在 Azure Machine Learning 中設定一個搭配 Azure Databricks 和 AutoML 的開發環境
了解如何在 Azure Machine Learning 中設定一個使用 Azure Databricks 和自動化 ML 的開發環境。
Azure Databricks 適合在 Azure 雲端的可調整 Apache Spark 平台上執行大規模密集的機器學習工作流程。 提供以 Notebook 為基礎的共同作業環境,還有以 CPU 或 GPU 為基礎的計算叢集。
如需其他機器學習開發環境的相關資訊,請參閱設定 Python 開發環境。
必要條件
Azure Machine Learning 工作區。 若要建立,請使用建立工作區資源一文中的步驟。
Azure Databricks 搭配 Azure Machine Learning 和 AutoML
Azure Databricks 與 Azure Machine Learning 及其 AutoML 功能整合。
Azure Databricks 的用途:
- 使用 Spark MLlib 來定型模型,並將模型部署到 ACI/AKS。
- 透過 Azure Machine Learning SDK 來搭配自動化機器學習功能。
- 作為來自 Azure Machine Learning 管線的計算目標。
設定 Databricks 叢集
建立 Databricks 叢集。 只有當您在 Databricks 上安裝適用於自動化機器學習的 SDK 時,才會適用某些設定。
建立叢集需要幾分鐘的時間。
使用下列設定:
| 設定 | 適用於 | 值 |
|---|---|---|
| 叢集名稱 | always | yourclustername |
| Databricks Runtime 版本 | always | 9.1 LTS |
| Python 版本 | always | 3 |
| 背景工作角色類型 (決定同時反覆運算次數上限) |
自動化 ML 向 |
建議使用已記憶體最佳化的 VM |
| 背景工作角色 | always | 2 個以上 |
| 啟用自動調整功能 | 自動化 ML 向 |
取消選取 |
請靜候至叢集運作,再繼續操作。
將 Azure Machine Learning SDK 新增至 Databricks
叢集執行之後,請建立程式庫,以將適當的 Azure Machine Learning SDK 封裝附加至叢集。
若要使用自動化 ML,請跳至將 Azure Machine Learning SDK 搭配 AutoML 新增至 Databricks。
以滑鼠右鍵按一下您要儲存程式庫的目前工作區資料夾。 選取 [建立]>[程式庫]。
提示
如果您有舊版 SDK,請從叢集已安裝的程式庫中取消選取 SDK,並放到垃圾桶。 安裝新版 SDK,並重新啟動叢集。 如果重新啟動之後發生問題,請中斷連結叢集再重新連結。
選擇下列選項 (不支援其他 SDK 安裝)
SDK 封裝額外項目 來源 PyPi 名稱 適用於 Databricks 上傳 Python Egg 或 PyPI azureml-sdk[databricks] 警告
無法安裝其他 SDK 額外項目。 只能選擇 [
databricks] 選項。- 請勿選取 [自動附加至所有叢集]。
- 選取叢集名稱旁的 [附加]。
監視錯誤,直到狀態變更為已附加為止,可能需要幾分鐘的時間。 如果此步驟失敗:
執行下列動作來嘗試重新啟動叢集:
- 在左窗格中,選取 [叢集]。
- 請選取表格中您的叢集名稱。
- 在 [程式庫] 索引標籤上,選取 [重新啟動]。
成功安裝看起來如下所示:
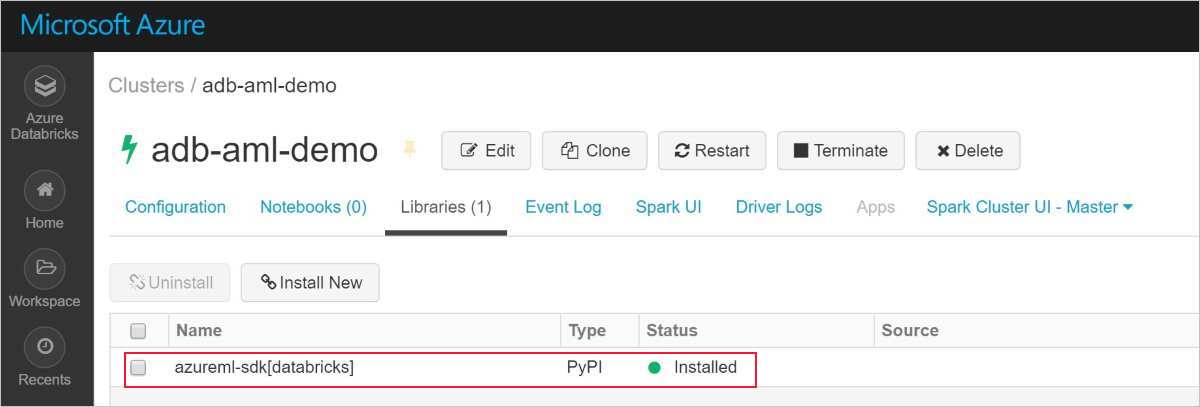
將 Azure Machine Learning SDK 搭配 AutoML 新增至 Databricks
