從生產環境中的模型收集資料

本文將說明如何從部署在 Azure Kubernetes Service (AKS) 叢集的 Azure Machine Learning 模型中收集資料。 然後將收集到的資料儲存在 Azure Blob 儲存體中。
啟用收集之後,您收集的資料就可協助您:
使用 Power BI 或 Azure Databricks 分析收集的資料
針對重新訓練或最佳化模型的時機,做出更好的決策。
使用收集的資料重新訓練您的模型。
限制
- 模型資料收集功能只能與 Ubuntu 18.04 映像搭配運作。
重要
自 2023 年 3 月 10 日起,Ubuntu 18.04 映像現已淘汰。 對於 Ubuntu 18.04 映像的支援會從 2023 年 1 月起中止,且其會在 2023 年 4 月 30 日到達 EOL。
MDC 功能與 Ubuntu 18.04 以外的任何映像都不相容,其在 Ubuntu 18.04 映像淘汰後就無法使用。
如需詳細資訊,您可以參閱:
注意
資料收集功能目前處於預覽狀態,不建議將任何預覽功能用於生產工作負載。
收集的內容和儲存位置
下列是可收集的資料:
來自 AKS 叢集中所部署 Web 服務的模型輸入資料。 不會收集語音音訊、影像和影片。
使用生產輸入資料的模型預測。
注意
這項資料的 Preaggregation 和 precalculations 目前不是收集服務的一部分。
輸出會儲存在 Blob 儲存體中。 因為資料會新增至 Blob 儲存體,所以您可以選擇您慣用的工具來執行分析。
Blob 中輸出資料的路徑遵循此語法:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
注意
在適用於 Python 的 Azure Machine Learning SDK 0.1.0a16 版之前,designation 引數稱為 identifier。 如果您使用較早的版本開發程式碼,您必須據以更新。
