Teradata 移轉的設計和效能
本文是七部分系列的第一部分,提供如何從 Teradata 遷移至 Azure Synapse Analytics 的指引。 本文著重於設計和效能的最佳做法。
概觀
許多 Teradata 數據倉儲系統的現有使用者都想要利用新式雲端環境所提供的創新功能。 基礎結構即服務 (IaaS) 和平台即服務 (PaaS) 雲端環境可讓您將基礎結構維護和平台開發等工作委派給雲端提供者。
提示
不只是資料庫,Azure 環境還包含一組完整的功能和工具。
雖然 Teradata 和 Azure Synapse Analytics 都是使用大量平行處理 (MPP) 技術的 SQL 資料庫,在超大型數據量上達到高查詢效能,但方法有一些基本差異:
舊版 Teradata 系統通常會安裝在內部部署並使用專屬硬體,而 Azure Synapse 是雲端式系統,並使用 Azure 儲存體 和計算資源。
由於儲存體和計算資源在 Azure 環境中是分開的,而且具有彈性的調整功能,因此這些資源可以獨立擴大或縮小。
您可以根據需要暫停 Azure Synapse Analytics 或調整其大小,以降低資源使用率和成本。
升級 Teradata 設定是涉及額外實體硬體以及可能冗長的資料庫重新設定或重載的主要工作。
Microsoft Azure 是全球可用、高度安全且可調整的雲端環境,包含 Azure Synapse 以及支援工具和功能的生態系統。 下圖摘要說明 Azure Synapse 生態系統。
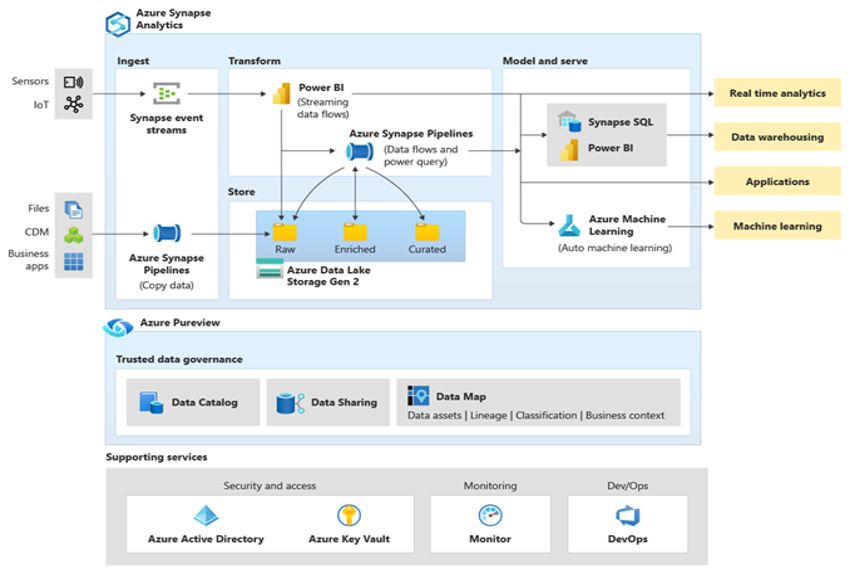
Azure Synapse 使用 MPP 和多個層級的自動化快取等技術,為常用數據提供最佳品種的關係資料庫效能。 您可以在獨立的基準測試中看到這些技術的結果,例如 GigaOm 最近一次執行的基準測試,其將 Azure Synapse Analytics 與其他熱門的雲端資料倉儲供應項目進行比較。 移轉至 Azure Synapse Analytics 環境的客戶會看到許多優點,包括:
改善的效能與性價比。
增加靈活度和較短的價值時間。
較快的伺服器部署和應用程式開發。
彈性可擴縮性—僅需支付實際使用量的費用。
改善的安全性/合規性。
降低儲存和災害復原的成本。
降低整體 TCO、更好的成本控制,以及簡化的營運支出 (OPEX)。
若要充散發揮這些優點,請將新的和現有的資料與應用程式遷移至 Azure Synapse Analytics 平台中。 在許多組織中,移轉包括將現有的數據倉儲從舊版內部部署平臺,例如 Teradata 移至 Azure Synapse。 概括而言,移轉程序包含下列步驟:
準備 🡆
定義範圍:要移轉的內容。
建置要移轉的資料和程序詳細目錄。
定義資料模型變更 (若有的話)。
定義來源資料擷取機制。
識別要使用的適當 Azure 和第三方工具與功能。
盡早在新平台上培訓員工。
設定 Azure 目標平台。
移轉 🡆
從小規模且簡單的內容著手。
盡可能自動化。
使用 Azure 內建工具和功能來減少移轉工作。
遷移資料表和檢視的中繼資料。
移轉要維護的歷史資料。
遷移或重構預存程序和業務流程。
遷移或重構 ETL/ELT 增量負載流程。
移轉後
監視並記錄程序的所有階段。
使用獲得的經驗為將來的移轉建置範本。
視需要重新設計資料模型 (使用新的平台效能和可擴縮性)。
測試應用程式和查詢工具。
基準和最佳化查詢效能。
本文提供將數據倉儲從現有 Netezza 環境移轉至 Azure Synapse 時的效能優化一般資訊和指導方針。 效能優化的目標是在架構移轉之後,在 Azure Synapse 中達到相同或更好的數據倉儲效能。
設計考量
移轉範圍
當您準備從 Teradata 環境移轉時,請考慮下列移轉選擇。
選擇初次移轉的工作負載
一般而言,舊版 Teradata 環境經過一段時間的演進,以包含多個主題領域和混合工作負載。 當您決定要從何處開始移轉專案時,請選擇能夠達到下列條件的區域:
