Lake 資料庫
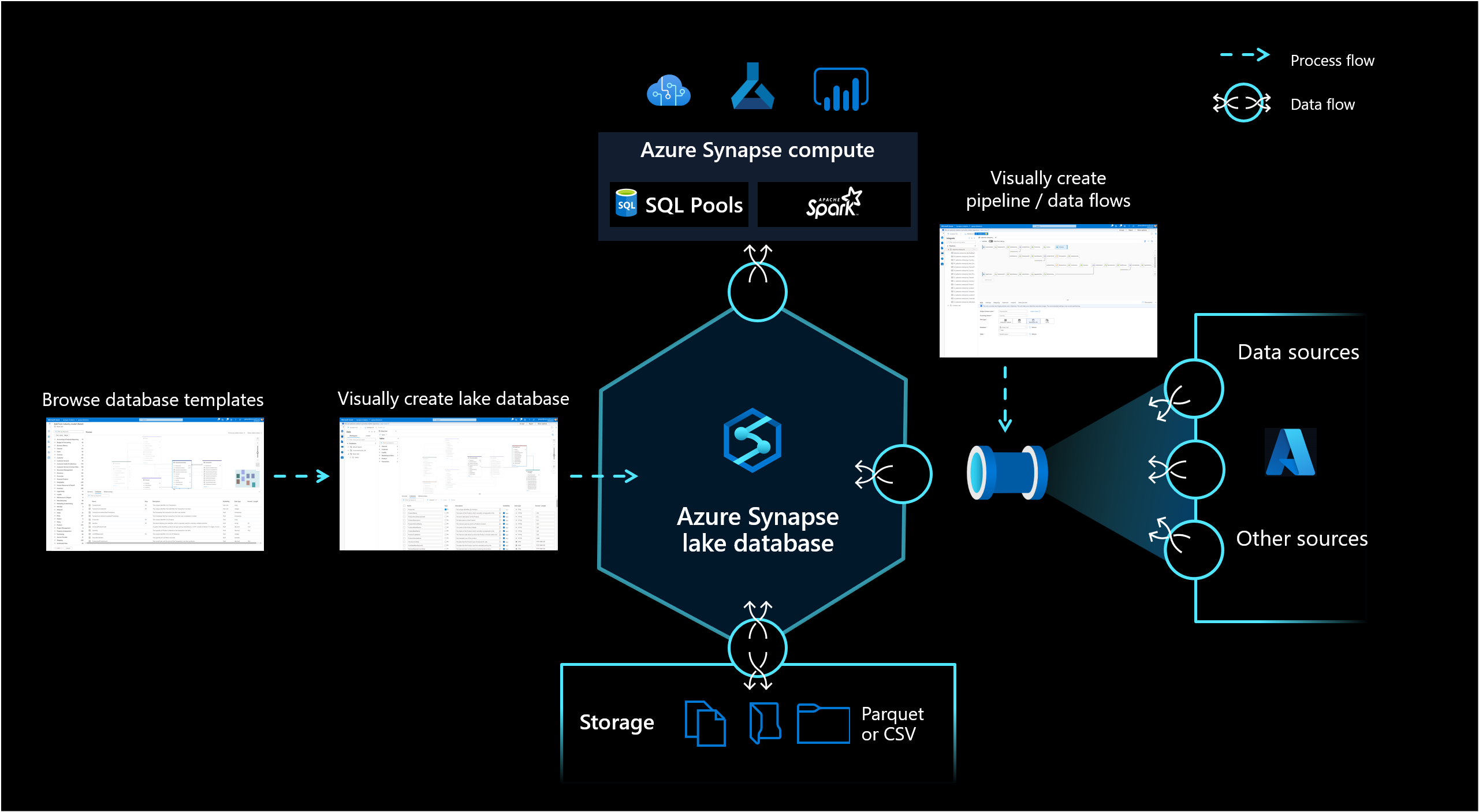
Azure Synapse Analytics 中的 Lake 資料庫可讓客戶整合資料庫設計、儲存數據的元數據資訊,以及描述數據儲存方式和位置的可能性。 Lake 資料庫解決了現今數據湖的挑戰,很難了解數據的結構化方式。
資料庫設計工具
Synapse Studio 中的新資料庫設計工具可讓您建立 Lake 資料庫的數據模型,並將其他資訊加入其中。 您可以描述每個實體和屬性,以提供模型的詳細資訊,此模型不僅包含實體,也包含關聯性。 特別是,無法建立模型關聯性是數據湖上互動的挑戰。 這項挑戰現在已透過整合式設計工具來解決,該設計工具提供資料庫中可用但未在 Lake 上提供的可能性。 此外,將描述和可能示範值新增至模型的功能,可讓未來與模型互動的人員有需要的資訊,以進一步了解數據。
注意
Lake 資料庫中元數據的大小上限為 10 GB。 嘗試發行或更新大小超過 10 GB 的模型將會失敗。 若要解決此問題,請移除數據表和數據行來減少模型大小。 請考慮將大型模型分割成多個 Lake 資料庫,以避免此限制。
資料存放區
Lake 資料庫會使用 Azure 儲存體 帳戶上的 Data Lake 來儲存資料庫的數據。 數據可以儲存在 Parquet、Delta 或 CSV 格式,而不同的設定可用來優化記憶體。 每個 Lake 資料庫都會使用連結服務來定義根資料資料資料夾的位置。 針對每個實體,預設會在 Data Lake 上的這個資料庫資料夾內建立個別的資料夾。 根據預設,Lake 資料庫中的所有數據表都會使用相同的格式,但如果要求,每個實體都可以變更數據的格式和位置。
注意
發佈 Lake 資料庫不會建立查詢 Spark 或 SQL 中數據所需的任何基礎結構或架構。 發佈之後,使用 管線 將數據載入您的 Lake 資料庫,以開始查詢它。
目前 Synapse Studio 不支援 Lake 資料庫的差異格式支援。
記憶體與 Synapse 之間的 Lake 資料庫物件同步處理是單向的。 請務必使用 Synapse Studio 中的資料庫設計工具,執行 Lake 資料庫物件的任何建立或架構修改。 如果您改為從 Spark 進行這類變更,或直接在記憶體中進行這類變更,則 Lake 資料庫的定義將會不同步。如果發生這種情況,您可能會在資料庫設計工具中看到舊的 Lake 資料庫定義。 您必須在資料庫設計工具中復寫和發佈這類變更,才能讓 Lake 資料庫重新同步。
資料庫計算
Lake 資料庫會在 Synapse SQL 無伺服器 SQL 集區和 Apache Spark 中公開,讓使用者能夠將記憶體與計算分離。 與 Lake 資料庫相關聯的元數據可讓您輕鬆地讓不同的計算引擎提供整合式體驗,也能夠使用數據湖上原本不支援的其他資訊(例如關聯性)。
相關內容
使用下列連結,繼續探索資料庫設計工具的功能。