如果是以 Databricks Runtime 7.3 LTS (非 ML) 建立叢集,請在筆記本的第一個儲存格中執行下列命令,以安裝 Azure Machine Learning SDK。
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
AutoML 組態設定
在 AutoML 組態中,使用 Azure Databricks 時,請新增下列參數:
max_concurrent_iterations以叢集中的背景工作節點數目為基礎。spark_context=sc以預設 spark 內容為基礎。
適用於 Azure Databricks 的 ML 筆記本
試試看:
雖然有許多範例筆記本可用,但只有這些範例筆記本適用於 Azure Databricks。
直接從工作區匯入這些範例。 請參閱以下內容:
疑難排解
Databricks 取消自動化機器學習執行:當您在 Azure Databricks 上使用自動化機器學習功能時,若要取消執行並開始新的實驗執行,請重新啟動 Azure Databricks 叢集。
Databricks 在自動化機器學習中 >10 次反覆運算:在自動化機器學習設定中,如果您有 10 次以上的反覆運算,請在提交執行時將
show_output設定為False。適用於 Azure Machine Learning SDK 和自動化機器學習服務的 Databricks widget:Databricks 筆記本中不支援 Azure Machine Learning SDK widget,因為筆記本無法剖析 HTML widget。 在入口網站中,您可以在 Azure Databricks 筆記本儲存格中使用此 Python 程式碼來檢視 widget:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))安裝封裝時失敗
在 Azure Databricks 上,Azure Machine Learning SDK 安裝在安裝多個封裝時失敗。 有些套件 (例如
psutil) 會導致發生衝突。 為了避免安裝錯誤,請凍結程式庫版本來安裝封裝。 此問題與 Databricks 有關,與 Azure Machine Learning SDK 無關。 其他程式庫也可能發生此問題。 範例:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0或者,如果持續遇到 Python 程式庫的安裝問題,您可以使用 init 指令碼。 未正式支援此方法。 如需詳細資訊,請參閱叢集範圍的 init 指令碼。
匯入錯誤:無法從
pandas._libs.tslibs匯入名稱Timedelta:如果您在使用自動化機器學習時看到此錯誤,請在筆記本中執行下列兩行:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4匯入錯誤:沒有名為 'pandas.core.indexes' 的模組:如果您在使用自動化機器學習時看到此錯誤:
執行此命令,在 Azure Databricks 叢集安裝兩個封裝:
scikit-learn==0.19.1 pandas==0.22.0中斷連結叢集,再將叢集重新連結至筆記本。
如果這些步驟無法解決問題,請嘗試重新啟動叢集。
FailToSendFeather:如果您在 Azure Databricks 叢集上讀取資料時看到
FailToSendFeather錯誤,請參閱下列解決方案:- 將
azureml-sdk[automl]封裝更新為最新版本。 - 新增
azureml-dataprep1.1.8 版或更新版本。 - 新增
pyarrow0.11 版或更新版本。
- 將
下一步
- 在 Azure Machine Learning 上使用 MNIST 資料集來定型和部署模型。
- 請參閱適用於 Python 的 Azure Machine Learning SDK。