使用變體調整提示
製作良好的提示是一項具有挑戰性的工作,需要大量的創意、清晰度和相關性。 良好的提示會從預先定型的語言模型引發所需的輸出,而不正確的提示會導致不正確、不相關或無意義的輸出。 因此必須調整提示,以針對不同的工作和領域最佳化其效能和健全性。
因此,我們會介紹變體的概念,其可協助您在不同條件下測試模型的行為,例如不同的措辭、格式、內容、溫度或 top-k,比較並找出最佳提示和設定,以最大化模型的正確性、多樣性或連貫性。
在本文中,我們將會示範如何使用變體來調整提示,並評估不同變體的效能。
必要條件
閱讀本文之前,最好先進行:
如何使用變體調整提示?
在本文中,我們將會使用 Web 分類範例流程作為範例。
開啟範例流程,並移除 prepare_examples 節點作為起點。
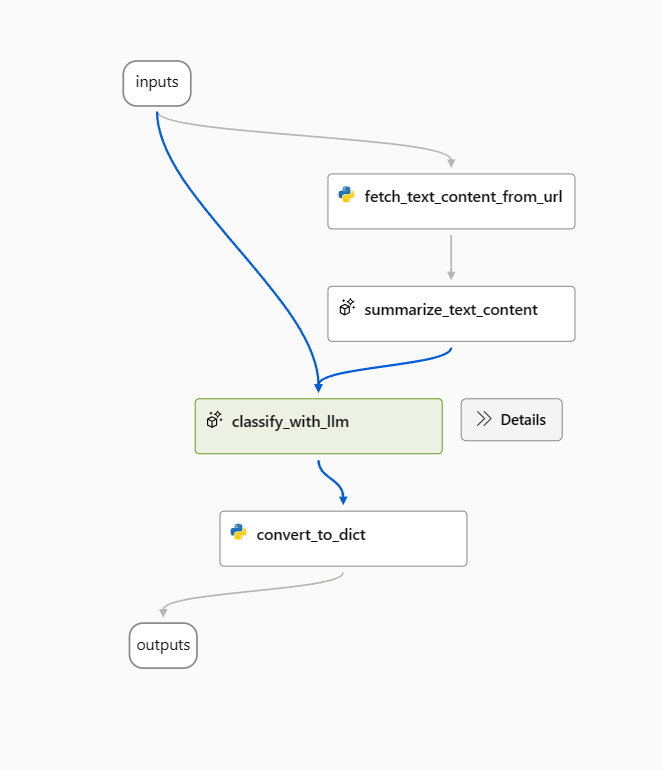
使用下列提示作為 classify_with_llm 節點中的基準提示。

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
若要最佳化此流程,有多種方式,以下是兩個方向:
對於 classify_with_llm 節點:我從社群和論文中了解到,較低的溫度可提供較高的精確度,但創意和驚喜較少,因此較低的溫度適合分類工作,而且小樣本提示可增加 LLM 效能。 因此,我想測試當溫度從 1 變更為 0 時,以及當提示是使用小樣本範例時,我的流程如何運作。
對於 summarize_text_content 節點:當我將摘要從 100 個字組變更為 300 個字組時,我也想要測試流程的行為,以查看更多文字內容是否有助於改善效能。
建立變體
- 選取 LLM 節點右上方的 [顯示變體] 按鈕。 現有的 LLM 節點是 variant_0,而且是預設變體。
- 選取 variant_0 上的 [複製] 按鈕以產生 variant_1,然後您可以將參數設定為不同的值,或更新 variant_1 的提示。
- 重複此步驟以建立更多變體。
- 選取 [隱藏變體] 停止新增更多變體。 所有變體都會摺疊。 系統會顯示節點的預設變體。
對於 classify_with_llm 節點,根據 variant_0:
- 建立 variant_1,其中溫度從 1 變更為 0。
- 建立溫度為 0 的 variant_2,您可以使用下列提示,包括小樣本範例。
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
對於 summarize_text_content 節點,根據 variant_0,您可以建立 variant_1,其中在提示中 100 words 變更為 300 個字組。
現在流程看起來如下,summarize_text_content 節點有 2 個變體,classify_with_llm 節點有 3 個變體。

使用單一資料列執行所有變體,並檢查輸出
若要確定所有變體都能順利執行,並如預期般運作,您可以使用單一資料列來執行流程以進行測試。
注意
您每次只能選取一個具有變體的 LLM 節點來執行,而其他 LLM 節點則會使用預設變體。
在此範例中,我們會設定 summarize_text_content 節點和 classify_with_llm 節點的變體,因此您必須執行兩次來測試所有變體。
- 選取右上方的 [執行] 按鈕。
- 選取具有變體的 LLM 節點。 其他 LLM 節點會使用預設變體。
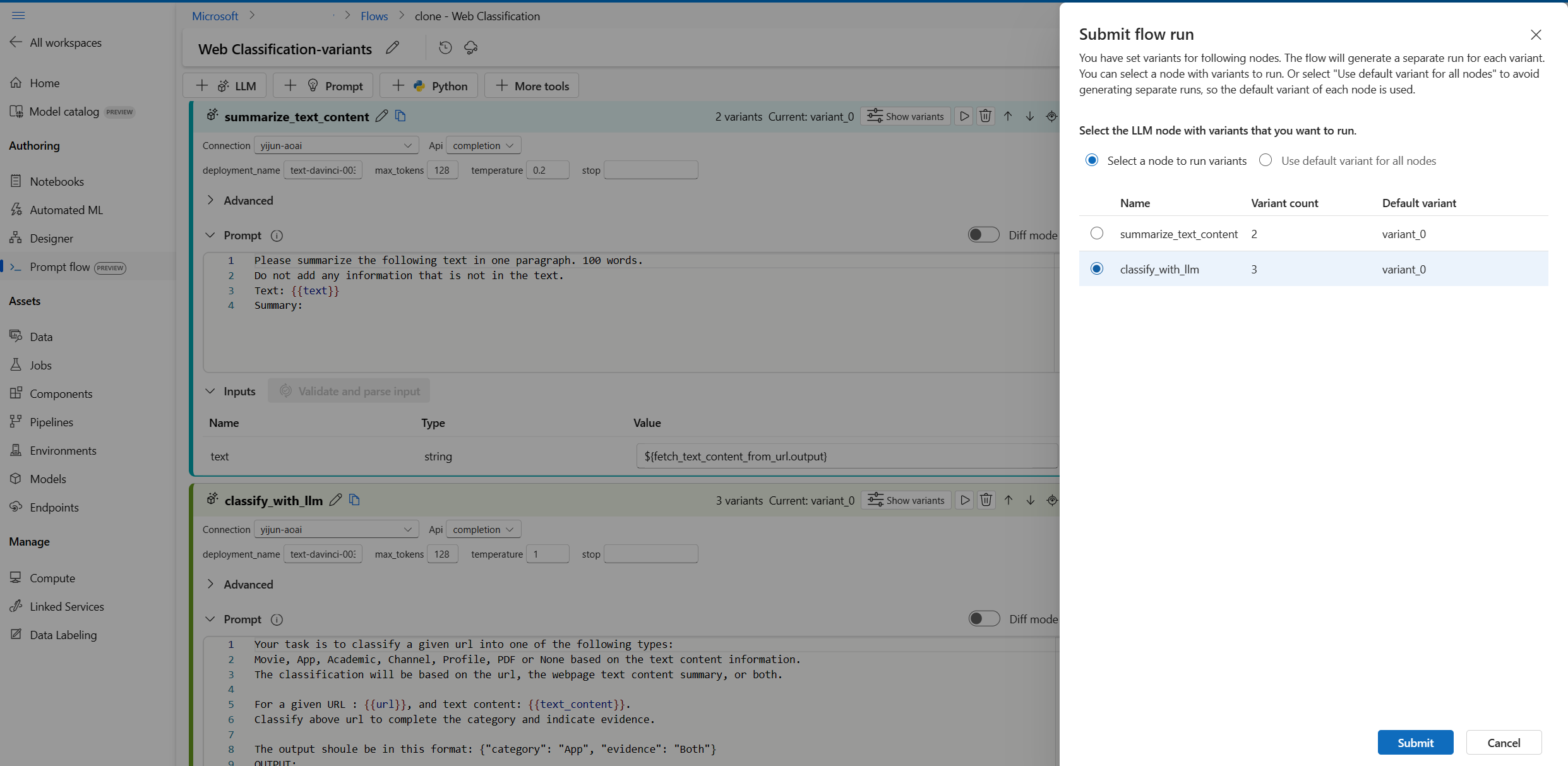
- 提交流程執行。
- 流程執行完成後,您可以檢查每個變體的對應結果。
- 使用其他 LLM 節點與變體提交另一個流程執行,並檢查輸出。
- 您可以變更另一個輸入資料 (例如,使用維基百科頁面 URL),並重複上述步驟來測試不同資料的變體。

評估變體
當您以一些單一資料片段執行變體,並以肉眼檢查結果時,無法反映真實世界資料的複雜性和多樣性,同時輸出無法測量,因此難以比較不同變體的有效性,然後選擇最佳的變體。
您可以提交批次執行,這可讓您測試具有大量資料的變體,並使用計量進行評估,以協助您找到最適合的變體。
首先,您需要準備資料集,這足以代表您想要使用提示流程解決的實際問題。 在此範例中,這是 URL 及其分類有根據事實的清單。 我們將會使用正確性來評估變體的效能。
在頁面右上方選取 [評估]。
[批次執行和評估] 精靈隨即出現。 第一個步驟是選取節點以執行其所有變體。
若要測試不同變體在流程中每個節點的運作程度,您必須針對具有變體的每個節點逐一執行批次執行。 這可協助您避免其他節點變體的影響,並將焦點放在此節點變體的結果上。 這會遵循受控制實驗的規則,這表示您一次只能變更一件事,其他一切項目保持相同。
例如,您可以選取 classify_with_llm 節點來執行所有變體,summarize_text_content 節點將會使用預設變體來進行此批次執行。
接下來在 [批次執行設定] 中,您可以設定批次執行名稱、選擇執行階段、上傳備妥的資料。
接下來在 [評估設定] 中,選取評估方法。
由於此流程適用於分類,因此您可以選取 [分類正確性評估] 方法來評估正確性。
正確性是藉由比較流程指派的預測標籤 (預測) 與資料的實際標籤 (有根據事實) 來計算,並計算其中有多少相符。
在 [評估輸入對應] 區段中,您需要指定有根據事實來自輸入資料集的類別資料行,而預測則來自其中一個流程輸出:類別。
檢閱所有設定之後,您可以提交批次執行。
提交執行之後,選取連結,移至執行詳細資料頁面。
注意
執行可能需要幾分鐘的時間才能完成。
將輸出視覺化
- 批次執行和評估執行完成之後,請在執行詳細資料頁面中,針對每個變體複選批次執行,然後選取 [視覺化輸出]。 您會看到 classify_with_llm 節點 3 個變體的計量,以及每個資料記錄的 LLM 預測輸出。
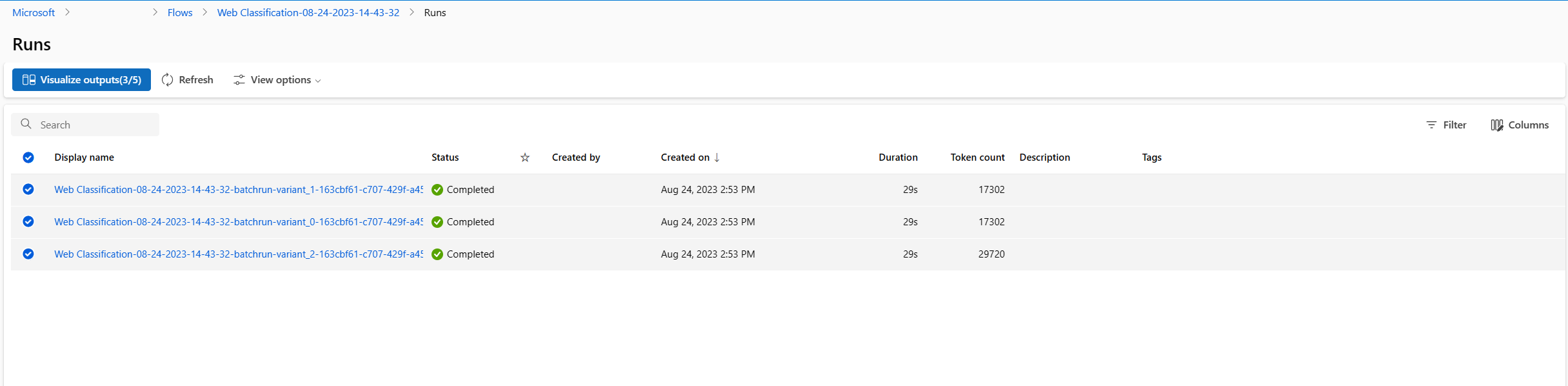
- 識別出哪一個變體是最佳變體之後,您可以回到流程撰寫頁面,並將該變體設定為節點的預設變體
- 您也可以重複上述步驟來評估 summarize_text_content 節點的變體。
現在,您已完成使用變體調整提示的程序。 您可以將這項技術套用至您自己的提示流程,以尋找 LLM 節點的最佳變體。