執行 Azure HDInsight 活動來轉換資料
Microsoft Fabric Data Factory 中的 Azure HDInsight 活動可讓您協調下列 Azure HDInsight 工作類型:
- 執行 Hive 查詢
- 叫用 MapReduce 程式
- 執行 Pig 查詢
- 執行 Spark 程式
- 執行 Hadoop Stream 程式
本文章提供逐步解說,說明如何使用 Data Factory 介面建立 Azure HDInsight 活動。
必要條件
若要開始使用,您必須滿足下列必要條件:
- 具有有效訂用帳戶的租用戶帳戶。 免費建立帳戶。
- 已建立一個工作區。
使用 UI 將 Azure HDInsight (HDI) 活動新增至管線
在工作區中建立新的資料管線
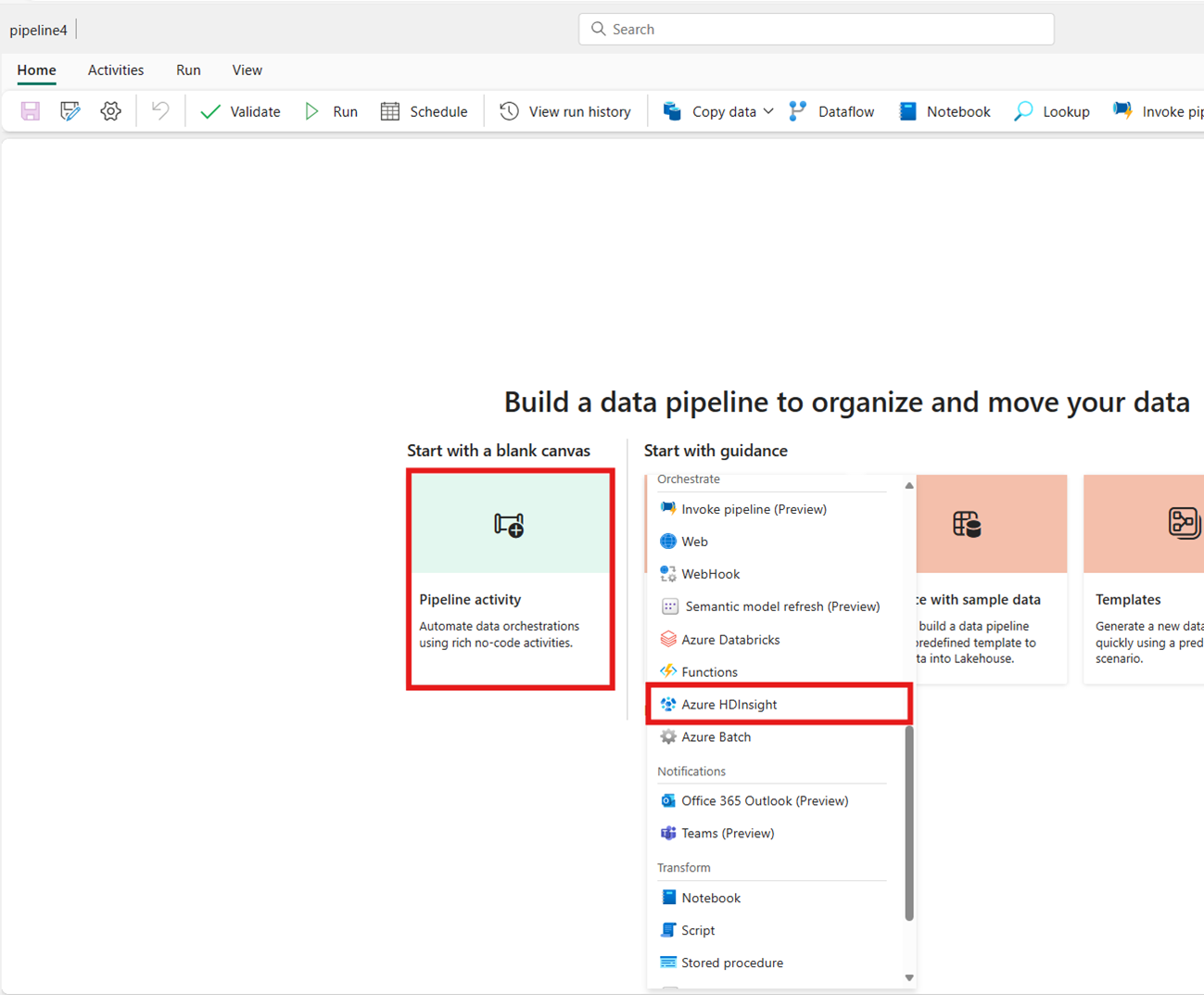
從主螢幕卡片搜尋 Azure HDInsight,然後選取該卡片,或從 [活動] 列中選取活動,將其新增至管線創作區。
