資料行存放區索引:概觀
適用於:![]() Microsoft Fabric 中的 SQL Server
Microsoft Fabric 中的 SQL Server ![]() Azure SQL 資料庫 Azure SQL 受控執行個體
Azure SQL 資料庫 Azure SQL 受控執行個體![]()
![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() SQL Database
SQL Database
「資料行存放區索引」是儲存和查詢大型資料倉儲事實資料表的標準。 此索引使用以資料行為基礎的資料儲存和查詢處理,相較於傳統的資料列導向儲存,最高可在您的資料倉儲中達到 10 倍的查詢效能改善。 相較於未壓縮的資料大小,您也可以將資料壓縮提升高達 10 倍。 從 SQL Server 2016 (13.x) SP1 開始,資料行存放區索引可啟用作業分析:在交易式工作負載上執行高效能即時分析的能力。
深入了解相關案例:
何謂資料行存放區索引?
資料行存放區索引是使用單欄式資料格式 (稱為資料行存放區) 儲存、擷取及管理資料的一項技術。
主要詞彙和概念
以下是與資料行存放區索引相關聯的主要詞彙和概念。
columnstore
資料行存放區是以邏輯方式組織成資料表的資料,其中包含資料列和資料行,並且會以資料行取向的資料格式實際儲存。
資料列存放區
資料列存放區是以邏輯方式組織成資料表的資料,其中包含資料列和資料行,並且會以資料列取向的資料格式實際儲存。 此格式是傳統儲存關聯式資料表資料的方式。 在 SQL Server 中,資料列存放區是指其基礎資料格式為堆積、叢集索引或記憶體最佳化資料表的資料表。
注意
在資料行存放區索引的相關討論中,資料列存放區和資料行存放區等詞用於強調資料儲存的格式。
資料列群組
資料列群組是指同時壓縮成資料行存放區格式的一組資料列。 資料列群組通常包含了每個資料列群組的資料列數目上限,即 1,048,576 個資料列。
為達到高效能和高壓縮率,資料行存放區索引會將資料表切割為資料列群組,然後以資料行取向的方式壓縮每個資料列群組。 資料列群組中的資料列數目必須多到足以改善壓縮率,並且少到足以獲益於記憶體中作業。
資料列群組,其中所有資料都已從 COMPRESSED 轉換成 TOMBSTONE 狀態,並在稍後由名為 Tuple Mover 的背景處理序移除。 如需有關資料列群組狀態的詳細資訊,請參閱 sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)。
提示
太多小型資料列群組會降低資料行存放區索引的品質。 在 SQL Server 2017 (14.x) 之前,需要遵循內部閾值原則來進行重新組織作業,以合併較小的 COMPRESSED 資料列群組,該內部閾值原則會決定如何移除已刪除的資料列以及合併已壓縮的資料列群組。
從 SQL Server 2019 (15.x) 開始,背景合併工作也適用於合併已刪除大量資料列的 COMPRESSED 資料列群組。
合併較小的資料列群組之後,索引品質應該會改善。
注意
從 SQL Server 2019 (15.x)、Azure SQL Database、Azure SQL 受控執行個體和 Azure Synapse Analytics 中的專用 SQL 集區開始,背景合併工作將會協助 Tuple Mover,該工作會自動壓縮已存在一段時間的較小 OPEN 差異資料列群組 (由內部閾值決定),或合併已刪除大量資料列的 COMPRESSED 資料列群組。 這可改善一段時間的資料行存放區索引品質。
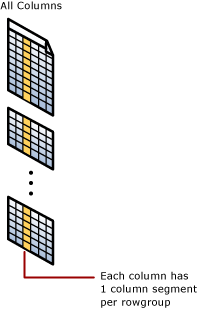
資料行區段
資料行區段是指資料列群組內部的資料行。
- 每一個資料列群組會針對資料表中的每一個資料行包含一個資料行區段。
- 每個資料行區段會各自壓縮成一體並且儲存到實體媒體上。
- 每個區段都有中繼資料,可讓您快速刪除區段,而不需讀取它們。
叢集資料行存放區索引
叢集資料行存放區索引是整個資料表的實體儲存體。

為降低資料行區段形成片段的程度並提升效能,資料行存放區索引可能會暫時將一些資料儲存到叢集索引 (稱為「差異存放區」),並儲存已刪除資料列識別碼的 B 型樹狀結構清單。 差異存放區作業將由幕後處理。 為了能傳回正確的查詢結果,叢集資料行存放區索引會結合資料行存放區和差異存放區兩方面的查詢結果。
注意
文件通常會使用「B 型樹狀結構」一詞來指稱索引。 在資料列存放區索引中,資料庫引擎會實作 B+ 樹狀結構。 這不適用於資料行存放區索引或經記憶體最佳化的資料表。 如需詳細資訊,請參閱《SQL Server 和 Azure SQL 索引架構和設計指南》。
差異資料列群組
差異資料列群組是僅能搭配資料行存放區索引使用的叢集 B 型樹狀結構索引。 其可藉由儲存資料列,直到資料列數達到閾值 (1,048,576 個資料列) 後移入資料行存放區,以改善資料行存放區的壓縮與效能。
差異資料列群組一旦達到資料列數目上限,就會從 OPEN 轉換為 CLOSED 狀態。 名為 Tuple Mover 的背景處理序會檢查已關閉的資料列群組。 如果處理序發現已關閉的資料列群組,便會壓縮差異資料列群組,並將其儲存至資料行存放區中作為 COMPRESSED 資料列群組。
當差異資料列群組已壓縮時,現有的差異資料列群組會轉換成 TOMBSTONE 狀態,供 Tuple Mover 稍後在其沒有參考時移除。
如需有關資料列群組狀態的詳細資訊,請參閱 sys.dm_db_column_store_row_group_physical_stats (Transact-SQL)。
注意
從 SQL Server 2019 (15.x) 開始,背景合併工作將會協助 Tuple Mover,該工作會自動壓縮已存在一段時間的較小 OPEN 差異資料列群組 (由內部閾值決定),或合併已刪除大量資料列的 COMPRESSED 資料列群組。 這可改善一段時間的資料行存放區索引品質。
差異存放區
資料行存放區索引可以有多個差異資料列群組。 所有差異資料列群組統稱為差異存放區。
在大規模的大量載入過程中,大多數資料列會直接進入資料行存放區,而不經過差異存放區。 大量載入結束時,某些資料列可能因為數量太少,而不符合資料列群組 102,400 個資料列的大小下限。 因此,最後這些資料列就會進入差異存放區,而不是資料行存放區。 若是少於 102,400 個資料列的小規模大量載入,則所有資料列都將直接進入差異存放區。
非叢集資料行存放區索引
非叢集資料行存放區索引和叢集資料行存放區索引的功能相同。 差別在於非叢集索引是在資料列存放區資料表上建立的次要索引,但是叢集資料行存放區索引則是整個資料表的主要儲存體。
非叢集索引包含基礎資料表中部分或所有資料列和資料行的複本。 此索引會定義為資料表的一個或多個資料行,並具有篩選資料列的選用條件。
非叢集資料行存放區索引可使用即時作業分析,其中 OLTP 工作負載會使用基礎叢集索引,並同時對資料行存放區索引執行分析。 如需詳細資訊,請參閱開始使用資料行存放區進行即時作業分析。
批次模式執行
批次模式執行是用來同時處理多個資料列的查詢處理方法。 批次模式執行與資料行存放區儲存格式緊密整合,並以其為中心進行最佳化。 批次模式執行有時又稱為向量式或向量化執行。 資料行存放區索引的查詢使用批次模式執行,通常可改善查詢效能 2 至 4 倍。 如需詳細資訊,請參閱查詢處理架構指南。
為什麼應該使用資料行存放區索引?
資料行存放區索引可提供非常高度的資料壓縮,通常是 10 倍,因此可大幅降低資料倉儲儲存體成本。 資料行存放區索引在分析時所提供的效能遠比 B 型樹狀結構索引還高。 資料行存放區索引是資料倉儲和分析工作負載的慣用資料儲存格式。 從 SQL Server 2016 (13.x) 開始,您可以使用資料行存放區索引,對您的作業工作負載進行即時分析。
資料行存放區索引之所以很快的原因︰
資料行會儲存來自相同網域的值,而且通常會有類似的值,因此壓縮率會很高。 您系統中的 I/O 瓶頸會減至最少或消失,而且會大幅減少記憶體耗用量。
高壓縮率會透過使用較小的記憶體中耗用量改善查詢效能。 而查詢效能可獲得改善是因為 SQL Server 能夠執行更多記憶體中查詢及資料作業。
批次執行藉由同時處理多個資料列來改善查詢效能,通常是 2 至 4 倍。
查詢通常只會選取資料表中的少數資料行,如此可降低讀取實體媒體的總 I/O 量。
何時應該使用資料行存放區索引?
