教學課程:使用 Synapse 工作區搭配 IntelliJ 來建立 Apache Spark 應用程式
本教學課程說明如何使用 Azure Toolkit for IntelliJ 外掛程式來開發以 Scala 撰寫的 Apache Spark 應用程式,然後直接從 IntelliJ 整合式開發環境 (IDE) 將其提交至無伺服器 Apache Spark 集區。 您可以利用數個方式來使用此外掛程式:
- 在 Spark 集區上開發並提交 Scala Spark 應用程式。
- 存取 Spark 集區資源。
- 在本機開發並執行 Scala Spark 應用程式。
在本教學課程中,您會了解如何:
- 使用 Azure Toolkit for IntelliJ 外掛程式
- 開發 Apache Spark 應用程式
- 將應用程式提交至 Spark 集區
必要條件
Azure 工具組外掛程式 3.27.0-2019.2 - 從 IntelliJ 外掛程式存放庫來安裝
Scala 外掛程式 - 從 IntelliJ 外掛程式存放庫來安裝。
下列必要條件僅適用於 Windows 使用者:
在 Windows 電腦上執行本機 Spark Scala 應用程式時,可能會發生如 SPARK-2356 中所述的例外狀況。 發生這個例外狀況是因為 Windows 上遺失 WinUtils.exe。 若要解決這個錯誤,請將 WinUtils 可執行檔下載至 C:\WinUtils\bin 之類的位置。 然後,新增環境變數 HADOOP_HOME,並將變數的值設為 C:\WinUtils。
建立適用於 Spark 集區的 Spark Scala 應用程式
啟動 IntelliJ IDEA,然後選取 [建立新專案] 來開啟 [新增專案] 視窗。
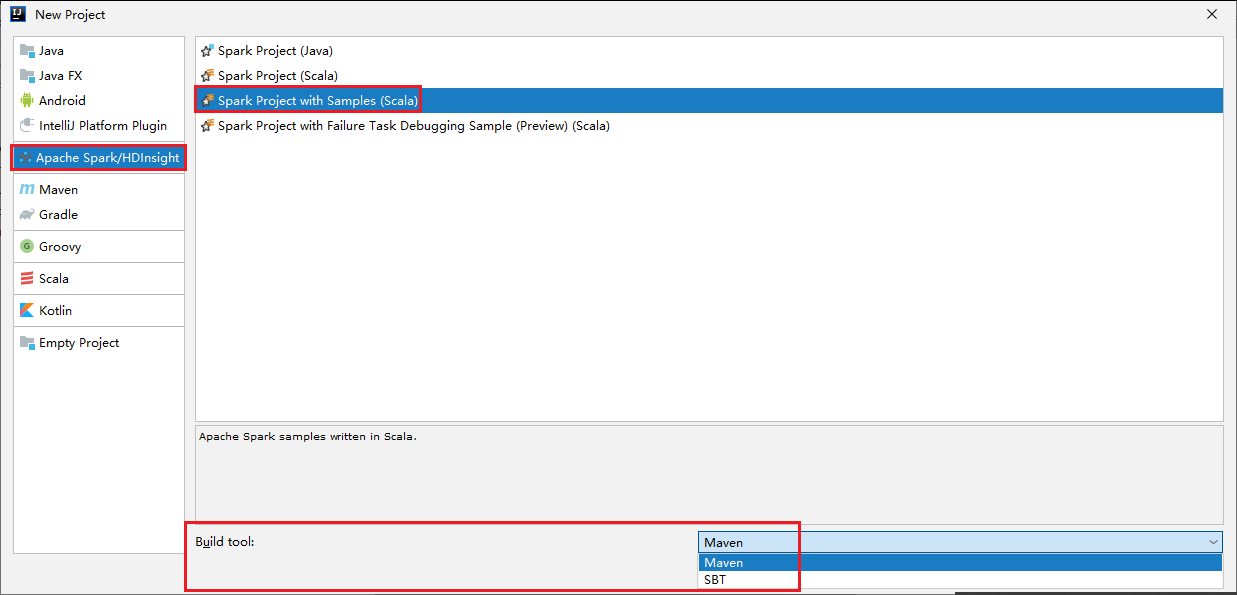
選取左窗格中的 [Apache Spark/HDInsight]。
選取主視窗中的 [Spark 專案與範例 (Scala)]。
從 [建置工具] 下拉式清單中,選取下列其中一種類型:
- Maven:建立 Scala 專案精靈支援。
- SBT:可供管理相依性並建置 Scala 專案。
選取 [下一步]。
在 [新增專案] 視窗中,提供下列資訊:
屬性 說明 專案名稱 輸入名稱。 本教學課程使用 myApp。專案位置 輸入所要的位置以儲存您的專案。 專案 SDK 您第一次使用 IDEA 時,這可能是空白的。 選取 [新增...] 並瀏覽至您的 JDK。 Spark 版本 建立精靈會為 Spark SDK 和 Scala SDK 整合正確的版本。 您可以在這裏選擇所需的 Spark 版本。 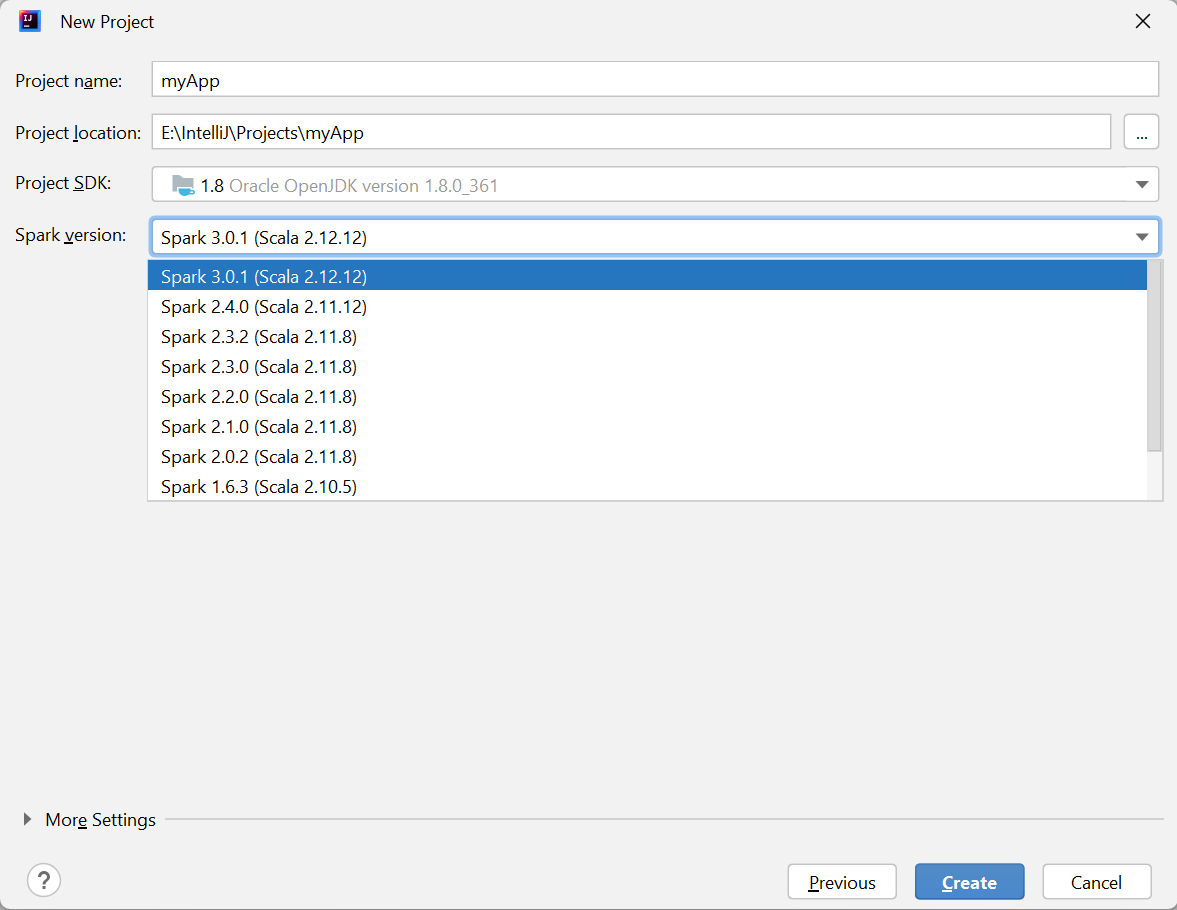
選取 [完成]。 可能需要幾分鐘的時間,專案才會變成可用。
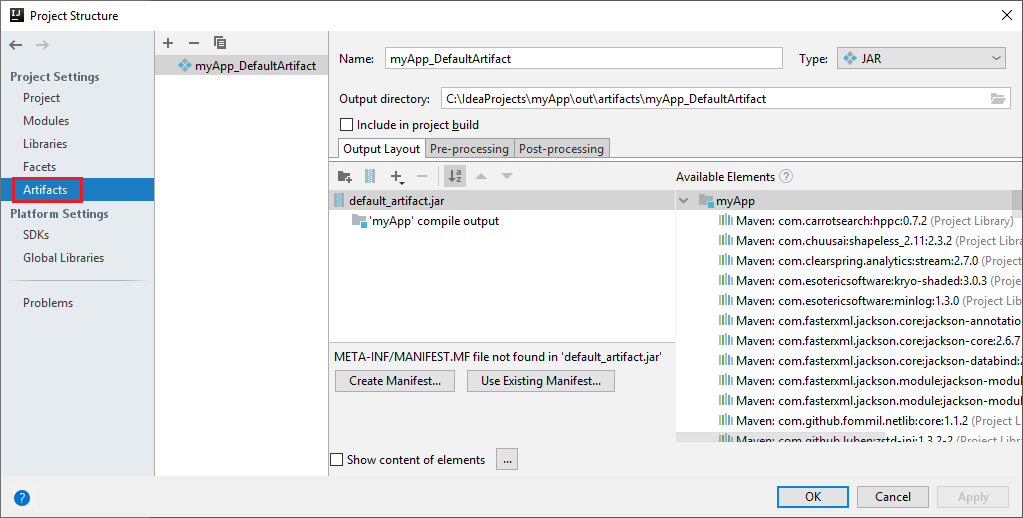
Spark 專案會自動為您建立成品。 若要檢視該成品,請執行下列操作:
a. 從功能表中,瀏覽至 [檔案]>[專案結構...]。
b. 從 [專案結構] 視窗中,選取 [成品]。
c. 檢視成品之後,請選取 [取消]。
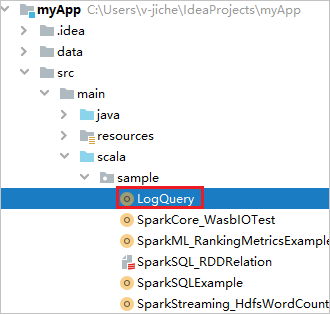
從 myApp>src>main>scala>sample>LogQuery 尋找 LogQuery。 本教學課程使用 LogQuery 來執行。
連線到 Spark 集區
登入 Azure 訂用帳戶以連線到 Spark 集區。
登入您的 Azure 訂用帳戶
從功能表列中,瀏覽至 [檢視]>[工具視窗]>[Azure Explorer]。
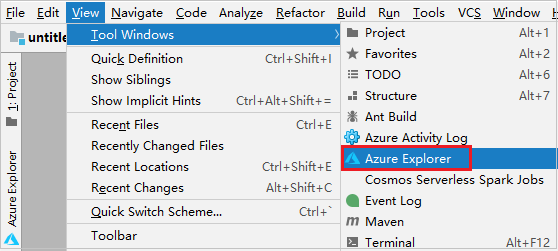
在 Azure Explorer 中,以滑鼠右鍵按一下 [Azure] 節點,然後選取 [登入]。
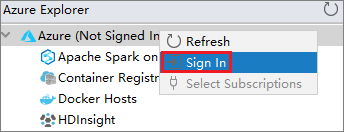
在 [Azure 登入] 對話方塊中選擇 [裝置登入],然後選取 [登入]。
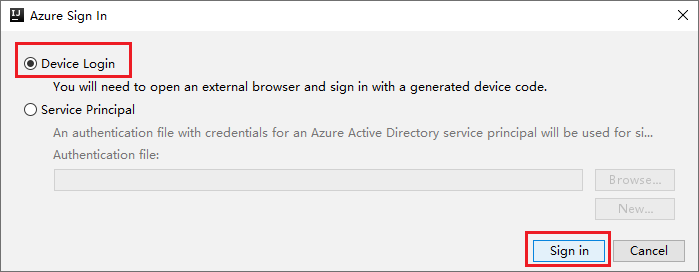
在 [Azure 裝置登入] 對話方塊中,選取 [複製並開啟]。
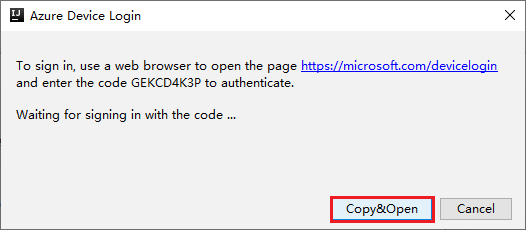
在瀏覽器介面中貼上程式碼,然後選取 [下一步]。
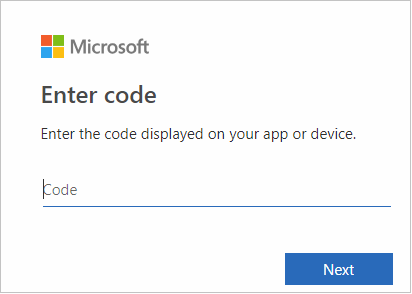
輸入您的 Azure 認證,然後關閉瀏覽器。
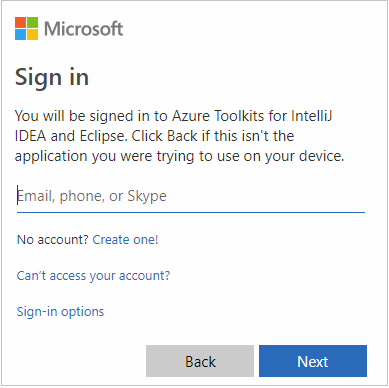
登入之後,[選取訂用帳戶] 對話方塊會列出與認證建立關聯的所有 Azure 訂用帳戶。 選取您的訂用帳戶,然後選取 [選取]。
![[選取訂用帳戶] 對話方塊](media/intellij-tool-synapse/select-subscriptions.png)
從 Azure Explorer 中展開 [Synapse 上的 Apache Spark],以檢視訂用帳戶中的工作區。
