將 Lakehouse 目的地新增至 eventstream
本文說明如何將 lakehouse 新增為Microsoft Fabric 事件數據流中的事件串流目的地。 針對優化的串流效能和實時查詢,請考慮將數據串流至 Eventhouse,並將 Eventhouse 目的地新增至 eventstream ,然後啟用 Eventhouse OneLake 可用性。
注意
當您立即建立 Eventstream 時,預設會啟用增強功能。 如果您有使用標準功能建立的事件串流,這些事件串流將會繼續運作。 您仍然可以像往常一樣編輯並使用它們。 建議您建立新的 Eventstream 來取代標準事件串流,以便利用增強事件串流的其他功能和優點。
重要
有架構 強制 將數據寫入 Lakehouse 目的地資料表。 所有新寫入資料表都必須在寫入時與目標資料表的架構相容,以確保數據品質。
如果輸出寫入新的 Delta 資料表,則會使用第一個記錄來建立資料表結構描述。 輸出資料的所有記錄都會投射到現有資料表的結構描述。
如果傳入數據的數據行不在現有資料表架構中,則寫入資料表的數據中不會包含額外的數據行。 同樣地,如果傳入的數據遺漏現有資料表架構中的數據行,則遺漏的數據行會寫入資料表,並將值設定為 null。
必要條件
- 在 Fabric 容量授權模式中存取工作區,或具有參與者或更高許可權的試用版授權模式。
- 使用參與者或更高許可權存取 Lakehouse 所在的工作區。
注意
一個事件資料流的來源和目的地數目上限為 11。
將您的 Lakehouse 新增為目的地。
若要將 Lakehouse 目的地新增至預設或衍生的事件串流,請遵循下列步驟。
在 事件資料流的 [編輯模式 ] 中,選取 功能區上的 [新增目的地 ],然後從下拉式清單中選取 [Lakehouse ]。
![[新增目的地] 下拉式列表的螢幕快照,其中已醒目提示 Lakehouse。](media/add-destination-lakehouse/add-destination.png)
將 Lakehouse 節點連線到您的串流節點或運算符。
在 Lakehouse 組態畫面上,完成下列資訊:
- 輸入目的地名稱。
- 選取包含 Lakehouse 的工作區。
- 從您指定的工作區中選取現有的 Lakehouse 。
- 選取現有 Delta 資料表,或建立新的 Delta 資料表來接收資料。
- 選取傳送至 Lakehouse 的輸入數據格式。 支持的數據格式為 JSON、Avro 和 CSV(含標頭)。
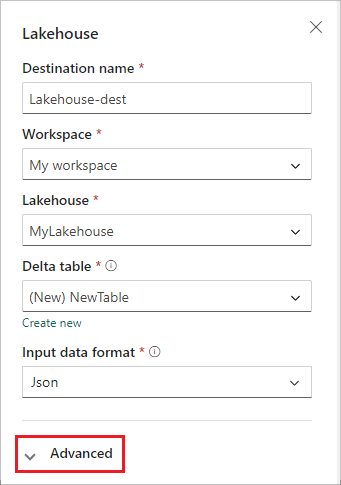
選取進階。
湖屋目的地有兩種擷取模式。 根據您的案例,設定這些模式,以將 Fabric 事件串流寫入 Lakehouse 的方式優化。
最小數據列 是 Lakehouse 內嵌在單一檔案中的最小數據列數目。 最小值為 1 個數據列,每個檔案的最大值為 2 百萬個數據列。 湖屋在擷取期間建立的檔案數目越小,數據列數目越小。
持續時間上限是湖屋內嵌單一檔案所花費的最大持續時間。 最短 1 分鐘,最長 2 小時。 持續時間越長,檔案中會擷取的數據列越多。
![Lakehouse 組態畫面 [進階] 區段的螢幕快照。](media/add-destination-lakehouse/advanced-screen.png)
選取儲存。
若要實作新增的 Lakehouse 目的地,請選取 [ 發佈]。
![[編輯] 模式中串流和 Lakehouse 目的地的螢幕快照,其中已醒目提示 [發佈] 按鈕。](media/add-destination-lakehouse/edit-mode.png)
![[新增目的地] 下拉式列表的螢幕快照,其中已醒目提示 Lakehouse。](media/add-destination-lakehouse/add-destination.png#lightbox)
![[編輯] 模式中串流和 Lakehouse 目的地的螢幕快照,其中已醒目提示 [發佈] 按鈕。](media/add-destination-lakehouse/edit-mode.png#lightbox)
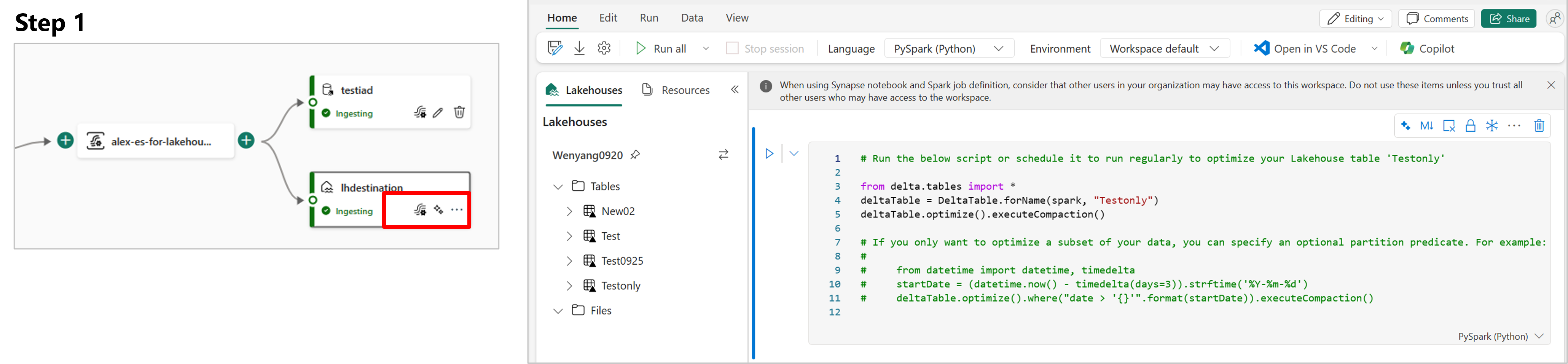
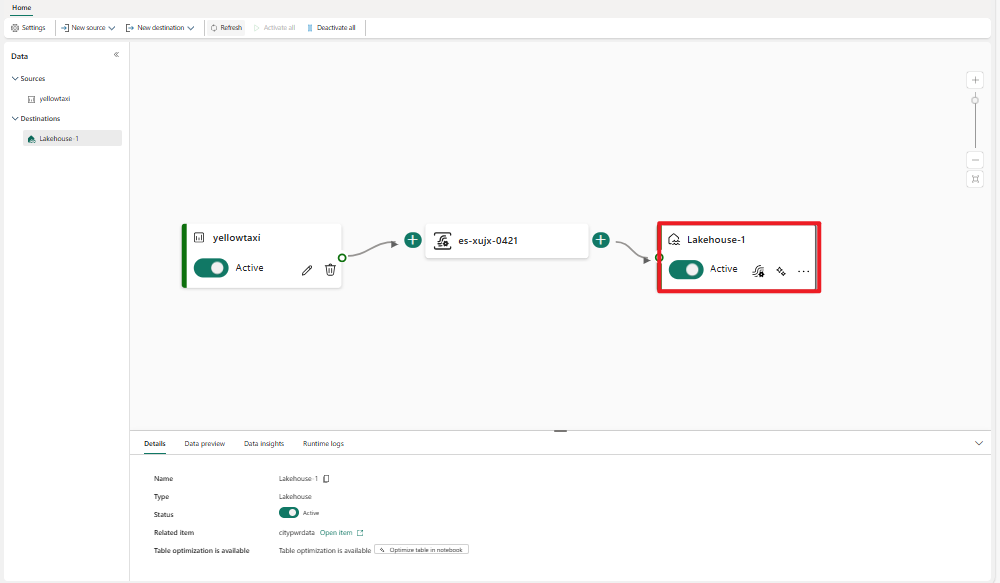
完成這些步驟之後,Lakehouse 目的地即可在 [即時檢視] 中取得視覺效果。 在 [ 詳細數據 ] 窗格中,您可以選取 筆記本快捷方式中的 [優化] 資料表,以在 Notebook 內啟動 Apache Spark 作業,以合併目標 Lakehouse 資料表內的小型串流檔案。
![[實時檢視] 中 Lakehouse 目的地和資料表優化按鈕的螢幕快照。](media/add-destination-lakehouse/live-view.png#lightbox)
相關內容
若要瞭解如何將其他目的地新增至事件資料流,請參閱下列文章:
必要條件
開始之前,您必須完成下列先決條件:
- 在 Fabric 容量授權模式中存取工作區,或具有參與者或更高許可權的試用版授權模式。
- 取得您 Lakehouse 所在位置具有參與者或以上許可權的工作區存取權。
注意
一個事件資料流的來源和目的地數目上限為 11。
將您的 Lakehouse 新增為目的地。
如果您的工作區中已建立 Lakehouse,請遵循下列步驟,將 Lakehouse 新增至事件串流作為目的地:
選取緞帶上的 [新增目的地] 或主要編輯器創作區中的“+”,然後選取 [Lakehouse]。 Lakehouse 目的地設定畫面隨即出現。
輸入 eventstream 目的地的名稱,並完成 Lakehouse 的相關信息。
![Lakehouse [目的地設定] 畫面的螢幕擷取畫面。](media/event-streams-destination/eventstream-destinations-lakehouse.png)
Lakehouse:從您指定的工作區中選取現有的 Lakehouse。
Delta 資料表:選取現有的 Delta 資料表,或建立新的 Delta 資料表來接收資料。
注意
將數據寫入 Lakehouse 資料表時,會 強制執行架構。 結構描述強制執行表示對資料表的所有新寫入會在寫入時強制與目標資料表的結構描述相容,以確保資料品質。
輸出資料的所有記錄都會投射到現有資料表的結構描述。 如果輸出要寫入新的 Delta 資料表,則會使用第一個記錄來建立資料表結構描述。 如果傳入的資料相較於現有資料表結構描述有一個額外的資料行,則會在資料表中寫入,而不會有該額外的資料行。 如果傳入的資料相較於現有資料表結構描述遺漏一個資料行,則會在資料表中寫入資料行,且該資料行為 Null。
輸入數據格式:選取傳送至 Lakehouse 的數據 (輸入資料) 格式。
注意
支援的輸入事件數據格式為 JSON、Avro 和 CSV(含標頭)。
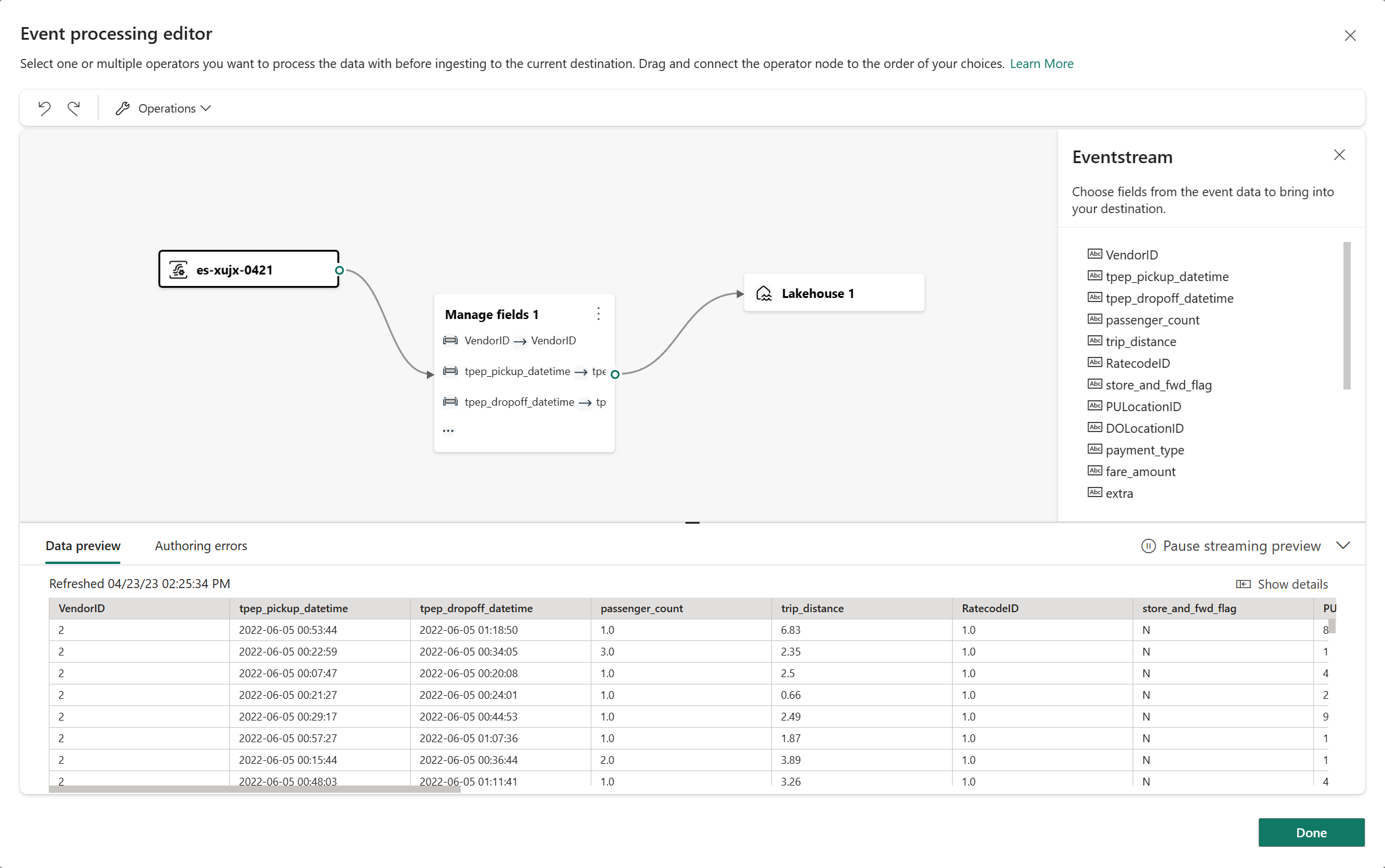
事件處理:您可以使用事件處理編輯器來指定數據在傳送至 Lakehouse 之前應如何處理數據。 選取 [ 開啟事件處理器 ] 以開啟事件處理編輯器。 若要深入瞭解使用事件處理器進行實時處理,請參閱 使用事件處理器編輯器處理事件數據。 當您使用編輯器完成時,請選取 [完成 ] 以返回 Lakehouse 目的地設定畫面。
湖屋目的地有兩種擷取模式。 選取下列其中一種模式,根據您的案例,將 Fabric 事件串流功能寫入 Lakehouse 的方式優化。
每個檔案 的數據列 – Lakehouse 在單一檔案中擷取的數據列數目下限。 Lakehouse 在擷取期間建立的檔案數目越小,數據列數目越小。 最小值為 1 個數據列。 每個檔案的最大值為 200 萬個數據列。
Duration – Lakehouse 擷取單一檔案所花費的最大持續時間。 持續時間越長,檔案中會擷取更多數據列。 最短 1 分鐘,最長 2 小時。
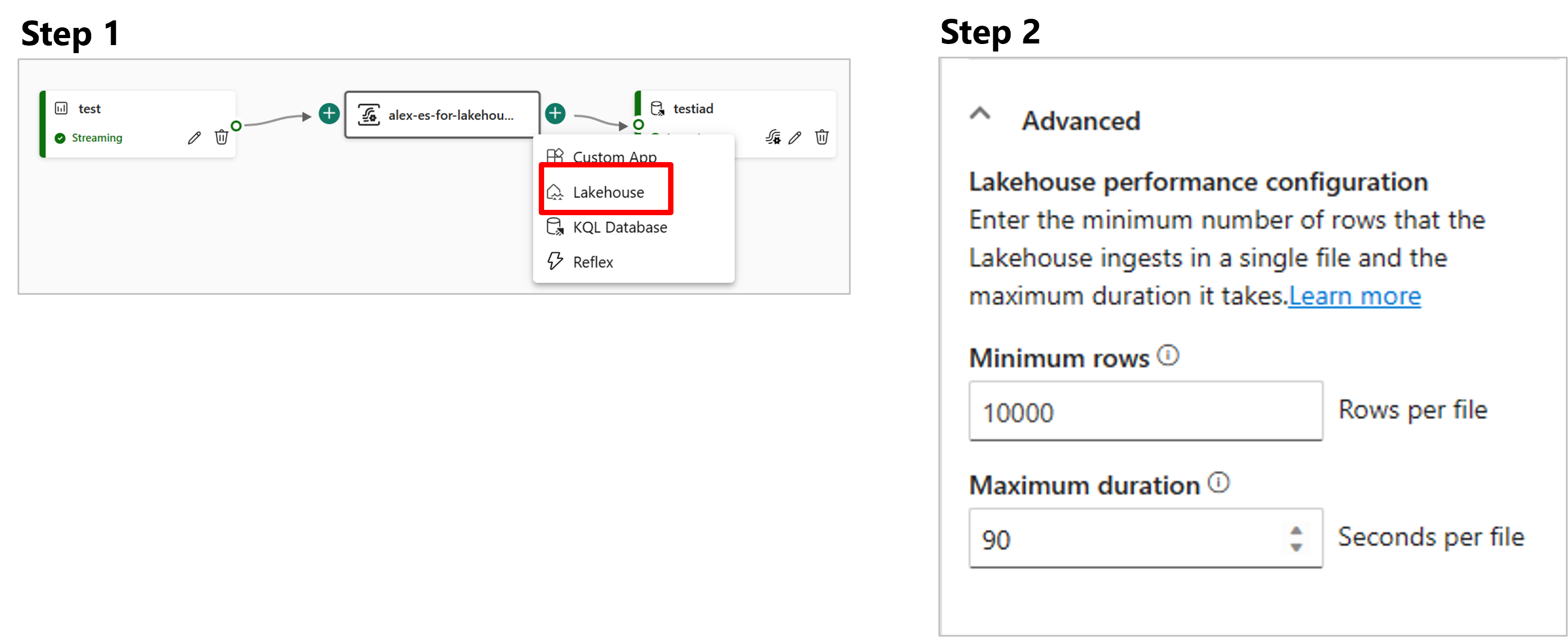
選取 [新增目的地] 以新增其他目的地。
Lakehouse 目的地內可用的資料表優化快捷方式。 此解決方案可藉由在 Notebook 內啟動 Spark 作業,以合併目標 Lakehouse 資料表內的這些小型串流檔案,協助您。
湖屋目的地會出現在畫布上,並顯示旋轉狀態指示器。 系統需要幾分鐘的時間,才能將狀態變更為 [作用中]。
![Lakehouse [目的地設定] 畫面的螢幕擷取畫面。](media/event-streams-destination/eventstream-destinations-lakehouse.png#lightbox)




管理目的地
編輯/移除:您可以透過瀏覽窗格或畫布編輯或移除 eventstream 目的地。
當您選取 [ 編輯] 時,編輯窗格會在主編輯器右側開啟。 您可以視需要修改組態,包括透過事件處理器編輯器的事件轉換邏輯。

相關內容
若要瞭解如何將其他目的地新增至事件資料流,請參閱下列文章: