提交批次執行以評估流程
批次執行會執行具有大型數據集的提示流程,併產生每個數據列的輸出。 若要評估您的提示流程與大型數據集的執行程度,您可以提交批次執行,並使用評估方法來產生效能分數和計量。
批次流程完成之後,評估方法會自動執行以計算分數和計量。 您可以使用評估計量,根據效能準則和目標評估流程的輸出。
本文說明如何提交批次執行,並使用評估方法來測量流程輸出的品質。 您將瞭解如何檢視評估結果和計量,以及如何使用不同的方法或變體子集來開始新一輪的評估。
必要條件
若要使用評估方法執行批次流程,您需要下列元件:
您想要測試效能的工作 Azure 機器學習 提示流程。
要用於批次執行的測試數據集。
您的測試數據集必須是 CSV、TSV 或 JSONL 格式,而且應該具有符合流程輸入名稱的標頭。 不過,您可以在評估回合安裝程序期間,將不同的數據集數據行對應至輸入數據行。
建立和提交評估批次執行
若要提交批次執行,您可以選取要用來測試流程的數據集。 您也可以選取評估方法來計算流程輸出的計量。 如果您不想使用評估方法,您可以略過評估步驟並執行批次執行,而不需要計算任何計量。 您也可以稍後執行評估回合。
若要使用或不使用評估啟動批次執行,請選取 提示流程頁面頂端的 [評估 ]。
在 [Batch 執行和評估精靈] 的 [基本設定] 頁面上,視需要自定義 [執行顯示名稱],並選擇性地提供 [執行描述] 和 [卷標]。 選取 [下一步]。
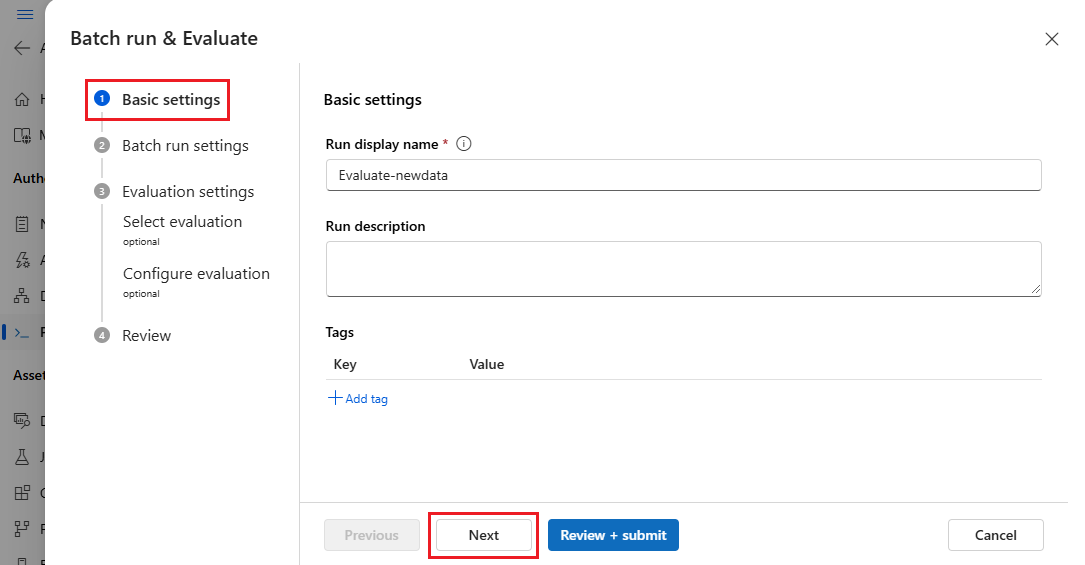
在 [ 批次執行設定 ] 頁面上,選取要使用的數據集並設定輸入對應。
提示流程支援將流程輸入對應至數據集中的特定數據行。 您可以使用 將資料集資料列指派給特定輸入
${data.<column>}。 如果您想要將常數值指派給輸入,您可以直接輸入該值。
此時您可以選取 [ 檢閱 + 提交 ],略過評估步驟並執行批次執行,而不需使用任何評估方法。 然後,批次執行會針對數據集中的每個專案產生個別輸出。 您可以手動檢查輸出,或匯出這些輸出以進行進一步分析。
否則,若要使用評估方法來驗證此執行的效能,請選取 [ 下一步]。 您也可以將新的一輪評估新增至已完成的批次執行。
在 [ 選取評估 ] 頁面上,選取一或多個要執行的自定義或內建評估。 您可以選取 [ 檢視詳細數據 ] 按鈕,以查看評估方法的詳細資訊,例如所產生的計量,以及所需的連接和輸入。
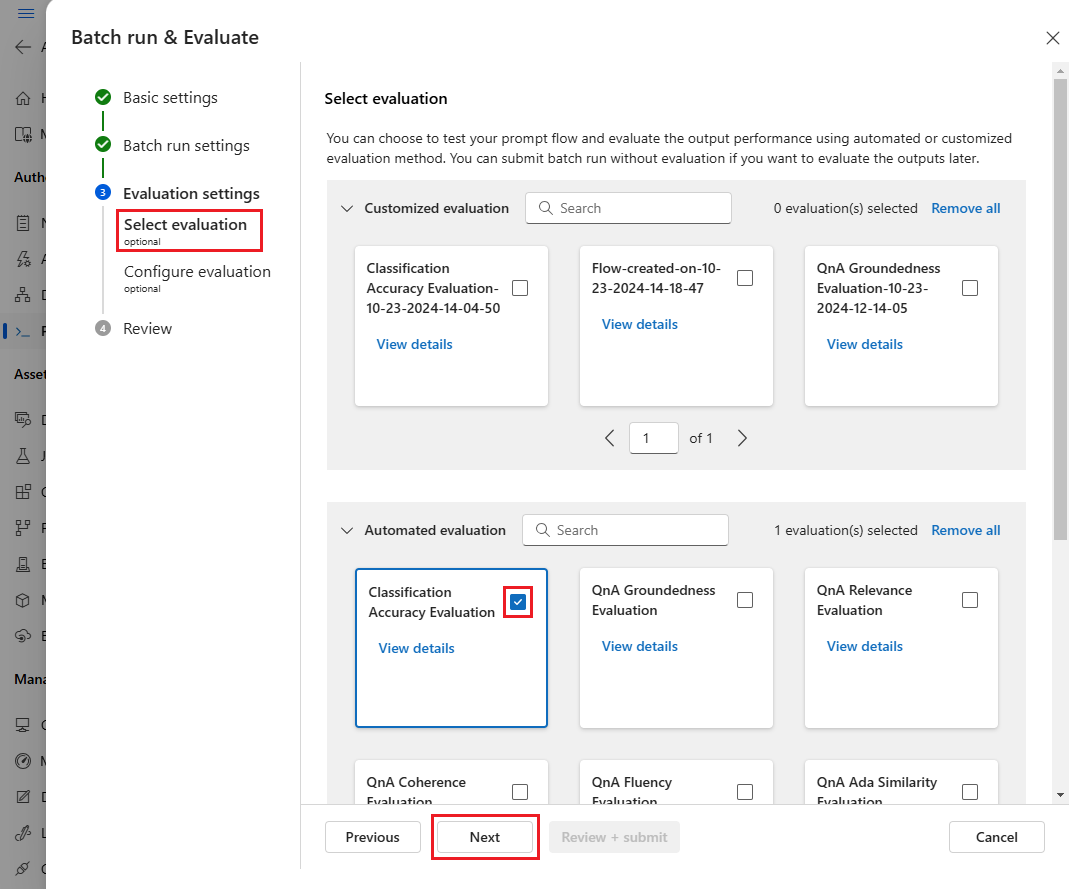
接下來,在 [ 設定評估] 畫面上,指定評估所需的輸入來源。 例如,地面真相數據行可能來自數據集。 根據預設,評估會使用與整體批次執行相同的數據集。 不過,如果對應的標籤或目標地面真值位於不同的數據集中,您可以使用該標籤。
注意
如果您的評估方法不需要數據集的數據,數據集選取是不會影響評估結果的選擇性設定。 您不需要選取數據集,或參考輸入對應區段中的任何數據集數據行。
在 [ 評估輸入對應] 區段中,指出評估所需的輸入來源。
- 如果資料來自測試資料集,請將來源設定為
${data.[ColumnName]}。 - 如果資料來自您的執行輸出,請將來源設定為
${run.outputs.[OutputName]}。
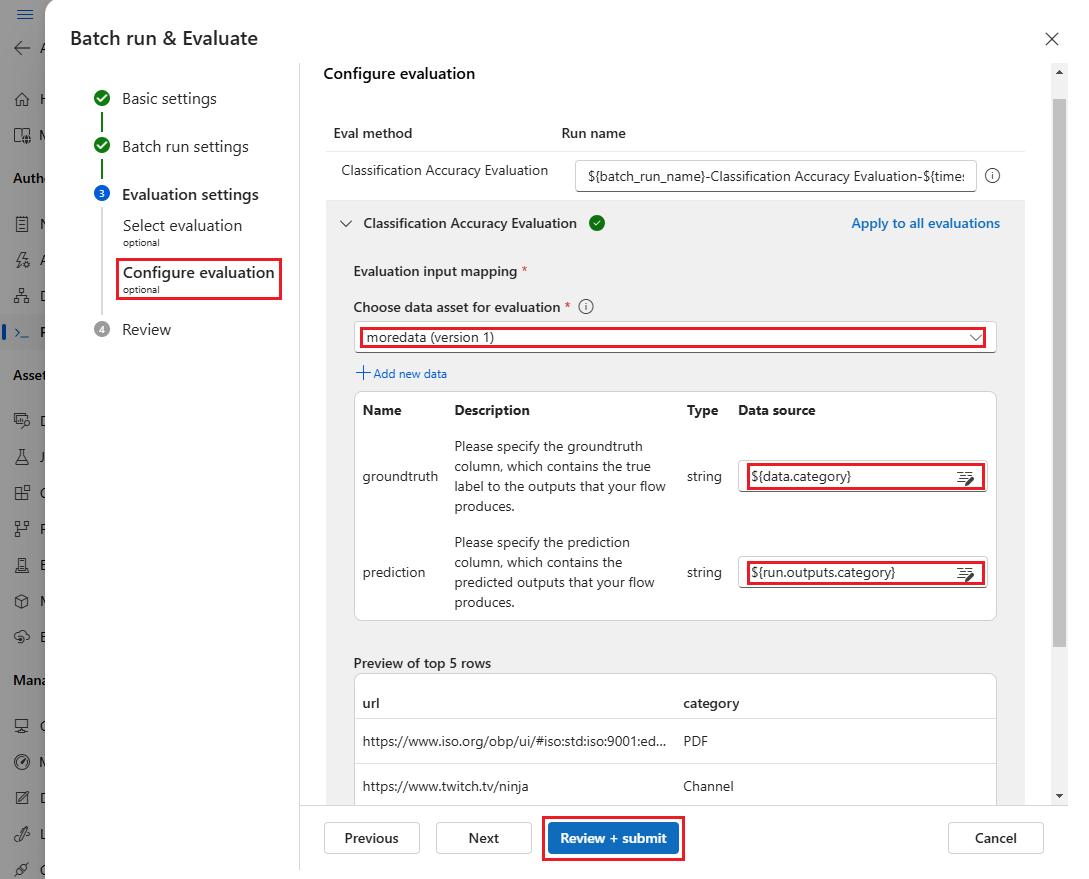
- 如果資料來自測試資料集,請將來源設定為
某些評估方法需要大型語言模型(LLM),例如 GPT-4 或 GPT-3,或需要其他連線來取用認證或密鑰。 針對這些方法,您必須在此畫面底部的 [連線 ] 區段中輸入連線數據,才能使用評估流程。 如需詳細資訊,請參閱 設定連線。

選取 [ 檢閱 + 提交 ] 以檢閱您的設定,然後選取 [ 提交 ] 以啟動批次執行評估。






注意