必要條件
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
您必須安裝 Azure Machine Learning 工作區、包含您指令碼的本機目錄,以及適用於 Python 的 Azure Machine Learning SDK。 若要了解如何安裝,請參閱如何設定開發環境。
您需要已訓練的機器學習模型,以將其部署至 AKS。 如果您沒有模型,請參閱訓練影像分類模型教學課程。
您需要 AKS 叢集。 如需如何建立和部署模型的詳細資訊,請參閱將機器學習模型部署至 Azure。
使用以 Ubuntu 18.04 為基礎的 Docker 映像,此映像隨附於
libssl 1.0.0,這是 modeldatacollector 的基本相依性。 您可以參考預建映像。
啟用資料收集
不論透過 Azure Machine Learning 或其他工具所部署的模型為何,都可以啟用資料收集。
若要啟用資料收集,您需要:
開啟評分檔案。
在檔案的頂端新增下列程式碼:
from azureml.monitoring import ModelDataCollector在
init函式中宣告資料收集變數:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId 是選擇性參數。 如果您的模型不需要,您就無須使用此參數。 使用 CorrelationId 可協助您更輕鬆地與其他資料對應 (例如 LoanNumber 或 CustomerId)。
稍後會使用 Identifier 參數來建立 Blob 中的資料夾結構。 您可以使用此參數來區分未經處理資料與已處理的資料。
將下列程式碼行新增至
