okně Vytvořit soubor JAR z modulů vyberte ikonu složky v textovém poli Hlavní třída .
V okně Vybrat hlavní třídu vyberte třídu, která se zobrazí ve výchozím nastavení, a pak vyberte OK.
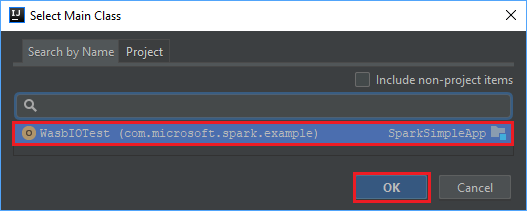
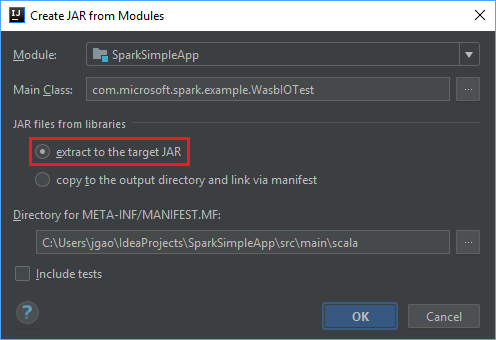
V okně Vytvořit soubor JAR z modulů se ujistěte, že je vybraná možnost extrahovat do cílového souboru JAR , a pak vyberte OK. Toto nastavení vytvoří jeden soubor JAR se všemi závislostmi.
Karta Rozložení výstupu obsahuje seznam všech souborů JAR, které jsou součástí projektu Maven. Můžete vybrat a odstranit soubory, na kterých aplikace Scala nemá přímou závislost. Pro aplikaci, kterou tady vytváříte, můžete odebrat všechny kromě posledního (výstup kompilace SparkSimpleApp). Vyberte soubory JAR, které chcete odstranit, a pak vyberte záporný symbol -.
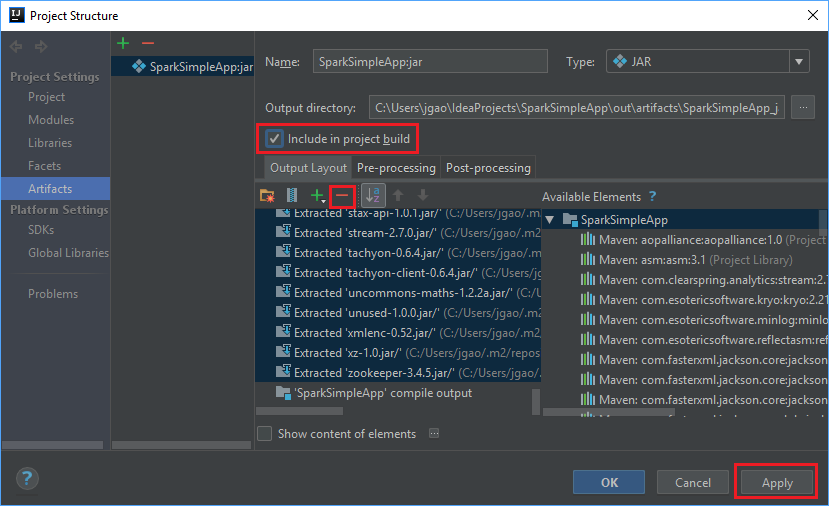
Ujistěte se, že je zaškrtnuté políčko Zahrnout do sestavení projektu. Tato možnost zajistí, že se soubor JAR vytvoří při každém sestavení nebo aktualizaci projektu. Vyberte Použít a pak OK.
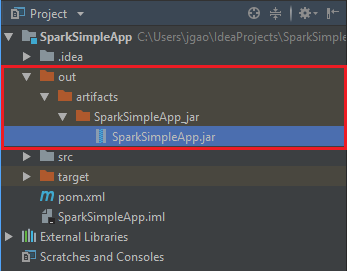
Pokud chcete vytvořit soubor JAR, přejděte do sestavení>sestavení artefaktů>sestavení. Projekt se zkompiluje přibližně za 30 sekund. Výstupní soubor JAR se vytvoří v adresáři \out\artifacts.
Spuštění aplikace v clusteru Apache Spark
Ke spuštění aplikace v clusteru můžete použít následující postupy:
Zkopírujte soubor JAR aplikace do objektu blob služby Azure Storage přidruženého ke clusteru. Můžete k tomu použít nástroj příkazového řádku AzCopy. Existuje také řada dalších klientů, které můžete k nahrání dat použít. Další informace o nich najdete v tématu Nahrání dat pro úlohy Apache Hadoop ve službě HDInsight.
Pomocí Apache Livy odešlete úlohu aplikace vzdáleně do clusteru Spark. Clustery Spark ve službě HDInsight zahrnují rozhraní Livy, které zveřejňuje koncové body REST pro vzdálené odesílání úloh Sparku. Další informace najdete v tématu Vzdálené odesílání úloh Apache Spark pomocí Apache Livy s clustery Spark ve službě HDInsight.
Vyčištění prostředků
Pokud nebudete tuto aplikaci dál používat, odstraňte cluster, který jste vytvořili, pomocí následujícího postupu:
Přihlaste se k portálu Azure.
Do vyhledávacího pole v horní části zadejte HDInsight.
V části Služby vyberte clustery HDInsight.
V seznamu clusterů HDInsight, které se zobrazí, vyberte ... vedle clusteru, který jste vytvořili pro účely tohoto kurzu.
Vyberte Odstranit. Vyberte Ano.
Další krok
V tomto článku jste se dozvěděli, jak vytvořit aplikaci Apache Spark scala. V dalším článku zjistíte, jak tuto aplikaci spustit v clusteru HDInsight Spark pomocí Livy.