- 某些評估程式會使用許多令牌,因此建議使用可支援 >=16k 令牌的模型。
- 批次執行的最大持續時間為 10 小時。 如果批次執行超過此限制,則會終止並顯示為失敗。 監視 LLM 容量以避免節流。 如有必要,請考慮減少資料大小。 如果您仍有問題,請提出意見反應窗體或支援要求。
檢視評估結果和計量
您可以在 [Azure Machine Learning 工作室 提示流程] 頁面中的 [執行] 索引標籤上,找到提交的批次執行清單。
若要檢查批次執行的結果,請選取回合,然後選取 [ 可視化輸出]。
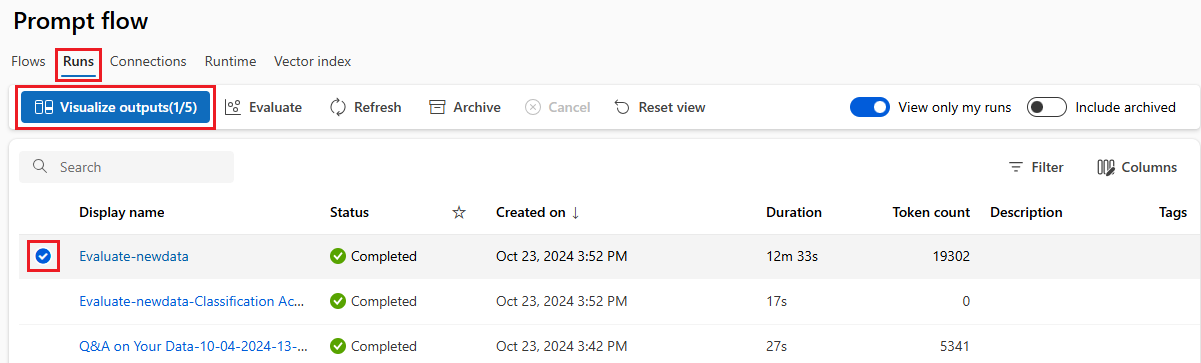
在 [ 可視化輸出] 畫面上,[ 執行和計量 ] 區段會顯示批次執行和評估回合的整體結果。 [輸出] 區段會在結果數據表中逐行顯示執行輸入,其中包含行標識碼、執行、狀態和系統計量。
![您在檢查批次執行輸出的 [輸出] 索引標籤上批次執行結果頁面的螢幕擷取畫面。](media/how-to-bulk-test-evaluate-flow/batch-run-output.png?view=azureml-api-2)
如果您在 [執行和計量] 區段中啟用評估回合旁的 [檢視] 圖示,則 [輸出] 數據表也會顯示每一行的評估分數或成績。
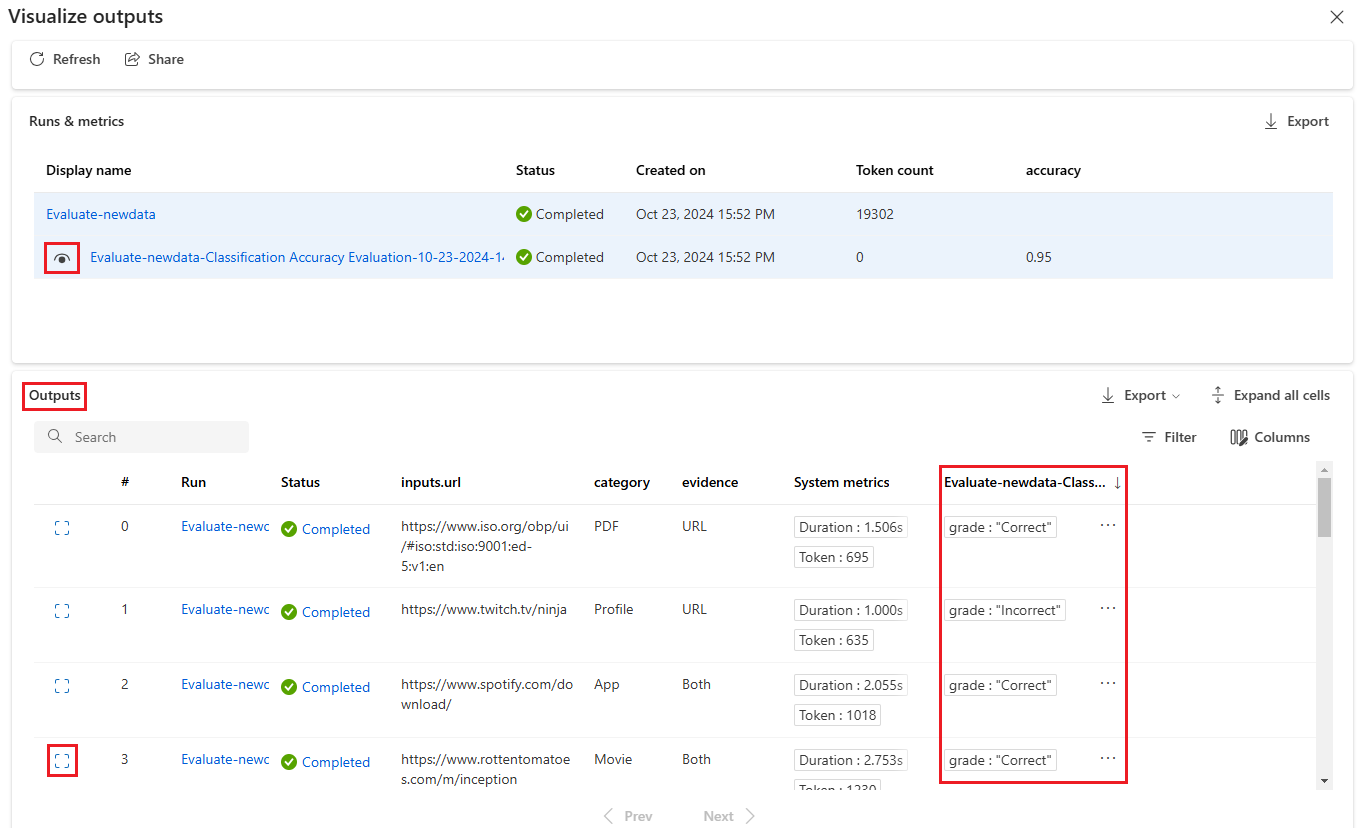
選取 [輸出] 數據表中每一行旁的 [檢視詳細數據] 圖示,以觀察及偵錯該測試案例的追蹤檢視和詳細數據。 追蹤檢視會顯示該案例的令牌數目和持續時間等資訊。 展開並選取任何步驟,以查看 該步驟的概觀 和 輸入 。
![[追蹤] 檢視的螢幕快照,其中已展開的步驟和詳細數據。](media/how-to-bulk-test-evaluate-flow/batch-run-output-new-evaluation.png?view=azureml-api-2)

![您在檢查批次執行輸出的 [輸出] 索引標籤上批次執行結果頁面的螢幕擷取畫面。](media/how-to-bulk-test-evaluate-flow/batch-run-output.png?view=azureml-api-2#lightbox)

![[追蹤] 檢視的螢幕快照,其中已展開的步驟和詳細數據。](media/how-to-bulk-test-evaluate-flow/batch-run-output-new-evaluation.png?view=azureml-api-2#lightbox)
您也可以從您測試的提示流程檢視評估回合結果。 在 [檢視批次執行] 下,選取 [檢視批次執行] 以查看流程的批次執行清單,或選取 [檢視最新的批次執行輸出] 以查看最新執行的輸出。
![Web 分類的螢幕擷取畫面,其中已選取 [檢視大量執行] 按鈕。](media/how-to-bulk-test-evaluate-flow/batch-run-history.png?view=azureml-api-2#lightbox)
在批次執行清單中,選取批次執行名稱以開啟該執行的流程頁面。
在評估執行的流程頁面上,選取 [檢視輸出] 或 [詳細數據] 以查看流程的詳細數據。 您也可以 複製 流程以建立新的流程,或 將其部署 為在線端點。

在 [ 詳細數據] 畫面上:
[概觀] 索引標籤會顯示執行的完整資訊,包括執行屬性、輸入數據集、輸出數據集、標籤和描述。
[ 輸出 ] 索引標籤會顯示頁面頂端的結果摘要,後面接著批次執行結果數據表。 如果您選取 [附加相關結果] 旁的評估回合,數據表也會顯示評估回合結果。
![評估流程詳細數據畫面之 [輸出] 索引標籤的螢幕快照。](media/how-to-bulk-test-evaluate-flow/batch-run-output-overview.png?view=azureml-api-2)
[記錄] 索引標籤會顯示執行記錄,這對於執行錯誤的詳細偵錯很有用。 您可以下載記錄檔。
[ 計量] 索引 標籤提供執行計量的連結。
[追蹤] 索引標籤會顯示詳細資訊,例如每個測試案例的令牌數目和持續時間。 展開並選取任何步驟,以查看 該步驟的概觀 和 輸入 。
[快照集] 索引 標籤 會顯示執行中的檔案和程序代碼。 您可以看到 flow.dag.yaml 流程定義,並下載任何檔案。
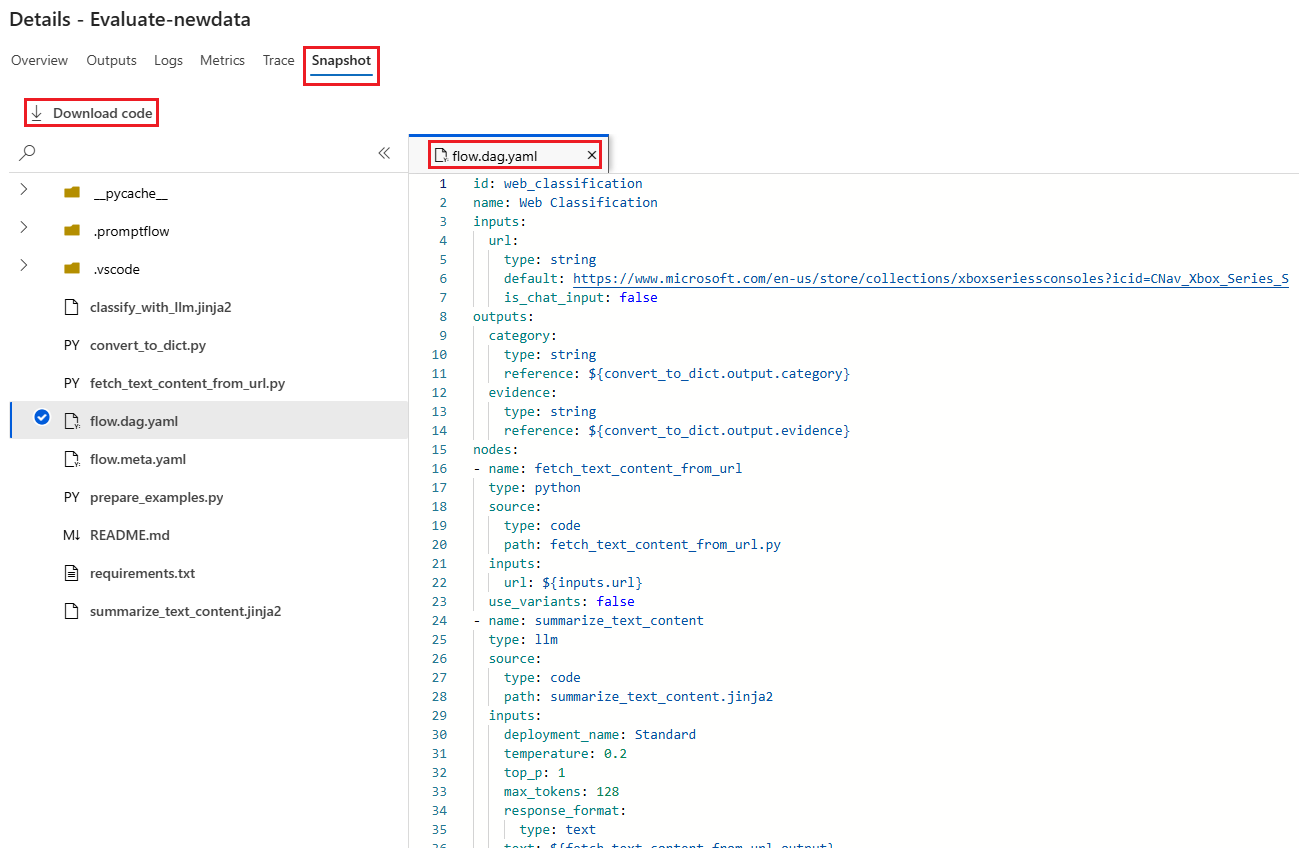
![評估流程詳細數據畫面之 [輸出] 索引標籤的螢幕快照。](media/how-to-bulk-test-evaluate-flow/batch-run-output-overview.png?view=azureml-api-2#lightbox)

針對相同的回合啟動新的評估回合
您可以執行新的評估回合來計算已完成批次執行的計量,而不需再次執行流程。 此程式可節省重新執行流程的成本,而且在下列案例中很有説明:
- 您未在提交批次執行時選取評估方法,現在想要評估執行效能。
- 您已使用評估方法來計算特定計量,現在想要計算不同的計量。
- 您先前的評估執行失敗,但批次執行已成功產生輸出,而您想要再次嘗試評估。
若要開始另一輪評估,請選取 批次執行流程頁面頂端的 [評估 ]。 [新增評估精靈] 隨即開啟至 [選取評估] 畫面。 完成設定並提交新的評估回合。
新的回合會出現在提示流程 [執行 ] 清單中,而您可以在清單中選取多個數據列,然後選取 [ 可視化輸出 ] 來比較輸出和計量。
比較評估執行歷程記錄和計量
如果您修改流程以改善其效能,您可以提交多個批次執行來比較不同流程版本的效能。 您也可以比較不同評估方法所計算的計量,以查看哪一種方法更適合您的流程。
若要檢查您的流程批次執行歷程記錄,請選取 流程頁面頂端的 [檢視批次執行 ]。 您可以選取每個回合來檢查詳細資料。 您也可以選取多個回合,然後選取 [可視化輸出 ] 來比較這些執行的計量和輸出。

瞭解內建評估計量
Azure 機器學習 提示流程提供數個內建評估方法,協助您測量流程輸出的效能。 每個評估方法都會計算不同的計量。 下表描述可用的內建評估方法。
| 評估方法 | 計量 | 描述 | 需要連線嗎? | 必要輸入 | 評分值 |
|---|---|---|---|---|---|
| 分類正確性評估 | 準確率 | 藉由比較分類系統的輸出與地面真相來測量分類系統的效能 | No | 預測,有根據事實 | 範圍 [0, 1] |
| QnA 根據性評估 | 根據性 | 測量模型預測答案在輸入來源中多麼有根據。 即使 LLM 回應正確,如果無法針對來源進行驗證,它們也不會被擱置。 | Yes | 問題、回答,內容 (沒有有根據事實) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA GPT 相似度評估 | GPT 相似度 | 使用 GPT 模型測量使用者提供的地面真相答案與模型預測答案之間的相似度 | Yes | 問題、回答,有根據事實 (不需要內容) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 相關性評估 | 相關性 | 測量模型預測答案與所詢問問題的相關程度 | Yes | 問題、回答,內容 (沒有有根據事實) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 連貫性評估 | 連貫性 | 測量模型預測答案中所有句子的品質,以及它們如何自然地結合在一起 | Yes | 問題、回答 (沒有有根據事實或內容) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 流暢度評估 | 流暢度 | 測量模型預測答案的文法和語言正確性 | Yes | 問題、回答 (沒有有根據事實或內容) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA F1 分數評估 | F1 分數 | 測量模型預測與地面真相之間共用字數的比例 | No | 問題、回答,有根據事實 (不需要內容) | 範圍 [0, 1] |
| QnA Ada 相似度評估 | Ada 相似度 | 使用 Ada 內嵌 API 來計算句子(檔)層級內嵌,以進行地面真相和預測,然後計算它們之間的餘弦相似度(一個浮點數) | Yes | 問題、回答,有根據事實 (不需要內容) | 範圍 [0, 1] |
改善流程效能
如果您的執行失敗,請檢查輸出和記錄數據,並偵錯任何流程失敗。 若要修正流程或改善效能,請嘗試修改流程提示、系統訊息、流程參數或流程邏輯。
提示工程
提示建構可能很困難。 若要瞭解提示建構概念,請參閱 提示概觀。 若要瞭解如何建構可協助達成目標的提示,請參閱 提示工程技術。
系統訊息
您可以使用系統訊息,有時稱為中繼程式或 系統提示,引導 AI 系統的行為並改善系統效能。 若要瞭解如何使用系統訊息改善您的流程效能,請參閱 系統訊息逐步撰寫。
黃金數據集
建立使用 LLM 的 Copilot,通常牽涉到使用來源數據集將模型實作地面。 黃金 數據集 可協助確保 LLM 對客戶查詢提供最精確且實用的回應。
黃金數據集是實際客戶問題和專家製作的解答集合,可作為您共同使用之 LLM 的質量保證工具。 黃金數據集不會用來定型 LLM 或將內容插入 LLM 提示字元,而是用來評估 LLM 所產生的答案品質。
如果您的案例牽涉到 Copilot,或您正在建置自己的 Copilot,請參閱 產生黃金數據集 以取得詳細的指引和最佳做法。