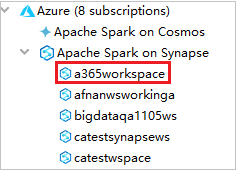
若要檢視 Spark 集區,您可以進一步展開工作區。
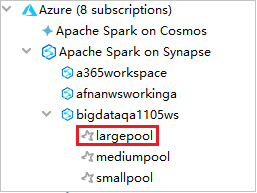
在 Spark 集區上遠端執行 Spark Scala 應用程式
在建立 Scala 應用程式之後,便可以從遠端加以執行。
選取圖示以開啟 [執行/偵錯設定] 視窗。
![[將 Spark 應用程式提交給 HDInsight] 命令 1](media/intellij-tool-synapse/open-configuration-window.png)
在 [執行/偵錯設定] 對話方塊視窗中,選取 [+],然後選取 [Synapse 上的 Apache Spark]。
![[將 Spark 應用程式提交給 HDInsight] 命令 2](media/intellij-tool-synapse/create-synapse-configuration02.png)
在 [執行/偵錯設定] 視窗中提供下列值,然後選取 [確定]:
屬性 值 Spark 集區 選取您要在其上執行應用程式的 Spark 集區。 選取要提交的成品 保留預設值。 Main class name (主要類別名稱) 預設值是所選取檔案中的主要類別。 您可以選取省略號 ( ... ) 並選擇另一個類別來變更類別。 作業設定 您可以變更預設的金鑰和值。 如需詳細資訊,請參閱 Apache Livy REST API。 命令列引數 如有需要,您可以為主類別輸入以空格隔開的引數。 參考的 Jar 和參考的檔案 如果有任何要參考的 Jar 或檔案,您可以輸入其路徑。 