在 Azure Synapse Analytics 中使用無伺服器 SQL 集區建立和使用檢視
在本節中,您將瞭解如何建立和使用檢視來包裝無伺服器 SQL 集區查詢。 檢視可讓您重複使用這些查詢。 如果您想要搭配無伺服器 SQL 集區使用 Power BI 之類的工具,也需要檢視。
必要條件
您的第一個步驟是建立檢視的資料庫,並藉由在該資料庫上執行 安裝腳本 ,初始化在 Azure 記憶體上驗證所需的物件。 本文中的所有查詢都會在您的範例資料庫上執行。
檢視外部數據
您可以建立檢視的方式與建立一般 SQL Server 檢視的方式相同。 下列查詢會建立可讀取 population.csv檔案的 檢視。
注意
變更查詢中的第一行,也就是 [mydbname],以使用您所建立的資料庫。
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
檢視會使用 EXTERNAL DATA SOURCE 具有記憶體根 URL 的 ,作為 DATA_SOURCE ,並將相對檔案路徑新增至檔案。
Delta Lake 檢視
如果您要在 Delta Lake 資料夾頂端建立檢視,您必須在 選項後面 BULK 指定根資料夾的位置,而不是指定檔案路徑。
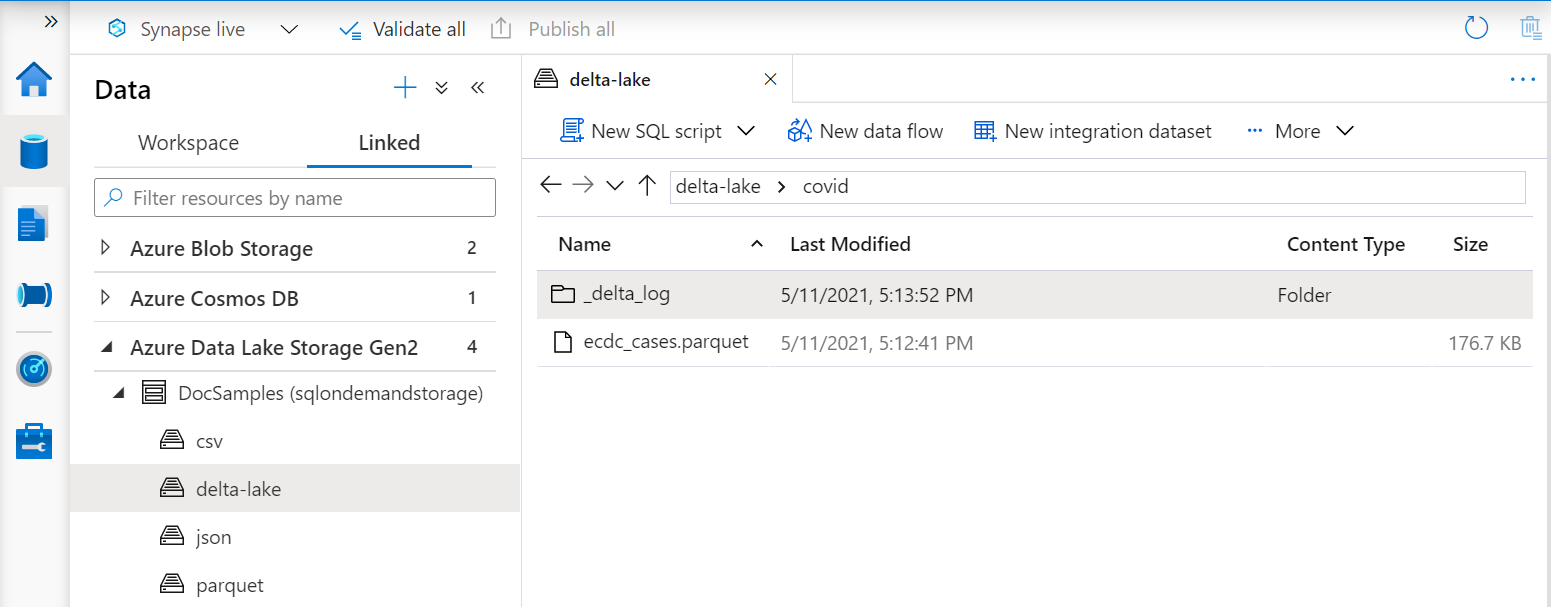
OPENROWSET從 Delta Lake 資料夾讀取資料的函式會檢查資料夾結構,並自動識別檔案位置。
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
如需詳細資訊,請檢閱 Synapse 無伺服器 SQL 集區自助頁面 和 Azure Synapse Analytics 已知問題。
分割的檢視
如果您有一組在階層式資料夾結構中分割的檔案,您可以使用檔案路徑中的通配符來描述分割模式。 使用 函 FILEPATH 式,將資料夾路徑的一部分公開為分割數據行。
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
當您使用數據分割數據行上的篩選來查詢數據分割時,數據分割檢視可以改善查詢的效能。 不過,並非所有查詢都支援刪除分割區,因此請務必遵循一些最佳做法。
若要確保數據分割消除,請避免在篩選中使用子查詢,因為它們可能會干擾消除分割區的能力。 相反地,將子查詢的結果當做變數傳遞至篩選。
在 SQL 查詢中使用 JOIN 時,將篩選述詞宣告為 NVARCHAR,以減少查詢計劃的複雜性,並增加正確數據分割消除的可能性。 分割區數據行通常會推斷為 NVARCHAR(1024),因此針對述詞使用相同的類型可避免隱含轉換的需求,這會增加查詢計劃的複雜性。
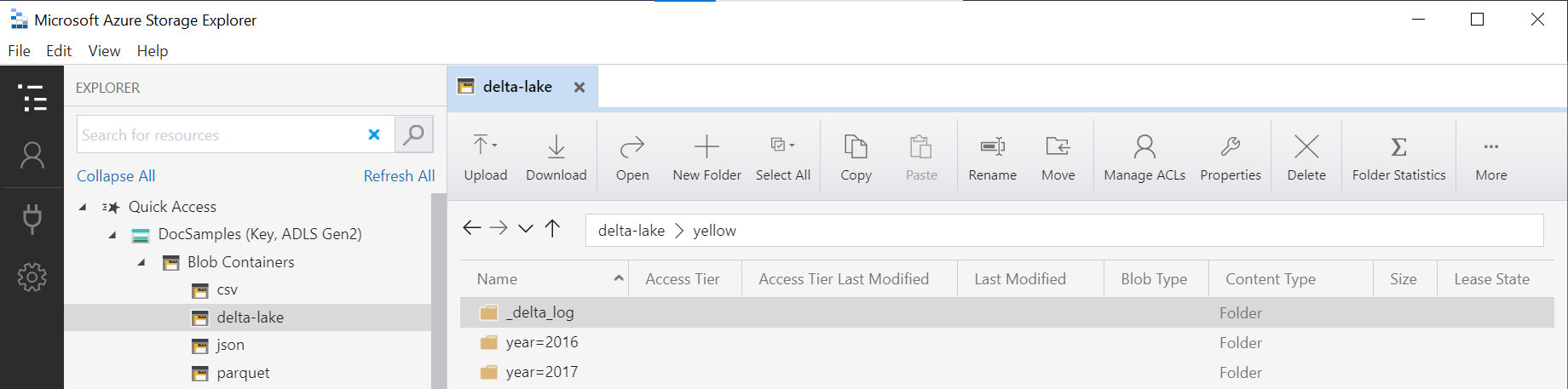
Delta Lake 數據分割檢視
