Fabric Spark 的原生執行引擎
原生執行引擎是 Microsoft Fabric 中 Apache Spark 工作執行的開創性加強程式。 此向量化引擎會直接在 Lakehouse 基礎結構上執行 Spark 查詢,以最佳化 Spark 查詢的效能和效率。 引擎的無縫整合表示不需要修改程式碼,並避免廠商鎖定。 它支援 Apache Spark API,且與 運行時間 1.3 (Apache Spark 3.5) 相容,而且可搭配 Parquet 和 Delta 格式使用。 無論您的資料在 OneLake 內的位置為何,或如果您透過捷徑存取資料,原生執行引擎都會將效率和效能最大化。
原生執行引擎可大幅提升查詢效能,同時將營運成本降至最低。 與傳統的 OSS(開放原始碼軟體)Spark 相比,它提供了顯著的速度提升,效能增加至四倍,這已由 TPC-DS 1 TB 基準測試驗證。 引擎擅長管理各種資料處理案例,範圍從例行資料擷取、批次作業和 ETL (擷取、轉換、載入) 工作到複雜的資料科學分析和回應式互動查詢。 使用者可受益於加速處理時間、提高輸送量,以及最佳化資源使用率。
原生執行引擎以兩個關鍵的 OSS 元件為基礎:Velox 是由 Meta 推出的 C++ 資料庫加速程式庫,而 Apache Gluten (孵化中) 則是由 Intel 推出的中間層,負責將 JVM 型 SQL 引擎的執行卸載至原生引擎。
注意
原生執行引擎目前已公開預覽。 如需詳細資訊,請參閱目前的限制。 我們鼓勵您在工作負載上啟用原生執行引擎,而不需要額外費用。 您將受益於更快的作業執行,而不需要支付更多費用-實際上,您會為相同的工作支付較少的費用。
使用原生執行引擎的時機
原生執行引擎提供在大型資料集上執行查詢的解決方案;它會使用基礎資料來源的原生功能來最佳化效能,並將通常與傳統Spark環境中的資料移動和串行化相關聯的額外負荷降到最低。 引擎支援各種運算子和資料類型,包括彙總雜湊彙總、廣播巢狀迴圈聯結 (BNLJ),以及精確的時間戳記格式。 不過,若要完全受益於此引擎的功能,您應該考慮其最佳使用案例:
- 使用 Parquet 和 Delta 格式的資料時,此引擎很有效,它能以原生且有效率的方式處理。
- 涉及複雜轉換和彙總的查詢可大幅受益於引擎的分欄處理和向量化功能。
- 效能提升最顯著的情況是,查詢不會因避免不支援的功能或運算式而觸發後援機制。
- 此引擎非常適合需要大量運算的查詢,而不是簡單或 I/O 繫結。
如需原生執行引擎所支援的運算子和函式資訊,請參閱 Apache Gluten 文件。
啟用原生執行引擎
若要在預覽階段使用原生執行引擎的完整功能,則需要特定的設定。 下列程式示範如何針對筆記本、Spark 工作定義和整個環境啟用此功能。
重要
原生執行引擎支援最新的 GA 運行時間版本,也就是 Runtime 1.3(Apache Spark 3.5、Delta Lake 3.2)。 在 Runtime 1.3 中發行原生執行引擎時,已停止對舊版的運行時間 1.2(Apache Spark 3.4,Delta Lake 2.4)的支援。 我們鼓勵所有客戶升級至最新的 Runtime 1.3。 如果您在運行時間 1.2 上使用原生執行引擎,原生加速很快就會停用。
在環境層級啟用
若要確保統一的效能增強,請在與環境相關聯的所有工作和筆記本上啟用原生執行引擎:
瀏覽至環境設定。
移至 Spark 計算。
移至 [ 加速 ] 索引標籤。
核取標示為 [啟用原生執行引擎] 的方塊。
儲存併發佈 變更。
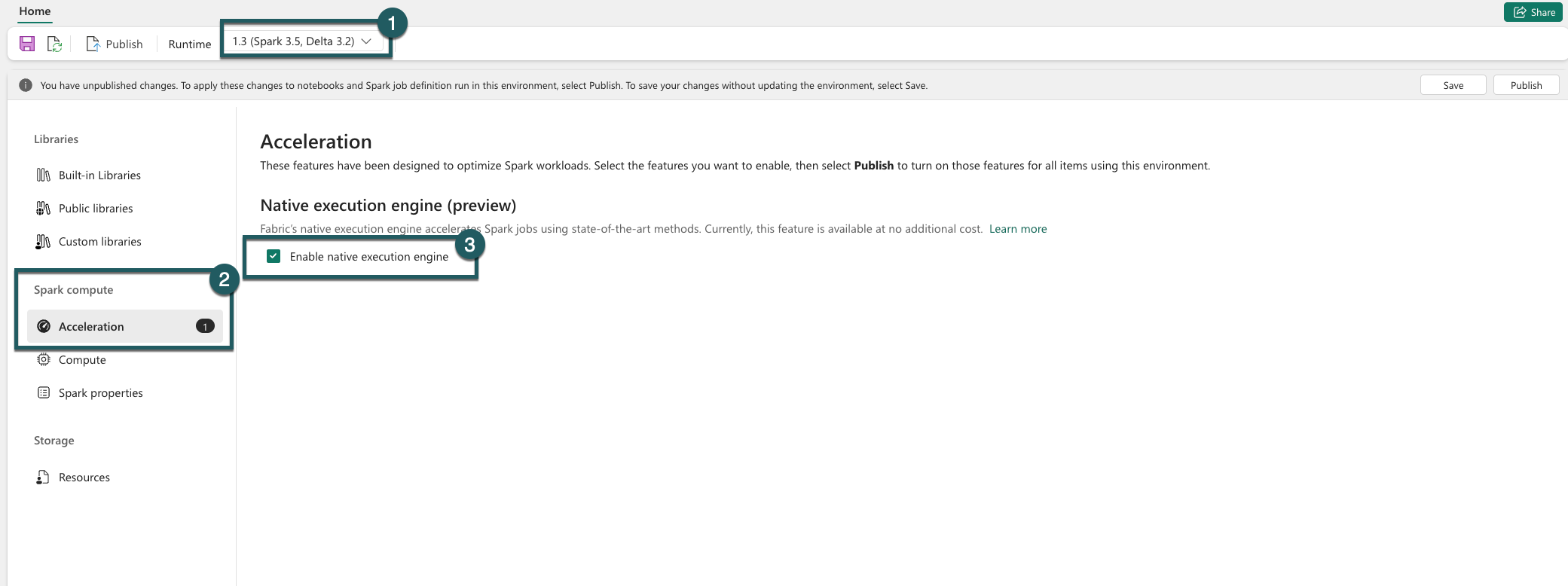