run(input_df)函式:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure Blob當您在 AKS 中部署服務時,資料收集不會自動設定為 true。 請更新您的設定檔,如下列範例所示:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)您也可以變更以下設定,以啟用 Application Insights 來監視服務:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)若要建立新的映像並部署機器學習模型,請參閱將機器學習模型部署至 Azure。
將 'Azure-Monitoring' pip 套件新增至 Web 服務環境的 Conda 相依性:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
停用資料收集
您可以隨時停止收集資料。 使用 Python 程式碼來停用資料收集。
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
驗證及分析您的資料
您可以選擇您偏好的工具來分析 Blob 儲存體中收集的資料。
快速存取 Blob 資料
登入 Azure 入口網站。
開啟工作區。
選取儲存體。

遵循使用下列語法的 Blob 輸出資料路徑:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

使用 Power BI 分析模型資料
下載並開啟 Power BI Desktop。
選取 [取得資料],然後選取 Azure Blob 儲存體。
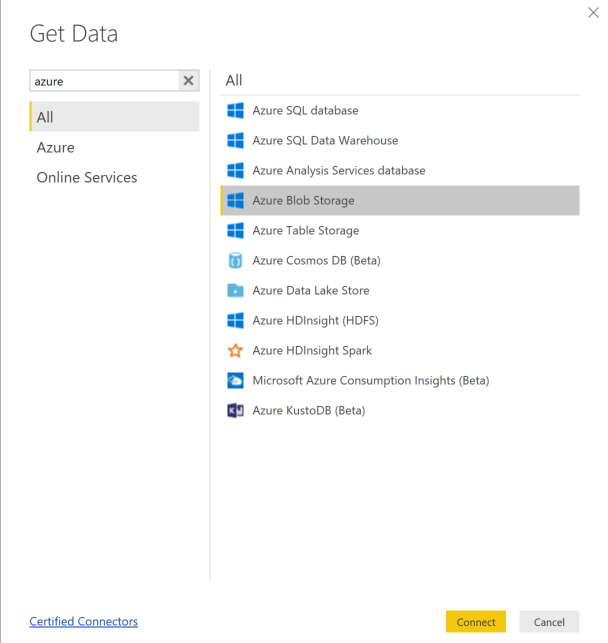
新增您的儲存體帳戶名稱並輸入您的儲存體金鑰。 您可以在 Blob 中的 [設定]>[存取金鑰] 中找到這項資訊。
選取模型資料容器,然後選取 [編輯]。
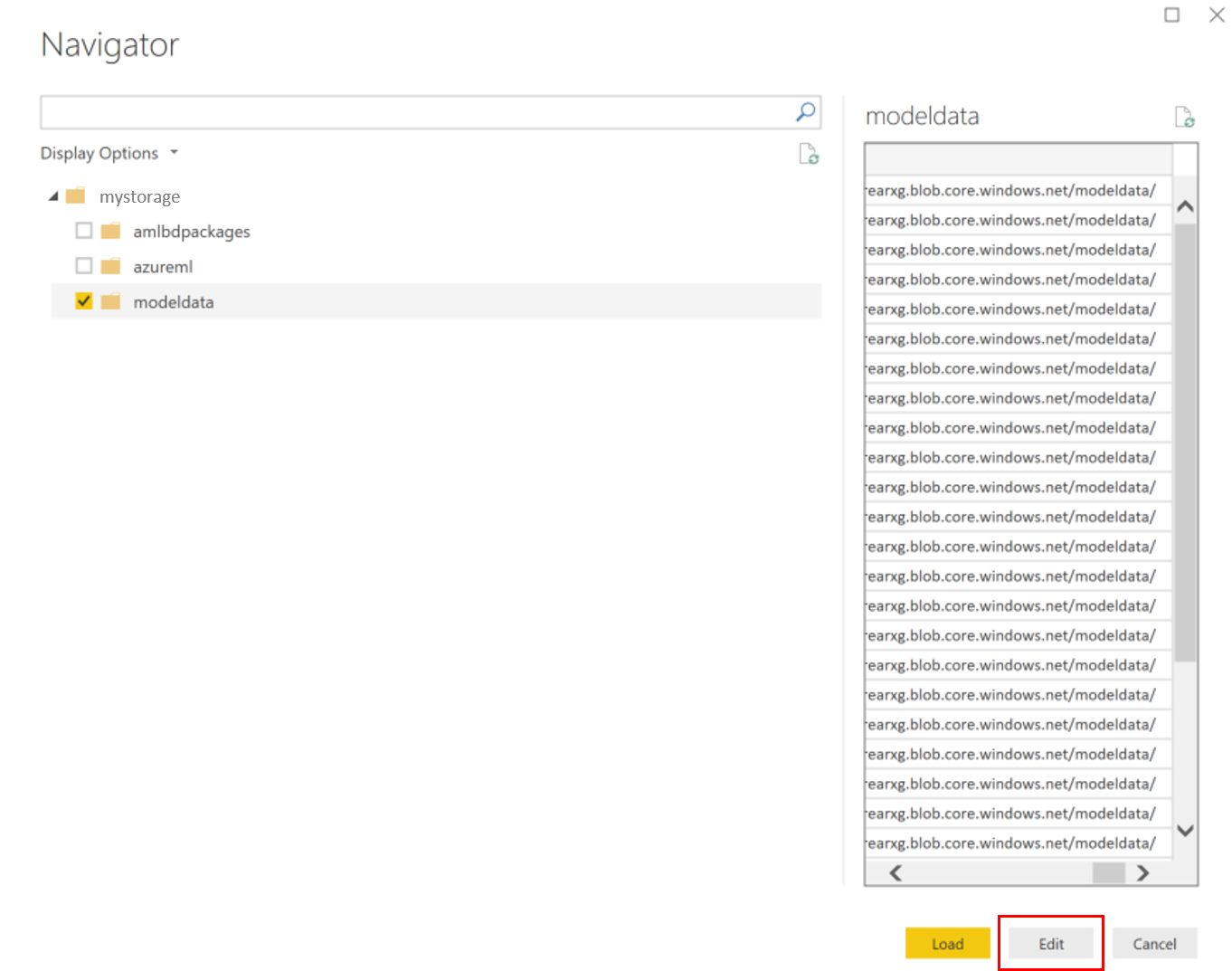
在查詢編輯器中的 [名稱] 資料行下方按一下,然後新增您的儲存體帳戶。