建議使用案例:
使用叢集資料行存放區索引,儲存資料倉儲工作負載的事實資料表和大型維度資料表。 此方法可以提升查詢效能和資料壓縮最多 10 倍。 如需詳細資訊,請參閱資料倉儲的資料行存放區索引。
使用非叢集資料行存放區索引,對 OLTP 工作負載執行即時分析。 如需詳細資訊,請參閱開始使用資料行存放區進行即時作業分析。
如需資料行存放區索引的更多使用案例,請參閱視需要選擇最適合的資料行存放區索引。
如何在資料列存放區索引與資料行存放區索引之間進行選擇?
資料列存放區索引在搜尋資料的查詢、搜尋特定值,或搜尋一小段值範圍查詢的效果最佳。 請搭配交易式工作負載使用資料列存放區索引,因為它們通常需要大量資料表搜尋,而不是資料表掃描。
資料行存放區索引可提升分析查詢的效能,現在可掃描大量資料,特別是大型資料表上的資料。 請在資料倉儲和分析工作負載上 (尤其是在事實資料表上) 使用資料行存放區索引,因為它們通常需要完整資料表掃描,而不是資料表搜尋。
已排序的叢集資料行存放區索引會根據已排序的資料行述詞改善查詢的效能。 已排序的資料行存放區索引可以改善資料列群組消除,藉由完全略過資料列群組提升效能。 如需詳細資訊,請參閱 使用已排序的叢集數據行存放區索引進行效能微調。 如需已排序的數據行存放區索引可用性,請參閱 已排序的數據行索引可用性。
我可以將資料列存放區和資料行存放區合併到同一個資料表嗎?
是。 從 SQL Server 2016 (13.x) 開始,您可以在資料列存放區資料表上建立可更新的非叢集資料行存放區索引。 資料行存放區索引會儲存所選資料行的複本,因此您需要額外的空間來存放此資料,但所選資料平均會壓縮 10 倍。 您就可以同時在資料行存放區索引上執行分析,並在資料列存放區索引上執行交易。 當資料列存放區資料表中的資料變更時,會更新資料行存放區,讓兩個索引針對相同的資料執行。
從 SQL Server 2016 (13.x) 開始,您在資料行存放區索引上可以有一個或多個非叢集資料列存放區索引,而且可以針對基礎資料行存放區執行有效率的資料表搜尋。 其他選項現在也可以使用。 例如,您可以在資料列存放區資料表上使用 UNIQUE 條件約束,強制執行主索引鍵條件約束。 由於非唯一值將無法插入至資料列存放區資料表,因此 SQL Server 無法將值插入至資料行存放區。
已排序的數據行存放區索引
藉由啟用有效率的區段消除,已排序的叢集數據行存放區索引 (CCI) 藉由略過大量不符合查詢述詞的已排序數據來提供更快的效能。 由於資料排序作業,將資料載入已排序 CCI 資料表可能會較載入非排序 CCI 資料表花費更長的時間,但之後查詢可利用已排序 CCI 使執行速度更快。
- 如需使用已排序叢集數據行存放區索引之 SQL 資料庫 引擎中效能微調數據倉儲工作負載的詳細資訊,請參閱使用已排序的叢集數據行存放區索引進行效能微調。
- 如需何時使用哪一種數據行存放區索引的詳細資訊,請參閱 為您的需求選擇最佳的數據行存放區索引。
已排序的數據行存放區索引可用性
SQL Server 2022 (16.x),已排序的數據行存放區索引會先在 ![]() 下列平臺上推出。
下列平臺上推出。
| 平台 | 已排序 的叢集數據 行存放區索引 | 已排序 的非叢集數據 行存放區索引 |
|---|---|---|
| Azure SQL Database | 是 | Yes |
| Microsoft Fabric SQL 資料庫 | 是* | Yes |
| SQL Server 2022 (16.x) | 是 | No |
| Azure SQL 受控執行個體 | 是 | Yes |
| Azure Synapse Analytics 中的專用 SQL 集區 | 是 | No |
* 在 Fabric SQL 資料庫中,具有叢集數據行存放區索引的數據表不會 鏡像到 Fabric OneLake。
中繼資料
資料行存放區索引中的所有資料行都將儲存於中繼資料內成為內含資料行。 資料行存放區索引沒有索引鍵資料行。
相關工作
所有關聯式資料表都會使用資料列存放區作為基礎資料格式,除非您將其指定為叢集資料行存放區索引。 除非您指定 WITH CLUSTERED COLUMNSTORE INDEX 選項,否則 CREATE TABLE 會建立資料列存放區資料表。
