使用 Pacemaker 在 Azure VM 上的 SUSE Linux Enterprise Server 實現 IBM Db2 LUW 的高可用性
高可用性和災害復原 (HADR) 設定中適用於 Linux、UNIX 和 Windows (LUW) 的 IBM Db2,包含一個執行主要資料庫執行個體的節點,以及至少一個執行次要資料庫執行個體的節點。 根據您的設定,主要資料庫執行個體的變更會同步或非同步地複寫到次要資料庫執行個體。
注意
本文參考了 Microsoft 不再使用的詞彙。 當這些字詞從軟體中移除時,我們會將其從本文中移除。
本文說明如何部署和設定 Azure 虛擬機器 (VM)、安裝叢集架構,以及安裝具備 HADR 設定的 IBM Db2 LUW。
本文未涵蓋如何安裝及設定具備 HADR 的 IBM Db2 LUW 或如何安裝 SAP 軟體。 為了協助您完成這些工作,我們提供 SAP 和 IBM 安裝手冊的參考。 本文著重於 Azure 環境中特有的部分。
支援的 IBM Db2 版本為 10.5 和更新版本,如 SAP 附註 1928533 中所述。
開始安裝之前,請參閱下列 SAP 附註和文件:
| SAP 附註 | 描述 |
|---|---|
| 1928533 | Azure 上的 SAP 應用程式︰支援的產品和 Azure VM 類型 |
| 2015553 | Microsoft Azure 上的 SAP:支援的必要條件 |
| 2178632 | Azure 上適用於 SAP 的主要監視計量 |
| 2191498 | Linux 上搭配 Azure 的 SAP:增強型監視功能 |
| 2243692 | Linux on Azure (IaaS) VM:SAP 授權問題 |
| 1984787 | SUSE LINUX Enterprise Server 12:安裝注意事項 |
| 1999351 | 對適用於 SAP 的增強型 Azure 監視功能進行疑難排解 |
| 2233094 | DB6︰Azure 上使用適用於 Linux、UNIX 和 Windows 之 IBM Db2 的 SAP 應用程式 - 其他資訊 |
| 1612105 | DB6:使用 HADR 的 Db2 常見問題 |
概觀
為了實現高可用性,具備 HADR 的 IBM Db2 LUW 會安裝在至少兩部 Azure 虛擬機器上,這些虛擬機器部署在具有跨可用性區域 (部分機器翻譯) 彈性協調流程的虛擬機器擴展集 (部分機器翻譯) 中,或是可用性設定組 (機器翻譯) 中。
下圖顯示兩部資料庫伺服器 Azure VM 的設定。 這兩部資料庫伺服器 Azure VM 都有自己的儲存體連結,且已啟動並執行。 在 HADR 中,其中一個 Azure VM 中的一個資料庫執行個體具有主要執行個體的角色。 所有用戶端都會連線到這個主要執行個體。 資料庫交易中的所有變更都會保存在本機的 Db2 交易記錄中。 當交易記錄記錄保存在本機時,記錄會透過 TCP/IP 傳輸到第二部資料庫伺服器、待命伺服器或待命執行個體上的資料庫執行個體。 待命執行個體會向前復原傳輸的交易記錄記錄,來更新本機資料庫。 如此一來,待命伺服器就會與主要伺服器保持同步。
HADR 只是複寫功能。 它沒有失敗偵測,也沒有自動接管或容錯移轉設施。 接管或傳輸至待命伺服器必須由資料庫管理員手動起始。 若要實現自動接管和失敗偵測,您可以使用 Linux Pacemaker 叢集功能。 Pacemaker 會監視兩個資料庫伺服器執行個體。 當主要資料庫伺服器執行個體當機時,Pacemaker 會起始由待命伺服器接管的「自動」HADR。 Pacemaker 也會確保虛擬 IP 位址已指派給新的主要伺服器。
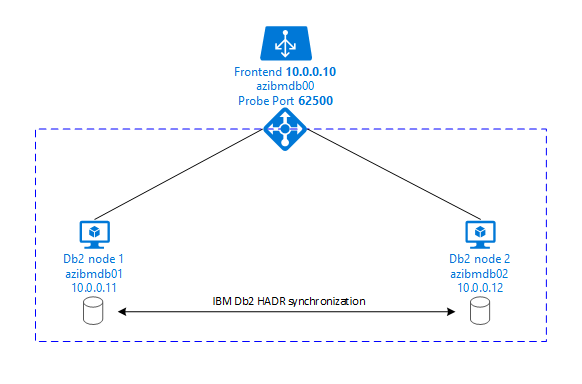
若要讓 SAP 應用程式伺服器連線到主要資料庫,您需要虛擬主機名稱和虛擬 IP 位址。 在容錯移轉後,SAP 應用程式伺服器會連線到新的主要資料庫執行個體。 在 Azure 環境中,需要有 Azure 負載平衡器,才能使用 IBM Db2 HADR 所需的虛擬 IP 位址。
為了協助您完整了解具備 HADR 的 IBM Db2 LUW 和 Pacemaker 如何符合高可用性 SAP 系統設定,下圖提供以 IBM Db2 資料庫為基礎的 SAP 系統高可用性設定概觀。 本文僅涵蓋 IBM Db2,但提供有關如何設定 SAP 系統其他元件的文章參考。
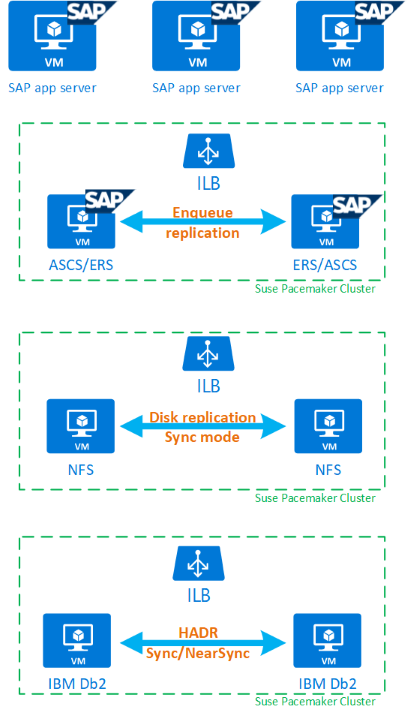
必要步驟的整體概觀
若要部署 IBM Db2 設定,您必須遵循下列步驟:
- 規劃您的環境。
- 部署 VM。
- 更新 SUSE Linux 並設定檔案系統。
- 安裝並設定 Pacemaker。
- 安裝高可用性 NFS。
- 將 ASCS/ERS 安裝在不同的叢集上。
- 安裝具有分散式/高可用性選項 (SWPM) 的 IBM Db2 資料庫。
- 安裝並建立次要資料庫節點和執行個體,並設定 HADR。
- 確認 HADR 正常運作。
- 套用 Pacemaker 設定以控制 IBM Db2。
- 設定 Azure Load Balancer。
- 安裝主要和對話方塊應用程式伺服器。
- 檢查並調整 SAP 應用程式伺服器的設定。
- 執行容錯移轉和接管測試。
針對裝載具備 HADR 的 IBM Db2 LUW 規劃 Azure 基礎結構
在執行部署之前,請先完成規劃程序。 規劃程序可為在 Azure 中部署具備 HADR 的 Db2 設定奠定基礎。 下表列出規劃 IMB Db2 LUW (SAP 環境的資料庫部分) 所需的重要元素:
| 主題 | 簡短描述 |
|---|---|
| 定義 Azure 資源群組 | 部署 VM、虛擬網路、Azure Load Balancer 和其他資源的資源群組。 可以是現有或全新。 |
| 虛擬網路/子網路定義 | 部署 IBM Db2 和 Azure Load Balancer 之 VM 的位置。 可以是現有或新建立的。 |
| 裝載 IBM Db2 LUW 的虛擬機器 | VM 大小、儲存體、網路、IP 位址。 |
| IBM Db2 資料庫的虛擬主機名稱和虛擬 IP | 用於連線 SAP 應用程式伺服器的虛擬 IP 或主機名稱。 db-virt-hostname、db-virt-ip。 |
| Azure 隔離 | Azure 隔離或 SBD 隔離 (強烈建議)。 避免核心分裂情況的方法。 |
| SBD VM | SBD 虛擬機器大小、儲存體、網路。 |
| Azure Load Balancer | 使用適用於 Db2 資料庫的標準 (建議) 探查連接埠 probe-port (建議使用 62500)。 |
| 名稱解析 | 名稱解析在環境中的運作方式。 強烈建議使用 DNS 服務。 您可以使用本機主機檔案。 |
如需 Azure 中 Linux Pacemaker 的詳細資訊,請參閱在 Azure 中的 SUSE Linux Enterprise Server 上設定 Pacemaker。
重要
針對 Db2 11.5.6 (含) 以上版本,我們強烈建議使用 IBM Pacemaker 的整合式解決方案。
- 使用 Pacemaker 的整合式解決方案 (英文)。
- Microsoft Azure 上可用的替代或其他設定 (英文)。
在 SUSE Linux 上進行部署
IBM Db2 LUW 的資源代理程式隨附於適用於 SAP 應用程式的 SUSE Linux Enterprise Server 中。 針對本文件中所述的設定,您必須使用適用於 SAP 應用程式的 SUSE Linux Server。 Azure Marketplace 包含適用於 SAP 應用程式 12 的 SUSE Linux Enterprise Server 的映像,讓您可用來部署新的虛擬機器。 當您在 Azure VM Marketplace 中選擇 VM 映像時,請注意 SUSE 透過 Azure Marketplace 提供的各種支援或服務模型。
主機:DNS 更新
建立所有主機名稱的清單,包括虛擬主機名稱,並更新 DNS 伺服器,以啟用適當的 IP 位址來解析主機名稱解決方案。 如果 DNS 伺服器不存在,或您無法更新並建立 DNS 項目,您必須使用參與此案例之個別 VM 的本機主機檔案。 如果您使用主機檔案項目,請確定項目會套用至 SAP 系統環境中的所有 VM。 不過,建議您使用您的 DNS,在理想情況下,會延伸至 Azure
手動部署
請確定 IBM/SAP for IBM Db2 LUW 支援選取的作業系統。 Azure VM 和 Db2 版本支援作業系統版本的清單可在 SAP 附註 1928533 中取得。 個別 Db2 版本的 OS 版本清單可在 SAP 產品可用性對照表中取得。 我們強烈建議至少使用 SLES 12 SP4,因為此版本或更新版本的 SUSE Linux 版本有 Azure 相關的效能改善。
- 建立或選取資源群組。
- 建立或選取虛擬網路和子網路。
- 為 SAP 虛擬機器選擇適當的部署類型 (部分機器翻譯)。 通常是具有彈性協調流程的虛擬機器擴展集。
- 建立虛擬機器 1。
- 在 Azure Marketplace 中使用 SLES for SAP 映像。
- 選取在步驟 3 中建立的擴展集、可用性區域或可用性設定組。
- 建立虛擬機器 2。
- 在 Azure Marketplace 中使用 SLES for SAP 映像。
- 選取在步驟 3 中建立的擴展集、可用性區域或可用性設定組 (與步驟 4 中建立的區域不同)。
- 將資料磁碟新增至 VM,然後查看 SAP 工作負載的 IBM Db2 Azure 虛擬機器 DBMS 部署一文中的檔案系統設定建議。
安裝 IBM Db2 LUW 和 SAP 環境
在開始安裝以 IBM Db2 LUW 為基礎的 SAP 環境之前,請先檢閱下列文件:
- Azure 文件
- SAP 文件
- IBM 文件
本文中的簡介一節會提供此文件的連結。
請參閱 SAP 安裝手冊,以了解在 IBM Db2 LUW 上安裝 NetWeaver 架構應用程式的相關資訊。
您可以使用 SAP 安裝指南尋找工具,在 SAP 說明入口網站上找到指南。
您可以藉由設定下列篩選條件,減少入口網站中顯示的指南數目:
- 我想要:「安裝新系統」
- 我的資料庫:「IBM Db2 for Linux、Unix 和 Windows」
- SAP NetWeaver 版本、堆疊設定或作業系統的其他篩選條件
設定具備 HADR 之 IBM Db2 LUW 的安裝提示
若要設定主要 IBM Db2 LUW 資料庫執行個體:
- 使用高可用性或分散式選項。
- 安裝 SAP ASCS/ERS 和資料庫執行個體。
- 備份新安裝的資料庫。
重要
記下安裝期間設定的「資料庫通訊連接埠」。 這兩個資料庫執行個體的連接埠號碼必須相同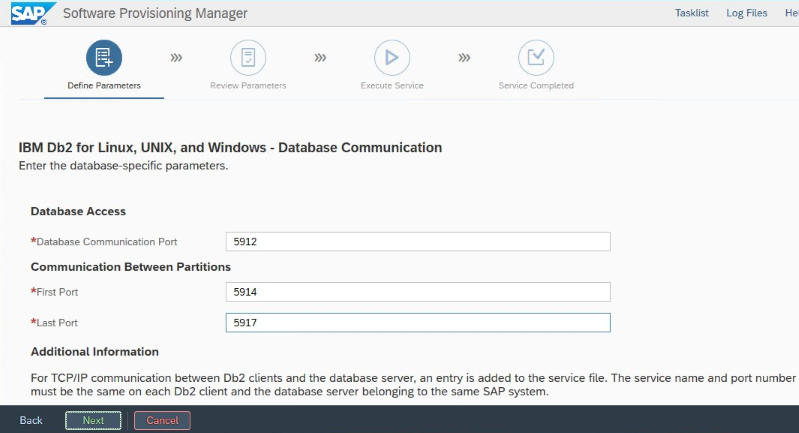
若要使用 SAP 同質系統複製程序來設定待命資料庫伺服器,請執行下列步驟:
選取 [系統複製] 選項 >[目標系統]>[分散式]>[資料庫執行個體]。
至於複製方法,請選取 [同質系統],以便您可以使用備份來還原待命伺服器執行個體上的備份。
當您到達結束步驟,要還原同質系統複製的資料庫時,請結束安裝程式。 從主要主機的備份還原資料庫。 所有後續安裝階段都已在主要資料庫伺服器上執行。
設定 IBM Db2 的 HADR。
注意
針對 Azure 和 Pacemaker 專用的安裝和設定:透過 SAP 軟體佈建管理員進行安裝程序期間,IBM Db2 LUW 的高可用性有明確的問題:
- 請勿選取 [IBM Db2 pureScale]
- 請勿選取 [為多平台安裝 IBM Tivoli System Automation]。
- 請勿選取 [產生叢集設定檔]。
當您使用適用於 Linux Pacemaker 的 SBD 裝置時,請設定下列 Db2 HADR 參數:
- HADR 對等時間範圍期間 (秒) (HADR_PEER_WINDOW) = 300
