教學課程:使用 Jupyter Notebook 範例將影像分類模型定型並進行部署
適用於:  Python SDK azureml v1 (部分機器翻譯)
Python SDK azureml v1 (部分機器翻譯)
在本教學課程中,您會在遠端計算資源上定型機器學習模型。 您會使用 Python Jupyter Notebook 中的 Azure Machine Learning 訓練和部署工作流程。 然後,您可以使用 Notebook 作為範本,以自己的資料將您自己的機器學習服務模型定型。
本教學課程可讓您使用 MNIST 資料集,並搭配 scikit-learn 與 Azure Machine Learning 定型簡單的羅吉斯迴歸。 MNIST 是一種由 70,000 張灰階影像組成的熱門資料集。 每一張影像都是 28 x 28 像素的手寫數字,代表從 0 到 9 的數字。 目標是要建立多類別分類器,來識別特定影像代表的數字。
了解如何採取下列動作:
- 下載資料集並查看資料。
- 使用 MLflow 將影像分類模型定型並記錄計量。
- 部署模型以執行即時推斷。
必要條件
- 完成快速入門:開始使用 Azure Machine Learning,以執行下列作業:
- 建立工作區。
- 建立雲端式計算執行個體,以用於您的開發環境。
從您的工作區執行筆記本
Azure Machine Learning 會在您的工作區中包含雲端 Notebook 伺服器,讓您擁有免安裝和預先設定的體驗。 如果您想要控制您的環境、套件和相依性,請使用您自己的環境。
複製 Notebook 資料夾
您將完成下列實驗設定,並在 Azure Machine Learning 工作室中執行步驟。 此整合介面包含機器學習工具,可為所有技能等級的資料科學從業人員執行資料科學案例。
選取訂用帳戶與您建立的工作區。
選取左側的 [筆記本]。
選取頂端的 [範例] 索引標籤。
開啟 SDK v1 資料夾。
選取 tutorials 資料夾右側的 [...] 按鈕,然後選取 [複製]。
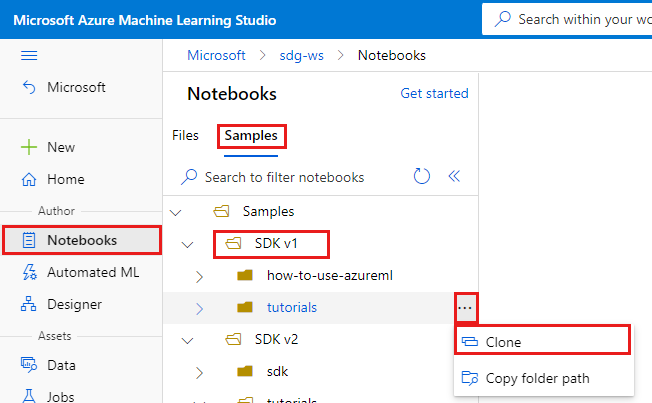
資料夾清單會顯示每位存取工作區的使用者。 選取您的資料夾,以將 tutorials 資料夾複製到該處。
開啟複製的筆記本
在 [使用者檔案] 區段中開啟已複製的 tutorials 資料夾。
從 tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins 資料夾中選取 quickstart-azureml-in-10mins.ipynb 檔案。
![螢幕擷取畫面:顯示 [開啟教學課程] 資料夾。](media/tutorial-train-deploy-notebook/expand-folder.png?view=azureml-api-1)
安裝套件
計算執行個體執行且核心出現之後,請新增程式碼資料格以安裝本教學課程所需的套件。
在筆記本頂端,新增程式碼資料格。
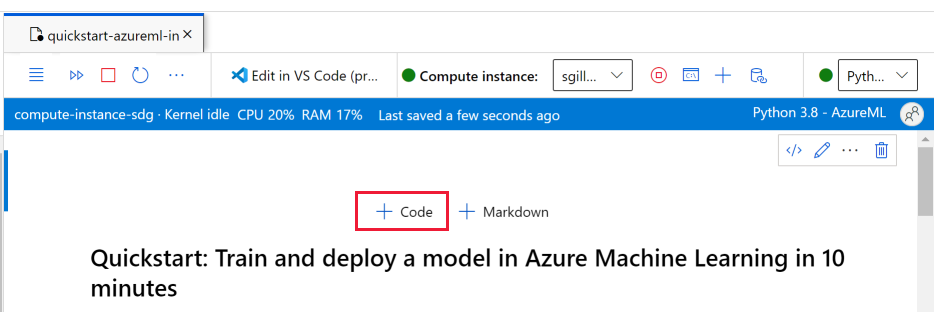
將下列內容新增至資料格,然後使用 [執行] 工具或使用 Shift+Enter 來執行資料格。
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
您可能會看到一些安裝警告。 請放心忽略這項錯誤訊息。
執行該筆記本
如果您想要在自己的本機環境中使用此教學課程,也可以在 GitHub 上取得此教學課程和隨附的 utils.py 檔案。 如果您未使用計算執行個體,則請將 %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib 新增至上述安裝。
重要
本文的其餘部分包含與您在 Notebook 中所見相同的內容。
如果您想要在閱讀時執行程式碼,請立即切換至 Jupyter Notebook。 若要在 Notebook 中執行單一程式碼資料格,請按一下程式碼資料格,然後按 Shift+Enter。 或者,從頂端工具列中選擇 [全部執行],以執行整個 Notebook。
匯入資料
將模型定型之前,您需要了解用來進行定型的資料。 在本節中,請了解如何:
- 下載 MNIST 資料集
- 顯示一些範例影像
請使用 Azure 開放資料集來取得原始 MNIST 資料檔案。 Azure 開放資料集是策劃的公用資料集,您可以使用這些公用資料集,將案例專有的功能新增至機器學習解決方案,以獲得更好的模型。 每個資料集都有對應的類別 (在此案例中為 MNIST),來以不同的方式擷取資料。
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
查看資料
