Python 教學課程:使用 SQL 機器學習來建置模型以分類客戶
適用於:![]() SQL Server 2017 (14.x) 和更新版本
SQL Server 2017 (14.x) 和更新版本 ![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體
在這個教學課程系列的第三部分 (總共四個部分) 中,您將在 Python 中建立一個 K-Means 模型以執行叢集。 在本系列的下一部分中,您將使用 SQL Server 機器學習服務在資料庫中部署此模型,或在巨量資料叢集上進行此部署。
在這個教學課程系列的第三部分 (總共四個部分) 中,您將在 Python 中建立一個 K-Means 模型以執行叢集。 在本系列的下一部分中,您將使用 SQL Server 機器學習服務在資料庫中部署此模型。
在這個教學課程系列的第三部分 (總共四個部分) 中,您將在 Python 中建立一個 K-Means 模型以執行叢集。 在本系列的下一部分中,您將使用 Azure SQL 受控執行個體機器學習服務在資料庫中部署此模型。
在本文中,您將學會如何:
- 為 K-Means 演算法定義叢集數目
- 執行叢集
- 分析結果
在第一部分中,您已安裝必要條件並還原範例資料庫。
在第二部分,您已了解如何準備資料庫中的資料,以執行叢集。
在第四部分,您將了解如何在資料庫中建立預存程序,以根據新的資料在 Python 中執行叢集。
Prerequisites
定義叢集數目
若要為您的客戶資料進行叢集化,您將使用 K-Means 叢集演算法,這是對資料進行分組的最簡單、最廣為人知的方法之一。 您可以在 K-means 叢集演算法的完整指南中深入了解 K-Means。
此演算法接受兩個輸入:資料本身,以及預先定義的數字「k」代表要產生的叢集數目。 輸出為 k 個叢集,包含在叢集之間分割的輸入資料。
K-means 的目標是將項目分組為 k 個叢集,讓相同叢集中的所有項目彼此相似,並盡可能與其他叢集中的項目不同。
若要對要使用的演算法判斷其叢集數目,請使用「群組平方和」內的繪圖,並以擷取的叢集數目為依據。 要使用的適當叢集數目是在繪圖的折彎處或「肘線」處。
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
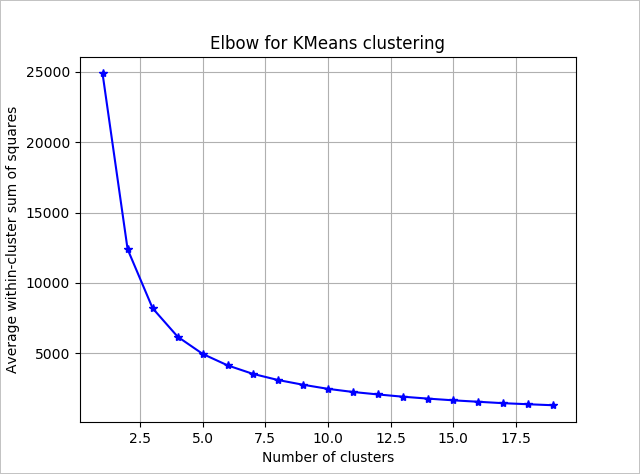
根據圖表,k = 4 看起來是理想的嘗試值。 k 值會將客戶分組成四個叢集。
執行叢集
在以下 Python 指令碼中,您將使用 sklearn 套件中的 KMeans 函數。
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
分析結果
現在,您已經使用 K-Means 執行叢集,下一步是分析結果,看看是否可以找到任何可行的資訊。
查看從上一個指令碼列印的叢集平均值和叢集大小。
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
使用第一部分中定義的變數以提供四種叢集平均值:
- orderRatio = 退貨訂單率 (部分退貨或全部退貨的訂單總數與訂單總數比較)
- itemsRatio = 退貨率 (退貨總數與購買項目數目比較)
- monetaryRatio = 退貨金額率 (退貨的貨幣金額總計與購買金額比較)
- frequency = 退貨頻率
使用 K-Means 的資料採礦經常需要進一步分析結果,並採取更多步驟,以深入了解每個叢集,但可以提供一些良好的潛在客戶。 您可以透過以下幾種方式來解譯這些結果:
- 叢集 0 似乎是不太活躍的客戶群組 (所有值皆為零)。
- 叢集 3 似乎是在退貨行為方面比較明顯的群組。
叢集 0 是顯然不活躍的客戶群組。 也許您可以針對該群組進行行銷活動,以觸發購買興趣。 在下一步驟中,您將為叢集 0 的客戶電子郵件地址查詢資料庫,以便向他們傳送行銷電子郵件。
清除資源
如果您不打算繼續進行本教學課程,請刪除 tpcxbb_1gb 資料庫。
後續步驟
在本教學課程系列的第三部分中,您已完成下列步驟:
- 為 K-Means 演算法定義叢集數目
- 執行叢集
- 分析結果
若要部署您已建立的機器學習模型,請遵循本教學課程系列的第四部分: