教學課程:使用 R 預測航班延誤
本教學課程提供 Microsoft Fabric 中 Synapse 資料科學工作流程的端對端範例。 它會使用 nycflights13 資料和 R 來預測飛機是否晚點 30 分鐘以上。 然後,它會使用預測結果來建置互動式 Power BI 儀表板。
在本教學課程中,您會了解如何:
- 使用 tidymodels 套件 (配方、parsnip、rsample、工作流程) 來處理資料並定型機器學習模型
- 將輸出資料寫入 Lakehouse 作為差異資料表
- 建置 Power BI 視覺報表以直接存取該 Lakehouse 中的資料
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
開啟或建立筆記本。 若要了解操作說明,請參閱如何使用 Microsoft Fabric 筆記本。
將語言選項設定為 SparkR (R),以變更主要語言。
將筆記本連結至 Lakehouse。 在左側,選取 [新增],以新增現有的 Lakehouse 或建立 Lakehouse。
安裝套件
安裝 nycflights13 套件,以在本教學課程中使用程式碼。
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
探索資料
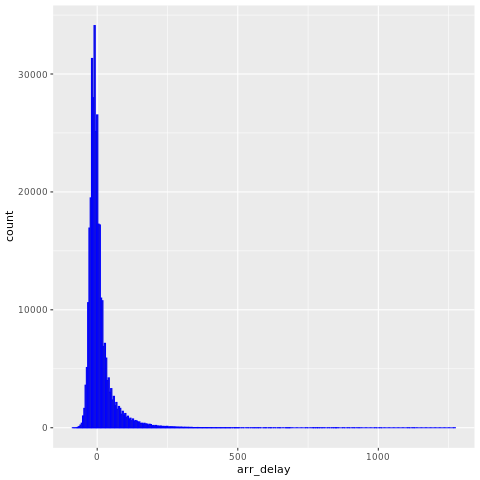
這些 nycflights13 資料有關於 2013 年抵達紐約市附近 325,819 個航班的資訊。 首先,檢視航班延誤的分佈。 此圖表顯示了抵達延遲的分佈偏斜。 它在高值中有長尾。
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
載入資料,並對變數進行一些變更:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
在建置模型之前,請考慮一些對於前置處理和模型而言很重要的特定變數。
變數 arr_delay 屬於因素變數。 對於羅吉斯迴歸模型定型,結果變數是因素變數很重要。
glimpse(flight_data)
此資料集中大約 16% 的航班已晚抵達 30 分鐘以上。
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
此 dest 功能有 104 個航班目的地。
unique(flight_data$dest)
有 16 家不同的航空公司。
unique(flight_data$carrier)
分割資料
將單一資料集分割成兩組:定型集和測試集。 在定型資料集中保留原始資料集的大部分資料列 (以隨機選擇的子集的形式)。 使用定型資料集來配合模型,並使用測試資料集來測量模型效能。
