使用星雲提升檢查點速度並降低成本
瞭解如何使用星雲提升檢查點速度,並降低大型 Azure 機器學習 定型模型的檢查點成本。
概觀
Nebula 是適用於 PyTorch 的 Azure 容器中快速、簡單、無磁碟的模型感知檢查點工具。 Nebula 針對使用 PyTorch 的分散式大規模模型定型作業,提供簡單的高速檢查點解決方案。 藉由利用最新的分散式計算技術,星雲可以將檢查點時間從小時減少到秒,可能節省 95% 到 99.9% 的時間。 大規模訓練工作可以從星雲的表現中獲益匪淺。
若要讓 Nebula 可供您的定型作業使用,請在腳本中匯 nebulaml 入 Python 套件。 星雲與不同的分散式 PyTorch 訓練策略完全相容,包括 PyTorch Lightning、DeepSpeed 等等。 星雲 API 提供簡單的方法來監視和檢視檢查點生命週期。 API 支援各種模型類型,並確保檢查點一致性和可靠性。
重要
公用 nebulaml PyPI Python 套件索引上無法使用套件。 它僅適用於 Azure 機器學習 上適用於 PyTorch 的 Azure 容器 (ACPT) 策劃環境。 若要避免問題,請勿嘗試從 PyPI 安裝 nebulaml 或使用 pip 命令。
在本檔中,您將瞭解如何在 Azure 上搭配 ACPT 使用 Nebula 機器學習,以快速檢查模型定型作業。 此外,您將瞭解如何檢視及管理星雲檢查點數據。 如果 Azure 機器學習 中斷、失敗或終止,您也將瞭解如何從最後一個可用的檢查點繼續模型定型作業。
大型模型定型的檢查點優化為何很重要
隨著數據磁碟區成長,數據格式變得更加複雜,機器學習模型也變得更加複雜。 由於 GPU 記憶體容量限制和冗長的定型時間,定型這些複雜模型可能會很困難。 因此,使用大型數據集和複雜模型時,通常會使用分散式定型。 不過,分散式架構可能會發生非預期的錯誤和節點失敗,當機器學習模型中的節點數目增加時,可能會越來越有問題。
檢查點可藉由定期在指定時間儲存完整模型狀態的快照集,來協助減輕這些問題。 發生失敗時,此快照集可用來在快照集時將模型重建至其狀態,以便從該點繼續定型。
當大型模型定型作業發生失敗或終止時,數據科學家和研究人員可以從先前儲存的檢查點還原定型程式。 不過,檢查點和終止之間的任何進度都會遺失,因為必須重新執行計算,才能復原未儲存的中繼結果。 較短的檢查點間隔有助於降低此損失。 此圖說明從檢查點到終止定型程式之間浪費的時間:

不過,儲存檢查點本身的程式可能會產生顯著的額外負荷。 儲存 TB 大小的檢查點通常會成為定型程式中的瓶頸,同步檢查點程式會封鎖訓練數小時。 平均而言,檢查點相關的額外負荷可以佔訓練時間總數的 12%,而且可以上升到高達 43%(Maeng 等人,2021 年)。
總結來說,大型模型檢查點管理牽涉到大量的記憶體,以及作業復原時間的額外負荷。 頻繁的檢查點儲存,加上從最新的可用檢查點恢復訓練作業,成為一個很大的挑戰。
星雲到救援
若要有效地定型大型分散式模型,請務必有可靠且有效率的方式來儲存和繼續定型進度,以將數據遺失和浪費資源降到最低。 星雲藉由提供更快速且更簡單的檢查點管理,協助減少大型模型 Azure 機器學習 定型作業的檢查點節省時間和 GPU 時數需求。
使用星雲,您可以:
使用簡單的 API,以異步方式搭配定型程式,提升檢查點速度高達 1000 倍 。 星雲可以將檢查點時間從小時減少到秒,可能減少 95% 到 99%。
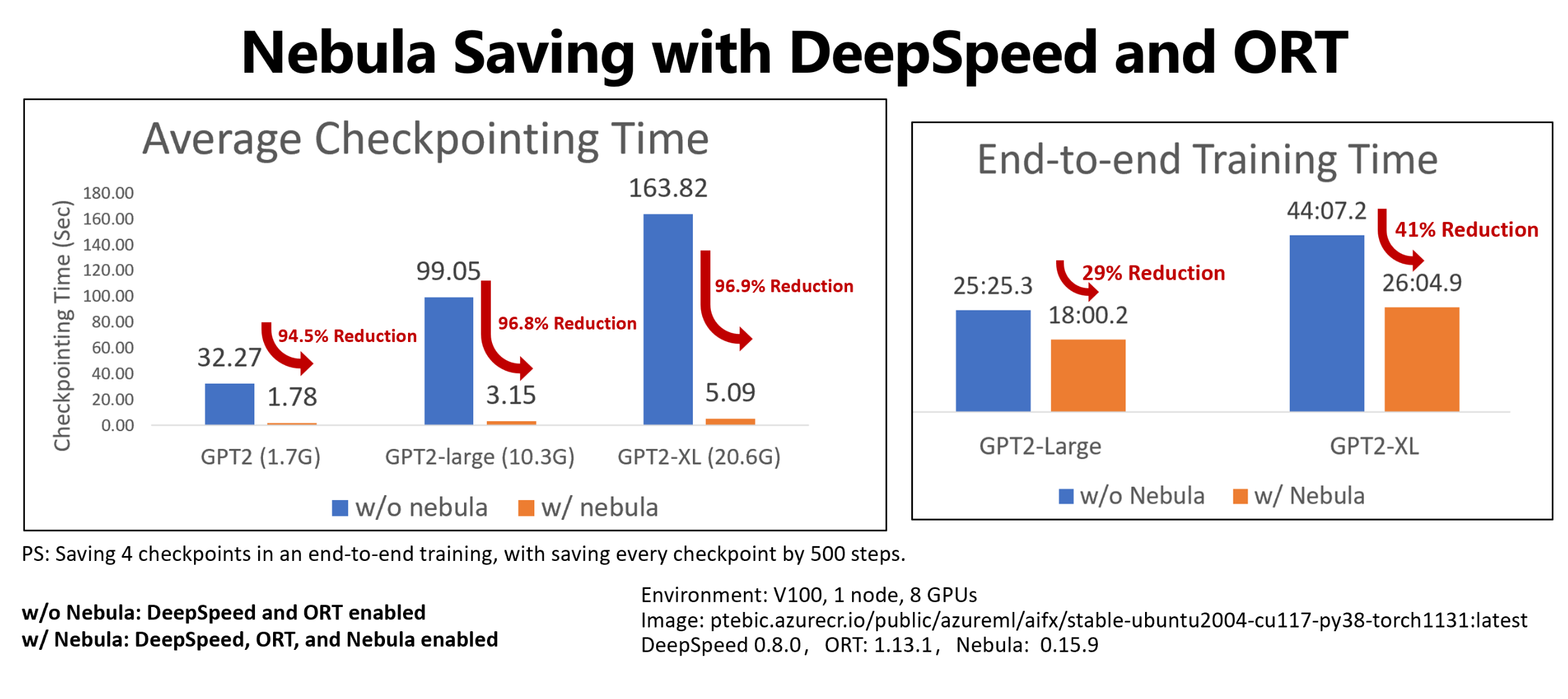
此範例顯示四個檢查點的檢查點和端對端訓練時間減少,可節省擁抱臉部 GPT2、GPT2-Large 和 GPT-XL 訓練作業。 對於中型擁抱臉部 GPT2-XL 檢查點節省 (20.6 GB), 星雲達到 96.9% 的時間減少一個檢查點。
檢查點速度提升仍然可以隨著模型大小和 GPU 數位而增加。 例如,在 128 A100 Nvidia GPU 上測試定型點檢查點儲存 97 GB,可以從 20 分鐘縮減到 1 秒。
減少大型模型的 端對端定型時間和計算成本,方法是將檢查點額外負荷降至最低,並減少在作業復原時浪費的 GPU 時數。 星雲會以異步方式儲存檢查點,並解除封鎖定型程式,以壓縮端對端定型時間。 它也允許更頻繁的檢查點儲存。 如此一來,您就可以在任何中斷之後,從最新的檢查點繼續訓練,並節省工作復原和 GPU 訓練時所浪費的時間和金錢。
提供與 PyTorch 的完整相容性。 Nebula 提供與 PyTorch 的完整相容性,並提供與分散式訓練架構的完整整合,包括 DeepSpeed (>=0.7.3),以及 PyTorch Lightning (>=1.5.0)。 您也可以將它與不同的 Azure 機器學習 計算目標搭配使用,例如 Azure 機器學習 Compute 或 AKS。
使用 Python 套件輕鬆管理檢查點 ,以協助列出、取得、儲存和載入檢查點。 為了顯示檢查點生命週期,星雲也會在 Azure Machine Learning 工作室 上提供完整的記錄。 您可以選擇將檢查點儲存到本機或遠端儲存位置
- Azure Blob 儲存體
- Azure Data Lake Storage
- NFS
並隨時使用幾行程式代碼加以存取。

必要條件
- Azure 訂用帳戶和 Azure 機器學習 工作區。 如需建立工作區資源的詳細資訊,請參閱建立工作區資源
- Azure 機器學習 計算目標。 請參閱 管理定型 和部署計算,以深入了解計算目標建立
- 使用 PyTorch 的定型腳本。
- ACPT 策劃的 (適用於 PyTorch 的 Azure 容器) 環境。 請參閱 策展環境 以取得 ACPT 映像。 瞭解如何 使用策劃的環境
如何使用星雲
星雲提供快速、輕鬆的檢查點體驗,直接在您的現有定型腳本中。 快速入門星雲的步驟包括:
使用 ACPT 環境
適用於 PyTorch 的 Azure 容器 (ACPT)是 PyTorch 模型定型的策劃環境,包含 Nebula 作為預安裝相依 Python 套件。 請參閱適用於 PyTorch 的 Azure 容器 (ACPT) 以檢視策劃的環境,以及在 Azure 機器學習 中使用適用於 PyTorch 的 Azure 容器啟用深度學習,以深入瞭解 ACPT 映射。
初始化星雲
若要使用 ACPT 環境啟用 Nebula,您只需要修改訓練腳本以匯 nebulaml 入套件,然後在適當的位置呼叫 Nebula API。 您可以避免 Azure 機器學習 SDK 或 CLI 修改。 您也可以避免修改其他步驟,以在 Azure 機器學習 平臺上定型大型模型。
星雲需要在定型腳本中執行初始化。 在初始化階段,指定決定檢查點儲存位置和頻率的變數,如下列代碼段所示:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
星雲已整合到 DeepSpeed 和 PyTorch 閃電中。 因此,初始化變得簡單易懂。 這些 範例 示範如何將星雲整合到您的訓練腳本中。
重要
使用星雲儲存檢查點需要一些記憶體來儲存檢查點。 請確定您的記憶體大於檢查點的至少三個複本。
如果記憶體不足以保存檢查點,建議您在命令中設定環境變數 NEBULA_MEMORY_BUFFER_SIZE ,以在儲存檢查點時限制每個節點的記憶體使用量。 設定此變數時,Nebula 會使用此記憶體作為緩衝區來儲存檢查點。 如果記憶體使用量不受限制,星雲會盡可能使用記憶體來儲存檢查點。
如果多個進程在同一個節點上執行,儲存檢查點的最大記憶體將會是限制的一半除以進程數目。 星雲將使用另一半進行多進程協調。 例如,如果您想要將每個節點的記憶體使用量限製為 200MB,您可以在 命令中將環境變數設定為 export NEBULA_MEMORY_BUFFER_SIZE=200000000 (位元元組,約 200 MB)。 在此情況下,Nebula 只會使用 200 MB 記憶體來儲存每個節點中的檢查點。 如果在同一節點上執行 4 個進程,則 Nebula 會為每個進程使用 25 MB 的記憶體來儲存檢查點。
呼叫 API 以儲存和載入檢查點
星雲提供 API 來處理檢查點儲存。 您可以在定型腳本中使用這些 API,類似於 PyTorch torch.save() API。 這些 範例 示範如何在定型腳本中使用Nebula。
檢視檢查點歷程記錄
當您的訓練作業完成時,請流覽至 [作業 Name> Outputs + logs ] 窗格。 在左面板中,展開 [星雲] 資料夾,然後選取checkpointHistories.csv以查看星雲檢查點儲存的詳細資訊 - 持續時間、輸送量和檢查點大小。

範例
這些範例示範如何搭配不同的架構類型使用Nebula。 您可以選擇最符合定型腳本的範例。
若要啟用與 PyTorch 型訓練腳本的完整 Nebula 相容性,請視需要修改您的定型腳本。
首先,匯入必要的
nebulaml套件:# Import the Nebula package for fast-checkpointing import nebulaml as nm若要初始化 Nebula,請在 中
main()呼叫 函nm.init()式,如下所示:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)若要儲存檢查點,請取代原始
torch.save()語句,以將檢查點儲存為星雲。 請確定您的檢查點實例開頭為 「global_step」,例如 「global_step500」 或 「global_step1000」:checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)注意
<'CKPT_TAG_NAME'>是檢查點的唯一標識碼。 標籤通常是步驟數目、epoch 編號或任何使用者定義的名稱。 選擇性的選擇性<'NUM_OF_FILES'>參數會指定您要為這個標籤儲存的狀態號碼。載入最新的有效檢查點,如下所示:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)由於檢查點或快照集可能包含許多檔案,因此您可以依名稱載入一或多個檔案。 使用最新的檢查點,定型狀態可以還原到最後一個檢查點所儲存的狀態。
其他 API 可以處理檢查點管理
- 列出所有檢查點
- 取得最新的檢查點
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)