瞭解並建立數據質量規則
數據品質是組織中數據完整性的度量,並使用數據品質分數進行評估。 根據針對 Microsoft Purview 整合式目錄 中定義之規則的數據評估所產生的分數。
數據品質規則是組織為了確保其數據正確性、一致性和完整性所建立的基本指導方針。 這些規則有助於維護數據完整性和可靠性。
以下是資料質量規則的一些重要層面:
精確度 - 資料應該正確代表真實世界的實體。 內容很重要! 例如,如果您要儲存客戶位址,請確定其符合實際位置。
完整性 - 此規則的目標是要識別空白、Null 或遺失的數據。 此規則會驗證所有值都存在 (但不一定正確) 。
一致性 - 此規則可確保數據遵循數據格式化標準,例如日期、地址和允許值的表示法。
一致性 - 此規則會檢查相同記錄的不同值是否與指定的規則一致,而且沒有任何附加性。 數據一致性可確保相同的資訊會在不同的記錄之間以一致的方式表示。 例如,如果您有產品目錄,一致的產品名稱和描述就很重要。
Time accessible - 此規則旨在確保數據能在最短的時間記憶體取。 它可確保數據是最新的。
唯一性 - 此規則會檢查值不會重複,例如,如果每個客戶只能有一筆記錄,則同一個客戶沒有多個記錄。 每個客戶、產品或交易都應該有唯一標識碼。
數據品質生命週期
建立數據品質規則是數據品質生命週期中 的第六 個步驟。 先前的步驟如下:
- 指派使用者 () 整合式目錄 中的數據品質管理人許可權,以使用所有數據品質功能。
- 在您的 Microsoft Purview 資料對應 中註冊和掃描數據源。
- 將您的數據資產新增至數據產品
- 設定數據源連線,以準備您的來源以進行數據質量評估。
- 設定及執行數據源中資產的數據分析。
所需角色
檢視現有的數據質量規則
從 [Microsoft Purview 整合式目錄],選取 [健全狀況管理] 功能表和 [數據品質] 子功能表。
在數據質量子功能表中,選取 治理網域。
選取數據產品。
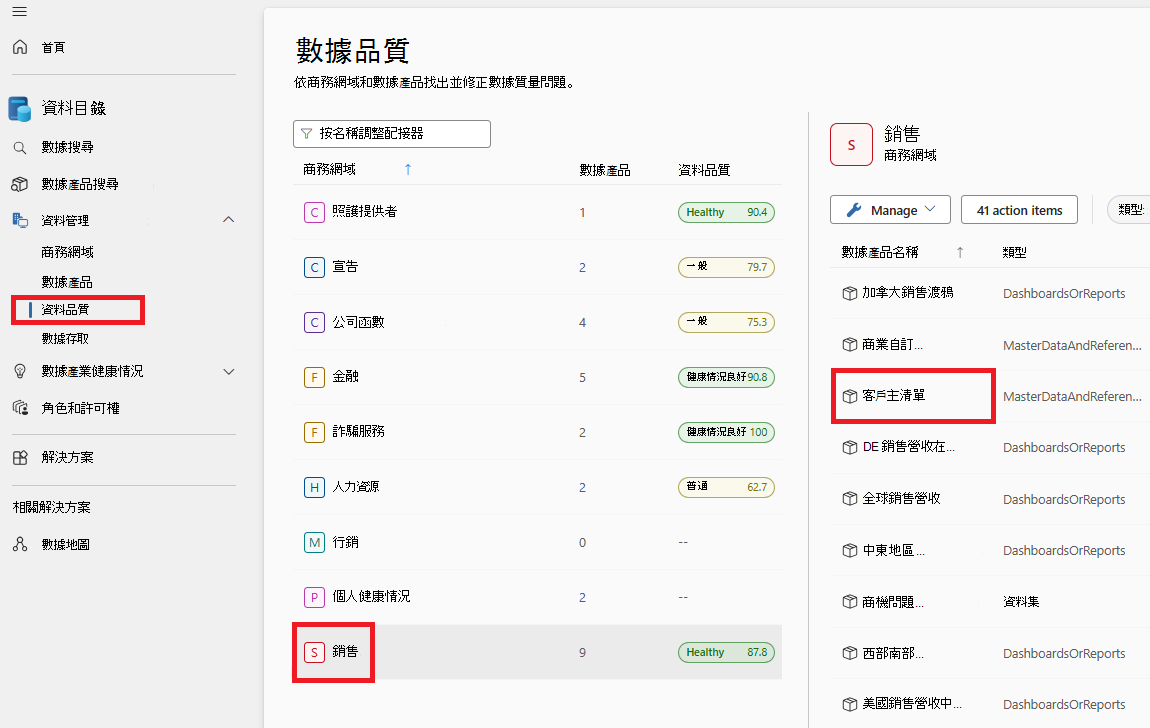
從所選 取資料 產品的資產清單中選取數據資產。
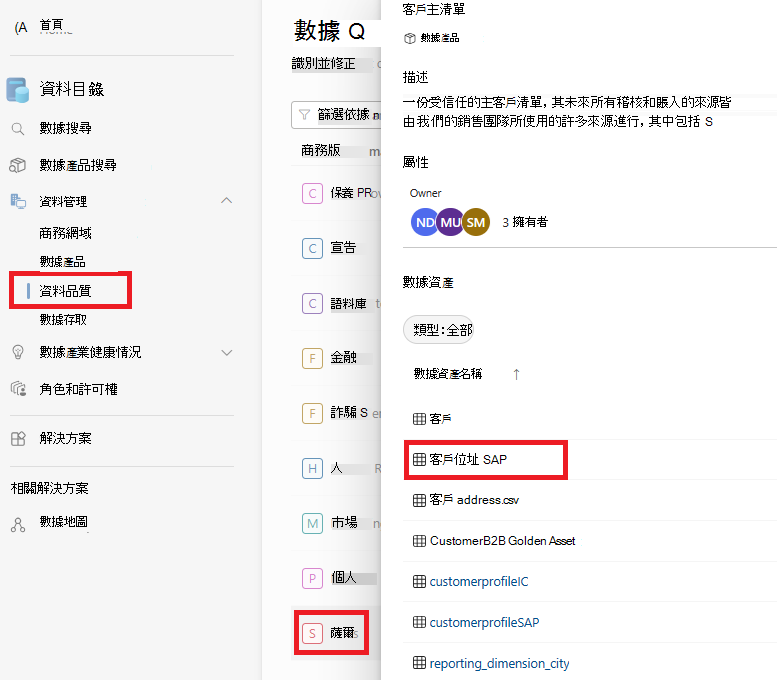
選取 [ 規則] 功能表索引標籤,以查看套用至資產的現有規則。
![數據資產的螢幕快照,其中已選取 [規則] 索引標籤。](media/concept-data-quality-rules/rule-page-inline.png)
選取規則,以瀏覽所選取數據資產所套用規則的效能歷程記錄。
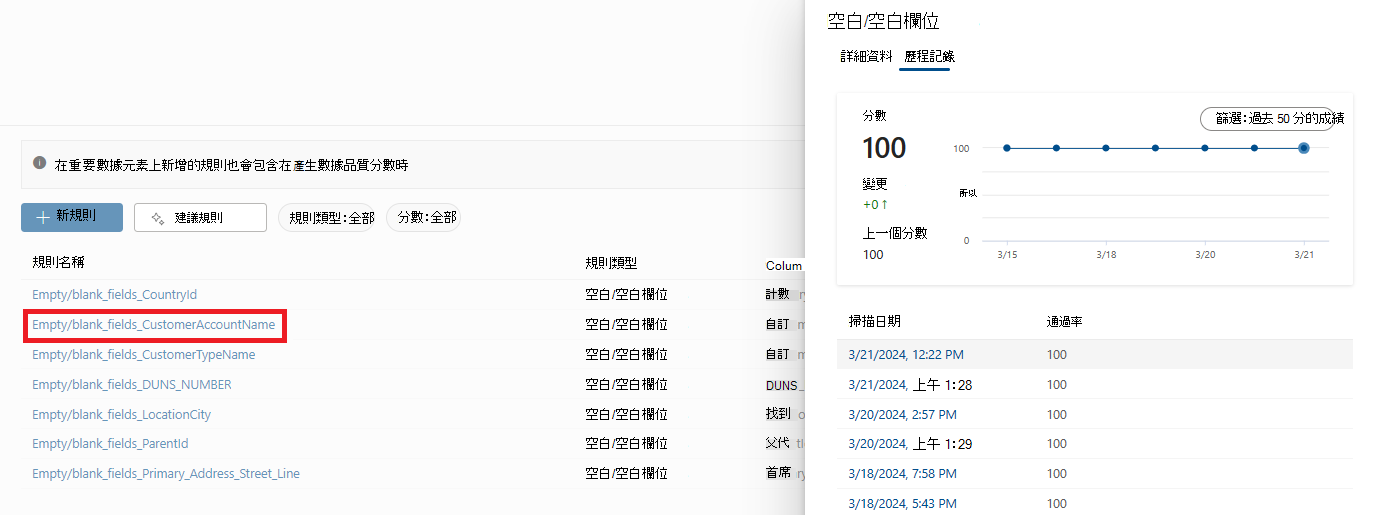


![數據資產的螢幕快照,其中已選取 [規則] 索引標籤。](media/concept-data-quality-rules/rule-page.png#lightbox)

可用的數據質量規則
Microsoft Purview 資料品質 啟用下列規則的設定,這些是現成可用的規則,可提供低程式代碼到無程式代碼的方式來測量數據的品質。
| 規則 | 定義 |
|---|---|
| 新鮮 | 確認所有值都是最新狀態。 |
| 唯一的值 | 確認數據行中的值是唯一的。 |
| 字串格式比對 | 確認數據行中的值符合特定格式或其他準則。 |
| 數據類型相符 | 確認數據列中的值符合其數據類型需求。 |
| 重複的數據列 | 檢查兩個以上數據行中是否有具有相同值的重複數據列。 |
| 空白/空白欄位 | 在應該有值的數據行中尋找空白和空白欄位。 |
| 表格查閱 | 確認某個數據表中的值可以在另一個數據表的特定數據行中找到。 |
| 自訂 | 使用可視化表達式產生器建立自定義規則。 |
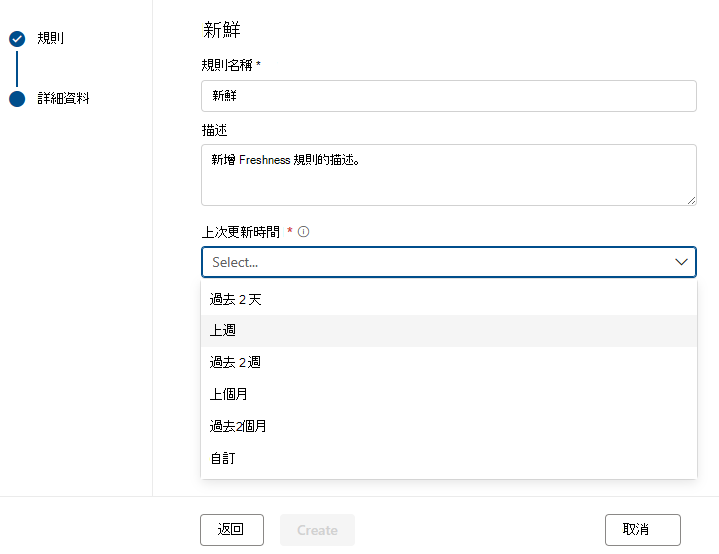
新鮮
有效 性規則 的目的是要判斷資產是否已在預期的時間內更新。 Microsoft Purview 目前透過查看 上次修改的日期來支持檢查有效性。
注意事項
有效性規則的分數為 100 (通過) ,或 (失敗) 為 0。 Snowflake、Azure Databricks UC、Google BigQuery、Synapes 和 Azure SQL 不支援有效期限規則。
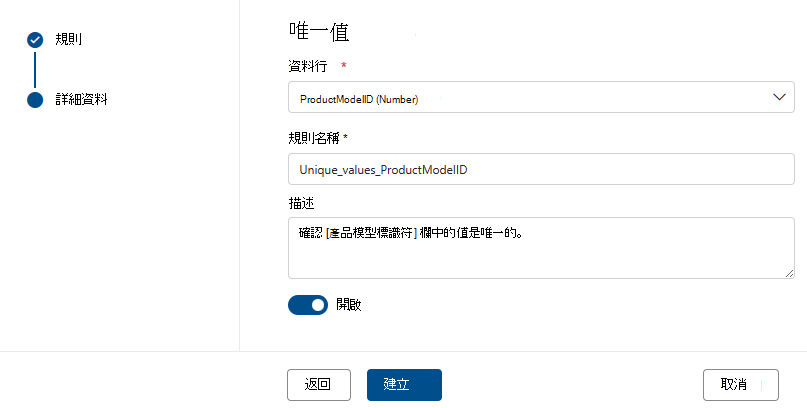
唯一的值
[ 唯一值] 規則 會指出指定數據行中的所有值都必須是唯一的。 所有唯一 『pass』 的值和未傳遞的值都會被視為失敗。 如果數據行上未定義空白/空白欄位規則,則基於此規則的目的,將會忽略 Null/空白值。
字串格式比對
[格式比對] 規則會檢查資料行中的所有值是否有效。 如果未在數據行上定義空白/空白欄位規則,則基於此規則的目的,將會忽略 Null/空白值。
此規則可以使用三種不同的方法來驗證資料列中的每個值:
列舉 – 這是以逗號分隔的值清單。 如果要評估的值無法與其中一個列出的值進行比較,則檢查會失敗。 您可以使用反斜杠來逸出逗號和反斜杠:
\。 因此a \, b, c,包含兩個值,第一個 值為a , b,而第二個值為c。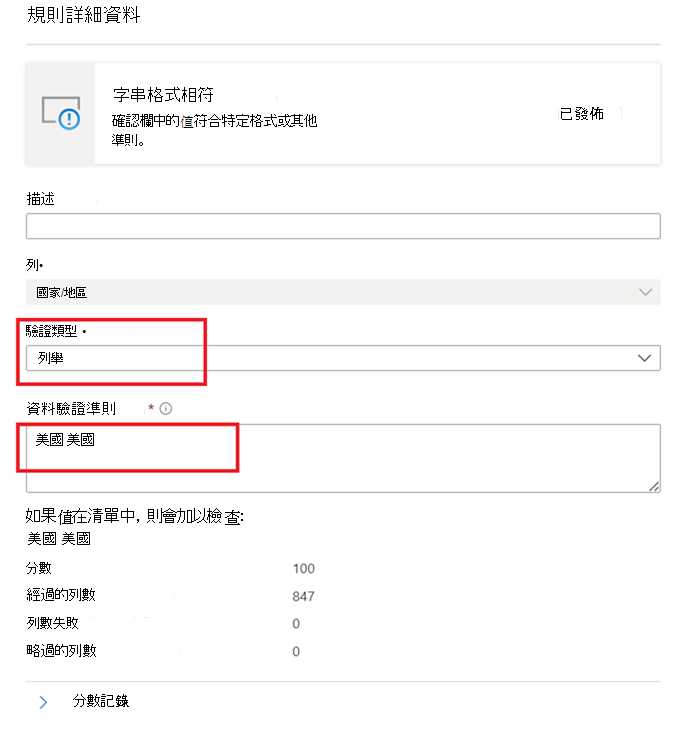
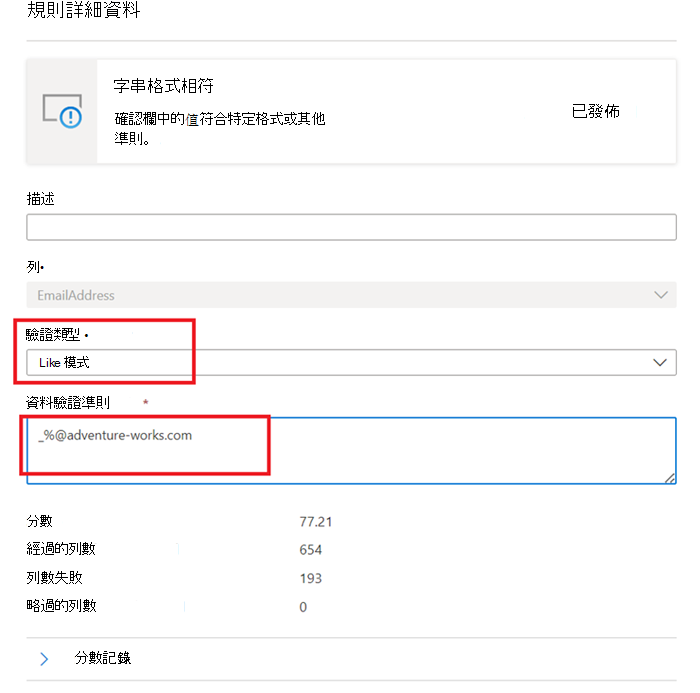
Like Pattern -
like(<string> : string, <pattern match> : string) => boolean
模式是字面上相符的字串。 例外狀況是下列特殊符號: _ 會比對輸入 (中的任何一個字元,類似於 。在posix正則表達式中,) % 會比對輸入 (中與正則表示式) 中的posix.* 類似的零個或多個字元。 逸出字元為 ''。 如果逸出字元在特殊符號或另一個逸出字元之前,則會以字面方式比對下列字元。 逸出任何其他字元是無效的。like('icecream', 'ice%') -> true
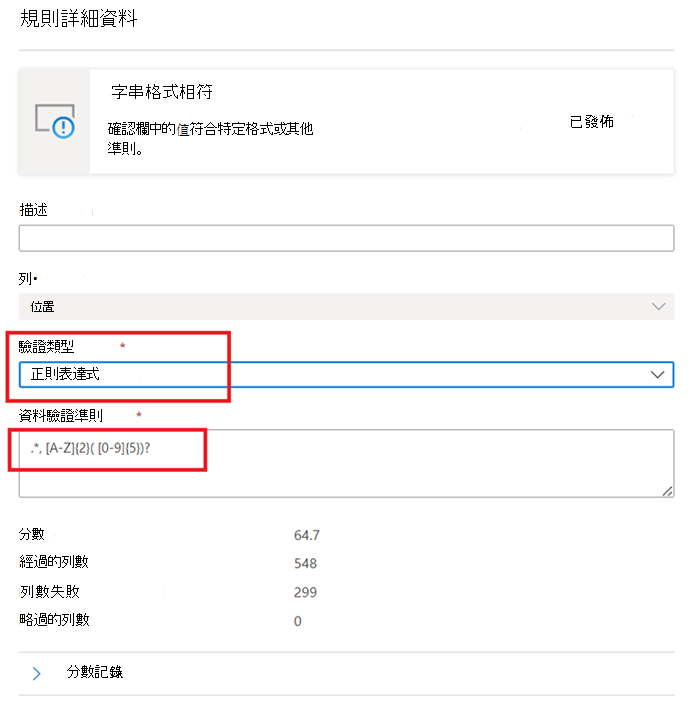
正規表示式 –
regexMatch(<string> : string, <regex to match> : string) => boolean
檢查字串是否符合指定的 regex 模式。 使用<regex>(反引號) 比對字串而不逸出。regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
數據類型相符
數據類型比對規則會指定關聯數據行預期要包含的數據類型。 因為規則引擎必須跨許多不同的數據源執行,所以無法使用 BIGINT 或 VARCHAR 等原生類型。 相反地,它有自己的類型系統,它會將原生類型轉譯成。 此規則會告訴質量掃描引擎應該轉譯原生類型的內建類型。 數據類型系統取自 Azure Data Factory 中使用的 Azure 資料流類型系統。
在質量掃描期間,系統會針對數據類型比對類型測試原生類型,如果無法將原生類型轉譯成數據類型比對類型,數據列就會被視為發生錯誤。