使用 rsample 套件來建立物件,其中包含如何分割資料的相關資訊。 然後,再使用兩個 rsample 函式來建立定型和測試集的 DataFrame:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
建立配方與角色
建立簡單羅吉斯迴歸模型的配方。 在定型模型之前,請使用配方來建立新的預測值,並執行模型所需的前置處理。
使用 update_role() 函式,讓配方知道 flight 和 time_hour 是變數,並具有稱為 ID 的自訂角色。 角色可以具有任一字元值。 此公式包含了定型集中的所有變數 (而非 arr_delay) 作為預測值。 配方會保留這兩個識別碼變數,但不會將它們當做結果或預測值使用。
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
若要檢視目前的一組變數和角色,請使用 summary() 函式:
summary(flights_rec)
建立功能
執行一些特徵工程以改善您的模型。 航班日期可能會對遲到的可能性產生合理影響。
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
新增由日期衍生、對模型有潛在重要性的模型詞彙可能會有幫助。 從單一日期變數衍生下列有意義的功能:
- 星期幾
- Month
- 日期是否對應假日
將三個步驟新增至配方:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
使用配方來調整模型
使用羅吉斯迴歸來建立飛行資料的模型。 首先,使用 parsnip 套件來建置模型規格:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
使用 workflows 套件將 parsnip 模型 (lr_mod) 與您的配方 (flights_rec) 進行捆綁:
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
定型模型
此函式可準備配方,並從產生的預測值定型模型:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
使用協助程式函式 xtract_fit_parsnip() 和 extract_recipe(),並從工作流程中擷取模型或配方物件。 在此範例中,提取適合的模型物件,然後使用 broom::tidy() 函式來取得整齊的模型係數:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
預測結果
對 predict() 的單一呼叫會使用已定型的工作流程 (flights_fit) 來使用未顯示的測試資料進行預測。
predict() 方法會將配方套用至新資料,然後將結果傳遞至適合的模型。
predict(flights_fit, test_data)
從 predict() 取得輸出以傳回預測類別:late 與 on_time。 不過,針對每個飛行的預測類別機率,請搭配模型使用 augment(),結合測試資料,將它們儲存在一起:
flights_aug <-
augment(flights_fit, test_data)
檢閱資料:
glimpse(flights_aug)
評估模型
我們現在有一個包含預測類別機率的 tibble。 在前幾個資料列中,該模型正確預測了五個準時航班 (.pred_on_time 的值為 p > 0.50)。 不過,我們總共有 81,455 個資料列可預測。
我們需要一個計量,來顯示與結果變數 arr_delay 的真實狀態相比,模型預測的延誤情況。
使用「接收者作業特性曲線下方的面積」(AUC-ROC) 作為計量。 使用 roc_curve() 套件中的 roc_auc() 和 yardstick 計算:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
建置 Power BI 報告
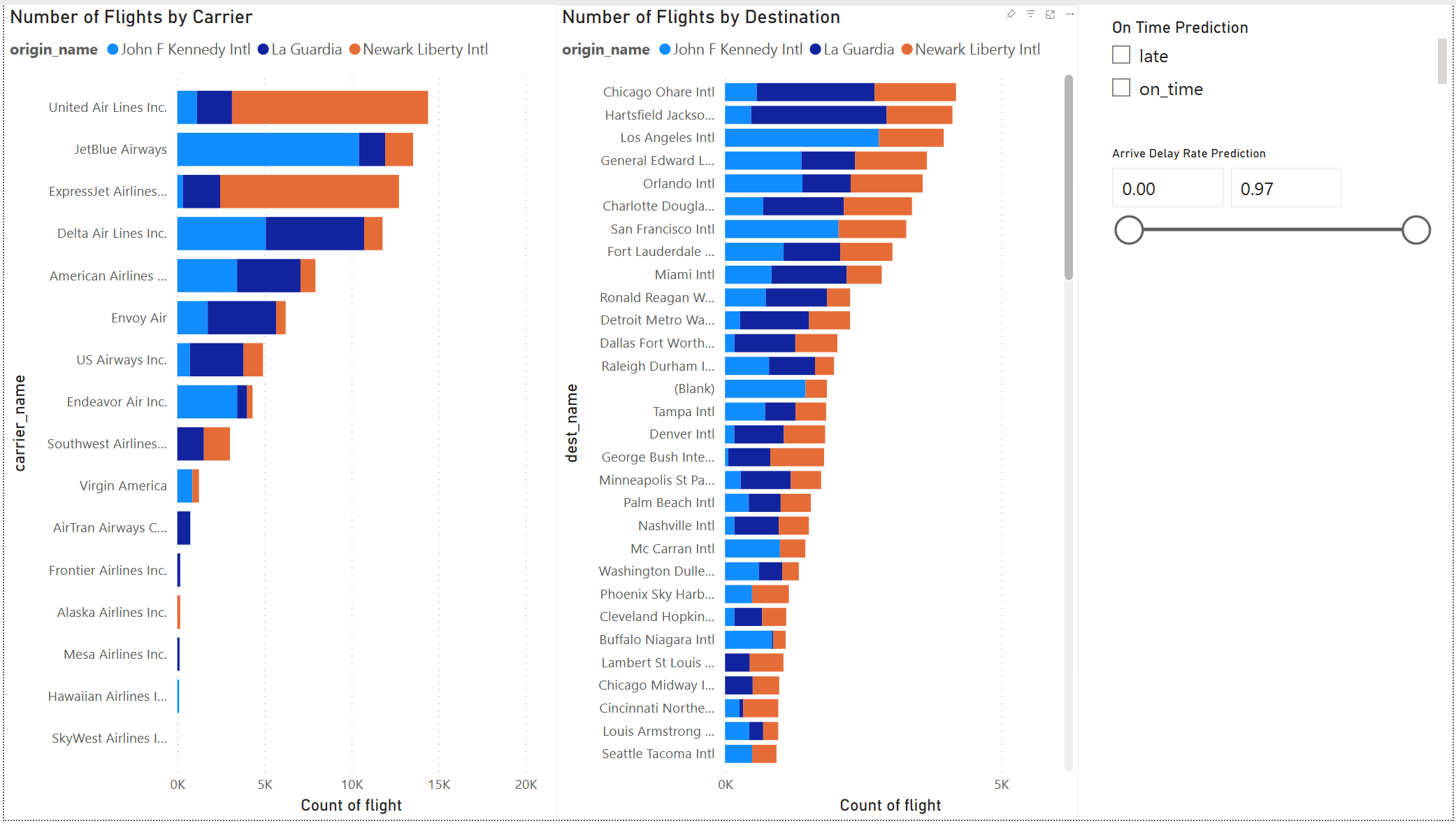
模型結果看起來很不錯。 使用航班延誤預測結果來建置互動式 Power BI 儀表板。 儀表板會顯示依航空公司的航班數目,以及依目的地的航班數目。 儀表板可以依延遲預測結果進行篩選。
在預測結果資料集中包含航空公司名稱和機場名稱:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
檢閱資料:
glimpse(flights_clean)
將資料轉換成 Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
將資料寫入 Lakehouse 中的差異資料表:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
使用差異資料表來建立語意模型。
在左側,選取 [OneLake]
選取您連結至筆記本的 Lakehouse
選取 [開啟]
選取 [新語意模型]
針對新的語意模型選取 nycflight13,然後選取 [確認]
您的語意模型已建立。 選取 [新增報告]
從 [資料] 和 [視覺效果] 窗格選取或拖曳欄位到報表畫布上,以建置報表
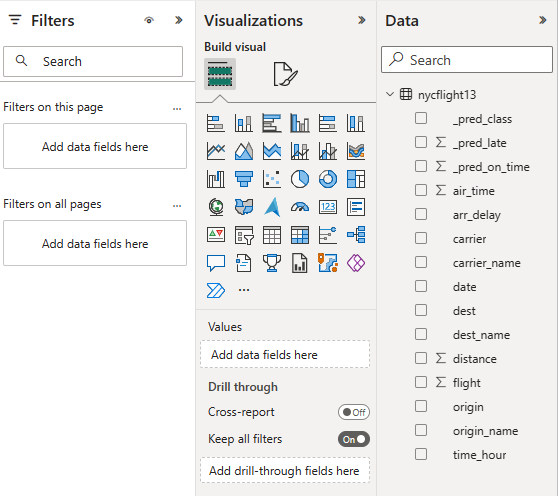
若要建立本節開頭顯示的報表,請使用下列視覺效果和資料:
-
 堆疊橫條圖與:
堆疊橫條圖與:- Y 軸:carrier_name
- X 軸:航班。 為彙總選取 [計數]
- 圖例:origin_name
-
堆疊橫條圖與:
- Y 軸:dest_name
- X 軸:航班。 為彙總選取 [計數]
- 圖例:origin_name
-
 交叉分析篩選器與:
交叉分析篩選器與:- 欄位:_pred_class
-
交叉分析篩選器與:
- 欄位:_pred_late