- HADR 逾時值 (HADR_TIMEOUT) = 60
當您使用 Azure Pacemaker 隔離代理程式時,請設定下列參數:
- HADR 對等時間範圍期間 (秒) (HADR_PEER_WINDOW) = 900
- HADR 逾時值 (HADR_TIMEOUT) = 60
我們根據初始容錯移轉/接管測試來建議上述參數。 您必須使用這些參數設定來測試容錯移轉和接管的適當功能。 因為個別設定可能會有所不同,所以參數可能需要調整。
重要
針對正常啟動具備 HADR 設定的 IBM Db2:次要或待命資料庫執行個體必須啟動並執行,才能啟動主要資料庫執行個體。
為了示範本文描述的用途和程序,資料庫 SID 為 PTR。
IBM Db2 HADR 檢查
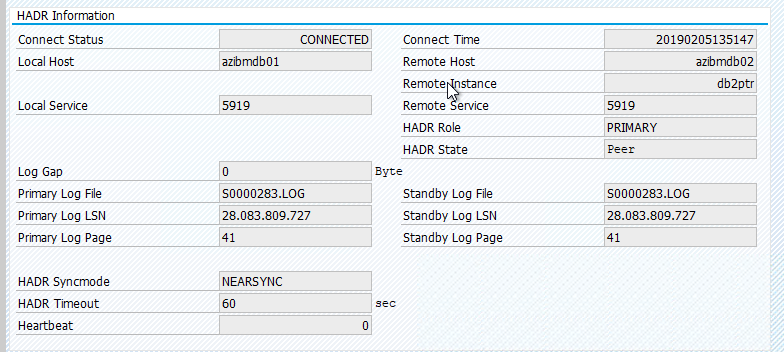
在您設定 HADR,而且在主要和待命節點上的狀態為 PEER 和 CONNECTED 之後,請執行下列檢查:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
# Database Member 0 -- Database PTR -- Active -- Up 1 days 01:51:38 -- Date 2019-02-06-15.35.28.505451
#
# HADR_ROLE = PRIMARY
# REPLAY_TYPE = PHYSICAL
# HADR_SYNCMODE = NEARSYNC
# STANDBY_ID = 1
# LOG_STREAM_ID = 0
# HADR_STATE = PEER
# HADR_FLAGS = TCP_PROTOCOL
# PRIMARY_MEMBER_HOST = azibmdb02
# PRIMARY_INSTANCE = db2ptr
# PRIMARY_MEMBER = 0
# STANDBY_MEMBER_HOST = azibmdb01
# STANDBY_INSTANCE = db2ptr
# STANDBY_MEMBER = 0
# HADR_CONNECT_STATUS = CONNECTED
# HADR_CONNECT_STATUS_TIME = 02/05/2019 13:51:47.170561 (1549374707)
# HEARTBEAT_INTERVAL(seconds) = 15
# HEARTBEAT_MISSED = 0
# HEARTBEAT_EXPECTED = 6137
# HADR_TIMEOUT(seconds) = 60
# TIME_SINCE_LAST_RECV(seconds) = 13
# PEER_WAIT_LIMIT(seconds) = 0
# LOG_HADR_WAIT_CUR(seconds) = 0.000
# LOG_HADR_WAIT_RECENT_AVG(seconds) = 0.000025
# LOG_HADR_WAIT_ACCUMULATED(seconds) = 434.595
# LOG_HADR_WAIT_COUNT = 223713
# SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
# SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 374400
# PRIMARY_LOG_FILE,PAGE,POS = S0000280.LOG, 15571, 27902548040
# STANDBY_LOG_FILE,PAGE,POS = S0000280.LOG, 15571, 27902548040
# HADR_LOG_GAP(bytes) = 0
# STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000280.LOG, 15571, 27902548040
# STANDBY_RECV_REPLAY_GAP(bytes) = 0
# PRIMARY_LOG_TIME = 02/06/2019 15:34:39.000000 (1549467279)
# STANDBY_LOG_TIME = 02/06/2019 15:34:39.000000 (1549467279)
# STANDBY_REPLAY_LOG_TIME = 02/06/2019 15:34:39.000000 (1549467279)
# STANDBY_RECV_BUF_SIZE(pages) = 2048
# STANDBY_RECV_BUF_PERCENT = 0
# STANDBY_SPOOL_LIMIT(pages) = 0
# STANDBY_SPOOL_PERCENT = NULL
# STANDBY_ERROR_TIME = NULL
# PEER_WINDOW(seconds) = 300
# PEER_WINDOW_END = 02/06/2019 15:40:25.000000 (1549467625)
# READS_ON_STANDBY_ENABLED = N
#Secondary output:
