準備使用 Apache Spark
Apache Spark 是一種分散式資料處理架構,可協調叢集 (在 Microsoft Fabric 中稱為 Spark 集區) 中多個處理節點的工作,以進行大規模的資料分析。 更簡單來說,Spark 會使用「分治」方法,藉由將工作分散到多部電腦,以快速處理大量的資料。 Spark 會為您處理散發工作和校對結果的流程。
Spark 可以執行以各種語言撰寫的程式碼,包括 JAVA、Scala (以 JAVA 為基礎的指令碼語言)、Spark R、Spark SQL 和 PySpark (Python 的 Spark 特定變體)。 事實上,大部分的資料工程和分析工作負載都會使用 PySpark 和 Spark SQL 的組合來完成。
Spark 集區
Spark 集區是由散發資料處理工作的計算節點所組成。 下圖顯示一般架構。
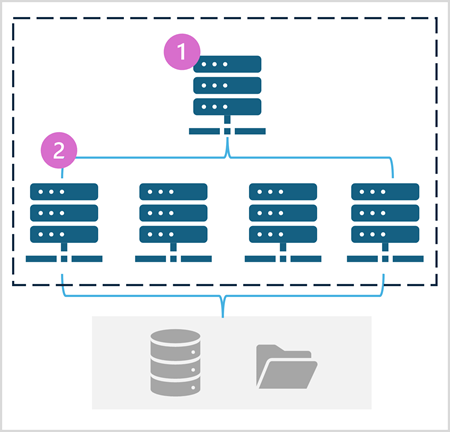
如下圖所示,Spark 集區包含兩種節點:
- Spark 集區中的前端節點會透過驅動程式協調分散式程序。
- 集區包含多個背景工作角色節點,執行程式會在這些節點上執行實際資料處理工作。
Spark 集區會使用此分散式計算架構,以存取和處理相容資料存放區中的資料,例如以 OneLake 為基礎的資料湖存放庫。
Microsoft Fabric 中的 Spark 集區
Microsoft Fabric 在每個工作區中提供入門集區,讓您能夠以最精簡的設定快速啟動與執行 Spark 作業。 您可以設定入門集區,根據特定的工作負載需求或成本限制,將其所包含的節點最佳化。
此外,您可以使用支援特定資料處理需求的特定節點設定,以建立自訂 Spark 集區。
注意
Fabric 管理員可以在 Fabric 容量層級停用自訂 Spark 集區設定的功能。 如需詳細資訊,請參閱 Fabric 文件中資料工程和資料科學的功能管理設定。
您可以在工作區設定的 [資料工程/科學] 區段中,管理入門集區的設定並建立新的 Spark 集區。
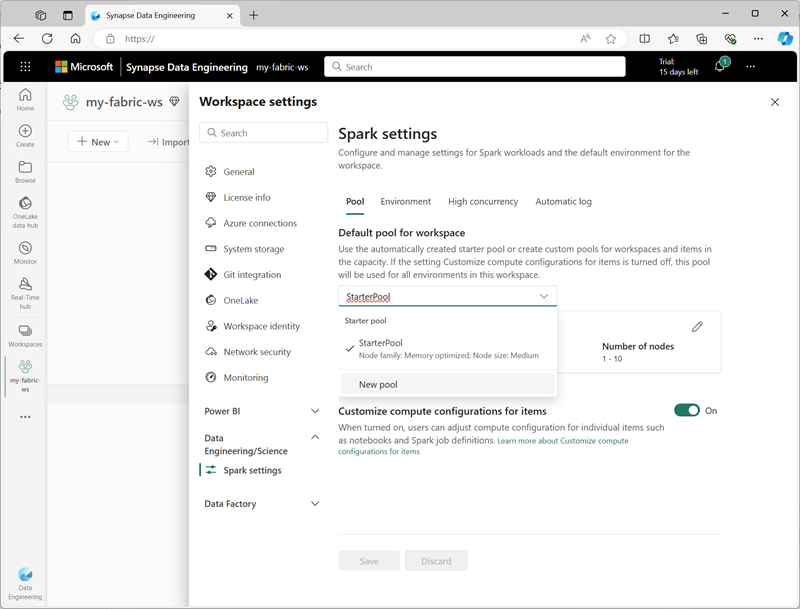
Spark 集區的特定設定包括:
- 節點系列:用於 Spark 叢集節點的虛擬機器類型。 在大部分情況下,記憶體最佳化的節點可提供最佳效能。
- 自動調整:視需要是否要自動佈建節點,如果是,則為要配置給集區的初始和最大節點數目。
- 動態配置:是否根據資料磁碟區,在背景工作角色節點上動態配置執行程式程序。
如果在工作區中建立一或多個自訂 Spark 集區,您可以將其中一個集區 (或入門集區) 設為預設集區,在沒有為指定 Spark 作業指定特定集區時使用。
提示
如需在 Microsoft Fabric 中管理 Spark 集區的詳細資訊,請參閱在 Microsoft Fabric 文件中,在 Microsoft Fabric 中設定入門集區,以及如何在 Microsoft Fabric 中建立自訂 Spark 集區。
執行階段和環境
Spark 開放原始碼生態系統包含多個版本的 Spark 執行階段,可判斷已安裝的 Apache Spark、Delta Lake、Python 和其他核心軟體元件版本。 此外,您可以在執行階段安裝和使用各種程式碼程式庫,以進行一般 (有時非常專業) 的工作。 由於使用 PySpark 執行大量的 Spark 處理,因此 Python 程式庫範圍很大,可確保無論您需要執行的工作為何,都可能有程式庫可協助。
在某些案例中,組織可能需要定義多個環境,以支援各種不同的資料處理工作。 每個環境都會定義特定的執行階段版本,以及必須安裝才能執行特定作業的程式庫。 然後,資料工程師和科學家可以針對特定工作選取要與 Spark 集區搭配使用的環境。
Microsoft Fabric 的 Spark 執行階段
Microsoft Fabric 支援多個 Spark 執行階段,而且會在發佈時繼續新增對執行階段的支援。 您可以使用工作區設定介面,來指定 Spark 集區啟動時,預設使用的 Spark 執行階段。
提示
如需 Microsoft Fabric 中 Spark 執行階段的詳細資訊,請參閱 Microsoft Fabric 文件中在 Fabric 中的 Apache Spark 執行階段。
Microsoft Fabric 中的環境
您可以在 Fabric 工作區中建立自訂環境,就能針對不同的資料處理作業,使用特定的 Spark 執行階段、程式庫和設定。
![Microsoft Fabric 中 [環境] 頁面的螢幕擷取畫面。](../../wwl/use-apache-spark-work-files-lakehouse/media/spark-environment.png)
您可以在建立環境時,執行以下操作:
- 指定其應使用的 Spark 執行階段。
- 檢視每個環境中安裝的內建程式庫。
- 從 Python 套件索引 (PyPI) 安裝特定的公用程式庫。
- 上傳套件檔案以安裝自訂程式庫。
- 指定環境應使用的 Spark 集區。
- 指定 Spark 設定屬性,以覆寫預設行為。
- 上傳環境中需要提供的資源檔案。
建立至少一個自訂環境之後,您可以將其指定為工作區設定中的預設環境。
提示
如需在 Microsoft Fabric 中使用自訂環境的詳細資訊,請參閱 Microsoft Fabric 文件中的在 Microsoft Fabric 中建立、設定及使用環境。
其他 Spark 設定選項
Spark 集區和環境的管理,是您可以在 Fabric 工作區中管理 Spark 處理的主要方式。 不過,有一些其他選項可供您用來進一步執行最佳化。
原生執行引擎
Microsoft Fabric 中的原生執行引擎是向量化的處理引擎,可直接在湖存放庫基礎結構上執行 Spark 操作。 使用原生執行引擎,可在使用 Parquet 或 Delta 檔案格式的大型資料集時,大幅改善查詢效能。
若要使用原生執行引擎,您可以在環境層級或個別筆記本內將其啟用。 若要在環境層級啟用原生執行引擎,請在環境設定中設定下列 Spark 屬性:
- spark.native.enabled:true
- spark.shuffle.manager:org.apache.spark.shuffle.sort.ColumnarShuffleManager
若要啟用特定指令碼或筆記本的原生執行引擎,您可以如下所示,在程式碼開頭設定這些設定屬性:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
提示
如需原生執行引擎的詳細資訊,請參閱 Microsoft Fabric 文件中的 Fabric Spark 中的原生執行引擎。
高並行模式
當您在 Microsoft Fabric 中執行 Spark 程式碼時,即會起始 Spark 工作階段。 您可以使用高並行模式,跨多個並行使用者或程序共用 Spark 工作階段,以最佳化 Spark 資源使用方式的效率。 針對 Notebook 啟用高並行模式時,多名使用者都可以在使用相同 Spark 工作階段的筆記本中執行程式碼,同時確保程式碼是隔離的,以避免某個筆記本中的變數受到另一個筆記本中的程式碼影響。 您也可以啟用 Spark 作業的高並行模式,讓非互動式的並行 Spark 指令碼執行也有類似的效率。
若要啟用高並行模式,請使用工作區設定介面的 [資料工程/科學] 區段。
提示
如需高並行模式的詳細資訊,請參閱 Microsoft Fabric 文件中適用於 Fabric 的 Apache Spark 中的高並行模式。
自動 MLFlow 記錄
MLFlow 是開放原始碼程式庫,用於資料科學工作負載,以管理機器學習訓練和模型部署。 MLFlow 的主要功能是,能夠記錄模型訓練和管理操作。 根據預設,Microsoft Fabric 會使用 MLFlow,以隱含記錄機器學習實驗活動,而不需要資料科學家加入明確的程式碼,來進行記錄。 您可以在工作區設定中停用此功能。
Fabric 容量的 Spark 管理
管理員可以在 Fabric 容量層級管理 Spark 設定,讓他們能夠限制和覆寫組織內工作區中的 Spark 設定。
提示
如需在 Fabric 容量層級管理 Spark 組態的詳細資訊,請參閱 Microsoft Fabric 文件中的設定和管理 Fabric 容量的資料工程和資料科學設定。