透過快速提供新環境的優勢,證明遷移至 Azure Synapse 的可行性。
可讓內部技術人員透過遷移其他區域時所使用的程序和工具,獲得相關體驗。
建立範本,以進一步移轉來源 Teradata 環境,以及已就緒的目前工具和程式。
從 Teradata 進行初始移轉的好候選專案,環境支援 上述專案,以及:
實作 BI/分析工作負載,而不是線上交易處理 (OLTP) 工作負載。
具有資料模型,例如可以透過最少修改進行移轉的星型或雪花式結構描述。
提示
建立需要移轉的物件詳細目錄,並記錄移轉程序。
初始移轉中移轉的資料量應該夠大,才能示範 Azure Synapse Analytics 環境的功能和優點,但也不能太大而無法快速展現價值。 1-10 TB 範圍內的大小是典型大小。
針對您的初始移轉專案,將風險、精力和移轉時間降至最低,以便快速查看 Azure 雲端環境的優點,將移轉的範圍限制為只有數據超市,例如 Teradata 倉儲的 OLAP DB 部分。 隨即轉移和分階段移轉方法會將初始移轉的範圍限製為僅數據超市,且不會解決更廣泛的移轉層面,例如 ETL 移轉和歷程記錄數據遷移。 不過,一旦移轉的資料超市層回填資料和必要的建置程序之後,您就可以在專案的稍後階段中處理那些層面。
隨即轉移移轉與階段式方法
一般而言,不論計劃的移轉目的和範圍為何,移轉都有兩種類型:隨即轉移及包含變更的階段式方法。
隨即轉移
在隨即轉移中,現有的資料模型 (例如星型結構描述) 會依原樣移轉至新的 Azure Synapse Analytics 平台。 此方法只需少量工作就能實現移至 Azure 雲端環境的優點,進而將風險和移轉時間降到最低。 隨即轉移移轉適合下列案例:
- 您有現有的 Teradata 環境,具有要移轉的單一數據超市,或
- 您有現有的 Teradata 環境,且數據已經位於設計完善的星形或雪花式架構中,或
- 您有移至新式雲端環境的時間和成本壓力。
提示
隨即轉移是不錯的起點,即使後續階段會實作資料模型的變更也一樣。
納入變更的階段式方法
如果舊版資料倉儲已發展很長一段時間,您可能需要重新設計以維持所需的效能等級。 您可能也必須重新設計來支援新的資料,例如物聯網 (IoT) 資料流。 在重新設計的程序中,遷移至 Azure Synapse 可受益於可調整的雲端環境。 移轉也可以包含基礎數據模型中的變更,例如從 Inmon 模型移至數據保存庫。
Microsoft建議將現有的數據模型依現狀移至 Azure(選擇性地在 Azure 中使用 VM Teradata 實例),以及使用 Azure 環境的效能和彈性來套用重新工程變更。 如此一來,您就可以使用 Azure 的功能進行變更,而不會影響現有的來源系統。
使用 Azure VM Teradata 實例作為移轉的一部分
從內部部署 Teradata 環境移轉時,您可以利用 Azure 中的雲端記憶體和彈性延展性,在 VM 內建立 Teradata 實例。 此方法會將 Teradata 實例與目標 Azure Synapse 環境共置。 您可以使用標準 Teradata 公用程式,例如 Teradata Parallel Data Transporter,有效率地移動要移轉至 VM 實例的 Teradata 數據表子集。 然後,所有進一步的移轉工作都可以在 Azure 環境中進行。 這種方法有幾項優點:
在初始復寫數據之後,來源系統不會受到移轉工作的影響。
熟悉的 Teradata 介面、工具和公用程式可在 Azure 環境中使用。
Azure 環境避開內部部署來源系統與雲端目標系統之間網路頻寬可用性的任何潛在問題。
Azure Data Factory 之類的工具可以呼叫 Teradata Parallel Transporter 等公用程式,以有效率且快速地移轉數據。
您可以在 Azure 環境中完全協調及控制移轉程式。
提示
使用 Azure VM 建立暫時的 Teradata 實例,以加速移轉,並將對來源系統的影響降到最低。
