查詢 CSV 檔案
在本文中,您將瞭解如何使用 Azure Synapse Analytics 中的無伺服器 SQL 集區來查詢單一 CSV 檔案。 CSV 檔案的格式可能不同:
- 使用和不含標頭數據列
- 逗號和製表元分隔值
- Windows 和 Unix 樣式行結尾
- 非引號和引號值,以及逸出字元
上述所有變化將涵蓋於下方。
快速入門範例
OPENROWSET 函式可讓您藉由提供檔案的 URL 來讀取 CSV 檔案的內容。
讀取 CSV 檔案
檢視檔案 CSV 內容最簡單的方式是提供檔案 URL 以 OPENROWSET 運作、指定 csv FORMAT和 2.0 PARSER_VERSION。 如果檔案可供公開使用,或如果您的Microsoft Entra 身分識別可以存取此檔案,您應該能夠使用查詢來查看檔案的內容,如下列範例所示:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
選項 firstrow 可用來略過 CSV 檔案中的第一個數據列,此案例中代表標頭。 請確定您可以存取此檔案。 如果您的檔案受到 SAS 金鑰或自定義身分識別的保護,則必須設定 sql 登入的伺服器層級認證。
重要
如果您的 CSV 檔案包含 UTF-8 個字元,請確定您使用的是 UTF-8 資料庫定序(例如 Latin1_General_100_CI_AS_SC_UTF8)。
檔案中的文字編碼與定序不符可能會導致非預期的轉換錯誤。
您可以使用下列 T-SQL 語句,輕鬆變更目前資料庫的預設順序: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
資料來源使用量
上一個範例會使用檔案的完整路徑。 或者,您可以使用指向儲存體根資料夾的位置來建立外部資料來源:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
建立資料源之後,您就可以使用該數據源和函式中 OPENROWSET 檔案的相對路徑:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
如果數據源受到 SAS 金鑰或自定義身分識別的保護,您可以使用資料庫範圍認證來設定數據源。
明確指定架構
OPENROWSET 可讓您明確指定要使用 子句從檔案 WITH 讀取的數據行:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
子句中 WITH 數據類型後面的數位代表 CSV 檔案中的數據行索引。
重要
如果您的 CSV 檔案包含 UTF-8 個字元,請確定您明確為 子句中的所有WITH數據行指定一些 UTF-8 定序,Latin1_General_100_CI_AS_SC_UTF8或在資料庫層級設定某些 UTF-8 定序。
檔案中的文字編碼與定序不符可能會導致非預期的轉換錯誤。
您可以使用下列 T-SQL 語句,輕鬆變更目前資料庫的預設順序:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 您可以使用下列定義,輕鬆地在資料行類型上設定定序: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
在下列各節中,您可以看到如何查詢各種類型的 CSV 檔案。
必要條件
您的第一個步驟是 建立將建立數據表的資料庫 。 然後在該資料庫上執行安裝指令碼,將物件初始化。 此安裝指令碼會建立資料來源、資料庫範圍認證,以及用於這些範例中的外部檔案格式。
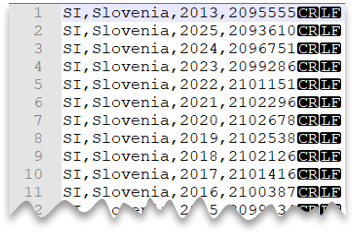
Windows 樣式新行
下列查詢示範如何使用 Windows 樣式的新行和逗號分隔數據行來讀取不含標頭數據列的 CSV 檔案。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
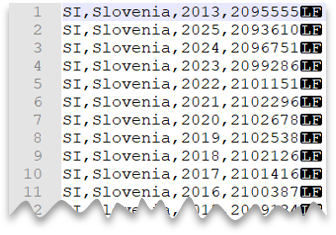
Unix 樣式的新行
下列查詢示範如何使用 Unix 樣式的新行和逗號分隔數據行來讀取沒有標題數據列的檔案。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
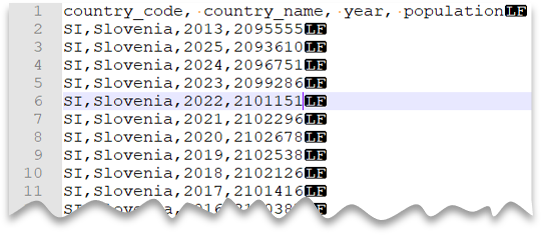
標頭數據列