從主螢幕卡片建立活動:
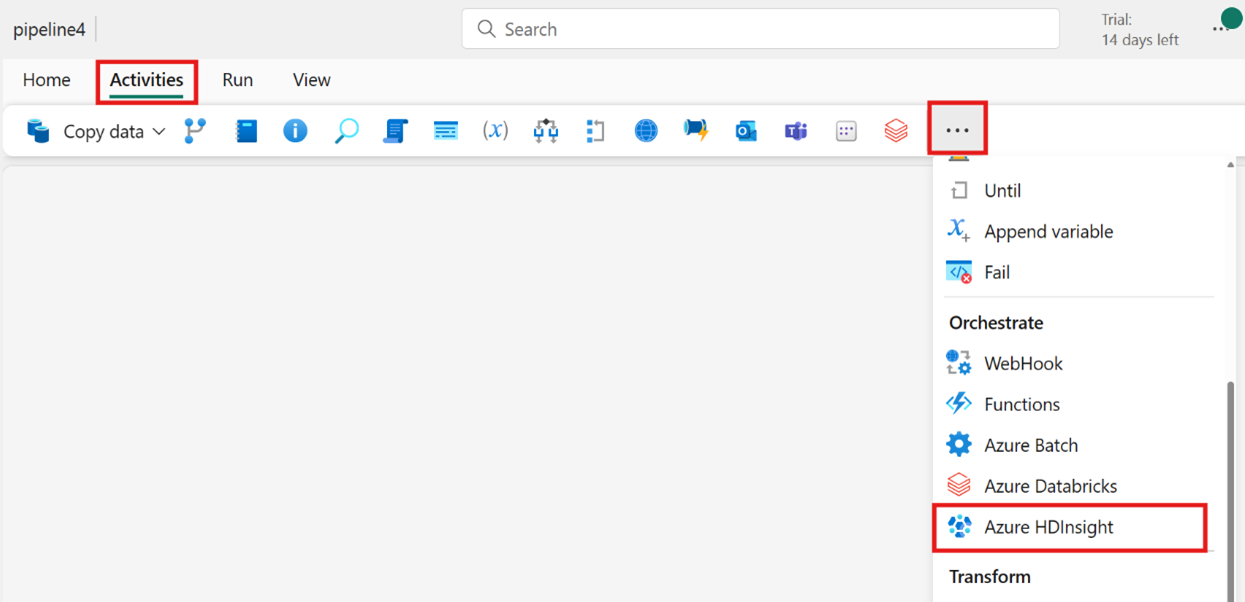
從 [活動] 列建立活動:
如果尚未進行選取,請在管線編輯器創作區選取新的 Azure HDInsight 活動。
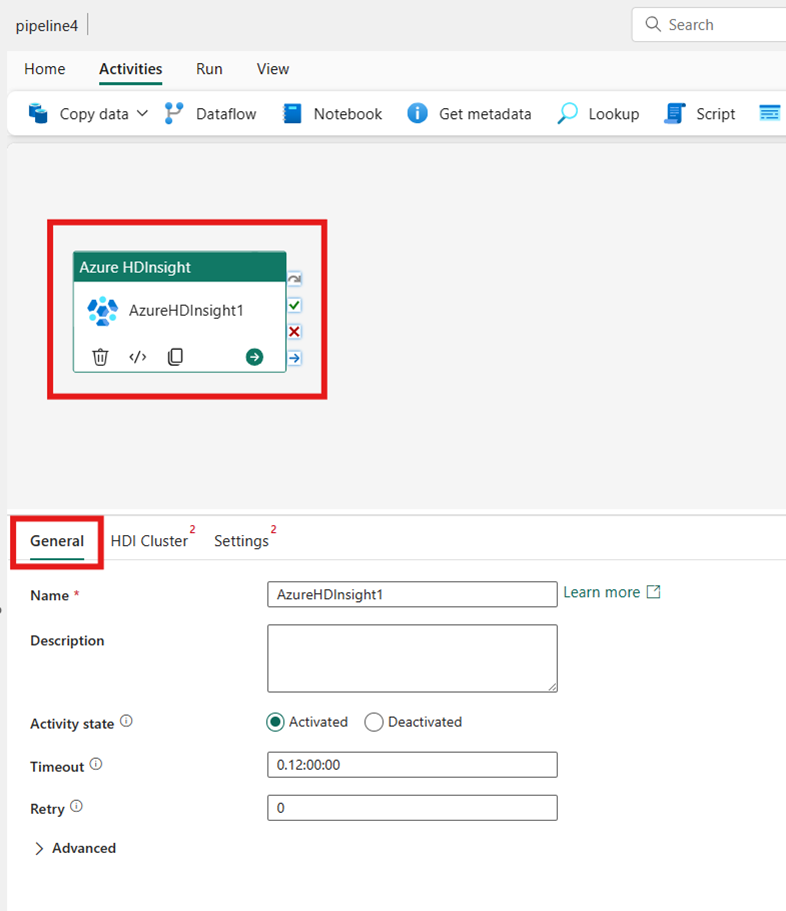
請參閱<[一般] 設定>指導,來設定 [一般] 設定索引標籤中的選項。

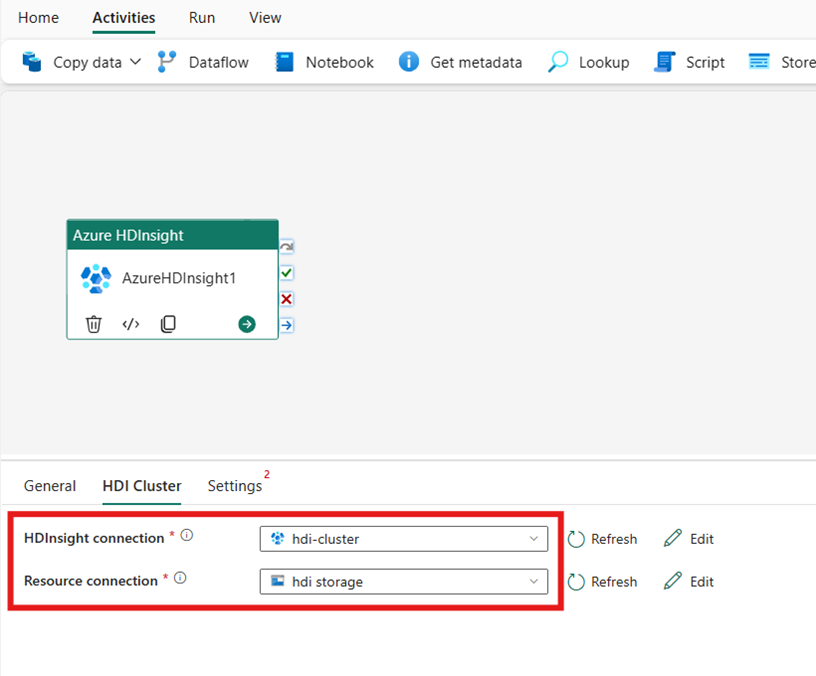
設定 HDI 叢集
選取 [HDI 叢集] 索引標籤。然後,您可以選擇現有的或建立新的 [HDInsight 連線]。
針對 [資源連線],選擇參考 Azure HDInsight 叢集的 Azure Blob 儲存體。 您可以選擇現有的 Blob 存放區或建立新的 Blob 存放區。
配置設定
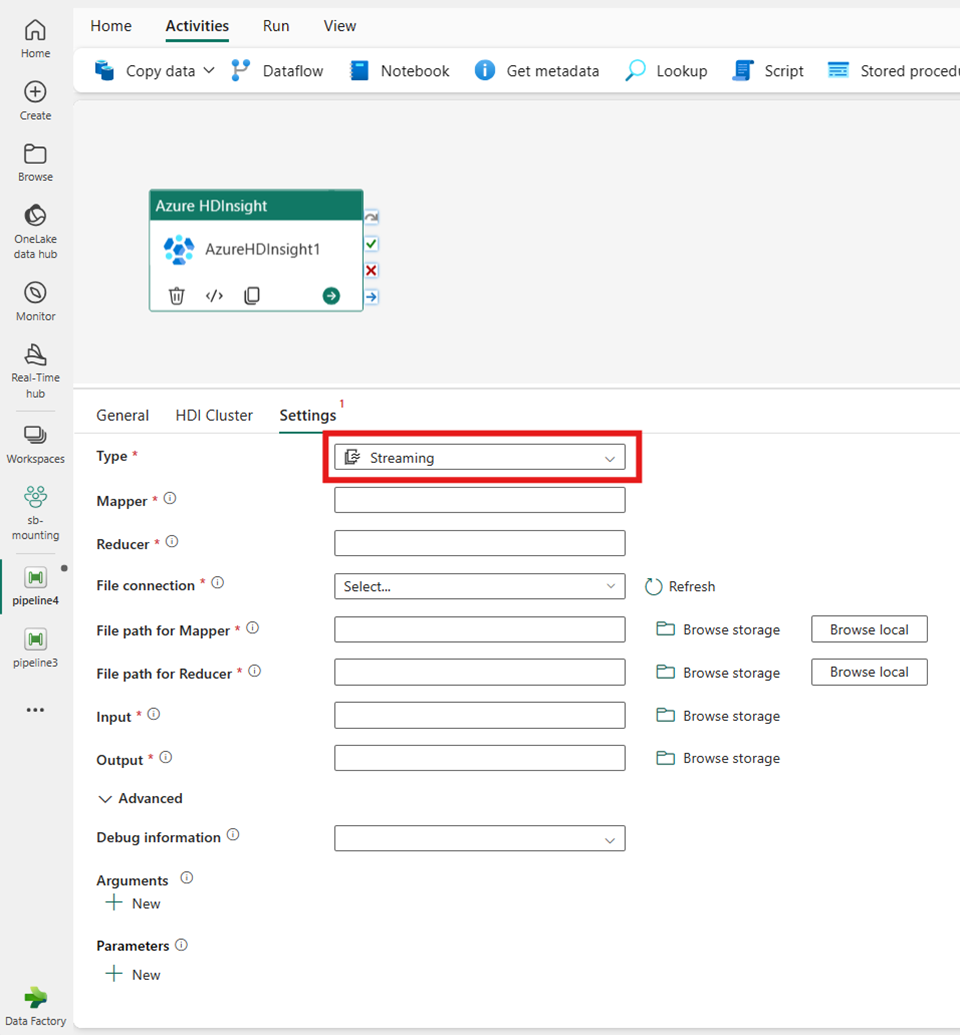