在環境層級啟用時,所有後續工作和筆記本都會繼承設定。 此繼承可確保環境中建立的任何新工作階段或資源都會自動受益於增強的執行功能。
重要
先前,原生執行引擎是透過環境組態內的Spark設定來啟用。 透過我們最新的更新(進行中推出),我們已在環境設定的 [加速] 索引標籤中引進切換按鈕,來簡化此動作。 使用新的切換重新啟用原生執行引擎 - 若要繼續使用原生執行引擎,請移至環境設定中的 [加速] 索引卷標,然後透過切換按鈕加以啟用。 UI 中的新切換設定現在優先於任何先前的Spark屬性組態。 如果您先前透過 Spark 設定啟用原生執行引擎,則會停用它,直到透過 UI 切換重新啟用為止。
針對筆記本或 Spark 工作定義啟用
若要啟用單一筆記本或 Spark 工作定義的原生執行引擎,您必須在執行指令碼開頭納入必要的設定:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
針對筆記本,請在第一個儲存格中插入必要的組態命令。 針對 Spark 工作定義,請在 Spark 工作定義的前線包含組態。 原生執行引擎會與即時集區整合,因此一旦啟用此功能,它就會立即生效,而不需要您起始新的會話。
重要
在啟動 Spark 工作階段之前,必須先設定原生執行引擎。 Spark 工作階段啟動之後,spark.shuffle.manager 設定會變成固定且無法變更。 請確定這些組態是在筆記本中的 %%configure 區塊內,或在 Spark 工作定義的 Spark 工作階段產生器中設定。
查詢層級上的控制
在租用戶、工作區和環境層級啟用原生執行引擎,並與 UI 無縫整合的機制正在積極開發中。 同時,您可以停用特定查詢的原生執行引擎,尤其是當查詢涉及目前不支援的運算子時 (請參閱限制)。 若要停用,請針對包含查詢的特定儲存格,將 Spark 組態 spark.native.enabled 設定為 false。
%%sql
SET spark.native.enabled=FALSE;

執行停用原生執行引擎的查詢之後,您必須將spark.native.enabled 設定為 true,為後續儲存格重新啟用它。 此步驟是必要的,因為 Spark 會循序執行程式碼儲存格。
%%sql
SET spark.native.enabled=TRUE;
識別引擎執行的作業
有數種方法可用來判斷 Apache Spark 工作中的運算子是否使用原生執行引擎來處理。
Spark UI 和 Spark 歷程記錄伺服器
存取 Spark UI 或 Spark 歷程記錄伺服器,以找出您需要檢查的查詢。 若要存取 Spark Web UI,請流覽至 Spark 作業定義並加以執行。 從 [執行] 索引標籤中,選取 [應用程式名稱 旁邊的 ...],然後選取 [開啟 Spark Web UI]。 您也可以從工作區中的 [監視器] 索引標籤進入 Spark UI。 從 [監視] 頁面中,選取筆記本或管線,即可直接存取作用中作業的 Spark UI。

在 Spark UI 介面中顯示的查詢計劃中,尋找任何以 Transformer、*NativeFileScan 或 VeloxColumnarToRowExec作為後綴結尾的節點名稱。 後置詞表示原生執行引擎已執行作業。 例如,節點可能會標示為 RollUpHashAggregateTransformer、ProjectExecTransformer、BroadcastHashJoinExecTransformer、ShuffledHashJoinExecTransformer 或 BroadcastNestedLoopJoinExecTransformer。

DataFrame 說明
或者,您可以在筆記本中執行 df.explain() 命令,以檢視執行計劃。 在輸出中,尋找相同的 Transformer、*NativeFileScan 或 VeloxColumnarToRowExec 後綴。 此方法提供快速的方式,以確認原生執行引擎是否正在處理特定作業。

後援機制
在某些情況下,原生執行引擎可能會因為不支援的功能等原因而無法執行查詢。 在這些情況下,此作業會退回到傳統的 Spark 引擎。 此 自動 後援機制可確保工作流程不會中斷。


監視引擎執行的查詢和數據框架
若要進一步瞭解原生執行引擎如何套用至 SQL 查詢和數據框架作業,以及向下切入至階段和運算符層級,您可以參考 Spark UI 和 Spark 歷程記錄伺服器,以取得原生引擎執行的詳細資訊。
原生執行引擎索引標籤
您可以流覽至新的 [麩質 SQL / 數據框架] 索引標籤,以檢視麩質組建資訊和查詢執行詳細數據。 [查詢] 數據表提供在原生引擎上執行的節點數目,以及針對每個查詢回復至 JVM 的節點數目的深入解析。

查詢執行圖形
您也可以在 Apache Spark 查詢執行計劃的視覺化中選取查詢描述。 執行圖表會跨階段及其個別作業提供原生執行詳細數據。 背景色彩區分執行引擎:綠色代表原生執行引擎,而淺藍色表示作業是在預設 JVM 引擎上執行。

限制
雖然原生執行引擎可增強 Apache Spark 工作的效能,但請注意其目前的限制。
- 目前尚不支援某些Delta特定的操作(我們正積極處理),包括合併操作、檢查點掃描和刪除向量。
- 某些 Spark 功能和運算式與原生執行引擎不相容,例如使用者定義函式 (UDF) 和
array_contains函式,以及 Spark 結構化串流。 使用這些不相容的作業或函式作為匯入程式庫的一部分,也會導致退回到 Spark 引擎。 - 使用私人端點的儲存解決方案的掃描目前尚未支援(我們正在積極進行相關工作)。
- 引擎不支援 ANSI 模式,因此它會搜尋,一旦啟用 ANSI 模式,它就會自動回復為 Vanilla Spark。
在查詢中使用日期篩選時,請務必確保雙方的數據類型一致,以避免效能問題。 不相符的資料類型可能無法提升查詢的執行效率,而且可能需要明確的轉換。 請務必確定比較的左側 (LHS) 和右側 (RHS) 的數據類型完全相同,因為不相符的類型不一定會自動轉換。 如果類型不相符是不可避免的,請使用明確轉換來比對資料類型,例如 CAST(order_date AS DATE) = '2024-05-20'。 原生執行引擎不會加速資料類型不符的查詢,因此確保類型一致性對於維持效能至關重要。 例如,與其使用 order_date = '2024-05-20' 其中 order_date 是 DATETIME ,而且字串是 DATE,不如將 order_date 明確轉換成 DATE 以確保一致的資料類型並改善效能。