您也可以在 Azure 虛擬檔案系統中瀏覽檔案;此系統目前僅支援 ADLS Gen2 叢集。 如需詳細資訊:Apache Spark 設定 (英文) 和如何將資源上傳至叢集。 作業上傳儲存體 展開以顯示其他選項。 儲存區類型 從下拉式清單中選取 [使用 Azure Blob 上傳] 或 [使用叢集預設儲存體帳戶上傳]。 儲存體帳戶 輸入儲存體帳戶。 儲存體金鑰 輸入儲存體金鑰。 儲存體容器 輸入儲存體帳戶和儲存體金鑰後,從下拉式清單中選取您的儲存體容器。 ![[提交 Spark] 對話方塊 1](media/intellij-tool-synapse/create-synapse-configuration03.png)
選取 [SparkJobRun] 圖示將您的專案提交至選取的 Spark 集區。 [Remote Spark Job in Cluster] \(叢集中的遠端 Spark 作業\) 索引標籤在底部顯示作業執行進度。 您可以選取紅色按鈕來停止應用程式。

![[提交 Spark] 對話方塊 2](media/intellij-tool-synapse/remotely-run-result.png)
本機執行/偵錯 Apache Spark 應用程式
您可以遵循下列指示來為 Apache Spark 作業設定本機執行和本機偵錯。
案例 1:進行本機執行
開啟 [執行/偵錯設定] 對話方塊,選取加號 (+)。 然後選取 [Synapse 上的 Apache Spark] 選項。 輸入要儲存的 [名稱]、[主要類別名稱] 資訊。
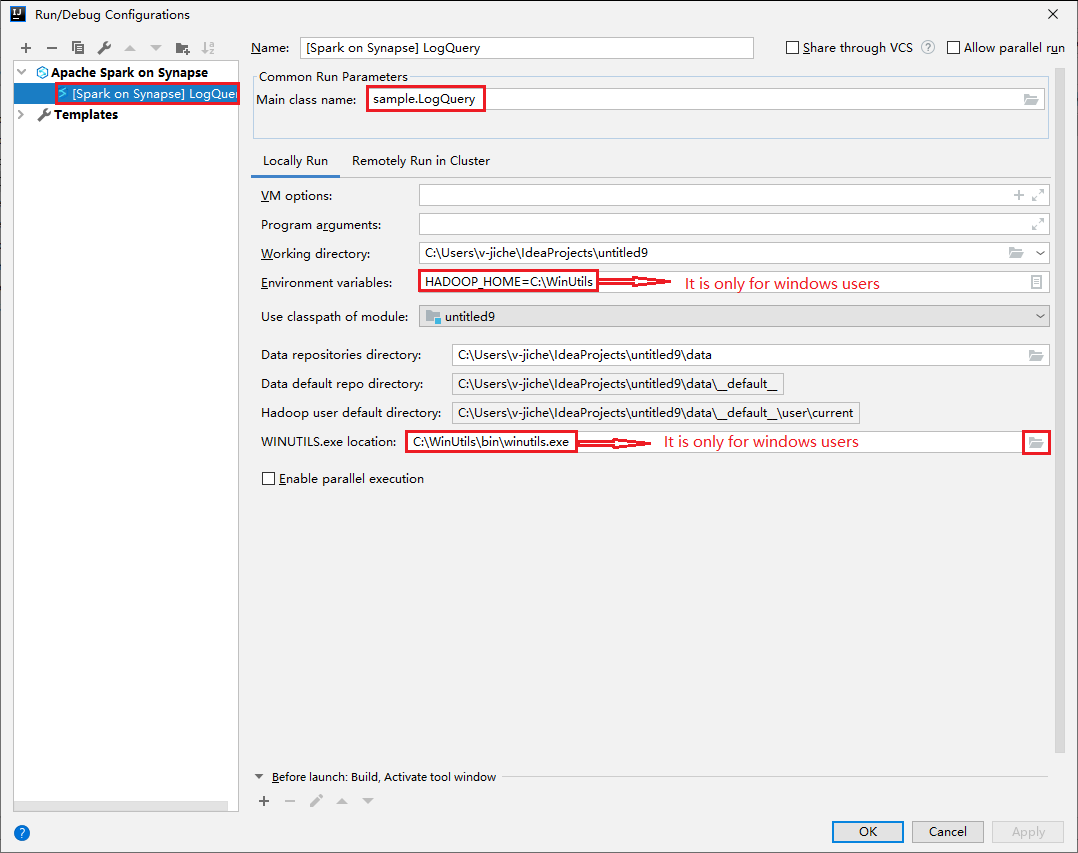
