微調 Azure Data Lake Storage Gen1 的效能
Data Lake Storage Gen1 支援 I/O 密集分析和資料移動的高輸送量。 在 Data Lake Storage Gen1 中,使用所有可用的輸送量 (每秒可以讀取或寫入的資料量) 是取得最佳效能的重要部分。 這可以藉由盡可能平行執行讀取和寫入來達成。
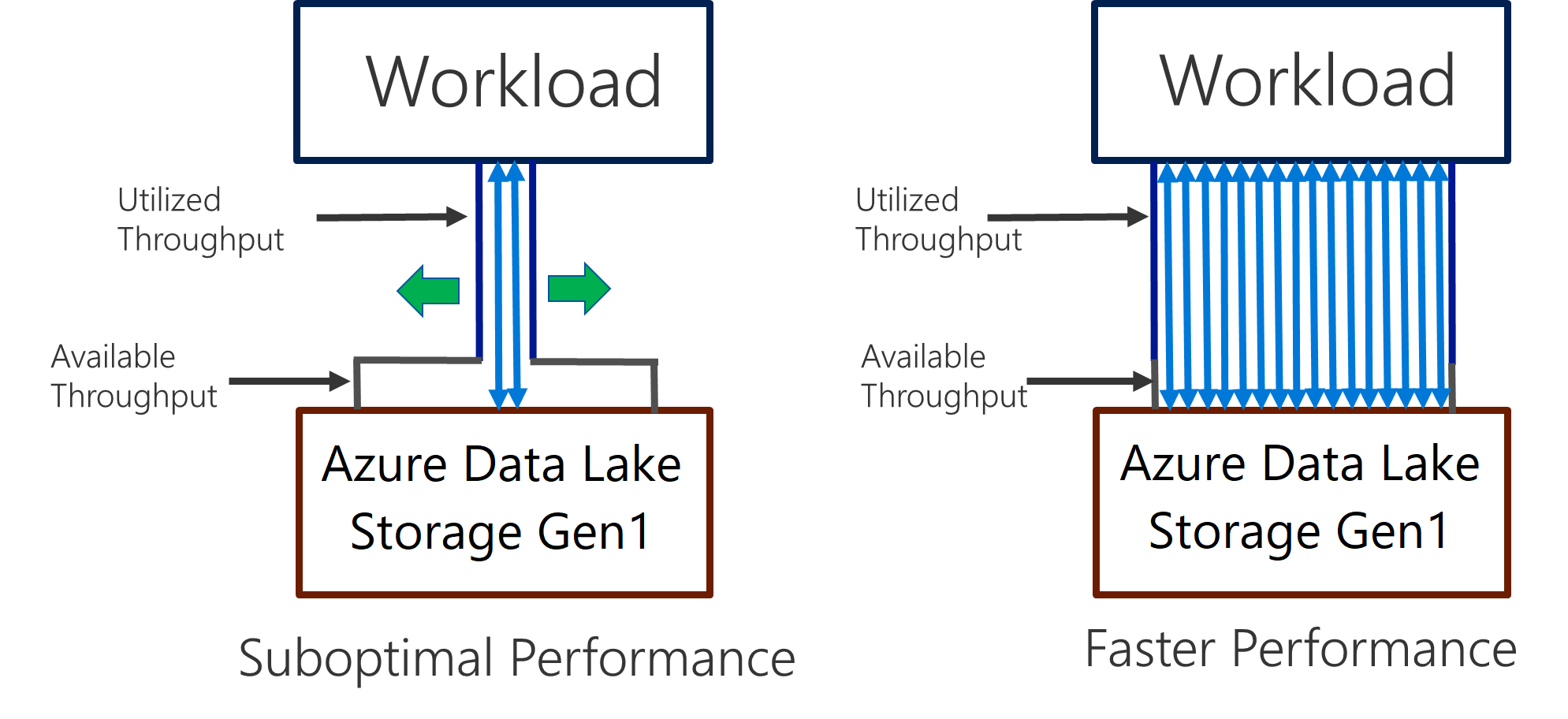
Data Lake Storage Gen1 可以調整以提供所有分析情節的必要輸送量。 根據預設,Data Lake Storage Gen1 帳戶會自動提供足夠產能,以符合廣泛類別使用案例的需求。 客戶遇到預設限制的情況下,可以將 Data Lake Storage Gen1 帳戶設定為連絡 Microsoft 支援服務來提供更多輸送量。
資料擷取
將資料從來源系統擷取至 Data Lake Storage Gen1 時,請務必考慮來源硬體、來源網路硬體和與 Data Lake Storage Gen1 的網路連線可能會是瓶頸。
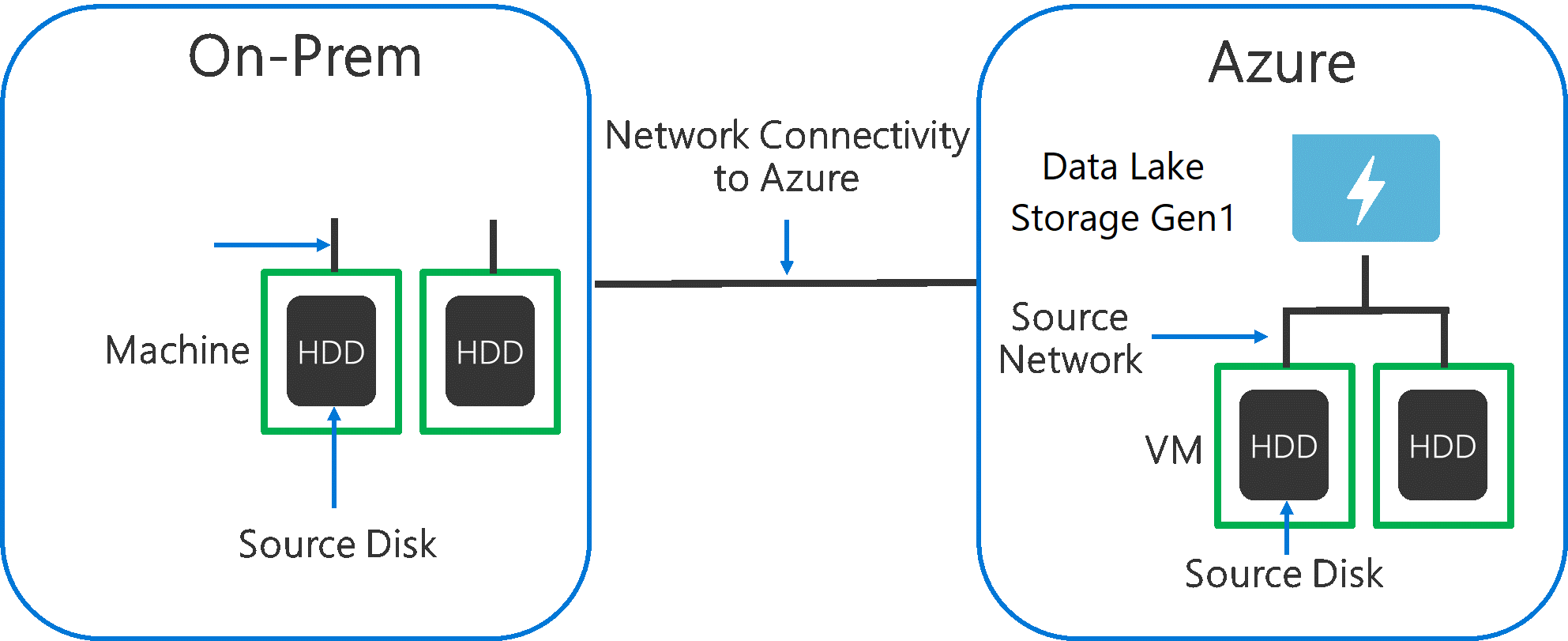
請務必確定資料移動不會受到這些因素影響。
來源硬體
不論您在 Azure 中使用內部部署機器或 VM,皆應仔細選取適當的硬體。 對於來源磁碟硬體,偏好使用 SSD 而非 HDD,並且挑選具有更快磁針的磁碟硬體。 對於來源網路硬體,盡可能使用最快的 NIC。 在 Azure 上,我們建議使用 Azure D14 VM,配備功能強大的適用磁碟和網路硬體。
與 Data Lake Storage Gen1 的網路連線
您的來源資料與 Data Lake Storage Gen1 之間的網路連線有時可能是瓶頸。 當您的來源資料是內部部署時,請考慮使用與 Azure ExpressRoute 的專用連結。 如果您的來源資料是在 Azure 中,當資料位於與 Data Lake Storage Gen1 相同的 Azure 區域時,效能最佳。
設定最大平行處理的資料擷取工具
解決來源硬體和網路連線瓶頸後,您就可以設定擷取工具了。 下表摘要說明數個熱門擷取工具的關鍵設定,並且提供它們的深入效能微調文章。 若要深入了解哪一個工具適用於您的案例,請參閱這篇文章。
| 工具 | 設定 | 其他詳細資訊 |
|---|---|---|
| PowerShell | PerFileThreadCount、ConcurrentFileCount | 連結 |
| AdlCopy | Azure Data Lake Analytics units | 連結 |
| DistCp | -m (mapper) | 連結 |
| Azure Data Factory | parallelCopies | 連結 |
| Sqoop | fs.azure.block.size、-m (mapper) | 連結 |
結構化您的資料集
資料儲存在 Data Lake Storage Gen1 時,檔案大小、檔案數目和資料夾結構都會影響效能。 下一節說明這些區域的最佳做法。
檔案大小
一般而言,例如 HDInsight 和 Azure Data Lake Analytics 的分析引擎都有每個檔案的額外負荷。 如果您將資料儲存為許多小型檔案,會造成效能的負面影響。
一般情況下,將您的資料組織成較大大小的檔案,以提升效能。 根據經驗法則,將檔案中的資料集組織為 256 MB 以上。 在例如映像和二進位資料的某些情況下,不能夠平行處理。 在這些情況下,建議將個別檔案保持在 2 GB 以下。
有時候,資料管線對於具有大量小型檔案的未經處理資料,具有受限制的控制權。 建議進行「cooking」程序,該程序會產生較大的檔案,以用於下游應用程式。
組織資料夾中的時間序列資料
對於 Hive 和 ADLA 工作負載,時間序列資料的磁碟分割剪除有助於某些查詢僅讀取資料的子集,進而改善效能。
