多變量異常偵測
如需即時智慧中多重變數異常偵測的一般資訊,請參閱 Microsoft Fabric 中的多重變數異常偵測 - 概觀。 在本教學課程中,您會使用範例數據,在 Python 筆記本中使用 Spark 引擎來定型多變數異常偵測模型。 接著,您可以使用 Eventhouse 引擎,將定型的模型套用至新數據,以預測異常狀況。 前幾個步驟會設定您的環境,而下列步驟會定型模型並預測異常狀況。
必要條件
- 工作區,具有已啟用 Microsoft Fabric 的容量
- 工作區中的管理員、參與者,或成員角色。 需要此權限等級,才能建立環境等項目。
- 具有資料庫之工作區中的事件存放區。
- 從 GitHub 存放庫下載範例資料
- 從 GitHub 存放庫下載 notebook
第 1 部分- 啟用 OneLake 可用性
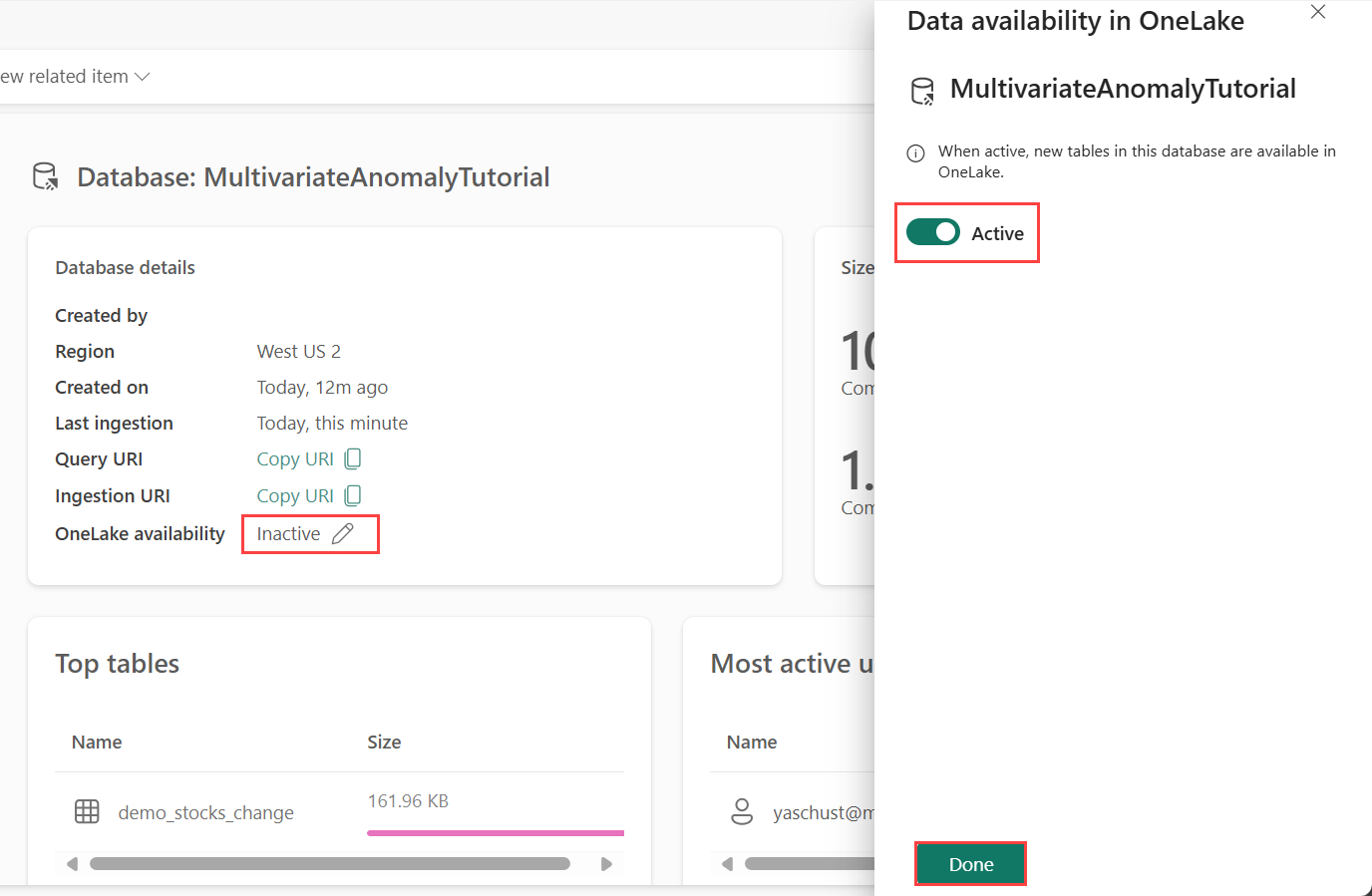
必須先 啟用 OneLake 可用性,才能在 Eventhouse 中取得資料。 此步驟很重要,因為它可讓您擷取的資料在 OneLake 中變成可用。 在稍後的步驟中,您會從Spark Notebook存取此相同的資料來定型模型。
從工作區中,選取您在前提條件中建立的 Eventhouse。 選擇您要儲存資料的資料庫。
在 [資料庫詳細數據] 窗格中,將 [OneLake 可用性] 按鈕切換為 [開啟]。
第 2 部分- 啟用 KQL Python 外掛程式
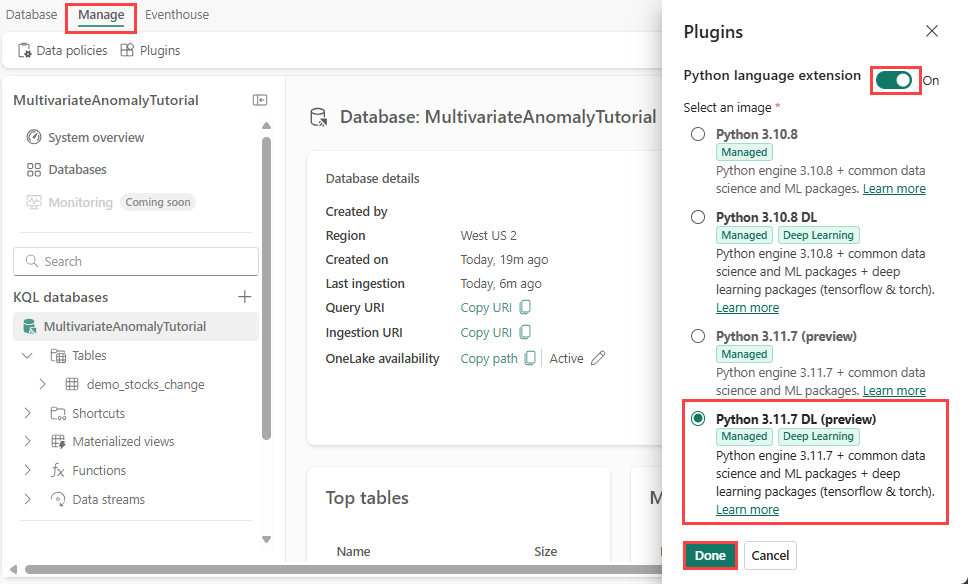
在此步驟中,您會在 Eventhouse 中啟用 Python 外掛程式。 需要此步驟,才能 在 KQL 查詢集中執行預測異常 Python 程式碼。 請務必選擇包含 時間序列異常偵測器 套件的正確映像。
在 [Eventhouse] 畫面中,從功能區選取 [Eventhouse> 外掛程式]。
在 [外掛程式] 窗格中,將 Python 語言延伸模組切換為 [ 開啟]。
選取 [Python 3.11.7 DL][預覽]。
選取完成。

第 3 部分- 建立 Spark 環境