# Database Member 0 -- Database PTR -- Standby -- Up 1 days 01:46:43 -- Date 2019-02-06-15.38.25.644168
#
# HADR_ROLE = STANDBY
# REPLAY_TYPE = PHYSICAL
# HADR_SYNCMODE = NEARSYNC
# STANDBY_ID = 0
# LOG_STREAM_ID = 0
# HADR_STATE = PEER
# HADR_FLAGS = TCP_PROTOCOL
# PRIMARY_MEMBER_HOST = azibmdb02
# PRIMARY_INSTANCE = db2ptr
# PRIMARY_MEMBER = 0
# STANDBY_MEMBER_HOST = azibmdb01
# STANDBY_INSTANCE = db2ptr
# STANDBY_MEMBER = 0
# HADR_CONNECT_STATUS = CONNECTED
# HADR_CONNECT_STATUS_TIME = 02/05/2019 13:51:47.205067 (1549374707)
# HEARTBEAT_INTERVAL(seconds) = 15
# HEARTBEAT_MISSED = 0
# HEARTBEAT_EXPECTED = 6186
# HADR_TIMEOUT(seconds) = 60
# TIME_SINCE_LAST_RECV(seconds) = 5
# PEER_WAIT_LIMIT(seconds) = 0
# LOG_HADR_WAIT_CUR(seconds) = 0.000
# LOG_HADR_WAIT_RECENT_AVG(seconds) = 0.000023
# LOG_HADR_WAIT_ACCUMULATED(seconds) = 434.595
# LOG_HADR_WAIT_COUNT = 223725
# SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
# SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 372480
# PRIMARY_LOG_FILE,PAGE,POS = S0000280.LOG, 15574, 27902562173
# STANDBY_LOG_FILE,PAGE,POS = S0000280.LOG, 15574, 27902562173
# HADR_LOG_GAP(bytes) = 0
# STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000280.LOG, 15574, 27902562173
# STANDBY_RECV_REPLAY_GAP(bytes) = 155
# PRIMARY_LOG_TIME = 02/06/2019 15:37:34.000000 (1549467454)
# STANDBY_LOG_TIME = 02/06/2019 15:37:34.000000 (1549467454)
# STANDBY_REPLAY_LOG_TIME = 02/06/2019 15:37:34.000000 (1549467454)
# STANDBY_RECV_BUF_SIZE(pages) = 2048
# STANDBY_RECV_BUF_PERCENT = 0
# STANDBY_SPOOL_LIMIT(pages) = 0
# STANDBY_SPOOL_PERCENT = NULL
# STANDBY_ERROR_TIME = NULL
# PEER_WINDOW(seconds) = 300
# PEER_WINDOW_END = 02/06/2019 15:43:19.000000 (1549467799)
# READS_ON_STANDBY_ENABLED = N
設定 Azure Load Balancer
在 VM 設定期間,您可以選擇在網路區段中建立或選取現有的負載平衡器。 請遵循下列步驟以設定 DB2 資料庫高可用性設定的標準負載平衡器。
請遵循建立負載平衡器中的步驟,使用 Azure 入口網站為高可用性 SAP 系統設定標準負載平衡器。 在設定負載平衡器期間,請考慮下列幾點:
- 前端 IP 組態:建立前端 IP。 選取與資料庫虛擬機相同的虛擬網路和子網路名稱。
- 後端集區:建立後端集區並新增資料庫 VM。
- 輸入規則:建立負載平衡規則。 針對這兩個負載平衡規則,請遵循相同的步驟。
- 前端 IP 位址:選取前端 IP。
- 後端集區:選取後端集區。
- 高可用性連接埠:選取此選項。
- 通訊協定:選取 [TCP]。
- 健全狀態探查:使用下列詳細衣料建立健全狀態探查:
- 通訊協定:選取 [TCP]。
- 連接埠:例如,625<執行個體編號>。
- 間隔:輸入 5。
- 探查閾值:輸入 2。
- 閒置逾時 (分鐘):輸入 30。
- 啟用浮動 IP:選取此選項。
注意
未遵守健全狀態探查設定屬性 numberOfProbes,在入口網站中又名為狀況不良閾值。 若要控制連續探查成功或失敗的數目,請將屬性 probeThreshold 設定為 2。 目前無法使用 Azure 入口網站來設定此屬性,因此請使用 Azure CLI 或 PowerShell 命令。
注意
當不具公用 IP 位址的 VM 放在內部 (沒有公用 IP 位址) Azure Standard Load Balancer 執行個體的後端集區時,除非另外設定來允許路由傳送至公用端點,否則不會有輸出網際網路連線能力。 如需更多如何實現輸出連線能力的詳細資訊,請參閱在 SAP 高可用性案例中使用 Azure Standard Load Balancer 實現 VM 的公用端點連線能力 (部分機器翻譯)。
重要
請勿在位於 Azure Load Balancer 後方的 Azure VM 上啟用 TCP 時間戳記。 啟用 TCP 時間戳記可能會導致健全狀態探查失敗。 將 net.ipv4.tcp_timestamps 參數設定為 0。 如需詳細資訊,請參閱負載平衡器健全狀態探查。
建立 Pacemaker 叢集
若要為此 IBM Db2 伺服器建立基本 Pacemaker 叢集,請參閱在 Azure 中的 SUSE Linux Enterprise Server 上設定 Pacemaker。
Db2 Pacemaker 設定
當您在節點失敗時使用 Pacemaker 進行自動容錯移轉時,您必須視情況設定 Db2 執行個體和 Pacemaker。 本節描述此類型的設定。
下列項目前面會加上:
- [A]:適用於所有節點
- [1]:僅適用於節點 1
- [2]:僅適用於節點 2
[A] Pacemaker 設定的必要條件:
- 使用 db2stop 透過使用者 db2<sid> 關閉兩個資料庫伺服器。
- 將 db2<sid> 使用者的殼層環境變更為 /bin/ksh。 建議您使用 Yast 工具。
Pacemaker 設定
重要
最近測試顯示 netcat 會因待處理項目及其僅處理單一連線的限制,而停止回應要求的狀況。 Netcat 資源會停止接聽 Azure Load Balancer 要求,使浮動 IP 無法使用。 針對現有的 Pacemaker 叢集,我們在過去建議將 netcat 取代成 socat。 目前建議使用 azure-lb 資源代理程式,其為 resource-agents 套件的一部分,並包含下列套件版本需求:
- 針對 SLES 12 SP4/SP5,版本必須至少為 resource-agents-4.3.018.a7fb5035-3.30.1。
- 針對 SLES 15/15 SP1,版本必須至少為 resource-agents-4.3.0184.6ee15eb2-4.13.1。
請注意,變更將會需要短暫的停機。
針對現有的 Pacemaker 叢集,若設定已按照 Azure Load Balancer 偵測強化中的描述變更為使用 socat,則沒有立即切換至 azure-lb 資源代理程式的需求。
[1] IBM Db2 HADR 特定的 Pacemaker 設定:
# Put Pacemaker into maintenance mode sudo crm configure property maintenance-mode=true[1] 建立 IBM Db2 資源:
# Replace **bold strings** with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo crm configure primitive rsc_Db2_db2ptr_PTR db2 \ params instance="db2ptr" dblist="PTR" \ op start interval="0" timeout="130" \ op stop interval="0" timeout="120" \ op promote interval="0" timeout="120" \ op demote interval="0" timeout="120" \ op monitor interval="30" timeout="60" \ op monitor interval="31" role="Master" timeout="60" # Configure virtual IP - same as Azure Load Balancer IP sudo crm configure primitive rsc_ip_db2ptr_PTR IPaddr2 \ op monitor interval="10s" timeout="20s" \ params ip="10.100.0.10" # Configure probe port for Azure load Balancer sudo crm configure primitive rsc_nc_db2ptr_PTR azure-lb port=62500 \ op monitor timeout=20s interval=10 sudo crm configure group g_ip_db2ptr_PTR rsc_ip_db2ptr_PTR rsc_nc_db2ptr_PTR sudo crm configure ms msl_Db2_db2ptr_PTR rsc_Db2_db2ptr_PTR \ meta target-role="Started" notify="true" sudo crm configure colocation col_db2_db2ptr_PTR inf: g_ip_db2ptr_PTR:Started msl_Db2_db2ptr_PTR:Master sudo crm configure order ord_db2_ip_db2ptr_PTR inf: msl_Db2_db2ptr_PTR:promote g_ip_db2ptr_PTR:start sudo crm configure rsc_defaults resource-stickiness=1000 sudo crm configure rsc_defaults migration-threshold=5000[1] 啟動 IBM Db2 資源:
讓 Pacemaker 脫離維護模式。
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo crm configure property maintenance-mode=false[1] 請確定叢集狀態正常,且所有資源皆已啟動。 資源在哪一個節點上執行並不重要。
sudo crm status # 2 nodes configured # 5 resources configured # Online: [ azibmdb01 azibmdb02 ] # Full list of resources: # stonith-sbd (stonith:external/sbd): Started azibmdb02 # Resource Group: g_ip_db2ptr_PTR # rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02 # rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02 # Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR] # Masters: [ azibmdb02 ] # Slaves: [ azibmdb01 ]
重要
您必須使用 Pacemaker 工具來管理 Pacemaker 叢集 Db2 執行個體。 如果您使用 db2stop 之類的 db2 命令,Pacemaker 會將動作偵測為資源失敗。 如果您正在執行維護,您可以將節點或資源置於維護模式。 Pacemaker 會暫停監視資源,然後您可以使用一般的 db2 管理命令。
變更 SAP 設定檔以使用虛擬 IP 進行連線
若要連線到 HADR 設定的主要執行個體,SAP 應用程式層必須使用您為 Azure Load Balancer 定義和設定的虛擬 IP 位址。 需要進行下列變更:
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
安裝主要和對話方塊應用程式伺服器
在針對 Db2 HADR 設定安裝主要和對話方塊應用程式伺服器時,請使用您為設定挑選的虛擬主機名稱。
如果您在建立 Db2 HADR 設定之前執行安裝,請依照上一節所述進行變更,並依照 SAP Java 堆疊的指示進行變更。
ABAP+Java 或 Java 堆疊系統 JDBC URL 檢查
使用 J2EE 設定工具來檢查或更新 JDBC URL。 因為 J2EE 設定工具是圖形化工具,所以您必須安裝 X 伺服器:
登入 J2EE 執行個體的主要應用程式伺服器,然後執行:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.sh在左側框架中,選擇 [安全性存放區]。
在右側框架中,選擇主要 jdbc/pool/SAPSID<>/url。
將 JDBC URL 中的主機名稱變更為虛擬主機名稱。
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0選取 [新增]。
若要儲存變更,請選取左上方的磁碟圖示。
關閉設定工具。
重新啟動 Java 執行個體。
設定 HADR 設定的記錄封存
若要設定 HADR 設定的 Db2 記錄封存,建議您將主要資料庫和待命資料庫設為可從所有記錄封存位置進行自動記錄擷取。 主要和待命資料庫必須能夠從可能會封存記錄檔案的任一資料庫執行個體的所有記錄封存位址來擷取記錄封存檔案。
只有主要資料庫才會執行記錄封存。 如果您變更資料庫伺服器的 HADR 角色,或發生失敗,新主要資料庫會負責記錄封存。 如果您已設定多個記錄封存位置,您的記錄可能會封存兩次。 如果發生本機或遠端追補,您可能也必須手動將封存的記錄從舊主要伺服器複製到新主要伺服器的作用中記錄位置。
建議您設定一個共通的 NFS 共用,從兩個節點寫入記錄。 NFS 共用必須具有高可用性。
您可以針對傳輸或設定檔目錄使用現有的高可用性 NFS 共用。 如需詳細資訊,請參閱
- SUSE Linux Enterprise Server 上 Azure VM 的 NFS 高可用性 (部分機器翻譯)。
- 針對 SAP 應用程式使用 Azure NetApp Files 在 SUSE Linux Enterprise Server 上的 Azure VM 達到 SAP NetWeaver 高可用性 (部分機器翻譯)。
- Azure NetApp 檔案 (以建立 NFS 共用)。
測試叢集設定
本節說明如何測試您的 Db2 HADR 設定。 每個測試皆假設您以使用者根身分登入,而且 IBM Db2 主要資料庫是在 azibmdb01 虛擬機器上執行。
這裡說明所有測試案例的初始狀態:(crm_mon -r 或 crm status)
- crm status 是執行時 Pacemaker 狀態的快照集。
- crm_mon -r 是 Pacemaker 狀態的連續輸出。
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Stopped
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Stopped
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
rsc_Db2_db2ptr_PTR (ocf::heartbeat:db2): Promoting azibmdb01
Slaves: [ azibmdb02 ]
SAP 系統中的原始狀態記錄在 [交易 DBACOCKPIT] > [設定] > [概觀] 中,如下圖所示:
測試接管 IBM Db2
重要
開始測試之前,請確定:
Pacemaker 沒有任何失敗的動作 (crm 狀態)。
沒有位置限制 (移轉測試的剩餘物)。
IBM Db2 HADR 同步處理正在運作中。 檢查使用者 db2<sid>
db2pd -hadr -db <DBSID>
藉由執行下列命令,移轉執行主要 Db2 資料庫的節點:
crm resource migrate msl_Db2_db2ptr_PTR azibmdb02
移轉完成後,crm 狀態輸出看起來如下所示:
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb02 ]
Slaves: [ azibmdb01 ]
SAP 系統中的原始狀態記錄在 [交易 DBACOCKPIT] > [設定] > [概觀] 中,如下圖所示:
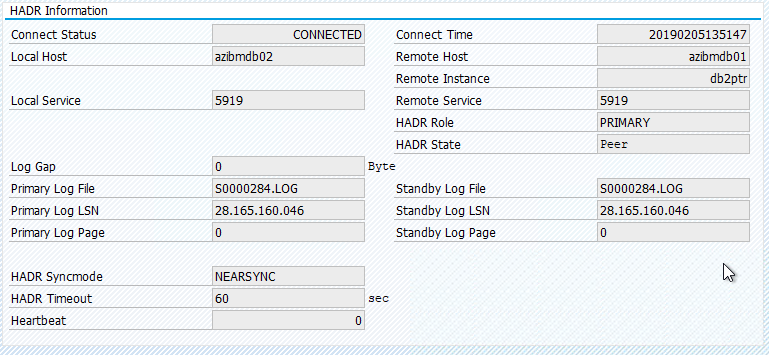
使用 "crm resource migrate" 的資源移轉會建立位置限制式。 應該篩除位置限制式。 如果未刪除位置限制,資源就無法容錯回復,或者您可能會遇到不必要的接管。
將資源移轉回 azibmdb01,並清除位置限制
crm resource migrate msl_Db2_db2ptr_PTR azibmdb01
crm resource clear msl_Db2_db2ptr_PTR
- crm resource migrate <res_name><host>:建立位置限制,並可能會造成接管問題
- crm resource clear <res_name>:清除位置限制式
- crm resource cleanup <res_name>:清除資源的所有錯誤
測試 SBD 隔離
在此情況下,我們會測試 SBD 隔離,建議您在使用 SUSE Linux 時這麼做。
azibmdb01:~ # ps -ef|grep sbd
root 2374 1 0 Feb05 ? 00:00:17 sbd: inquisitor
root 2378 2374 0 Feb05 ? 00:00:40 sbd: watcher: /dev/disk/by-id/scsi-36001405fbbaab35ee77412dacb77ae36 - slot: 0 - uuid: 27cad13a-0bce-4115-891f-43b22cfabe65
root 2379 2374 0 Feb05 ? 00:01:51 sbd: watcher: Pacemaker
root 2380 2374 0 Feb05 ? 00:00:18 sbd: watcher: Cluster
azibmdb01:~ # kill -9 2374
應該重新啟動叢集節點 azibmdb01。 IBM Db2 主要 HADR 角色會移至 azibmdb02。 當 azibmdb01 重新上線時,Db2 執行個體會在次要資料庫執行個體的角色中移動。
如果 Pacemaker 服務未在重新啟動的先前主要資料庫上自動啟動,請務必以下列方式手動啟動:
sudo service pacemaker start
測試手動接管
您可以藉由停止 azibmdb01 節點上的 Pacemaker 服務,測試手動接管:
service pacemaker stop
azibmdb02 上的狀態
2 nodes configured
5 resources configured
Online: [ azibmdb02 ]
OFFLINE: [ azibmdb01 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb02 ]
Stopped: [ azibmdb01 ]
容錯移轉之後,您可以在 azibmdb01 上重新啟動服務。
service pacemaker start
在執行 HADR 主要資料庫的節點上終止 Db2 程序
#Kill main db2 process - db2sysc
azibmdb01:~ # ps -ef|grep db2s
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
azibmdb01:~ # kill -9 34598
Db2 執行個體即將失敗,Pacemaker 將會報告下列狀態:
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Stopped
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Stopped
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Slaves: [ azibmdb02 ]
Stopped: [ azibmdb01 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_demote_0 on azibmdb01 'unknown error' (1): call=157, status=complete, exitreason='',
last-rc-change='Tue Feb 12 14:28:19 2019', queued=40ms, exec=223ms
Pacemaker 會在相同的節點上重新啟動 Db2 主要資料庫執行個體,或容錯移轉至執行次要資料庫執行個體的節點,並回報錯誤。
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb01 ]
Slaves: [ azibmdb02 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_demote_0 on azibmdb01 'unknown error' (1): call=157, status=complete, exitreason='',
last-rc-change='Tue Feb 12 14:28:19 2019', queued=40ms, exec=223ms
在執行次要資料庫執行個體的節點上終止 Db2 程序
azibmdb02:~ # ps -ef|grep db2s
db2ptr 65250 65248 0 Feb11 ? 00:09:27 db2sysc 0
azibmdb02:~ # kill -9
節點進入失敗狀態,並回報錯誤
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
rsc_Db2_db2ptr_PTR (ocf::heartbeat:db2): FAILED azibmdb02
Masters: [ azibmdb01 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_monitor_30000 on azibmdb02 'not running' (7): call=144, status=complete, exitreason='',
last-rc-change='Tue Feb 12 14:36:59 2019', queued=0ms, exec=0ms
Db2 執行個體會在之前指派的次要角色中重新啟動。
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb01 ]
Slaves: [ azibmdb02 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_monitor_30000 on azibmdb02 'not running' (7): call=144, status=complete, exitreason='',
last-rc-change='Tue Feb 12 14:36:59 2019', queued=0ms, exec=0ms
在執行 HADR 主要資料庫執行個體的節點上,透過 db2stop force 強制停止資料庫
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb01 ]
Slaves: [ azibmdb02 ]
當使用者 db2<sid> 強制執行命令 db2stop 時:
azibmdb01:~ # su - db2ptr
azibmdb01:db2ptr> db2stop force
偵測到失敗
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Stopped
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Stopped
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
rsc_Db2_db2ptr_PTR (ocf::heartbeat:db2): FAILED azibmdb01
Slaves: [ azibmdb02 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_demote_0 on azibmdb01 'unknown error' (1): call=201, status=complete, exitreason='',
last-rc-change='Tue Feb 12 14:45:25 2019', queued=1ms, exec=150ms
Db2 HADR 次要資料庫執行個體已晉升為主要角色。
nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb01
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb02 ]
Stopped: [ azibmdb01 ]
Failed Actions:
* rsc_Db2_db2ptr_PTR_start_0 on azibmdb01 'unknown error' (1): call=205, stat
us=complete, exitreason='',
last-rc-change='Tue Feb 12 14:45:27 2019', queued=0ms, exec=865ms
在執行 HADR 主要資料庫執行個體的節點上重新啟動損毀的 VM
#Linux kernel panic - with OS restart
azibmdb01:~ # echo b > /proc/sysrq-trigger
Pacemaker 會將次要執行個體升階至主要執行個體個體。 在虛擬機器重新啟動之後,舊的主要執行個體會在虛擬機器和所有服務完全還原之後,移至次要角色。
nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb01 ]
Slaves: [ azibmdb02 ]
透過 "halt" (終止) 讓執行 HADR 主要資料庫執行個體的虛擬機器損毀
#Linux kernel panic - halts OS
azibmdb01:~ # echo b > /proc/sysrq-trigger
在此情況下,Pacemaker 會偵測執行主要資料庫執行個體未回應的節點。
2 nodes configured
5 resources configured
Node azibmdb01: UNCLEAN (online)
Online: [ azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb01
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb01
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb01 ]
Slaves: [ azibmdb02 ]
下一個步驟是檢查「核心分裂」情況。 在存留的節點確定上次執行主要資料庫執行個體的節點已關閉之後,就會執行資源的容錯移轉。
2 nodes configured
5 resources configured
Online: [ azibmdb02 ]
OFFLINE: [ azibmdb01 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb02 ]
Stopped: [ azibmdb01 ]
如果節點發生「終止」,則必須透過 Azure 管理工具 (在 Azure 入口網站、PowerShell 或 Azure CLI 中) 重新啟動失敗的節點。 在失敗的節點重新上線之後,它會將 Db2 執行個體啟動至次要角色。
2 nodes configured
5 resources configured
Online: [ azibmdb01 azibmdb02 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started azibmdb02
Resource Group: g_ip_db2ptr_PTR
rsc_ip_db2ptr_PTR (ocf::heartbeat:IPaddr2): Started azibmdb02
rsc_nc_db2ptr_PTR (ocf::heartbeat:azure-lb): Started azibmdb02
Master/Slave Set: msl_Db2_db2ptr_PTR [rsc_Db2_db2ptr_PTR]
Masters: [ azibmdb02 ]
Slaves: [ azibmdb01 ]