下列查詢示範如何使用標頭數據列、使用 Unix 樣式的新行和逗號分隔數據行的讀取檔案。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
選項 HEADER_ROW = TRUE 會導致從檔案中的標頭數據列讀取數據行名稱。 當您不熟悉檔案內容時,這很適合用於探索用途。 若要獲得最佳效能,請參閱最佳做法中使用適當的資料類型一節。 此外,您可以在這裡閱讀更多有關 OPENROWSET 語法的資訊。
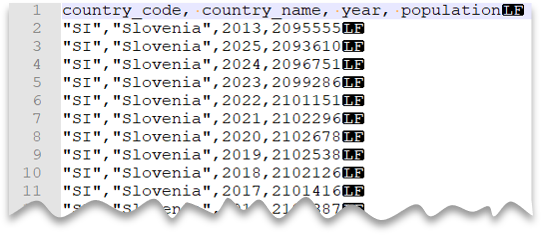
自訂引號字元
下列查詢示範如何使用 Unix 樣式的新行、逗號分隔的數據行和引號值來讀取具有標頭數據列的檔案。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
注意
如果您省略 FIELDQUOTE 參數,此查詢會傳回相同的結果,因為 FIELDQUOTE 的預設值是雙引號。
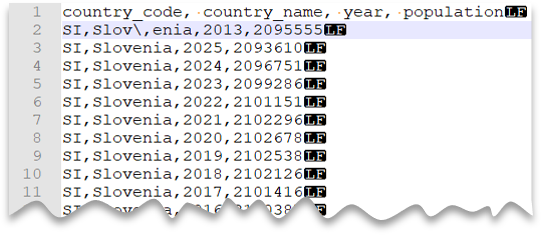
逸出字元
下列查詢示範如何讀取具有標頭數據列的檔案、具有 Unix 樣式的新行、逗號分隔數據行,以及用於值內欄位分隔符(逗號)的逸出字元。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
如果未指定 ESCAPECHAR,則此查詢會失敗,因為 「Slov, enia」 中的逗號會被視為欄位分隔符,而不是國家/地區名稱的一部分。 “Slov,enia” 將被視為兩個數據行。 因此,特定數據列會有一個數據行多於其他數據列,以及一個數據行多於您在WITH子句中定義的數據行。
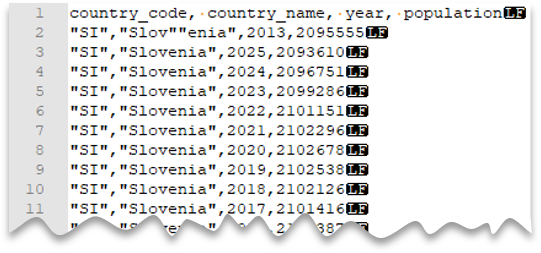
逸出引號字元
下列查詢示範如何使用標頭數據列、使用 Unix 樣式的新行、逗號分隔的數據行,以及值內的逸出雙引號字元來讀取檔案。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
引號字元必須以另一個引號字元來逸出。 只有在以引號字元封住值時,引號字元才能在資料行值中出現。
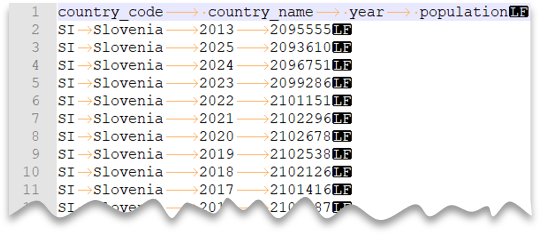
索引標籤分隔的檔案
下列查詢顯示如何使用標頭數據列、使用 Unix 樣式的新行和製表符分隔數據行來讀取檔案。 請注意與其他範例相比,檔案的不同位置。
檔案預覽:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
傳回數據行的子集
到目前為止,您已使用WITH指定 CSV 檔案架構,並列出所有資料行。 您只能針對所需的每個資料行使用序數來指定查詢中實際需要的數據行。 您也會省略不感興趣的數據行。
下列查詢會傳回檔案中相異國家/地區名稱的數目,只指定所需的數據行:
注意
請查看下列查詢中的WITH子句,並注意您在定義 [country_name] 資料行的數據列結尾有 “2” (不含引號)。 這表示 [country_name] 數據行是檔案中的第二個數據行。 查詢會忽略檔案中的所有數據行,但第二個數據行除外。
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
查詢可附加的檔案
查詢執行時,不應該變更查詢中使用的 CSV 檔案。 在長時間執行的查詢中,SQL 集區可能會重試讀取、讀取部分檔案,或甚至多次讀取檔案。 檔案內容的變更會導致錯誤的結果。 因此,如果偵測到查詢執行期間變更任何檔案的修改時間,SQL 集區就會失敗。
在某些情況下,您可能想要讀取不斷附加的檔案。 若要避免查詢失敗,因為經常附加的檔案,您可以允許函 OPENROWSET 式忽略使用 ROWSET_OPTIONS 設定可能不一致的讀取。
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
讀取 ALLOW_INCONSISTENT_READS 選項會在查詢生命週期期間停用檔案修改時間檢查,並讀取檔案中可用的任何專案。 在可附加的檔案中,現有的內容不會更新,而只會新增資料列。 因此,相較於可更新的檔案,這會將錯誤結果的機率降到最低。 此選項可讓您讀取經常附加的檔案,而無須處理錯誤。 在大部分情況下,SQL 集區只會忽略查詢執行期間附加至檔案的某些數據列。
下一步
下一篇文章將說明如何: