使用 AI 擴充從影像擷取文字和資訊
Azure AI 搜尋可透過 AI 擴充提供數個選項,讓您從影像建立及擷取可搜尋的文字,包括:
藉由使用 OCR,您可以擷取文字,並從相片或圖片中擷取文字,例如停止符號中的 STOP 一詞。 透過影像分析,您可以產生影像的文字表示法,例如丹公英相片的丹公英或黃色。 您也可以擷取影像的中繼資料,例如影像的大小。
本文涵蓋使用影像的基本概念,也說明數個常見案例,例如使用內嵌影像、自訂技能,以及原始影像上的重疊視覺效果。
若要在技能集中使用影像內容,您需要:
- 包含影像的來源檔案
- 針對影像動作設定的搜尋索引子
- 內建或自訂技能的技能集,可叫用 OCR 或影像分析
- 包含要接收分析文字輸出之欄位的搜尋索引,以及建立關聯之索引器中的輸出欄位對應
您可以選擇性地定義投影,以接受影像分析輸出到資料採礦案例的知識存放區。
設定來源檔案
影像處理為索引子驅動,這表示原始輸入必須位於支援的資料來源中。
- 影像分析支援 JPEG、PNG、GIF 和 BMP
- OCR 支援 JPEG、PNG、BMP 和 TIF
影像是獨立的二進位檔或內嵌在檔中,例如 PDF、RTF 或Microsoft應用程式檔。 最多可以從指定的檔擷取 1,000 個影像。 如果檔中有超過 1,000 個影像,則會擷取前 1,000 個影像,然後產生警告。
Azure Blob 儲存體是 Azure AI 搜尋中最常用於影像處理的儲存體。 有三個主要工作與從 Blob 容器擷取的影像相關:
啟用容器中的內容存取權。 如果您使用包含金鑰的完整存取連接字串,則金鑰會授與您內容的權限。 或者,您可以使用 Microsoft Entra ID 進行驗證或以受信任的服務身分連線。
建立 azureblob 類型的數據源,以連線到儲存檔案的 Blob 容器。
檢閱服務層級限制,以確保來源資料符合索引子和擴充的大小上限及數量限制。
設定影像處理的索引子
在設定來源檔案之後,您可以在索引子組態中設定 imageAction 參數,以啟用影像正規化。 影像正規化有助於使影像更統一,以進行下游處理。 影像正規化包含下列作業:
- 大型影像的大小會調整成最大高度和寬度,使其統一。
- 對於具有指定方向之元數據的影像,影像旋轉會調整為垂直載入。
系統會以針對每個影像建立的複雜類型,來擷取中繼資料調整項目。 您無法選擇退出映像正規化需求。 逐一查看影像的技能 (例如 OCR 和影像分析) 預期會有正規化的影像。
建立或更新索引器 以設定組態屬性:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }將
dataToExtract設為contentAndMetadata(必要)。確認 已
parsingMode設定為 預設值 (必要)。此參數會決定索引中所建立搜尋文件的細微性。 預設模式會設定一對一對應,如此一個 Blob 會產生一個搜尋文件。 如果檔很大,或技能需要較小的文字區塊,您可以新增文字分割技能,將檔細分為分頁以供處理之用。 但針對搜尋案例,如果擴充包含影像處理,則需要每個文件有一個 Blob。
設定
imageAction為啟用normalized_images擴充樹狀結構中的節點(必要):generateNormalizedImages會在文件破解期間產生一系列的標準化影像。generateNormalizedImagePerPage(僅適用於 PDF) 會產生正規化影像陣列,PDF 中的每個頁面會在其中轉譯成一個輸出影像。 對於非 PDF 檔案,此參數的行為與您已設定generateNormalizedImages的行為類似。 不過,設定generateNormalizedImagePerPage可讓索引編製作業在設計時效能較低(尤其是大型檔),因為必須產生數個影像。
您可以選擇性地調整所產生標準化影像的寬度或高度:
normalizedImageMaxWidth以像素為單位。 默認值為 2,000。 最大值為 10,000。normalizedImageMaxHeight以像素為單位。 默認值為 2,000。 最大值為 10,000。
標準化影像最大寬度和高度的預設值為 2,000 像素,是根據 OCR 技能所支援的大小上限和影像分析技能而定。 OCR 技能支援非英文語言的最大寬度和高度為 4,200,而英文則為 10,000。 如果您增加最大限制,根據技能集定義和文件的語言,處理可能會因較大的影像而失敗。
如果工作負載以特定檔案類型為目標,請選擇性地設定檔案類型準則。 Blob 索引子組態包括檔案包含和排除設定。 您可將不想要的檔案篩選掉。
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
關於標準化影像
當 imageAction 設定為非 值時,新 normalized_images 字段會包含影像陣列。 每個影像皆為具有下列成員的複雜類型:
| 影像成員 | 描述 |
|---|---|
| data | 以 BASE64 編碼的 JPEG 格式標準化影像字串。 |
| width | 標準化影像的寬度,以像素為單位。 |
| 高度 | 標準化影像的高度,以像素為單位。 |
| originalWidth | 影像標準化之前的原始寬度。 |
| originalHeight | 影像標準化之前的原始高度。 |
| rotationFromOriginal | 逆時針旋轉為了建立標準化影像而發生的度數。 0 度到 360 度之間的值。 此步驟會從相機或掃描器產生的影像中讀取中繼資料。 通常為 90 度的倍數。 |
| contentOffset | 影像擷取來源的內容欄位中的字元位移。 此欄位僅適用於含內嵌影像的檔案。
contentOffset從 PDF 檔擷取的影像一律位於檔中擷取的頁面上文字結尾。 這表示不論該頁面上影像的原始位置為何,影像都會出現在該頁面上的所有文字之後。 |
| pageNumber | 如果影像是從 PDF 擷取或轉譯,則此欄位會包含在其擷取或轉譯來源的 PDF 中的頁碼 (從 1 開始)。 如果影像不是來自 PDF,此欄位為 0。 |
的範例值 normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
定義影像處理的技能集
本節提供使用技能輸入、輸出和模式的內容,藉此補充技能參考文章,因為其與影像處理有關。
建立或更新技能集來新增技能。
從 Azure 入口網站 新增 OCR 和影像分析的範本,或從技能參考檔複製定義。 將其插入技能集定義的技能陣列中。
如有必要, 請在技能集的 Azure AI 服務屬性中包含多服務密鑰 。 Azure AI 搜尋會呼叫可計費的 Azure AI 服務資源來進行 OCR 和影像分析,以取得超過免費限制 (每天每個索引子 20 個) 的交易。 Azure AI 服務必須位於與搜尋服務相同的區域中。
如果原始影像內嵌在 PDF 或 PPTX 或 DOCX 等應用程式檔中,如果您想要一起輸出影像和文字輸出,則需要新增文字合併技能。 本文中會進一步討論使用內嵌影像。
建立技能的基本架構並設定 Azure AI 服務之後,您就可以專注於每個個別的影像技能、定義輸入和來源內容,以及將輸出對應至索引或知識存放區中的欄位。
注意
如需結合影像處理與下游自然語言處理的範例技能集,請參閱 REST 教學課程:使用 REST 和 AI 從 Azure Blob 產生可搜尋的內容。 其示範如何將技能映像處理輸出饋送至實體辨識和關鍵片語擷取。
影像處理的輸入
如前所述,會在文件破解期間擷取影像,然後正規化為預備步驟。 正規化影像是任何影像處理技能的輸入,且一律以下列兩種方式之一,在擴充的文件樹狀結構中表示:
/document/normalized_images/*適用於以整體方式處理的文件。/document/normalized_images/*/pages適用於以區塊 (頁面) 方式處理的文件。
無論您是否以相同方式使用 OCR 和影像分析,輸入幾乎具有相同的建構:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
將輸出對應至搜尋欄位
在技能中,影像分析和 OCR 技能輸出一律為文字。 輸出文字會在內部擴充文件樹狀結構中以節點表示,且每個節點都必須對應至知識存放區中搜尋索引或投影中的欄位,才能在應用程式中提供內容。
在技能中,檢閱每個技能的
outputs區段,以判斷擴充文件中有哪些節點存在:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }建立或更新搜尋索引,以新增可接受技能輸出的欄位。
在下列欄位集合範例中, 內容 為 Blob 內容。 Metadata_storage_name包含檔名(設為
retrievabletrue)。 Metadata_storage_path是 Blob 的唯一路徑,而且是預設的檔索引鍵。 Merged_content是來自文字合併的輸出(當影像內嵌時很有用)。文字 和 layoutText 是 OCR 技能輸出,而且必須是字串集合,才能擷取整個檔的所有 OCR 產生的輸出。
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],更新索引子,將技能集輸出 (擴充樹狀結構中的節點) 對應至索引欄位。
擴充的文件為內部文件。 若要將擴充文件樹中的節點外部化,請設定輸出欄位對應,指定哪些索引欄位接收節點內容。 您的應用程式會透過索引欄位存取擴充的資料。 下列範例顯示 擴充檔中的文字 節點 (OCR 輸出),其對應至 搜尋索引中的文字 欄位。
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]執行索引子以叫用來源文件擷取、影像處理和編製索引。
驗證結果
針對索引執行查詢,以檢查影像處理的結果。 使用搜尋總管做為搜尋用戶端,或任何傳送 HTTP 要求的工具。 下列查詢會選取包含影像處理輸出的欄位。
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR 會辨識影像檔案中的文字。 這表示如果源文檔是純文本或純影像,則 OCR 欄位(text 和 layoutText)是空的。 同樣地,如果源文檔輸入嚴格為文字,則影像分析字段(imageCaption 和 imageTags) 是空的。 如果映像處理輸入是空的,索引子執行就會發出警告。 當擴充文件中未填入節點時,預期會有這類警告。 回想一下,Blob 索引讓您可在想要隔離使用內容類型的情況下包含或排除檔案類型。 您可以使用這些設定來減少索引器執行期間的雜訊。
檢查結果的替代查詢可能包含 內容 和 merged_content 欄位。 請注意,這些欄位會包含任何 Blob 檔案的內容,即使是沒有執行影像處理的欄位也一樣。
關於技能輸出
技能輸出包括 text (OCR)、 layoutText (OCR)、 merged_content、 captions (影像分析)、 tags (影像分析):
text會儲存 OCR 產生的輸出。 這個節點應該對應至Collection(Edm.String)類型的欄位。 每個搜尋檔都有一個text字段,其中包含包含多個影像的檔的逗號分隔字串。 下圖顯示三份文件的 OCR 輸出。 首先是包含檔案但無影像的文件。 第二個是包含一個單字 的檔(圖像檔),Microsoft。 第三是包含多個影像的文件,有些不含任何文字 ("",)。"value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutText會儲存頁面上文字位置的 OCR 產生資訊,如標準化影像的周框方塊和座標所述。 這個節點應該對應至Collection(Edm.String)類型的欄位。 每個搜尋檔都有一個layoutText字段,其中包含逗號分隔字串。merged_content會儲存文字合併技能的輸出,而且應該是一個大型的型Edm.String別字段,其中包含源文檔的原始文字,內嵌text取代影像。 如果檔案是純文本的,則 OCR 和影像分析沒有任何作用,而且merged_content與 (包含 Blob 內容的 Blob 屬性) 相同content。imageCaption擷取影像的描述做為個別標記和較長的文字描述。imageTags會將影像的相關標籤儲存為關鍵詞集合、源檔中所有影像的一個集合。
下列螢幕擷取畫面為包含文字和內嵌影像的 PDF 圖例。 文件破解偵測到三個內嵌影像:海鷗、地圖、老鷹。 範例中的其他文字 (包括標題、標頭和本文文字) 已擷取為文字,並從影像處理中排除。
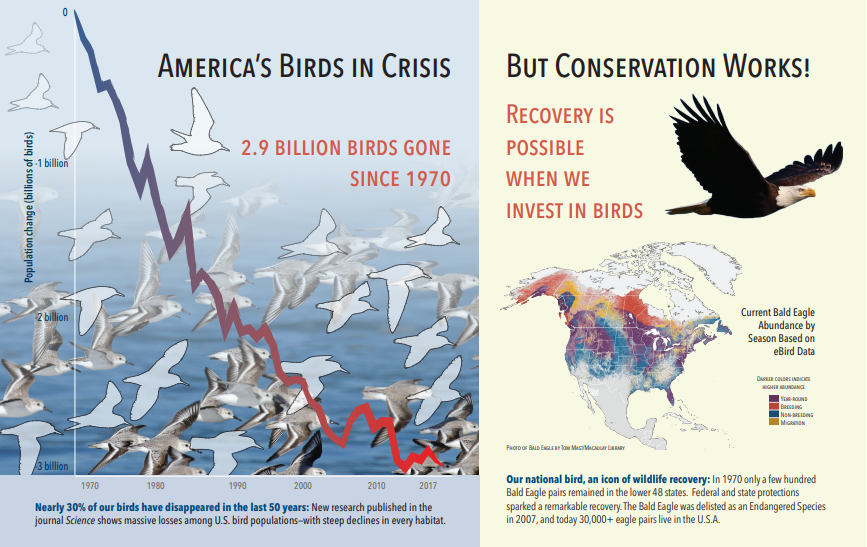
影像分析輸出會在下列 JSON 中說明(搜尋結果)。 技能定義可讓您指定感興趣的視覺功能。 在此範例中,會產生標記和描述,但還有更多輸出可供選擇。
imageCaptionoutput 是描述陣列,每個影像一個,由tags描述影像的單一單字和較長的片語所表示。 請注意,由海鷗群組成的 標記正在水中游泳,或 鳥的特寫。imageTagsoutput 是單一標記的陣列,會依建立順序列出。 請注意,標記會重複。 沒有彙總或群組。
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
案例:PDF 中的內嵌影像
當您想要處理的影像內嵌在其他檔案中,例如 PDF 或 DOCX 時,擴充管線只會擷取影像,然後將影像傳遞至 OCR 或影像分析進行處理。 影像擷取會在文件破解期間發生,一旦分隔影像後,除非明確將處理的輸出合併回來源文字,否則其會保持分隔。
文字合併可用來將影像處理輸出放回文件中。 雖然文字合併並非硬式需求,但會經常叫用,因此影像輸出 (OCR 文字、OCR layoutText、影像標籤、影像標題) 可以重新引入文件中。 視技能而定,影像輸出會將內嵌二進位影像取代為就地文字對等項目。 影像分析輸出可在影像位置進行合併。 OCR 輸出一律會出現在每個頁面的結尾。
下列工作流程概述影像擷取、分析、合併的程序,以及如何擴充管線,將影像處理的輸出推送至其他文字型技能 (例如實體辨識或文字翻譯)。
連線到資料來源之後,索引子就會載入並破解來源文件、擷取影像和文字,以及將每個內容類型排入佇列以進行處理。 只會建立包含根節點 (document) 的擴充檔。
佇列中的影像會正規化,並以檔/normalized_images節點的形式傳入擴充檔。
會執行影像擴充,並使用
"/document/normalized_images"做為輸入。影像輸出會傳遞至擴充的文件樹中,並將每個輸出做為個別節點。 輸出會因技能而異(OCR 的文字和版面配置文字;影像分析的標籤和標題)。
如果您想要讓搜尋文件同時包含文字和影像來源文字,請選擇性 (但建議) 使用文字合併執行,並結合這些影像的文字表示與擷取自檔案的原始文字。 文字區塊會合併成單一大型字串,其中會先將文字插入字串,然後再將 OCR 文字輸出或影像標記和標題插入。
現在,文字合併的輸出是最終文字,用於分析執行文字處理的任何下游技能。 例如,如果您的技能集同時包含 OCR 和實體辨識,則實體辨識的輸入應該為
"document/merged_text"(文字合併技能輸出的 targetName)。執行所有技能之後,擴充的文件隨即完成。 在最後一個步驟中,索引子會參考輸出欄位對應,以將擴充的內容傳送至搜尋索引中的個別欄位。
下列範例技能集會建立一個 merged_text 欄位,其中包含具有內嵌 OCRed 文字取代內嵌影像的文件原始文字。 其也包含使用 merged_text 做為輸入的實體辨識技能。
要求本文語法
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
既然您有欄位 merged_text ,您可以將它對應為索引器定義中的可搜尋欄位。 檔案中的所有內容,包括影像的文字,均可供搜尋。
案例:視覺化週框方塊
另一個常見的案例是,對於搜尋結果的版面配置資訊進行視覺化處理。 例如,您想要反白顯示影像中所找到的一段文字,作為搜尋結果的一部分。
由於 OCR 步驟是在標準化影像上執行,因此配置座標位於標準化影像空間中,但如果您需要顯示原始影像,請將配置中的座標點轉換為原始影像座標系統。
下方為該模式的演算法:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
案例:自訂影像技能
影像也可以傳入自訂技能並從自訂技能中傳回。 技能集 base64 編碼要傳入自訂技能的影像。 若要使用自訂技能內的影像,請將 "/document/normalized_images/*/data" 設定為自訂技能的輸入。 在您的自訂技能程式碼中,在將字串轉換成影像之前,先對字串進行 base64 解碼。 若要將影像傳回技能集,請在將影像傳回技能集之前,先對影像進行 base64 編碼。
影像會以包含下列屬性的物件傳回。
{
"$type": "file",
"data": "base64String"
}
Azure 搜尋服務 Python 範例存放庫具有在 Python 中實作的完整範例,其自訂技能可擴充影像。
將影像傳遞至自訂技能
針對需要自訂技能來處理影像的案例,您可以將影像傳遞至自訂技能,並使其傳回文字或影像。 下列技能來自範例。
下列技能集會採用標準化影像 (在文件破解期間取得),並輸出影像的配量。
範例技能集
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
自訂技能範例
自訂技能本身是技能集外部的技能。 在此情況下,Python 程式碼會先迴圈處理使用自訂技能格式的要求記錄批次,然後將 base64 編碼的字串轉換成影像。
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
類似於傳回影像,在 JSON 物件中傳回 base64 編碼的字串,其中包含$type檔案的屬性。
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
相關內容
- 建立索引子 (REST)(英文)
- 影像分析技能
- OCR 技術 (英文)
- 文字合併技能
- 如何建立技能集
- 將擴充的輸出對應至欄位