選取 [設定] 索引標籤以查看活動的進階設定。
![此螢幕快照顯示管線編輯器視窗中 Azure HDInsight 活動屬性的 [設定] 索引標籤。.](media/azure-hdinsight-activity/settings.png)
現在,AZURE Data Factory 和 Synapse Analytics HDInsight 連結服務中支援的所有進階叢集屬性和動態運算式在 UI 的 [進階] 區段下的 Microsoft Fabric Data Factory 的 Azure HDInsight 活動中也已受到支援。 這些屬性全都支援使用便於使用的自訂參數化運算式與動態內容。
叢集類型
若要設定 HDInsight 叢集的設定,請先從可用的選項中選擇其 [類型],包括 [Hive]、[Map Reduce]、[Pig]、[Spark] 和 [Streaming]。
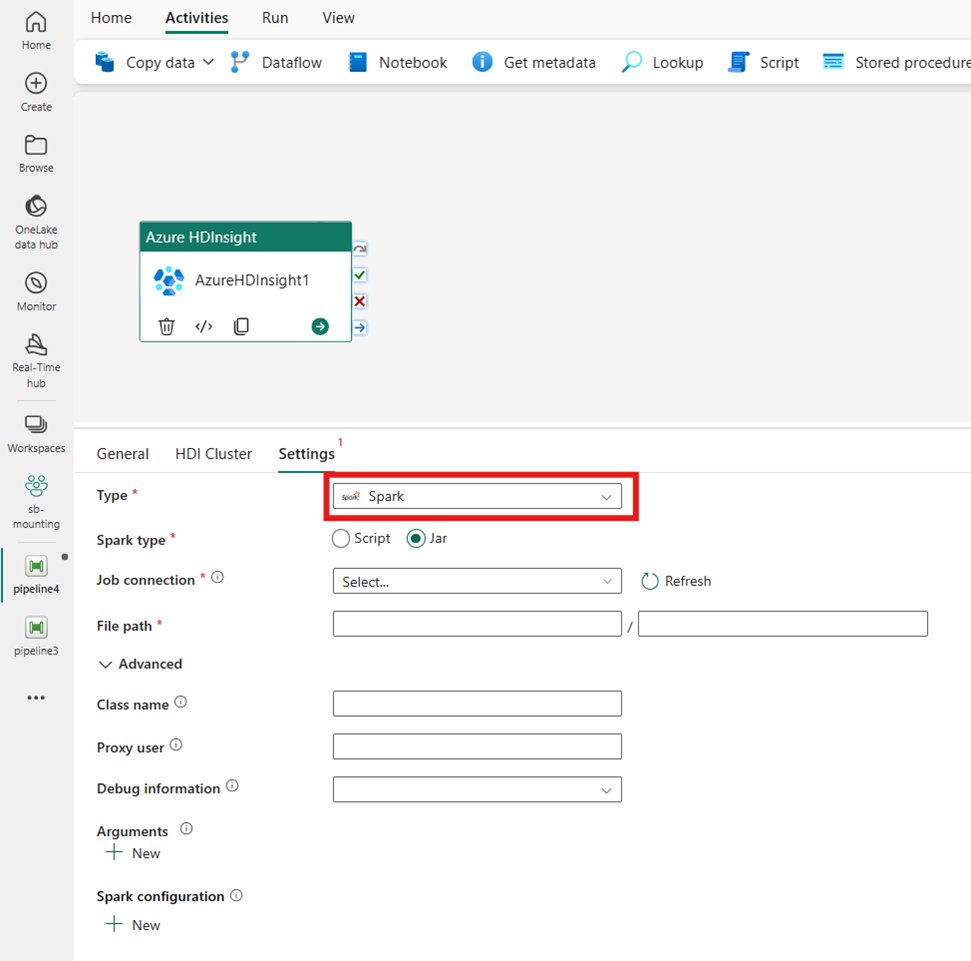
Hive
如果您在 [類型] 選擇 [Hive],活動會執行 Hive 查詢。 您可以選擇性地指定參考保存 Hive 類型的儲存體帳戶的 [指令碼連線]。 根據預設,會使用您在 [HDI 叢集] 索引標籤中指定的儲存體連線。 必須指定要在 Azure HDInsight 上執行的檔案路徑。 您可以選擇性地在 [進階] 區段中指定更多組態,例如 [偵錯資訊]、[查詢逾時]、[引數]、[參數] 和 [變數] 中。
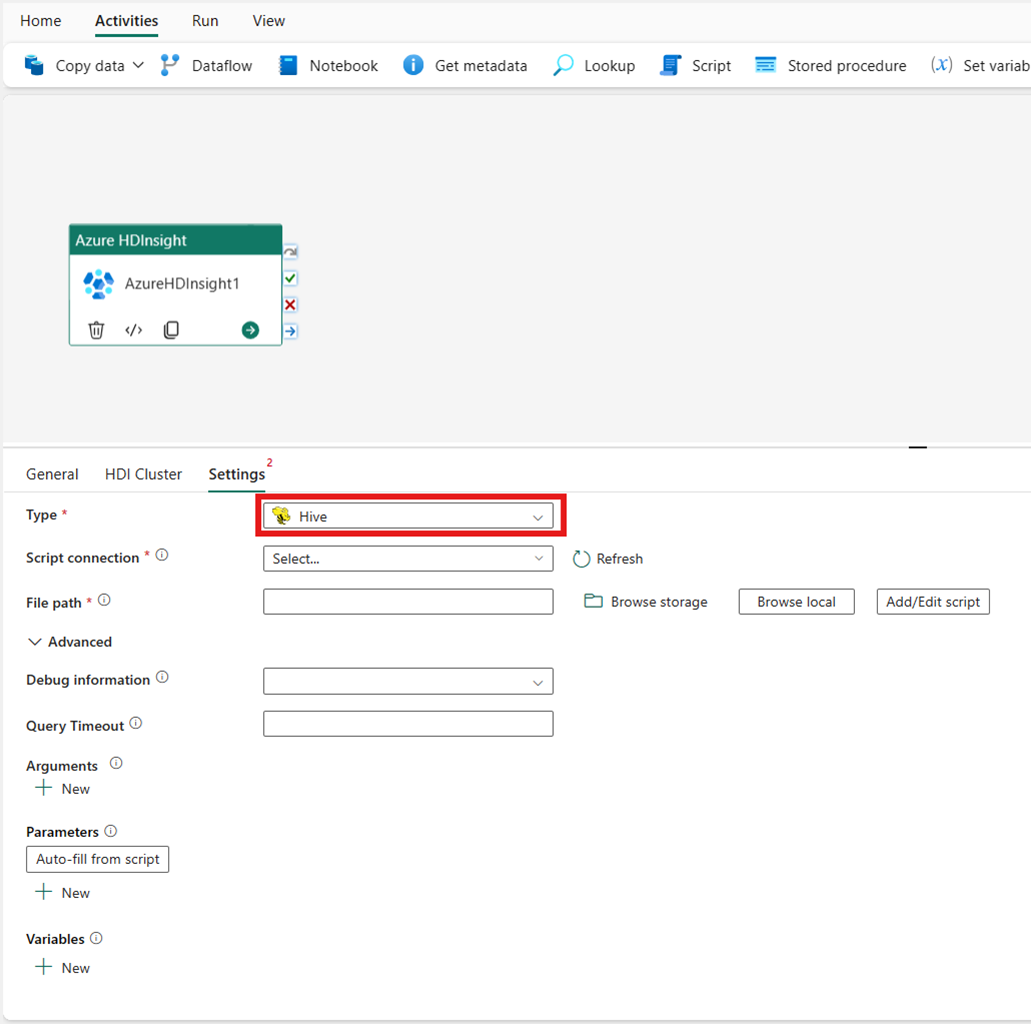
對應縮減
如果您在 [類型] 選擇 [對應縮減],活動會叫用對應縮減程式。 您可以選擇性地指定參考保存 [對應縮減] 類型的儲存體帳戶的 [Jar 連線]。 根據預設,會使用您在 [HDI 叢集] 索引標籤中指定的儲存體連線。 必須指定要在 Azure HDInsight 上執行的類別名稱和檔案路徑。 您可以選擇性地指定更多組態詳細資料,例如在 [進階] 區段下匯入 Jar 程序庫、偵錯資訊、引數和參數。