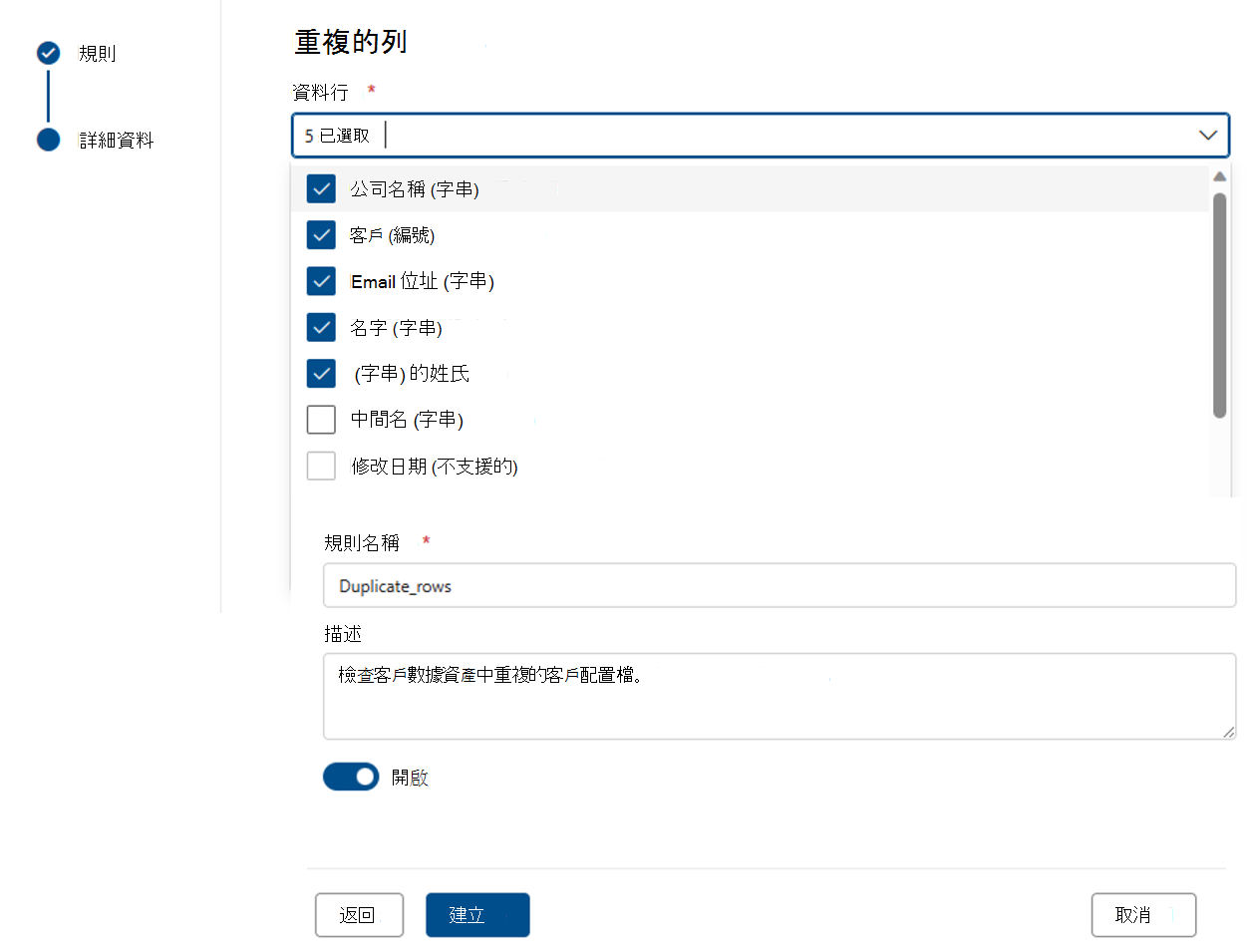
重複的數據列
重複的數據列規則會檢查數據列中值的組合是否對數據表中的每個數據列都是唯一的。
在下列範例中,預期_CompanyName、CustomerID、EmailAddress、 FirstName 和 LastName 的串連會產生數據表中所有數據列唯一的值。
每個資產都可以有此規則的零個或一個實例。
空白/空白欄位
空白/空白欄位規則會判斷提示識別的數據行不應包含任何 Null 值,而在字串的特定案例中,也不可包含空值或空格符值。 在質量掃描期間,此數據行中任何非 Null 的值都會視為正確。 此規則會影響其他規則,例如 Unique 值 或 Format 比對 規則。 如果未在數據行上定義此規則,則在該數據行上執行時,這些規則會自動忽略任何 Null 值。 如果在數據行上定義此規則,則這些規則會檢查該數據行上的Null/空白值,並基於分數目的考慮這些值。
表格查閱
[ 資料表查閱] 規則 會檢查定義規則之數據行中的每個值,並將其與參考數據表進行比較。 例如,主要數據表有一個名為 「location」 的數據行,其中包含 「city, state zip」 形式的城市、州和郵遞區號。 有一個名為 citystate 的參考數據表,其中包含 美國 中支援的所有城市、州和郵遞區區編碼法律組合。 目標是要比較目前數據行中的所有位置與該參考清單,以確保只使用合法的組合。
若要這樣做,我們會先在 [搜尋資產] 對話框中輸入 “citystatezip 的名稱。 然後選取所需的資產,然後選取要比較的數據行。
注意事項
參考數據表或數據資產必須屬於相同的治理網域。 不允許跨不同的治理網域比較數據資產。
自訂規則
自 定義規則 可讓您指定規則,嘗試根據該數據列中的一或多個值來驗證數據列。 自訂規則有兩個部分:
- 第一個部分是選用的篩選表達式,並透過選取 [使用篩選表達式] 的複選框來啟動。 這是傳回布爾值的表達式。 篩選表達式會套用至數據列,如果傳回 true,則會將該數據列視為規則。 如果篩選表達式針對該數據列傳回 false,則表示基於此規則的目的,將會忽略該數據列。 篩選表達式的預設行為是傳遞所有數據列,因此如果未指定任何篩選表達式,而且不需要篩選表達式,則會考慮所有數據列。
- 第二個部分是數據 列表達式。 這是套用至篩選表達式核准之每個數據列的布爾表達式。 如果此表達式傳回 true,則數據列會通過,如果為 false,則會將其標示為失敗。
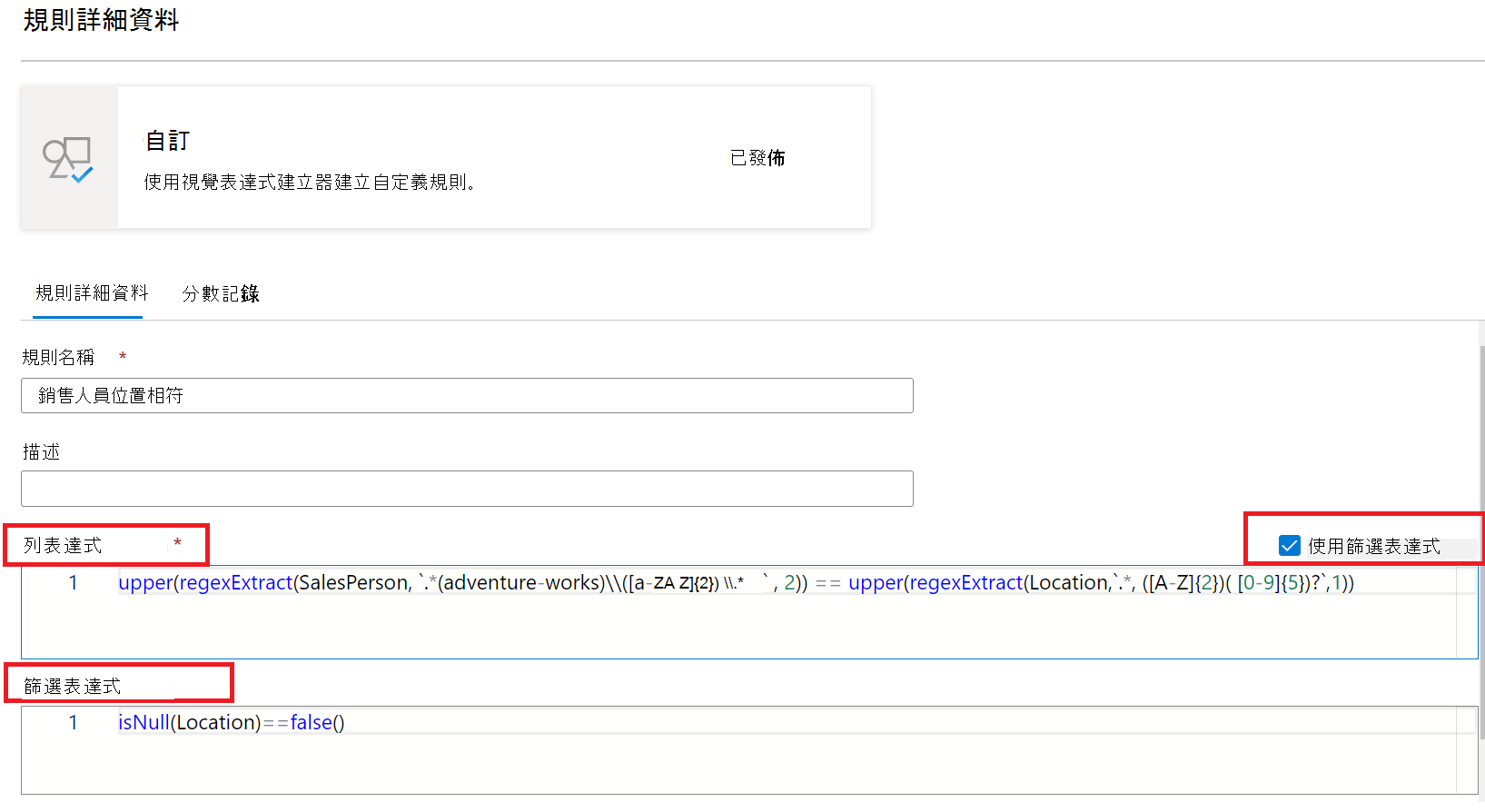
自訂規則的範例
| 案例 | 數據列表達式 |
|---|---|
| 驗證 state_id 是否等於加州, 且aba_Routing_Number 符合特定的 regex 模式,且出生日期落在特定範圍內 | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| 確認 VendorID 是否等於 124 | {VendorID}=='124' |
| 檢查 fare_amount 是否等於或大於 100 | {fare_amount} >= "100" |
| 驗證 fare_amount 是否大於100且 tolls_amount 不等於100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| 檢查 評等 是否小於 5 | Rating < 5 |
| 確認 年 份中的數字數目是否為 4 | length(toString(year)) == 4 |
| 比較兩 個數據行 bbToLoanRatio 和 bankBalance ,以檢查其值是否相等 | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| 檢查 firstName、 lastName、 LoanID、 uuid 中的修剪和串連字元數是否大於 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| 確認 aba_Routing_Number 是否符合特定的 regex 模式,且初始交易日期大於 2022-11-12, 而 Disallow-Listed 為 false,且平均 bankBalance 大於 50000, 且state_id 等於 'Massachuse'、'Marketplacee'、'North Registry' 或 'Americama' | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| 驗證 aba_Routing_Number 是否符合特定的 regex 模式,且 dateOfBirth 介於 1968-12-13 和 2020-12-13 之間 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| 檢查 aba_Routing_Number 中的唯一值數目是否等於 1,000,000,以及 EMAIL_ADDR 中的唯一值數目是否等於 1,000,000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
篩選表達式和數據列表示式都是使用 Azure Data Factory 表示式語言來定義,如這裡所導入的語言所定義。 不過請注意,並非所有針對泛型 ADF 運算式語言定義的函式都可以使用。 可用函式的完整清單位於表示式對話框中可用的 [函式] 清單中。 此處定義的下列函式不受支援:isDelete、isError、isIgnore、isInsert、isMatch、isUpdate、isUpsert、partitionId、快取查閱和 Window 函式。
注意事項
<regex> (回引號) 可用於自定義規則中包含的正則表示式,以比對字串,而不需要逸出特殊字元。 正則表達式語言是以 Java 為基礎,可如 這裡所示運作。
此頁面 會識別需要逸出的字元。
AI 輔助自動產生的規則
數據質量測量的 AI 輔助自動化規則產生牽涉到使用人工智慧 (AI) 技術,自動建立規則來評估和改善數據品質。 自動產生的規則是特定內容。 大部分的常見規則都會自動產生,讓使用者不需要投入太多心力來建立自定義規則。
若要瀏覽並套用自動產生的規則:
- 在規則頁面上選取 [建議規則 ]。
- 瀏覽清單建議的規則。
![資產的 [規則] 索引標籤螢幕快照,其中已醒目提示 [建議規則] 按鈕。](media/concept-data-quality-rules/suggest-rule-main.png#lightbox)
- 從建議的規則清單中選取要套用至數據資產的規則。

後續步驟
- 在數據產品上設定並執行數據質量掃描 ,以評估數據產品中所有支援資產的品質。
- 檢閱掃描結果 ,以評估數據產品的目前數據品質。