當您使用 CREATE TABLE 陳述式建立資料表時,可以指定 WITH CLUSTERED COLUMNSTORE INDEX 選項,將資料表建立為資料行存放區。 如果您已經有一個資料列存放區資料表,並想要將它轉換成資料行存放區,則可以使用 CREATE COLUMNSTORE INDEX 陳述式。
| Task | 參考文章 | 注意 |
|---|---|---|
| 建立資料表作為資料行存放區。 | CREATE TABLE (Transact-SQL) | 從 SQL Server 2016 (13.x) 開始,您可以建立資料表作為叢集資料行存放區索引。 您不需要先建立資料列存放區資料表,再將它轉換成資料行存放區。 |
| 建立具有資料行存放區索引的經記憶體最佳化的資料表。 | CREATE TABLE (Transact-SQL) | 從 SQL Server 2016 (13.x) 開始,您可以建立具有資料行存放區索引的記憶體最佳化資料表。 建立資料表之後,也可以使用 ALTER TABLE ADD INDEX 語法來加入資料行存放區索引。 |
| 將資料列存放區資料表轉換成資料行存放區。 | CREATE COLUMNSTORE INDEX (Transact-SQL) | 將現有的堆積或 B 型樹狀結構轉換成資料行存放區。 範例示範如何在執行這項轉換時處理現有的索引及索引名稱。 |
| 將資料行存放區資料表轉換成資料列存放區。 | 建立叢集索引X (Transact-SQL) 或將資料行存放區資料表轉換回資料列存放區堆積 | 此轉換通常並非必要,但有時您仍舊需要轉換。 範例示範如何將資料行存放區轉換成堆積或叢集索引。 |
| 在資料列存放區資料表上建立資料行存放區索引。 | CREATE COLUMNSTORE INDEX (Transact-SQL) | 資料列存放區資料表可以有一個資料行存放區索引。 從 SQL Server 2016 (13.x) 開始,資料行存放區索引可以有一個篩選條件。 範例示範基本語法。 |
| 為作業分析建立高效能的索引。 | 開始使用資料行存放區進行即時作業分析 | 描述如何建立互補資料行存放區和 B 型樹狀結構索引,讓 OLTP 查詢使用 B 型樹狀結構索引,而分析查詢使用資料行存放區索引。 |
| 為資料倉儲建立高效能的資料行存放區索引。 | 資料倉儲的資料行存放區索引 | 描述如何在資料行存放區資料表上使用 B 型樹狀結構索引,建立高效能的資料倉儲查詢。 |
| 使用 B 型樹狀結構索引,在資料行存放區索引上強制執行主索引鍵條件約束。 | 資料倉儲的資料行存放區索引 | 示範如何合併 B 型樹狀結構和資料行存放區索引,在資料行存放區索引上強制執行主索引鍵條件約束。 |
| 卸除資料行存放區索引。 | DROP INDEX (Transact-SQL) | 卸除資料行存放區索引使用 B 型樹狀結構索引所使用的標準 DROP INDEX 語法。 若卸除叢集資料行存放區索引,會將資料行存放區資料表轉換成堆積。 |
| 從資料行存放區索引刪除資料列。 | DELETE (Transact-SQL) | 使用 DELETE (Transact-SQL) 刪除資料列。 資料行存放區資料列:SQL Server 會將該資料列標示為邏輯刪除,但在重建索引之前,不會回收該資料列的實體儲存體。 差異存放區資料列:SQL Server 會以邏輯方式和實際方式刪除該資料列。 |
| 更新資料行存放區索引中的資料列。 | UPDATE (Transact-SQL) | 使用 UPDATE (Transact-SQL) 更新資料列。 資料行存放區資料列:SQL Server 會將該資料列標示為邏輯刪除,然後將更新的資料列插入差異存放區中。 差異存放區資料列:SQL Server 會更新差異存放區中的該資料列。 |
| 將資料載入資料行存放區索引。 | 資料行存放區索引資料載入 | |
| 強制將差異存放區中的所有資料列移入資料行存放區。 | ALTER INDEX (Transact-SQL) ... REBUILD 將索引維護最佳化以改善查詢效能並降低資源耗用量 |
ALTER INDEX 搭配 REBUILD 選項會強制將所有資料列移入資料行存放區。 |
| 重組資料行存放區索引。 | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE 會線上重組資料行存放區索引。 |
| 合併具有資料行存放區索引的資料表。 | MERGE (Transact-SQL) |