建立 Python 模型元件
本文說明 Azure 機器學習 設計工具中的元件。
瞭解如何使用建立 Python 模型元件,從 Python 腳本建立未定型的模型。 您可以將模型以 Azure 機器學習 設計工具環境中 Python 套件中包含的任何學習者為基礎。
建立模型之後,您可以使用定型模型在數據集上定型模型,就像 Azure 中任何其他學習者一樣 機器學習。 定型的模型可以傳遞至 評分模型 來進行預測。 然後,您可以儲存定型的模型,並將評分工作流程發佈為Web服務。
警告
目前無法將此元件連線至 微調模型超參數位 件,或將 Python 模型的評分結果傳遞至 評估模型。 如果您需要微調超參數或評估模型,您可以使用執行 Python 腳本元件來撰寫自定義 Python 腳本 。
設定元件
使用此元件需要 Python 的中繼或專家知識。 此元件支援使用已安裝在 Azure 機器學習 中 Python 套件中的任何學習模組。 請參閱執行 Python 腳本中的預安裝 Python 套件清單。
注意
撰寫文本時請非常小心,並確定沒有語法錯誤,例如使用未宣告的物件或未匯入的元件。
注意
也請特別注意執行 Python 腳本中預安裝的元件清單。 只匯入預安裝的元件。 請勿在此腳本中安裝額外的套件,例如 「pip install xgboost」,否則讀取元件中的模型時,將會引發錯誤。
本文說明如何使用 建立 Python 模型 搭配簡單的管線。 以下是管線的圖表:
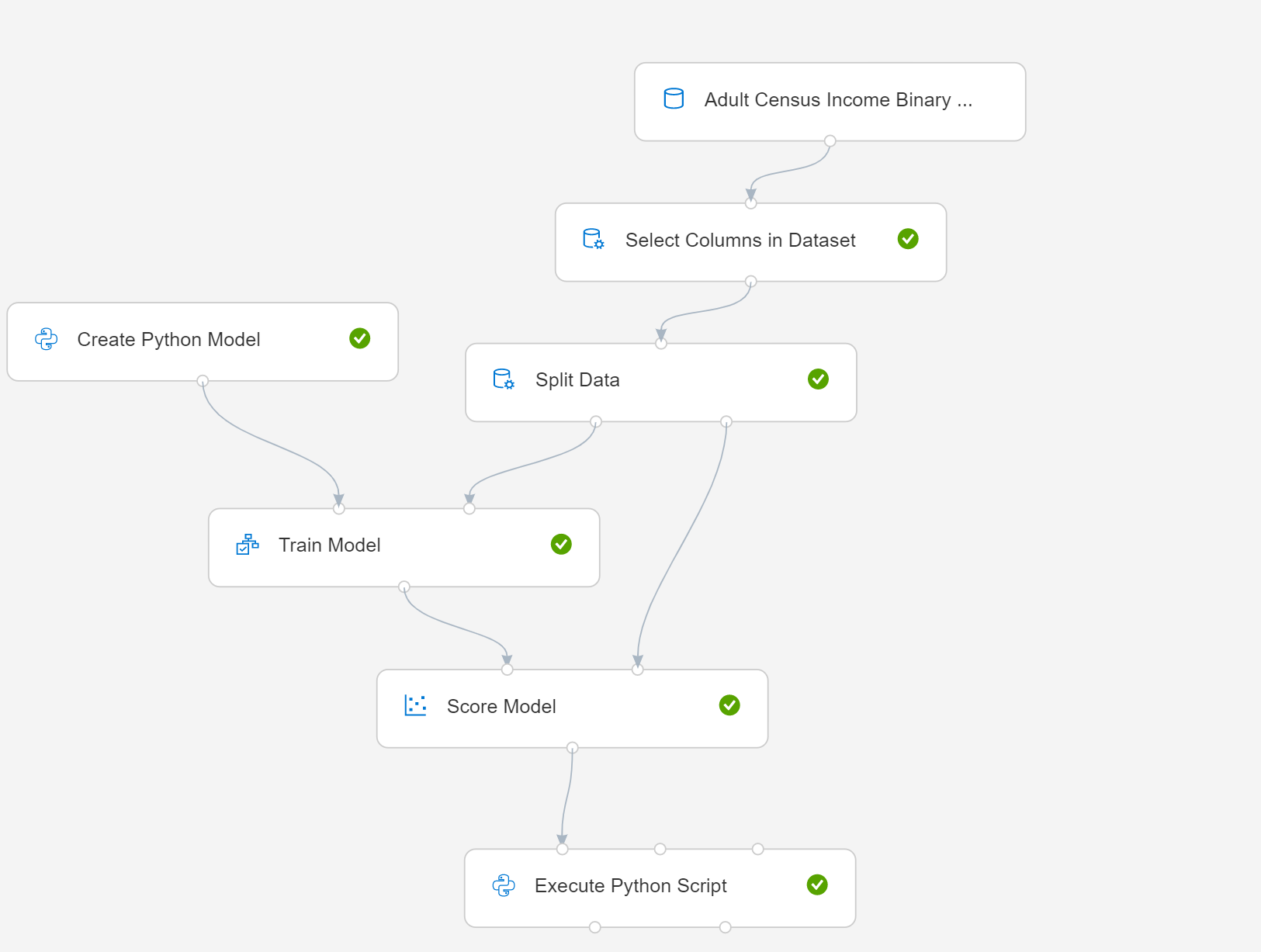
- 選取 [建立 Python 模型],然後編輯腳本以實作模型化或數據管理程式。 您可以將模型以 Azure 機器學習 環境中 Python 套件中包含的任何學習者為基礎。
注意
請特別注意文本範例程式代碼中的批註,並確定您的腳本嚴格遵循需求,包括類別名稱、方法和方法簽章。 違規會導致例外狀況。 建立 Python 模型 僅支援使用 定型模型來建立以 sklearn 為基礎的模型。
下列雙類別貝氏機率分類器的範例程式代碼會使用熱門 的sklearn 套件:
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
連接您剛才建立的建立 Python 模型元件,以定型模型和評分模型。
如果您需要評估模型,請新增 執行 Python 腳本 元件並編輯 Python 腳本。
下列文稿是範例評估程式代碼:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,