訓練 SVD 推薦
本文說明如何在 Azure 機器學習 設計工具中使用定型 SVD 建議工具元件。 使用此元件來根據單一值分解 (SVD) 演演算法來定型建議模型。
訓練 SVD 推薦元件會讀取用戶專案評等三倍的數據集。 它會傳回定型的SVD 推薦工具。 接著,您可以使用定型的模型來預測評等或產生建議,方法是連接 評分 SVD 推薦元件 。
深入了解建議模型和 SVD 建議工具
建議系統的主要目標是建議一或多個 專案 給 系統的使用者 。 專案的範例可能是電影、餐廳、書籍或歌曲。 使用者可能是具有專案喜好設定的人員、人員群組或其他實體。
建議系統有兩種主要方法:
- 以內容為基礎的方法會針對用戶和專案使用功能。 用戶可以依年齡和性別等屬性來描述。 專案可由作者和製造商等屬性描述。 您可以在社交配對網站上找到以內容為基礎的建議系統的典型範例。
- 共同作業篩選 只會使用使用者和專案的標識碼。 它會從使用者提供給項目的評分矩陣中,取得這些實體的相關隱含資訊。 我們可以從他們已評等的專案,以及已對相同項目進行評等的其他使用者,了解使用者。
SVD 建議工具會使用使用者和專案的標識碼,以及使用者提供給專案的評等矩陣。 這是共同 作業推薦工具。
如需 SVD 推薦的詳細資訊,請參閱相關研究論文: 推薦系統的矩陣分解技術。
如何設定訓練 SVD 建議工具
準備資料
使用元件之前,您的輸入數據必須採用建議模型預期的格式。 需要用戶項目評等三倍的定型數據集。
- 第一個數據行包含使用者識別碼。
- 第二個數據行包含專案識別碼。
- 第三個數據行包含用戶專案組的評等。 評等值必須是數值類型。
Azure 機器學習 設計工具中的電影評等數據集(選取 [數據集],然後選取 [範例] 會示範預期的格式:
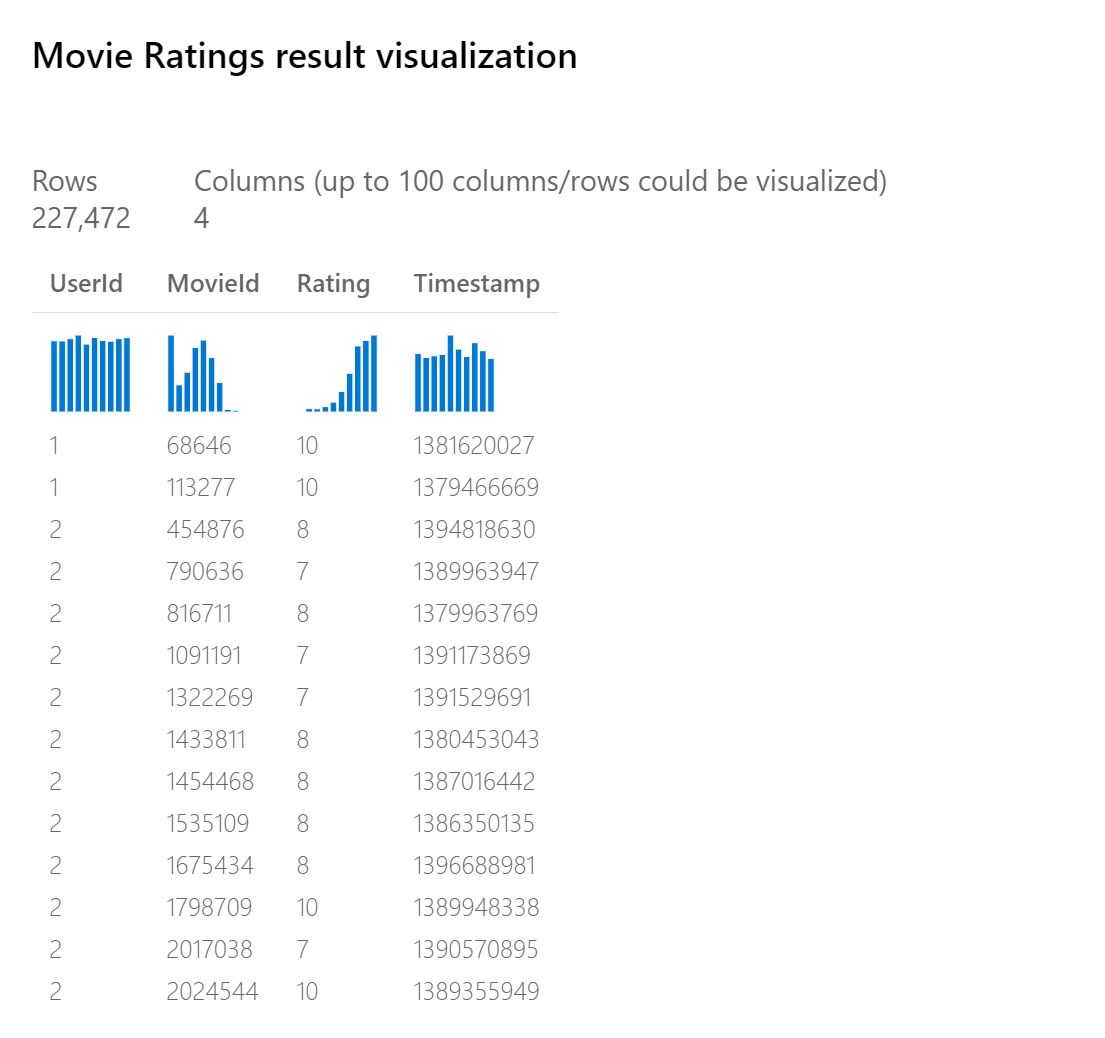
在此範例中,您可以看到單一使用者已評等數部影片。
訓練模型
將定型 SVD 建議程式元件新增至設計工具中的管線,並將其連線至定型數據。
針對 [因子數目],指定要與推薦程式搭配使用的因素數目。
每個因素都會測量用戶與項目相關的程度。 因素數目也是潛伏因數空間的維度。 隨著使用者和項目數目增加,最好設定較大的因素。 但是,如果數位太大,效能可能會下降。
建議演算法反覆 項目的數目表示演算法應該處理輸入數據多少次。 這個數位越高,預測越準確。 不過,較高的數位表示訓練速度較慢。 預設值是 30。
針對 學習速率,輸入介於 0.0 和 2.0 之間的數位,以定義學習的步驟大小。
學習速率會決定每個反覆專案上步驟的大小。 如果步驟大小太大,您可能會過度調整最佳解決方案。 如果步驟大小太小,定型需要較長的時間才能找到最佳的解決方案。
提交管線。
結果
管線作業完成後,若要使用模型進行評分,請將定型SVD 建議程式連接到評分 SVD 建議程式,以預測新輸入範例的值。