在 Synapse SQL 集區中使用複寫數據表的設計指導方針
本文提供在 Synapse SQL 集區架構中設計復寫數據表的建議。 使用這些建議可藉由減少數據移動和查詢複雜度來改善查詢效能。
必要條件
本文假設您已熟悉 SQL 集區中的數據散發和數據移動概念。 如需詳細資訊,請參閱 架構 一文。
在數據表設計中,盡可能瞭解您的數據,以及查詢數據的方式。 例如,請考慮下列問題:
- 數據表有多大?
- 數據表重新整理的頻率?
- 我是否在 SQL 集區中有事實和維度數據表?
什麼是復寫數據表?
復寫數據表在每個計算節點上都有可存取的完整數據表複本。 複寫資料表可讓系統不需要在進行聯結或彙總之前,於計算節點之間傳輸資料。 由於數據表有多個複本,因此當數據表大小小於 2 GB 壓縮時,複寫的數據表效果最好。 2 GB 不是硬性限制。 如果數據是靜態的,而且不會變更,您可以復寫較大的數據表。
下圖顯示每個計算節點上可存取的複寫數據表。 在 SQL 集區中,複寫數據表會完整複製到每個計算節點上的散發資料庫。

復寫的數據表適用於星型架構中的維度數據表。 維度數據表通常會聯結至事實數據表,其分佈方式與維度數據表不同。 維度通常是大小,因此可以儲存和維護多個複本。 維度會儲存變更緩慢的描述性數據,例如客戶名稱和位址,以及產品詳細數據。 數據緩時變的性質會導致復寫數據表的維護較少。
請考慮在下列情況下使用複寫資料表:
- 磁碟上的數據表大小小於 2 GB,不論數據列數目為何。 若要尋找資料表的大小,您可以使用 DBCC PDW_SHOWSPACEUSED 命令:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate')。 - 數據表用於聯結中,否則需要數據移動。 聯結未在相同數據行上散發的數據表時,例如哈希散發數據表到迴圈配置資源數據表時,需要數據移動才能完成查詢。 如果其中一個數據表很小,請考慮複寫的數據表。 在大部分情況下,我們建議使用復寫的數據表,而不是迴圈配置資源數據表。 若要檢視查詢計劃中的數據移動作業,請使用 sys.dm_pdw_request_steps。 BroadcastMoveOperation 是可使用複寫數據表來消除的典型數據移動作業。
復寫的數據表在下列情況下可能不會產生最佳查詢效能:
- 資料表具有頻繁的插入、更新與刪除作業。 資料操作語言 (DML) 作業需要重建複寫資料表。 頻繁重建可能會導致較慢的效能。
- SQL 集區會頻繁調整。 調整 SQL 集區會變更計算節點的數目,這會導致重建複寫資料表。
- 資料表具有大量資料行,但資料作業通常僅存取小量資料行。 在此案例中,散發資料表,然後在經常存取的資料行建立索引可能比較有效率,而非複寫整個資料表。 當查詢需要資料移動時,SQL 集區只會針對要求的資料行移動資料。
提示
如需索引編製和復寫數據表的詳細資訊,請參閱 Azure Synapse Analytics 中專用 SQL 集區的速查表(先前稱為 SQL DW)。
使用具有簡單查詢述詞的複寫數據表
選擇散發或復寫數據表之前,請先思考您計劃針對數據表執行的查詢類型。 盡可能
- 針對具有簡單查詢述詞的查詢使用複寫數據表,例如相等或不等。
- 針對具有複雜查詢述詞的查詢使用分散式數據表,例如 LIKE 或 NOT LIKE。
當工作分散到所有計算節點時,CPU 密集查詢的執行效能最佳。 例如,在數據表的每個數據列上執行計算的查詢,對分散式數據表的執行效能比復寫數據表更好。 由於復寫數據表會以完整方式儲存在每個計算節點上,因此針對復寫數據表的CPU密集查詢會針對每個計算節點上的整個資料表執行。 額外的計算可能會降低查詢效能。
例如,此查詢具有複雜的述詞。 當數據位於分散式數據表而非復寫數據表時,其執行速度會更快。 在此範例中,數據可以迴圈配置資源散發。
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
將現有的迴圈配置資源數據表轉換為複寫的數據表
如果您已經有迴圈配置資源數據表,如果它們符合本文所述的準則,建議您將它們轉換成復寫的數據表。 復寫數據表可改善迴圈配置資源數據表的效能,因為它們不需要數據移動。 迴圈配置資源數據表一律需要聯結的數據移動。
此範例會使用 CTAS 將 DimSalesTerritory 數據表變更為複寫數據表。 不論哈希散發還是迴圈配置資源為何,此範例都能運作 DimSalesTerritory 。
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
迴圈配置資源與複寫的查詢效能範例
復寫數據表不需要任何聯結的數據移動,因為整個數據表已存在於每個計算節點上。 如果維度數據表是迴圈配置資源分散式,聯結會將維度數據表完整複製到每個計算節點。 若要移動數據,查詢計劃包含名為 BroadcastMoveOperation 的作業。 這種類型的數據移動作業會減緩查詢效能,並使用複寫的數據表來消除。 若要檢視查詢計劃步驟,請使用 sys.dm_pdw_request_steps 系統目錄檢視。
例如,在下列針對架構的 AdventureWorks 查詢中, FactInternetSales 數據表是哈希散發的。 DimDate和 DimSalesTerritory 數據表是較小的維度數據表。 此查詢會傳回 2004 財年 北美洲 的總銷售額:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
我們重新建立 DimDate 和 DimSalesTerritory 作為迴圈配置資源數據表。 因此,查詢會顯示下列查詢計劃,其中包含多個廣播移動作業:
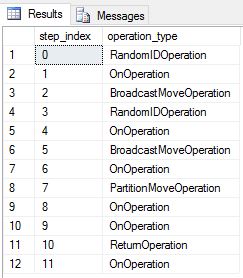
我們重新建立 DimDate 和 DimSalesTerritory 復寫數據表,然後再次執行查詢。 產生的查詢計劃要短得多,而且沒有任何廣播動作。
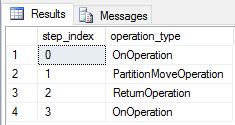
修改復寫數據表的效能考慮
SQL 集區會藉由維護數據表的主要版本來實作復寫的數據表。 它會將主要版本複製到每個計算節點上的第一個散發資料庫。 當有變更時,會先更新主要版本,然後重建每個計算節點上的數據表。 復寫數據表的重建包括將數據表複製到每個計算節點,然後建置索引。 例如,DW2000c 上的復寫數據表有五份數據。 每個計算節點上的主要復本和完整複本。 所有數據都會儲存在散發資料庫中。 SQL 集區使用此模型來支援更快速的數據修改語句和彈性調整作業。
異步重建是由第一個查詢在之後針對復寫數據表觸發的:
- 數據已載入或修改
- Synapse SQL 實例會調整為不同的層級
- 數據表定義已更新
在下列情況下,不需要重建:
- 暫停作業
- 繼續作業
重建不會在修改數據之後立即發生。 相反地,第一次從數據表選取查詢時,就會觸發重建。 當數據以異步方式複製到每個計算節點時,觸發重建的查詢會立即從數據表的主要版本讀取。 在數據複製完成之前,後續查詢會繼續使用數據表的主要版本。 如果針對強制另一個重建的復寫數據表發生任何活動,則數據複製會失效,而下一個 select 語句將會觸發再次複製數據。
保守地使用索引
標準索引編製做法適用於復寫的數據表。 SQL 集區會在重建時重建每個復寫的數據表索引。 只有在效能提升超過重建索引的成本時,才使用索引。
批次數據載入
將數據載入復寫的數據表時,請嘗試將載入批處理來最小化重建。 執行 select 語句之前,請先執行所有批次載入。
例如,此載入模式會從四個來源載入數據,並叫用四個重建。
- 從來源 1 載入。
- Select 語句觸發重建 1。
- 從來源 2 載入。
- Select 語句觸發重建 2。
- 從來源 3 載入。
- Select 語句觸發重建 3。
- 從來源 4 載入。
- Select 語句會觸發重建 4。
例如,此載入模式會從四個來源載入數據,但只會叫用一個重建。
- 從來源 1 載入。
- 從來源 2 載入。
- 從來源 3 載入。
- 從來源 4 載入。
- Select 語句觸發程式重建。
在批次載入之後重建複寫的數據表
若要確保查詢運行時間一致,請考慮在批次載入之後強制建立復寫數據表。 否則,第一個查詢仍會使用數據移動來完成查詢。
「建置複寫的資料表快取」作業最多可以同時執行兩個作業。 例如,如果您嘗試重建五個數據表的快取,系統會使用 staticrc20 (無法修改)同時建置兩個數據表。 因此,建議您避免使用超過 2 GB 的大型複寫資料表,因為這可能會讓整個節點的快取重建變慢,並增加整體時間。
此查詢會 使用 sys.pdw_replicated_table_cache_state DMV 來列出已修改但未重建的複寫數據表。
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
若要觸發重建,請在上述輸出中的每個數據表上執行下列語句。
SELECT TOP 1 * FROM [ReplicatedTable]
注意
如果您打算重建未快取復寫數據表的統計數據,請務必先更新統計數據,再觸發快取。 更新統計數據會使快取失效,因此順序很重要。
範例:從 開始 UPDATE STATISTICS,然後觸發快取的重建。 在下列範例中,正確的範例會更新統計數據,然後觸發快取的重建。
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
若要監視重建程式,您可以使用 sys.dm_pdw_exec_requests,其中 command 會以 'BuildReplicatedTableCache' 開頭。 例如:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
提示
數據表大小查詢 可用來驗證哪個數據表具有複寫的散發原則,且大於 2 GB。
下一步
若要建立複寫數據表,請使用下列其中一個 語句:
如需分散式數據表的概觀,請參閱 分散式數據表。