將壓縮的檔案載入到 numpy 陣列。 然後使用 matplotlib 來繪製 30 個來自資料集的隨機影像,並且在其上加上標籤。
請注意,此步驟需要 load_data 函式,它包含在 utils.py 檔案中。 此檔案會放在與此 Notebook 相同的資料夾中。 load_data 函式會直接將壓縮檔案剖析為 numpy 陣列。
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
此程式碼會顯示一組隨機影像及其標籤,如下所示:

使用 MLflow 將模型定型並記錄計量
請使用下列程式碼來訓練模型。 此程式碼會使用 MLflow 自動記錄功能來追蹤計量和記錄模型成品。
您會使用 SciKit Learn 架構中的 LogisticRegression 分類器來分類資料。
注意
模型訓練大約需要 2 分鐘才能完成。
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
檢視實驗
在 Azure Machine Learning 工作室的左側功能表中,選取 [作業],然後選取您的作業 (azure-ml-in10-mins-tutorial)。 作業聚集了指定指令碼或一段程式碼的多次執行。 多個作業可以分組在一起,做為實驗。
回合的資訊會儲存在該作業底下。 如果您提交作業時名稱不存在,而且您選取自己的執行,便會看到包含計量、記錄、說明等資訊的各種索引標籤。
使用模型登錄對模型進行版本控制
您可以使用模型註冊,以在工作區中儲存模型並設定其版本。 已註冊的模型可以用名稱和版本來識別。 每次您使用與既有名稱相同的名稱註冊模型時,登錄會遞增版本。 下列程式碼會註冊您在上面所定型的模型並設定其版本。 執行了下列程式碼資料格之後,即可在 Azure Machine Learning 工作室的左側功能表中選取 [模型] 來查看登錄中的模型。
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
部署模型以執行即時推斷
請在本節了解如何部署模型,讓應用程式可以透過 REST 取用 (推斷) 模型。
建立部署設定
程式碼資料格會取得策展的環境,以指定要裝載模型所需的所有相依性 (例如 scikit-learn 之類的套件)。 此外,您也會建立部署設定,以指定要裝載模型所需的計算數量。 在此案例中,計算有 1 個 CPU 和 1 GB 的記憶體。
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
部署模型
下一個程式碼資料格會將模型部署至 Azure 容器執行個體。
注意
部署大約需要 3 分鐘才能完成。 但可能需要更長的時間才可供使用,也許需要 15 分鐘之久。**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
上述程式碼中所參考的評分指令檔可以在與這個筆記本相同的資料夾中找到,而且有兩個函式:
init函式,此函式會在服務啟動時執行一次 - 在此函式中,您通常會從登錄取得模型並設定全域變數run(data)函式,此函式會在每次呼叫服務時執行。 在此函式中,您通常會將輸入資料格式化、執行預測,以及輸出預測的結果。
檢視端點
成功部署模型之後,您可以瀏覽至 Azure Machine Learning 工作室左側功能表中的 [端點] 來檢視端點。 您會看到端點的狀態 (狀況良好/狀況不良)、記錄和取用 (應用程式要如何取用模型)。
測試模型服務
您可以傳送未經處理的 HTTP 要求來測試 Web 服務,藉此測試模型。
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
清除資源
如果您不會繼續使用此模型,請透過下列方式刪除模型服務:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
如果您想要進一步控制成本,請選取 [計算] 下拉式清單旁邊的 [停止計算] 按鈕,以停止計算執行個體。 然後,在下次需要計算執行個體時,重新將其啟動。
刪除所有內容
請使用下列步驟來刪除 Azure Machine Learning 工作區和所有計算資源。
重要
您所建立的資源可用來作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
如果不打算使用您建立的任何資源,請刪除以免產生任何費用:
在 Azure 入口網站 的搜尋方塊中,輸入 [資源群組],然後從結果中選取它。
從清單中,選取您所建立的資源群組。
在 [概觀] 頁面上,選取 [刪除資源群組]。
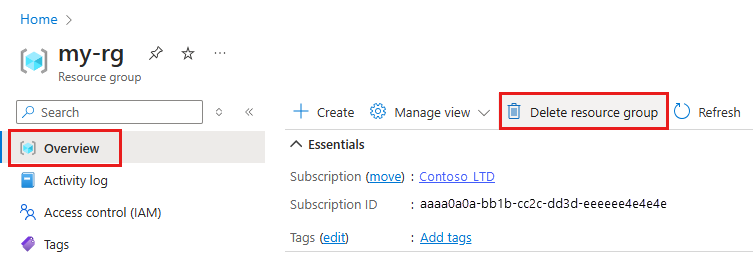
輸入資源群組名稱。 接著選取刪除。