使用 Azure Data Factory 實作元數據驅動移轉
您可以透過使用 Azure 環境的功能來自動化和協調移轉程序。 這種方法可將現有 Netezza 環境的效能降低到最低,這可能已經接近容量。
Azure Data Factory 是一項雲端式資料整合服務,可支援在雲端建立資料驅動工作流程,以便協調及自動進行資料移動和資料轉換。 您可以使用 Data Factory 建立並排定資料驅動的工作流程 (管線),以從不同的資料存放區內嵌資料。 透過使用計算服務 (例如,Azure HDInsight Hadoop、Spark、Azure Data Lake Analytics 和 Azure Machine Learning),Data Factory 可以處理或轉換資料。
當您打算使用 Data Factory 設施來管理移轉程式時,請建立元數據,列出要移轉的所有數據表及其位置。
Teradata 與 Azure Synapse 之間的設計差異
如先前所述,Teradata 與 Azure Synapse Analytics 資料庫之間方法有一些基本差異,接下來會討論這些差異。
多個資料庫與單一資料庫和架構
Teradata 環境通常包含多個不同的資料庫。 例如,可能有個別的資料庫:數據擷取和臨時表、核心倉儲數據表和數據超市(有時稱為語意層)。 ETL 或 ELT 管線程式可能會實作跨資料庫聯結,並在不同的資料庫之間行動數據。
相反地,Azure Synapse 環境包含單一資料庫,並使用結構描述將資料表分成邏輯上的個別群組。 建議您使用目標 Azure Synapse 資料庫中的一系列架構來模擬從 Teradata 環境移轉的個別資料庫。 如果 Teradata 環境已經使用架構,當您將現有的 Teradata 數據表和檢視移至新環境時,您可能需要使用新的命名慣例。 例如,您可以將現有的 Teradata 架構和數據表名稱串連至新的 Azure Synapse 數據表名稱,並使用新環境中的架構名稱來維護原始不同的資料庫名稱。 如果架構合併命名有點,Azure Synapse Spark 可能會有問題。 雖然您可以使用基礎資料表上的 SQL 檢視來維護邏輯結構,但該方法有一些潛在的缺點:
Azure Synapse Analytics 中的檢視僅供唯讀,因此必須在基礎基底資料表上更新任何資料。
已經存在一或多個檢視層,而且新增額外的檢視層可能會影響效能和支援性,因為巢狀檢視難以進行疑難解答。
提示
將多個資料庫結合成 Azure Synapse Analytics 中的單一資料庫,並使用結構描述名稱以邏輯方式分隔資料表。
資料表考量
當您在不同環境之間移轉資料表時,通常只有原始資料和描述其實際移轉的中繼資料。 來源系統的其他資料庫元素 (例如索引) 通常不會移轉,因為它們在新的環境中可能不必要,或會以不同的方式實作。 來源環境中的效能最佳化 (例如索引) 會指出您可以在新環境中新增效能最佳化的位置。 例如,如果來源 Teradata 環境中的數據表具有非唯一的次要索引 (NUSI),則建議在 Azure Synapse 內建立非叢集索引。 其他原生效能最佳化技術 (如資料表複寫),可能比直接建立「類似」索引更為適用。
提示
現有的索引會指出已移轉倉儲中用於編製索引的候選項目。
資料庫的高可用性
Teradata 支援透過 FALLBACK 選項跨節點的數據複寫,該選項會將實際位於指定節點上的數據表數據列復寫到系統中的另一個節點。 此方法可確保如果節點失敗,且提供故障轉移案例的基礎,數據將不會遺失。
Azure Synapse Analytics 中高可用性架構的目標是保證資料庫已啟動並執行 99.9%,而不必擔心維護作業和中斷的影響。 如需 SLA 的詳細資訊,請參閱 Azure Synapse Analytics 的 SLA。 Azure 會自動處理重要的服務工作,例如修補、備份和 Windows 和 SQL 升級。 Azure 也會自動處理非計劃性事件,例如基礎硬體、軟體或網路中的失敗。