如果您要在 Delta Lake 記憶體頂端建立數據分割檢視,您可以只指定根 Delta Lake 資料夾,而且不需要使用 FILEPATH 函式明確公開數據分割數據行:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
函 OPENROWSET 式會檢查基礎 Delta Lake 資料夾的結構,並自動識別和公開數據分割數據行。 如果您將分割區數據行放在查詢的 子句中 WHERE ,則會自動刪除資料分割。
函式中的OPENROWSET資料夾名稱(yellow在此範例中為)與數據源中DeltaLakeStorage定義的URI串連LOCATION,必須參考根 Delta Lake 資料夾,其中包含名為_delta_log的子資料夾。
如需詳細資訊,請檢閱 Synapse 無伺服器 SQL 集區自助頁面 和 Azure Synapse Analytics 已知問題。
JSON 檢視
如果您需要在從檔案擷取的結果集上進行一些額外的處理,則檢視是不錯的選擇。 其中一個範例可能是剖析 JSON 檔案,其中我們需要套用 JSON 函式,以從 JSON 檔擷取值:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
函 OPENJSON 式會剖析 JSONL 檔案中的每個行,其中包含每行一個 JSON 檔,格式為文字格式。
容器上的 Azure Cosmos DB 檢視
如果容器上已啟用 Azure Cosmos DB 分析記憶體,則可以在 Azure Cosmos DB 容器之上建立檢視。 Azure Cosmos DB 帳戶名稱、資料庫名稱和容器名稱應該新增為檢視的一部分,而唯讀存取密鑰應該放在檢視所參考的資料庫範圍認證中。
此範例文本會使用您可以遵循 這些指示來設定的資料庫和容器。
重要
在文稿中,以您自己的值取代這些值:
- your-cosmosdb - Cosmos DB 帳戶的名稱
- access-key - 您的 Cosmos DB 帳戶密鑰
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
如需詳細資訊,請參閱 在 Azure Synapse Link 中使用無伺服器 SQL 集區查詢 Azure Cosmos DB 數據。
使用檢視
您可以在查詢中使用檢視表,就像在 SQL Server 查詢中使用檢視表一樣。
下列查詢示範如何使用我們在建立檢視中建立的population_csv檢視。 它會以遞減順序傳回 2019 年其人口的國家/地區名稱。
注意
變更查詢中的第一行,也就是 [mydbname],以使用您所建立的資料庫。
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
當您查詢檢視時,可能會遇到錯誤或非預期的結果。 這可能表示檢視會參考已修改或已不存在的數據行或物件。 您必須手動調整檢視定義,以配合基礎架構變更。
相關內容
如需如何查詢不同文件類型的資訊,請參閱查詢單一 CSV 檔案、查詢 Parquet 檔案和查詢 JSON 檔案一文。