擷取時間序列資料的這些管線,通常會以結構化的檔案和資料夾命名方式來處理檔案。 以下是常見的依日期結構化的資料範例:\DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv。
請注意,日期時間資訊會同時在資料夾和檔案名稱中顯示。
若是依日期和時間結構化的資料,常見模式如下:\DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv。
同樣地,您對於資料夾和檔案組織的選擇,應該針對較大的檔案大小以及每個資料夾中合理的檔案數目進行最佳化。
最佳化 HDInsight 上 Hadoop 和 Spark 工作負載的 I/O 密集作業
作業屬於下列三個類別之一:
- CPU 密集作業 這些作業有很長的計算時間和最短的 I/O 時間。 範例包括機器學習和自然語言處理作業。
- 記憶體密集。 這些作業會使用大量記憶體。 範例包括 PageRank 和即時分析作業。
- I/O 密集作業 這些作業花費大部分時間執行 I/O。 常見範例是僅執行讀取和寫入作業的複製作業。 其他範例包括讀取大量資料、執行某些資料轉換,然後將資料寫回存放區的資料準備作業。
下列指南僅適用於 I/O 密集作業。
HDInsight 叢集的一般考量
- HDInsight 版本。 為了達到最佳效能,請使用最新版本的 HDInsight。
- 區域。 將 Data Lake Storage Gen1 帳戶放置在與 HDInsight 叢集相同的區域中。
HDInsight 叢集是由兩個前端節點和一些背景工作角色節點所組成。 每個背景工作角色節點提供特定數目的核心和記憶體,由 VM 類型決定。 執行作業時,YARN 是資源交涉程式,它會配置可用記憶體和核心來建立容器。 每個容器會執行完成作業所需的工作。 平行執行容器以快速地處理工作。 因此,盡可能平行執行最多容器可提升效能。
HDInsight 叢集內有三個層級可以微調,以增加容器數目並且使用所有可用的輸送量。
- 實體層
- YARN 層
- 工作負載層
實體層
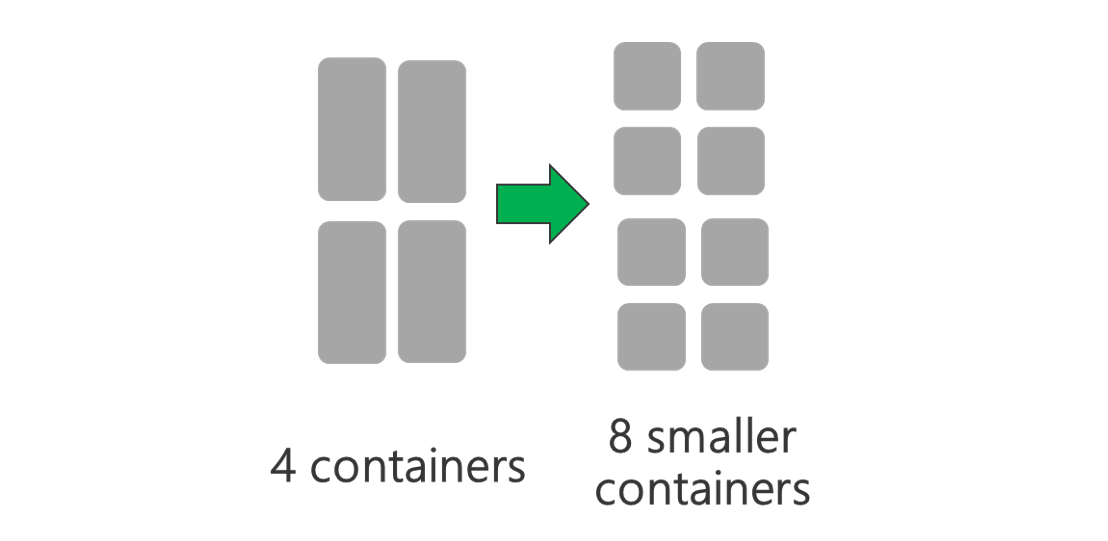
執行具有更多節點和/或較大大小 VM 的叢集。 較大的叢集可讓您執行更多 YARN 容器,如下圖所示。

使用具有較大網路頻寬的 VM。 如果網路頻寬比 Data Lake Storage Gen1 輸送量小,網路頻寬量可能會是瓶頸。 不同 VM 會有不同的網路頻寬大小。 選擇具有最大可能網路頻寬的 VM 類型。
YARN 層
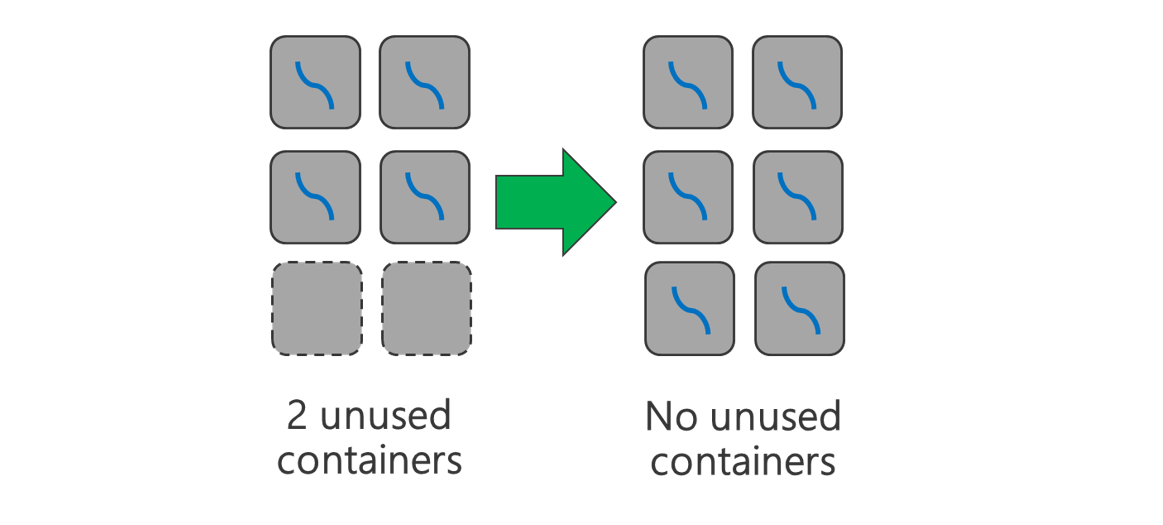
使用較小的 YARN 容器。 減少每個 YARN 容器的大小以使用相同的資源量來建立更多容器。
根據您的工作負載,一定有需要的最小 YARN 容器大小。 如果您挑選的容器太小,您的作業會遇到記憶體不足的問題。 通常 YARN 容器應該不小於 1 GB。 通常會看到 3 GB 的 YARN 容器。 針對某些工作負載,您可能需要較大的 YARN 容器。
增加每個 YARN 容器的核心。 增加配置給每個容器的核心數目,以增加在每個容器中執行的平行工作數目。 這適用於類似 Spark 的應用程式,它會在每個容器執行多項工作。 對於像是 Hive 的應用程式,它會在每個容器中執行單一執行緒,所以最好是有多個容器,而不是每個容器有多個核心。
工作負載層
使用所有可用的容器。 將工作數目設定為等於或大於可用容器的數目,以便用到所有資源。
失敗的工作成本很高。 如果每項工作都有大量資料要處理,則工作失敗會造成昂貴的重試成本。 因此,最好是建立更多工作,每個工作處理小量資料。
除了上述的一般方針,每個應用程式都有不同的參數可以針對該特定應用程式進行微調。 下表列出一些參數和連結,以開始進行每個應用程式的效能微調。
| 工作負載 | 設定工作的參數 |
|---|---|
| HDInsight 上的 Spark |
|
| HDInsight 上的 Hive |
|
| MapReduce on HDInsight |
|
| Storm on HDInsight |
|