- 環境變數和 WinUtils.exe 位置僅適用於 Windows 使用者。
- 環境變數:如果您之前有設定系統環境變數,系統會自動偵測到,無須手動新增。
- WinUtils.exe 位置:您可以選取右邊的資料夾圖示來指定 WinUtils 位置。
然後選取 [本機播放] 按鈕。

本機執行完成後,如果指令碼包含輸出,則可以從 data>default 檢查輸出檔案。
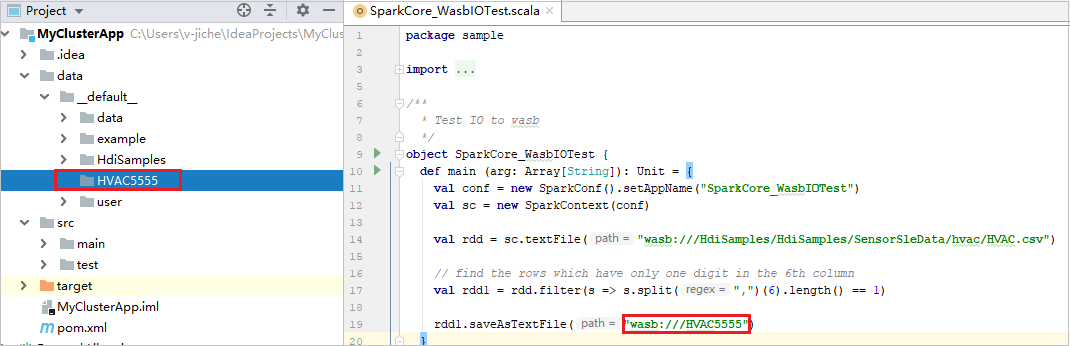
案例 2:進行本機偵錯
開啟 LogQuery 指令碼,設定中斷點。
選取 [本機偵錯] 圖示以進行本機偵錯。

存取和管理 Synapse 工作區
您可以在 Azure Toolkit for IntelliJ 內的 Azure Explorer 中執行不同作業。 從功能表列中,瀏覽至 [檢視]>[工具視窗]>[Azure Explorer]。
啟動工作區
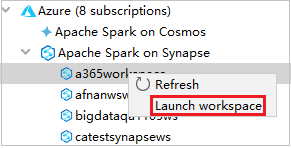
從 Azure Explorer 瀏覽至 [Synapse 上的 Apache Spark],然後將其展開。
以滑鼠右鍵按一下工作區,然後選取 [啟動工作區],網站便會開啟。
Spark 主控台
您可以執行 Spark 本機主控台 (Scala) 或執行 Spark Livy 互動式工作階段主控台 (Scala)。
Spark 本機主控台 (Scala)
請確定您已滿足 WINUTILS.EXE 的先決條件。
從功能表列,瀏覽至 [Run] \(執行\)>[Edit Configurations] \(編輯設定\)。
從 [執行/偵錯設定] 視窗的左側窗格瀏覽至 [Synapse 上的 Apache Spark]>[[Synapse 上的 Spark] myApp]。
在主視窗中,選取 [Locally Run] \(在本機執行\) 索引標籤。
提供下列值,然後選取 [OK] \(確定\):
屬性 值 環境變數 請確定 HADOOP_HOME 的值是正確的。 WINUTILS.exe 位置 請確定路徑是正確的。 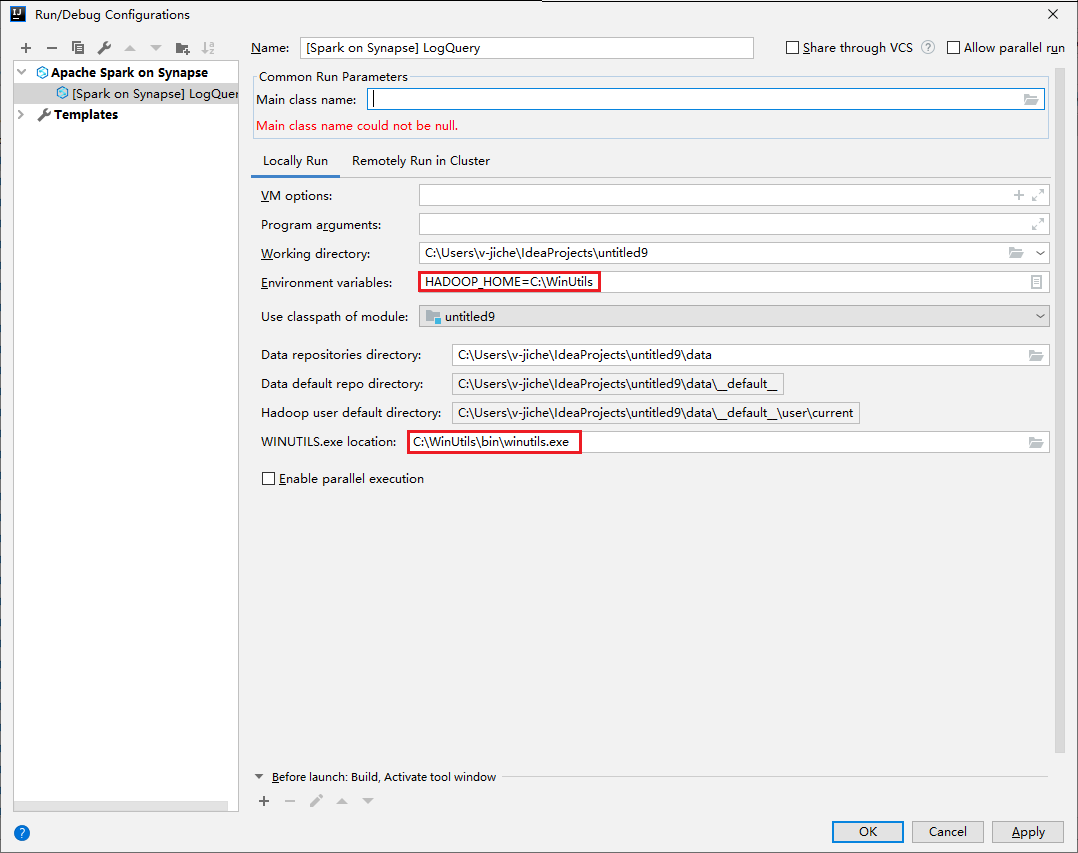
在 [Project] \(專案\) 中,瀏覽至 [myApp] >[src] >[main] >[scala] >[myApp] 。
在功能表列中,瀏覽至 [工具]>[Spark 主控台]>[執行 Spark 本機主控台 (Scala)]。
然後可能會出現兩個對話方塊,詢問您是否要自動修正相依性。 如果需要,請選取 [Auto Fix] \(自動修正\)。
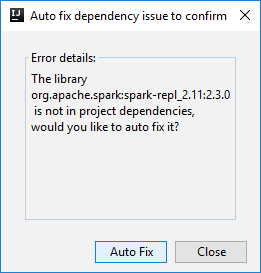
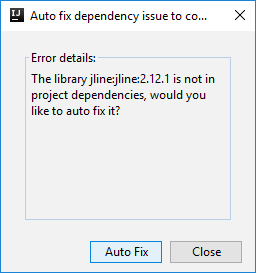
主控台看起來應該類似下面的圖片。 在主控台視窗中,輸入
sc.appName,然後按 Ctrl+Enter。 系統將會顯示結果。 您可以選取紅色按鈕來停止本機主控台。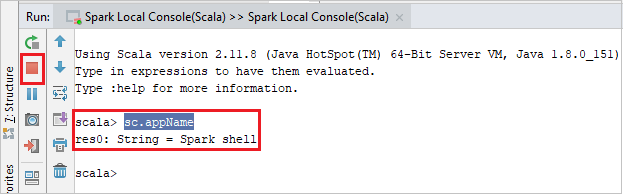
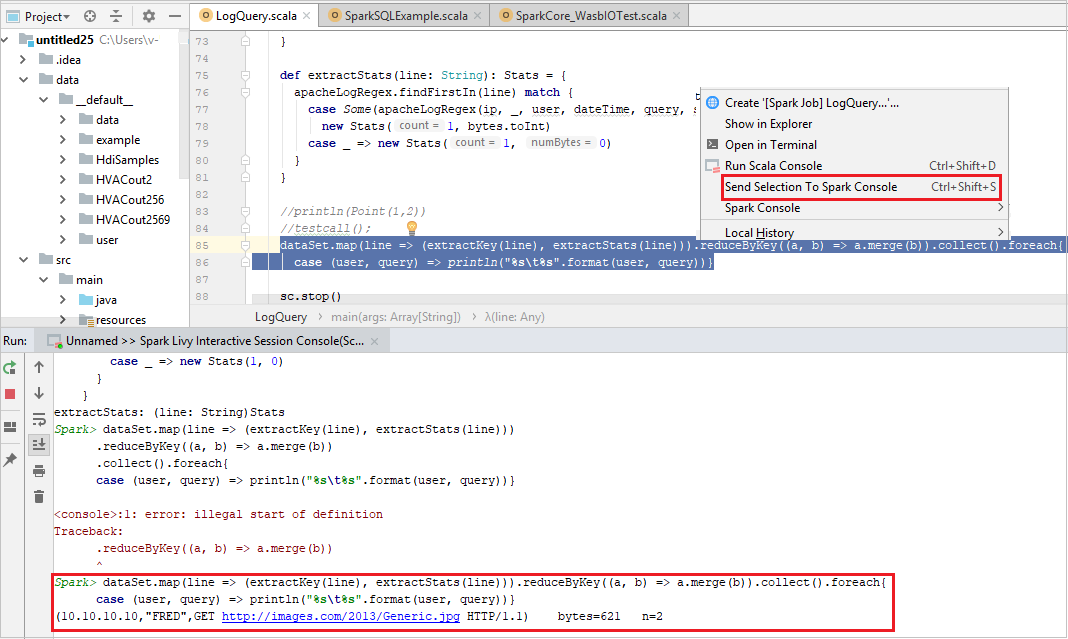
Spark Livy 互動式工作階段主控台 (Scala)
僅在 IntelliJ 2018.2 和 2018.3 上提供支援。
從功能表列,瀏覽至 [Run] \(執行\)>[Edit Configurations] \(編輯設定\)。