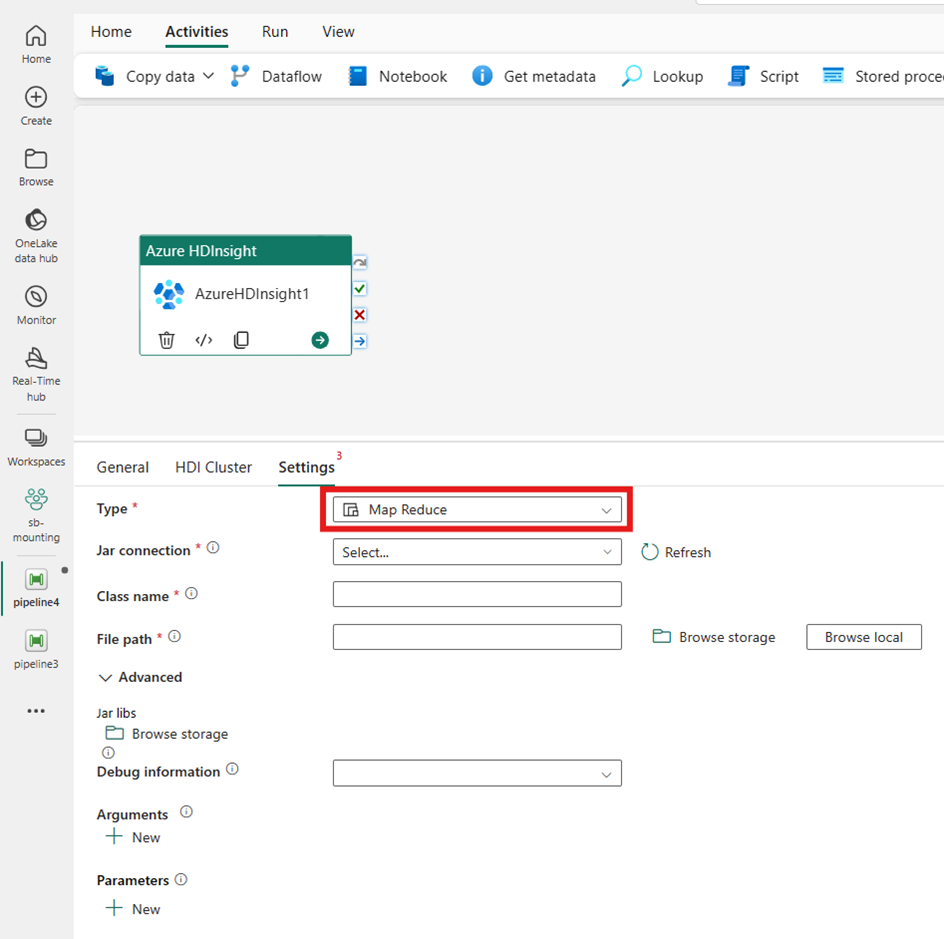
Pig
如果您在 [類型] 選擇 [Pig],活動會叫用 Pig 查詢。 您可以選擇性地指定參考保存 Pig 類型的儲存體帳戶的 [指令碼連線]。 根據預設,會使用您在 [HDI 叢集] 索引標籤中指定的儲存體連線。 必須指定要在 Azure HDInsight 上執行的檔案路徑。 您可以選擇性地指定更多組態,例如 [進階] 區段下的偵錯資訊、引數、參數和變數。
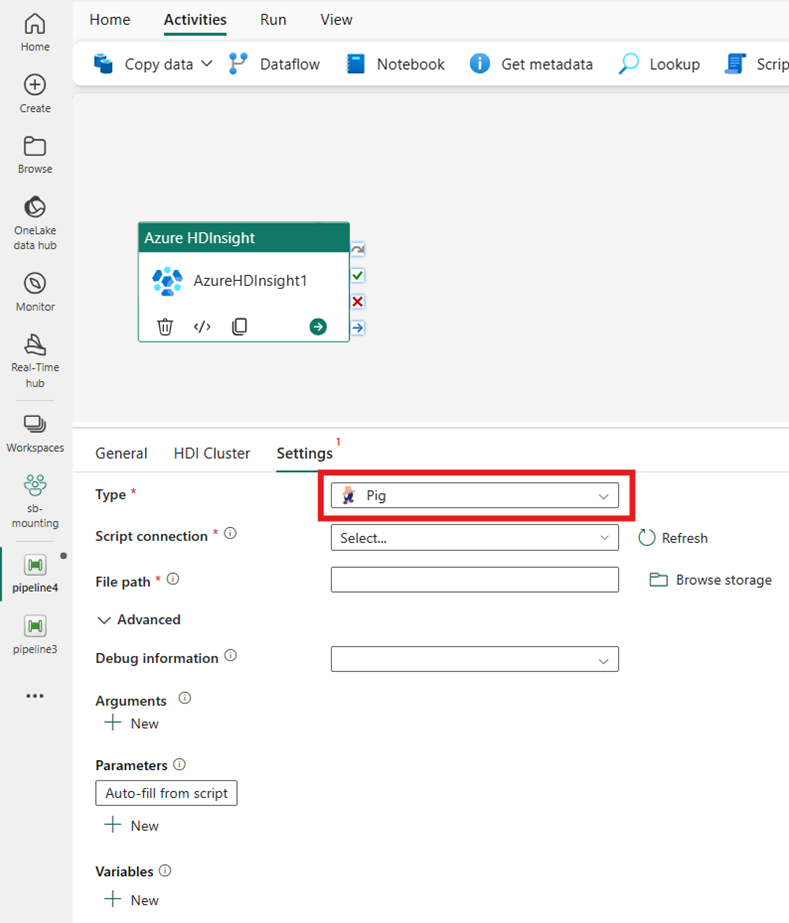
Spark
如果您在 [類型] 選擇 [Spark],活動會叫用 Spark 程式。 在 [Spark 類型] 選取 [指令碼] 或 [Jar]。 您可以選擇性地指定參考保存 Spark 類型的儲存體帳戶的 [工作連線]。 根據預設,會使用您在 [HDI 叢集] 索引標籤中指定的儲存體連線。 必須指定要在 Azure HDInsight 上執行的檔案路徑。 您可以選擇性地在 [進階] 區段下指定更多組態,例如類別名稱、Proxy 使用者、偵錯資訊、引數和 Spark 組態。
串流
如果您在 [類型] 選擇 [串流],活動會叫用串流程式。 指定對應工具和減速工具名稱,而且您可以選擇性地指定參考保存串流類型的儲存體帳戶的檔案連線。 根據預設,會使用您在 [HDI 叢集] 索引標籤中指定的儲存體連線。 必須指定要在 Azure HDInsight 上執行的 [對應工具檔案路徑] 和 [減速工具檔案路徑]。 還需包含 WASB 路徑的輸入和輸出選項。 您可以選擇性地在[進階] 區段下指定更多組態,例如偵錯資訊、引數和參數。
屬性參考
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 針對 Hadoop 資料流活動,活動類型是 HDInsightStreaming | Yes |
| mapper | 指定對應程式可執行檔的名稱 | Yes |
| reducer | 指定減壓器可執行檔的名稱 | Yes |
| 結合子 | 指定結合子可執行檔的名稱 | No |
| 檔案連線 | Azure 儲存體已連結的服務用來儲存要執行之對應程式、結合子和減壓器的參考。 | No |
| 這裡僅支援 Azure Blob 儲存體和 ADLS Gen2 的連線。 如果您未指定此連線,則會使用 HDInsight 連線中定義的儲存體連線。 | ||
| filePath | 提供檔案連線參考之 Azure 儲存體中儲存的對應程式、結合子和減壓器程式的路徑陣列。 | Yes |
| input | 指定對應程式輸入檔案的 WASB 路徑。 | Yes |
| output | 指定減壓器輸出檔案的 WASB 路徑。 | Yes |
| getDebugInfo | 指定何時將記錄檔複製到 HDInsight 叢集所使用 (或) scriptLinkedService 所指定的 Azure 儲存體。 | No |
| 允許的值︰None、Always 或 Failure。 預設值:無。 | ||
| 引數 | 指定 Hadoop 作業的引數陣列。 引數會以命令列引數的方式傳遞給每項工作。 | No |
| 定義 | 指定參數作為機碼/值組,以供在 Hive 指令碼內參考。 | No |
儲存並執行或排程管線
設定管線所需的任何其他活動之後,請切換至管線編輯器頂端的「首頁」索引標籤,然後選取儲存按鈕以儲存管線。 選取執行以直接執行,或選取排程來排程它。 您也可以在這裡檢視執行歷程記錄,或進行其他設定。
![管線編輯器中 [首頁] 索引標籤的螢幕擷取畫面,其中已醒目提示索引標籤名稱、[儲存]、[執行] 和 [排程] 按鈕。](media/azure-hdinsight-activity/save-run-schedule.png)