在篩選中輸入您的模型路徑。 如果您只想查看特定年份或月份的檔案,只要展開篩選路徑即可。 例如,如果只要查看三月的資料,請使用此篩選路徑:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
根據 [名稱] 值來篩選與您相關的資料。 如果您儲存了預測和輸入,則需要分別為這兩個項目建立查詢。
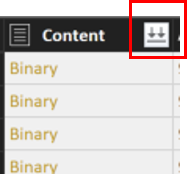
選取 [內容] 資料行標題旁的向下雙箭號,可合併這些檔案。
選取 [確定]。 資料會預先載入。
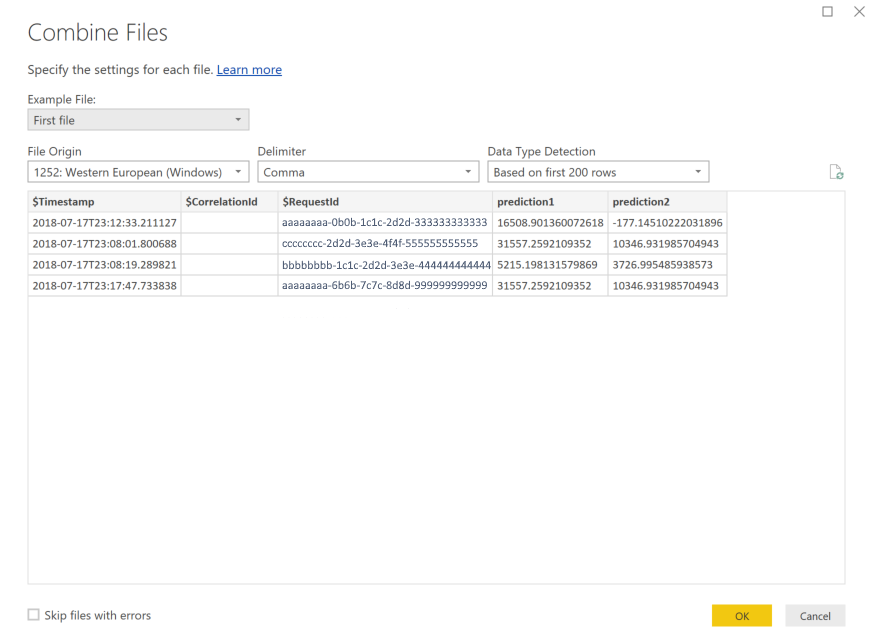
選取關閉並套用。
如果您新增了輸入和預測,您的資料表就會自動以 RequestId 值排序。
開始建置模型資料的自訂報告。




使用 Azure Databricks 分析模型資料
移至 Databricks 工作區。
在 Databricks 工作區中,選取 [上傳資料]。
![顯示選取 [Databricks 上傳資料] 選項的螢幕擷取畫面。](media/how-to-enable-data-collection/databricks-upload.png?view=azureml-api-1)
選取 [建立新資料表],然後選取 [其他資料來源]>[Azure Blob 儲存體]>[在 Notebook 中建立資料表]。

更新您的資料位置。 以下是範例:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"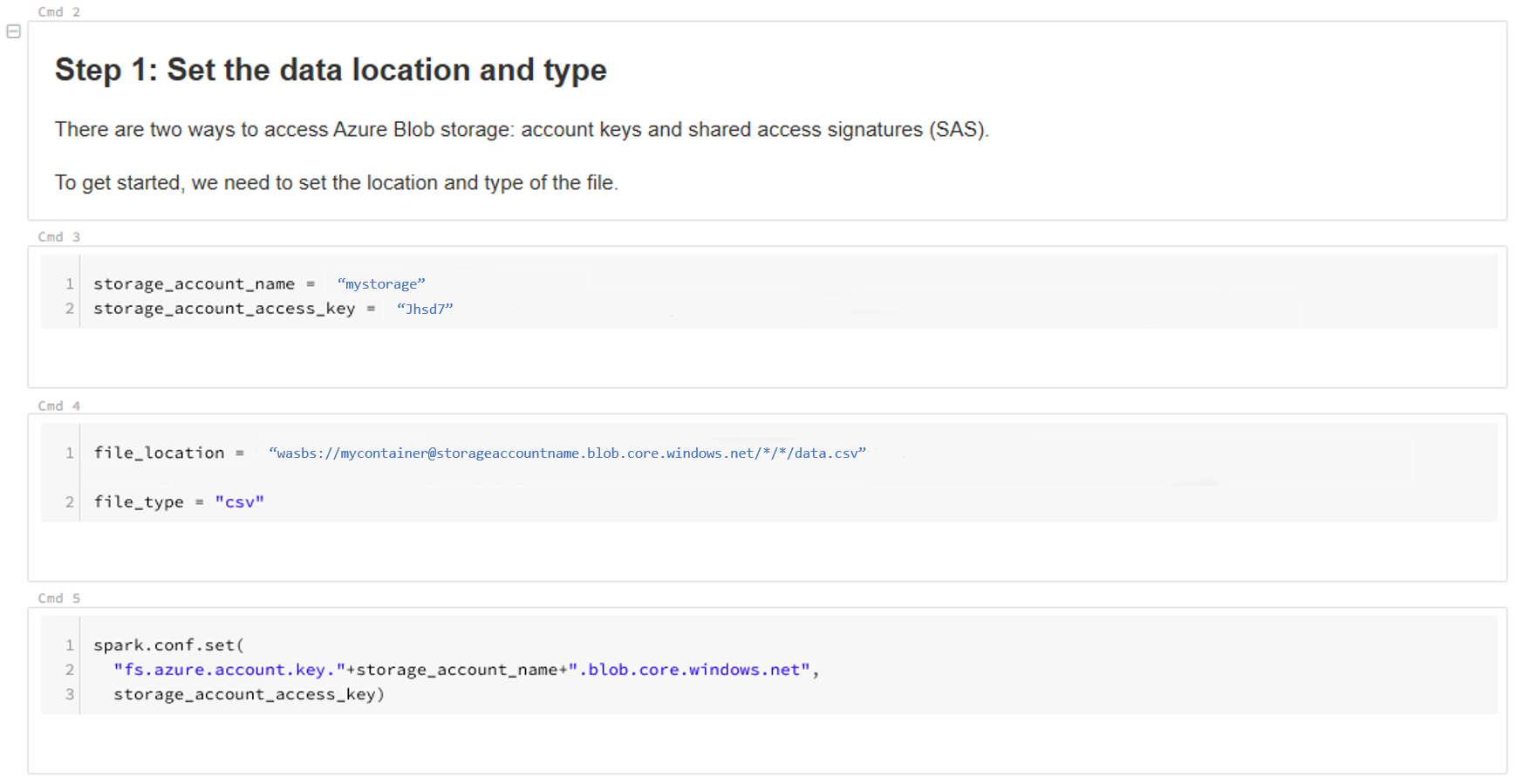
請遵循範本上的步驟,以便檢視及分析您的資料。
![顯示選取 [Databricks 上傳資料] 選項的螢幕擷取畫面。](media/how-to-enable-data-collection/databricks-upload.png?view=azureml-api-1#lightbox)


下一步
在您收集的資料上偵測資料漂移。