從 [執行/偵錯設定] 視窗的左側窗格瀏覽至 [Synapse 上的 Apache Spark]>[[Synapse 上的 Spark] myApp]。
在主視窗中,選取 [Remotely Run in Cluster] \(在叢集中遠端執行\) 索引標籤。
提供下列值,然後選取 [OK] \(確定\):
屬性 值 Main class name (主要類別名稱) 選取主要類別名稱。 Spark 集區 選取您要在其上執行應用程式的 Spark 集區。 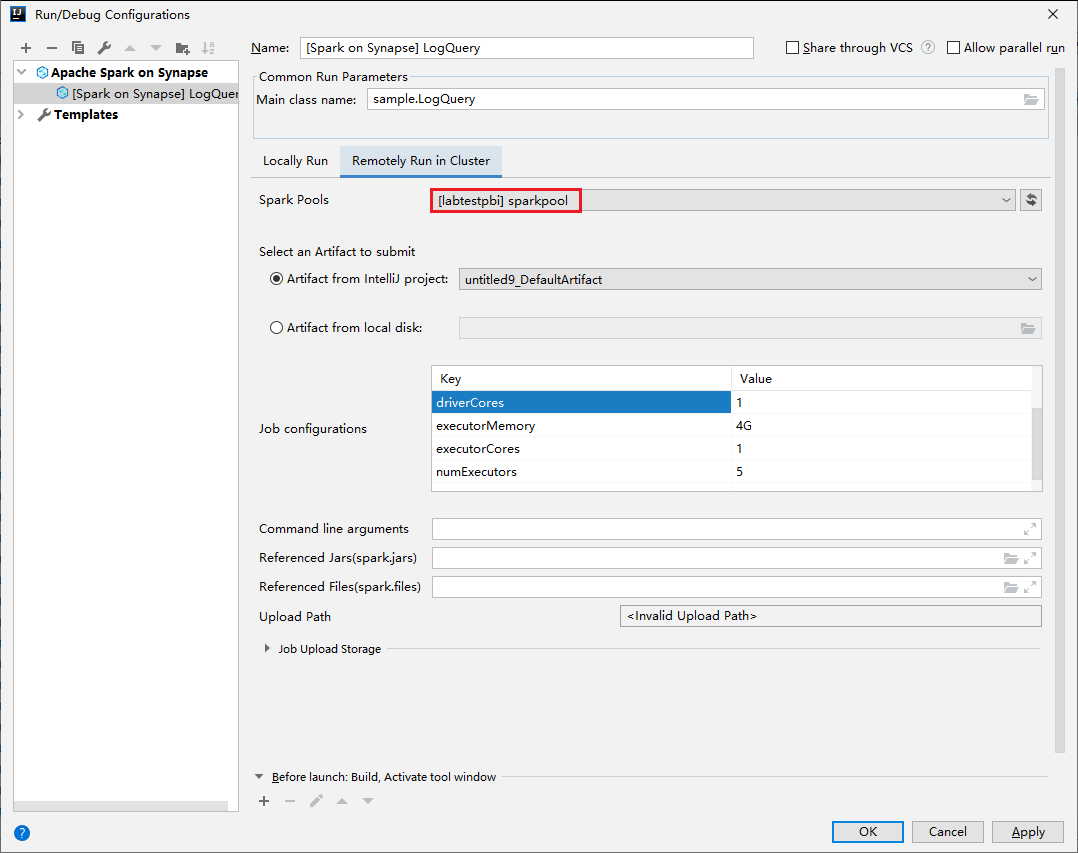
在 [Project] \(專案\) 中,瀏覽至 [myApp] >[src] >[main] >[scala] >[myApp] 。
在功能表列中,瀏覽至 [工具]>[Spark 主控台]>[執行 Spark Livy 互動式工作階段主控台 (Scala)]。
主控台看起來應該類似下面的圖片。 在主控台視窗中,輸入
sc.appName,然後按 Ctrl+Enter。 系統將會顯示結果。 您可以選取紅色按鈕來停止本機主控台。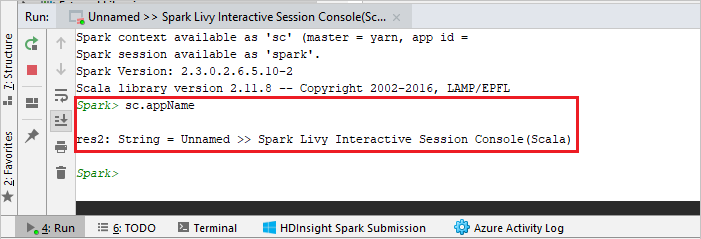
傳送所選項目至 Spark 主控台
您可能想要將一些程式碼傳送至本機主控台或 Livy 互動式工作階段主控台 (Scala) 來查看指令碼結果。 若要這樣做,您可以將 Scala 檔案中的某些程式碼反白顯示,然後以滑鼠右鍵按一下 [傳送所選項目至 Spark 主控台]。 所選的程式碼將會傳送至主控台並執行。 結果會在主控台中顯示於程式碼之後。 主控台會檢查現有錯誤。