在此步驟中,您會建立Spark環境來執行 Python 筆記本,以使用Spark引擎來定型多重異常偵測模型。 如需深入瞭建立環境的更多資訊,請參閱建立與管理環境。
在工作區中,選取 [+ 新增項目],然後 [環境]。
![[新增專案] 視窗中 [環境] 圖格的螢幕快照。](media/multivariate-anomaly-detection/create-environment.png)
輸入環境的名稱 MVAD_ENV,然後選取“建立”。
從環境的 [首頁] 索引標籤中,選取 [Runtime>1.2 (Spark 3.4,Delta 2.4)]。
在 [鏈接庫] 底下,選取 [公用連結庫]。
選取從 PyPI 新增。
在搜尋方塊中,輸入 時間序列異常偵測器。 版本會自動填入最新版本。 本教學課程是使用0.3.2版建立的。
選取儲存。

選取環境中的首頁索引標籤。
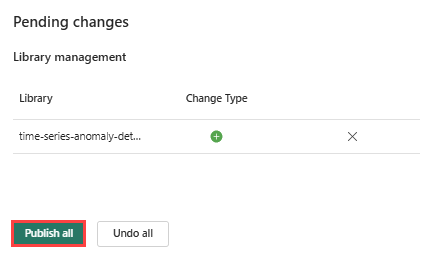
從功能區選取發佈圖示。

選取 [全部發佈]。 此步驟需要數分鐘的時間才能完成。
![[新增專案] 視窗中 [環境] 圖格的螢幕快照。](media/multivariate-anomaly-detection/create-environment.png#lightbox)

第 4 部分- 將資料放入 Eventhouse
將滑鼠停留在您想要儲存資料的 KQL 資料庫上。 選取 [ 更多] 功能表 [...]>取得資料>本機檔案。
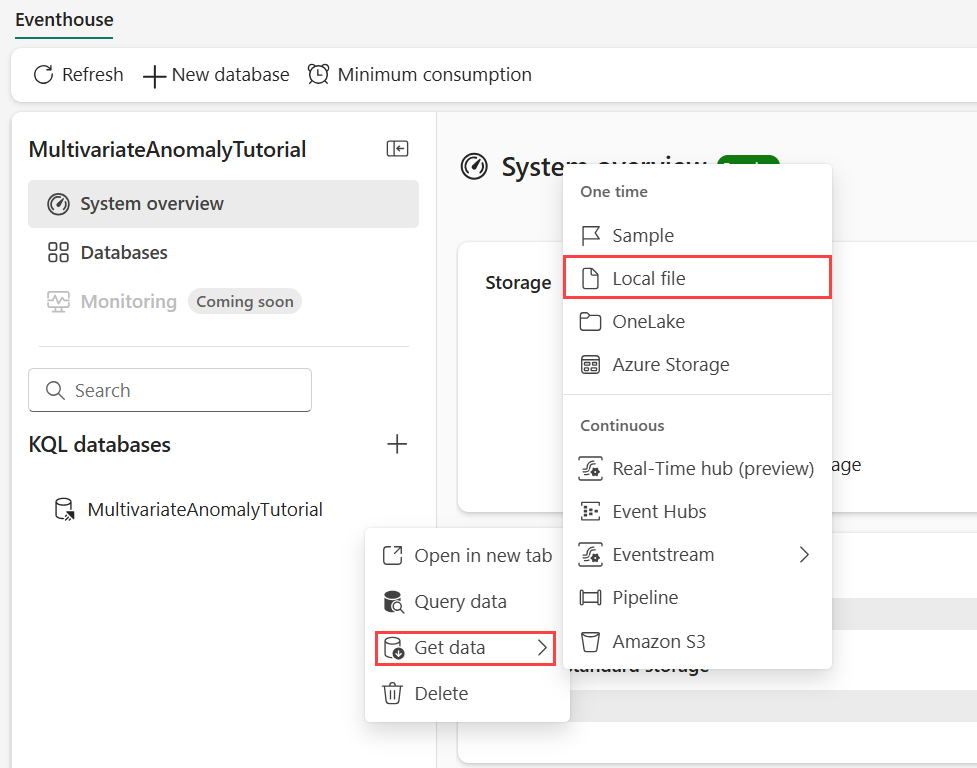
選取 [+ 新增資料表 ],然後輸入 demo_stocks_change 做為資料表名稱。
在上傳資料的對話方塊中,選取瀏覽檔案,然後上傳必要條件中下載的範例資料檔案
選取 [下一步]。
在 [檢查資料] 區段中,將 [第一列] 切換為 [開啟] 的資料行標頭。
選取 [完成]。
上傳資料時,請選取 [ 關閉]。
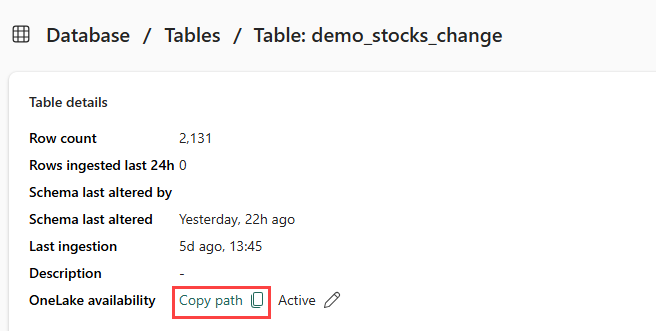
第 5 部分- 將 OneLake 路徑複製到資料表
請確定您選取 demo_stocks_change 資料表。 在 [數據表詳細數據] 窗格中,選取 [OneLake 資料夾],將 OneLake 路徑複製到剪貼簿。 將此複製的文字儲存在文本編輯器中,以供稍後步驟使用。
第 6 部分- 準備筆記本
選取您的工作區。
選取 [匯入]、[Notebook],然後選取 [從這部計算機]。
選取 [上傳],然後選擇您在必要條件中下載的筆記本。
上傳筆記本之後,您可以從工作區找到並開啟筆記本。
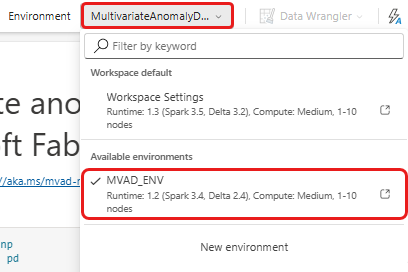
從頂端功能區中,選取 [ 工作區預設 ] 下拉式清單,然後選取您在上一個步驟中建立的環境。
第 7 部分- 執行筆記本
匯入標準套件。
import numpy as np import pandas as pdSpark 需要 ABFSS URI 才能安全地連線到 OneLake 儲存體,因此下一個步驟會定義此函式,將 OneLake URI 轉換為 ABFSS URI。
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uri將 OneLakeTableURI 占位元取代為從 第 5 部分複製到數據表 的 OneLake URI,以將 demo_stocks_change 數據表載入 pandas 數據框架。
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]執行下列資料格來準備定型和預測資料框架。
注意
實際預測將由 Eventhouse 在 9- Predict-anomalies-in-the-kql-queryset 中的資料上執行。 在生產案例中,如果您將資料串流至事件倉儲,則會針對新的串流資料進行預測。 為了本教學課程的目的,資料集已依日期分割成兩個區段來進行定型和預測。 這是為了模擬歷程記錄資料和新的串流資料。
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')執行儲存格來定型模型,並將其儲存在 Fabric MLflow 模型登錄中。
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )執行下列程式區塊,以擷取用於使用 Kusto Python 沙盒進行預測的已註冊模型路徑。
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)從最後一個儲存格的輸出中複製模型 URI,以便在後續步驟中使用。
第 8 部分- 設定您的 KQL 查詢集
如需一般資訊,請參閱 建立 KQL 查詢集。
- 從工作區中,選取 [+新建項目],>KQL 查詢集。
- 輸入名稱 MultivariateAnomalyDetectionTutorial,然後選取 [建立]。
- 在 OneLake 資料中 樞 視窗中,選取您儲存資料的 KQL 資料庫。
- 選取 Connect。
第 9 部分- 預測 KQL 查詢集中的異常
執行下列 '.create-or-alter 函式' 查詢來定義
predict_fabric_mvad_fl()儲存函式:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }執行下列預測查詢,將輸出模型 URI 取代為在步驟 7 結尾複製的 URI。
此查詢會根據定型的模型,偵測五個庫存的多變數異常,並將結果轉譯為
anomalychart。 異常點會在第一隻股票(AAPL)上呈現,不過它們代表多變異常(換句話說,特定日期中五隻股票的聯合變化異常)。let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
所導致的異常狀況圖表應顯示下列圖片:

清除資源
當您完成本教學課程時,您可以刪除資源,以避免產生其他成本。 若要刪除資源,請依照這些步驟操作:
- 流覽至工作區首頁。
- 刪除本教學課程中建立的環境。
- 刪除您在本教學課程中建立的 Notebook。
- 刪除本教學課程中使用的 Eventhouse 或 資料庫 。
- 刪除您在本教學課程中建立的 KQL 查詢集。