Azure Synapse 中的數據記憶體會自動 備份 快照集。 這些快照集是建立還原點之服務的內建功能。 您無須啟用此功能。 使用者目前無法刪除服務用來維護服務等級協定 (SLA) 進行復原的自動還原點。
Azure Synapse Dedicated SQL 集區會全天擷取數據倉儲的快照集,以建立 7 天可用的還原點。 無法變更此保留期間。 Azure Synapse 支援八小時的復原點目標 (RPO)。 您可以從過去七天內拍攝的任一快照,還原主要區域中的資料倉儲。 如果您需要更細微的備份,您可以使用另一個使用者定義的選項。
不支援的 Teradata 資料表類型
Teradata 支援時間序列和時態數據的特殊數據表類型。 Azure Synapse 中不支援這些數據表類型的語法和部分函式。 不過,您可以將數據遷移至 Azure Synapse 中的標準數據表,方法是對應至適當的數據類型,以及編製索引或分割日期/時間數據行。
提示
Azure Synapse 中的標準數據表可以支援已移轉的 Teradata 時間序列和時態數據。
Teradata 會實作時態查詢功能,方法是使用查詢重寫在時態查詢中新增其他篩選,以限制適用的日期範圍。 如果您打算從來源 Teradata 環境移轉這項功能,請將其他篩選新增至相關的時態查詢。
Azure 環境支援 時間序列深入解析,以大規模分析時間序列數據。 這項功能的目標是IoT資料分析應用程式。
SQL DML 語法差異
Teradata SQL 與 Azure Synapse T-SQL 之間存在 SQL 數據操作語言 (DML) 語法差異 :
QUALIFY:Teradata 支援QUALIFY運算符。 例如:SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;對等的 Azure Synapse 語法為:
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;日期算術:Azure Synapse 具有 運算符,例如
DATEADD和DATEDIFF,可用於DATE或DATETIME字段。 Teradata 支援日期的直接減法,例如SELECT DATE1 - DATE2 FROM...GROUP BY:針對GROUP BY序數,明確提供 T-SQL 資料行名稱。LIKE ANY:Teradata 支援LIKE ANY語法,例如:SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');Azure Synapse 語法中的對等專案為:
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');根據系統設定,Teradata 中的字元比較預設可能會不區分大小寫。 在 Azure Synapse 中,字元比較一律會區分大小寫。
函式、預存程式、觸發程式和序列
從 Teradata 等成熟環境移轉數據倉儲時,您可能需要移轉簡單數據表和檢視以外的元素。 範例包括函式、預存程式、觸發程式和序列。 檢查 Azure 環境中的工具是否可以取代函式、預存程式和序列的功能,因為使用內建 Azure 工具通常比重新編碼 Azure Synapse 的元素更有效率。
在準備階段中,請建立需要遷移的物件詳細目錄、定義處理這些物件的方法,並在移轉計畫中配置適當的資源。
數據整合合作夥伴 提供工具和服務,可將函式、預存程式和序列的移轉自動化。
下列各節會進一步討論函式、預存程序和序列的移轉。
函式
如同大部分的資料庫產品,Teradata 支援 SQL 實作內的系統和使用者定義函式。 當您將舊版資料庫平台遷移至 Azure Synapse 時,通常不需要變更即可遷移一般系統函式。 某些系統函式的語法可能稍有不同,但仍可以將必要的變更自動化。
針對在 Azure Synapse 中沒有對等的 Teradata 系統函式或任意使用者定義函式,請使用目標環境語言重新編碼這些函式。 Azure Synapse 會使用 Transact-SQL 語言來實作使用者定義函式。
預存程序
大部分的新式資料庫產品,都支援在資料庫中儲存程序。 Teradata 會為此目的提供SPL語言。 預存程序通常包含 SQL 陳述式和程序邏輯,並且會傳回資料或狀態。
Azure Synapse 支援使用 T-SQL 的預存程式,因此您必須以該語言重新編碼任何已移轉的預存程式。
觸發程序
Azure Synapse 不支援觸發程式建立,但可以使用 Azure Data Factory 來實作觸發程式建立。
序列
Azure Synapse 會以類似 Teradata 的方式來處理序列,而且您可以使用 IDENTITY 資料行或 SQL 程式代碼來實作序列,以產生數列中下一個序號。 序列提供唯一的數值,您可以做為主鍵的 Surrogate 索引鍵值。
從 Teradata 環境擷取元數據和數據
數據定義語言 (DDL) 產生
ANSI SQL 標準會定義資料定義語言 (DDL) 命令的基本語法。 Teradata CREATE TABLE 和 CREATE VIEWAzure Synapse 等一些 DDL 命令很常見,但也提供實作特定的功能,例如索引編製、數據表散發和分割選項。
您可以編輯現有的 Teradata CREATE TABLE 和 CREATE VIEW 腳本,以在 Azure Synapse 中達成對等的定義。 若要這樣做,您可能需要使用 修改過的數據類型 ,並移除或修改 Teradata 特定子句,例如 FALLBACK。
不過,指定現有 Teradata 環境內數據表和檢視目前定義的所有資訊都會保留在系統目錄數據表內。 這些數據表是這項資訊的最佳來源,因為它保證是最新且完整的。 使用者維護的檔案可能無法與目前的數據表定義同步。
在 Teradata 環境中,系統目錄資料表會指定目前的數據表和檢視定義。 與使用者維護的文件不同,系統類別目錄資訊一律是完整的,且與目前的資料表定義同步。 藉由使用 之類的 DBC.ColumnsV目錄檢視,您可以存取系統目錄資訊,以產生 CREATE TABLE 在 Azure Synapse 中建立對等數據表的 DDL 語句。
提示
使用現有的 Teradata 元數據,將 Azure Synapse 的 CREATE TABLE 和 CREATE VIEW DDL 產生自動化。
您也可以使用第三方的移轉和 ETL 工具來處理系統目錄資訊,以達到類似的結果。
從 Teradata 擷取數據
您可以使用基本 Teradata 查詢(BTEQ)、Teradata FastExport 或 Teradata Parallel Transporter (TPT) 等標準 Teradata 公用程式,將原始數據表數據從 Teradata 數據表擷取到一般分隔的檔案,例如 CSV 檔案。 使用 TPT 盡可能有效率地擷取數據表數據。 TPT 使用多個平行 FastExport 數據流來達到最高的輸送量。
提示
使用 Teradata Parallel Transporter 來擷取最有效率的數據。
直接從 Azure Data Factory 呼叫 TPT。 這是在 Azure 環境中 VM 內執行之 Teradata 內部部署實例和 Teradata 實例的數據遷移建議方法。
擷取的資料檔案應該包含 CSV、最佳化資料列單欄式 (ORC) 或 Parquet 格式的分隔文字。
如需從 Teradata 環境移轉數據和 ETL 的詳細資訊,請參閱 Teradata 移轉的數據遷移、ETL 和載入。
Teradata 移轉的效能建議
效能最佳化的目標是在遷移至 Azure Synapse 之後獲得相同或更好的資料倉儲效能。
提示
在移轉開始時,優先熟悉 Azure Synapse 中的微調選項。
效能微調方法的差異
本節強調 Teradata 與 Azure Synapse 之間的低階效能微調實作差異。
資料散發選項
為了提高效能,Azure Synapse 設計為使用多節點架構,並使用平行處理。 若要在 Azure Synapse 中優化個別數據表效能,您可以使用 語句在 語句DISTRIBUTION中CREATE TABLE定義數據散發選項。 例如,您可以指定雜湊分散式資料表,其會使用決定性雜湊函式,將資料表的資料列分散到計算節點上。 目標是在執行查詢時減少在處理節點之間移動的數據量。
對於大型數據表到大型數據表聯結,哈希散發一個或理想情況下,其中一個聯結數據行上的這兩個數據表都有廣泛的值,以協助確保平均分佈。 在本機執行聯結處理,因為將聯結的數據列會共置在相同的處理節點上。
Azure Synapse 也透過小型數據表複寫,支援小型數據表與大型數據表之間的本機聯結。 例如,星狀架構模型中的小型維度資料表和大型事實資料表。 Azure Synapse Analytics 可以跨所有節點複寫較小的維度資料表,以確保大型資料表的任何聯結索引鍵值都有相符的本機可用維度資料列。 小型維度資料表的維度資料表複寫額外負荷相對較低。 對於大型維度資料表,雜湊散發方法更合適。 如需資料散發選項的詳細資訊,請參閱使用複寫資料表的設計指引和設計分散式資料表的指引。
資料的索引編製
Azure Synapse 支援數個用戶可定義的索引選項,這些選項與 Teradata 中實作的索引選項不同。 如需有關 Azure Synapse 中不同索引編製選項的詳細資訊,請參閱專用 SQL 集區資料表上的索引。
來源 Teradata 環境中現有的索引提供有用的數據使用量指示,以及 Azure Synapse 環境中索引的候選數據行。
資料分割
在企業資料倉儲中,事實資料表可能包含數十億個資料列。 數據分割可將這些數據表分割成個別部分,以減少處理的數據量,藉此優化這些數據表的維護和查詢效能。 在 Azure Synapse 中,CREATE TABLE 陳述式會定義資料表的分割規格。 只有分割非常大的數據表,並確保每個分割區至少包含6000萬個數據列。
每個資料表只能使用一個欄位進行資料分割。 該欄位通常是日期欄位,因為許多查詢會依日期或日期範圍進行篩選。 您可以在初始載入之後變更資料表的分割,只要使用 CREATE TABLE AS (CTAS) 陳述式以新的散發來重新建立資料表即可。 如需 Azure Synapse 中資料分割的詳細說明,請參閱專用 SQL 集區中的資料分割資料表。
數據表統計數據
您應該藉由在 ETL/ELT 作業的統計數據步驟中 建置,以確保數據表上的統計數據 是最新的。
用於載入資料的 PolyBase 或 COPY INTO
PolyBase 支援使用平行載入資料流,有效率地將大量資料載入至資料倉儲。 如需詳細資訊,請參閱 PolyBase 資料載入策略。
COPY INTO 也支援高輸送量的資料擷取,以及:
從資料夾和子資料夾內的所有檔案中擷取資料。
從相同儲存體帳戶中的多個位置中擷取資料。 您可以使用逗號分隔路徑來指定多個位置。
Azure Data Lake Storage (ADLS) 和 Azure Blob 儲存體。
CSV、PARQUET 和 ORC 檔案格式。
工作負載管理
執行混合工作負載可能會造成忙碌系統上的資源挑戰。 成功的工作負載管理配置可有效地管理資源、確保高效率的資源使用率,以及最大化的投資報酬率 (ROI)。 工作負載分類、工作負載重要性和工作負載隔離可更充分地控制工作負載如何利用系統資源。
工作負載管理指南會說明分析工作負載、管理和監視工作負載重要性的技術,以及將資源類別轉換為工作負載群組的步驟。 使用 Azure 入口網站和 DMV 上的 T-SQL 查詢來監視工作負載,以確保有效率地利用適用資源。
下一步
若要瞭解 Teradata 移轉的 ETL 和負載,請參閱此系列中的下一篇文章: 數據遷移、ETL 和 Teradata 移轉的載入。