定型模型元件
本文說明 Azure 機器學習 設計工具中的元件。
使用此元件來定型分類或回歸模型。 定型會在您定義模型並設定其參數之後進行,而且需要標記的數據。 您也可以使用 定型模型 ,以新的數據重新定型現有的模型。
定型程序的運作方式
在 Azure 機器學習 中,建立和使用機器學習模型通常是三個步驟的程式。
您可以藉由選擇特定類型的演算法,以及定義其參數或超參數來設定模型。 選擇下列任何模型類型:
- 分類 模型,以神經網路、判定樹和判定樹和其他演算法為基礎。
- 回歸模型,包括標準線性回歸 ,或使用其他演算法,包括神經網路和貝氏回歸。
提供已加上標籤的數據集,且具有與演算法相容的數據。 將數據和模型連線到 定型模型。
定型所產生的是特定的二進位格式 iLearner,其會封裝從數據中學習的統計模式。 您無法直接修改或讀取此格式;不過,其他元件可以使用這個定型的模型。
您也可以檢視模型的屬性。 如需詳細資訊,請參閱結果一節。
定型完成後,請使用定型的模型搭配其中 一個評分元件,對新數據進行預測。
如何使用定型模型
將 定型模型 元件新增至管線。 您可以在 機器學習 類別下找到此元件。 展開 [定型],然後將 [定型模型] 元件拖曳至您的管線。
在左側輸入上,附加未定型模式。 將定型數據集附加至定型模型的右側輸入。
定型數據集必須包含標籤數據行。 會忽略不含標籤的任何數據列。
針對 [卷標] 數據行,按兩下元件右面板中的 [ 編輯 ] 資料行,然後選擇包含模型可用於定型結果的單一數據行。
對於分類問題,標籤數據行必須包含 類別 值或 離散 值。 某些範例可能是是/否評等、疾病分類代碼或名稱,或收入群組。 如果您挑選非類別數據行,元件會在定型期間傳回錯誤。
對於回歸問題,標籤數據行必須包含 代表回應變數的數值 數據。 在理想情況下,數值數據代表連續小數字數。
範例可能是信用風險分數、硬碟的預計失敗時間,或指定一天或一天或時間對客服中心的預測通話數目。 如果您未選擇數值資料行,您可能會收到錯誤。
- 如果您未指定要使用的標籤數據行,Azure 機器學習 會嘗試使用資料集的元數據來推斷哪個標籤數據列是適當的標籤數據行。 如果選取錯誤的數據行,請使用資料行選取器來更正它。
提示
如果您在使用數據行選取器時遇到問題,請參閱選取數據集中的數據行一文以取得秘訣。 它描述使用WITH RULES和 BY NAME 選項的一些常見案例和秘訣。
提交管線。 如果您有大量數據,可能需要一段時間。
模型可解釋性
模型可解釋性提供理解 ML 模型的可能性,並以人類可理解的方式呈現決策的基礎。
目前 訓練模型 元件支援 使用可解釋性套件來說明 ML 模型。 支援下列內建演算法:
- 線性迴歸
- 類神經網路迴歸
- 遞增譯碼樹狀結構回歸
- 決策樹系迴歸
- 波氏迴歸
- 二級羅吉斯迴歸
- 雙類別支援向量機
- 二級提升譯碼樹
- 雙類別決策樹系
- 多類別判定樹系
- 多類別羅吉斯回歸
- 多類別類類神經網路
若要產生模型說明,您可以在定型模型元件的模型說明下拉式清單中選取 [True]。 根據預設,它會在 [定型模型] 元件中設定為 False。 請注意,產生說明需要額外的計算成本。
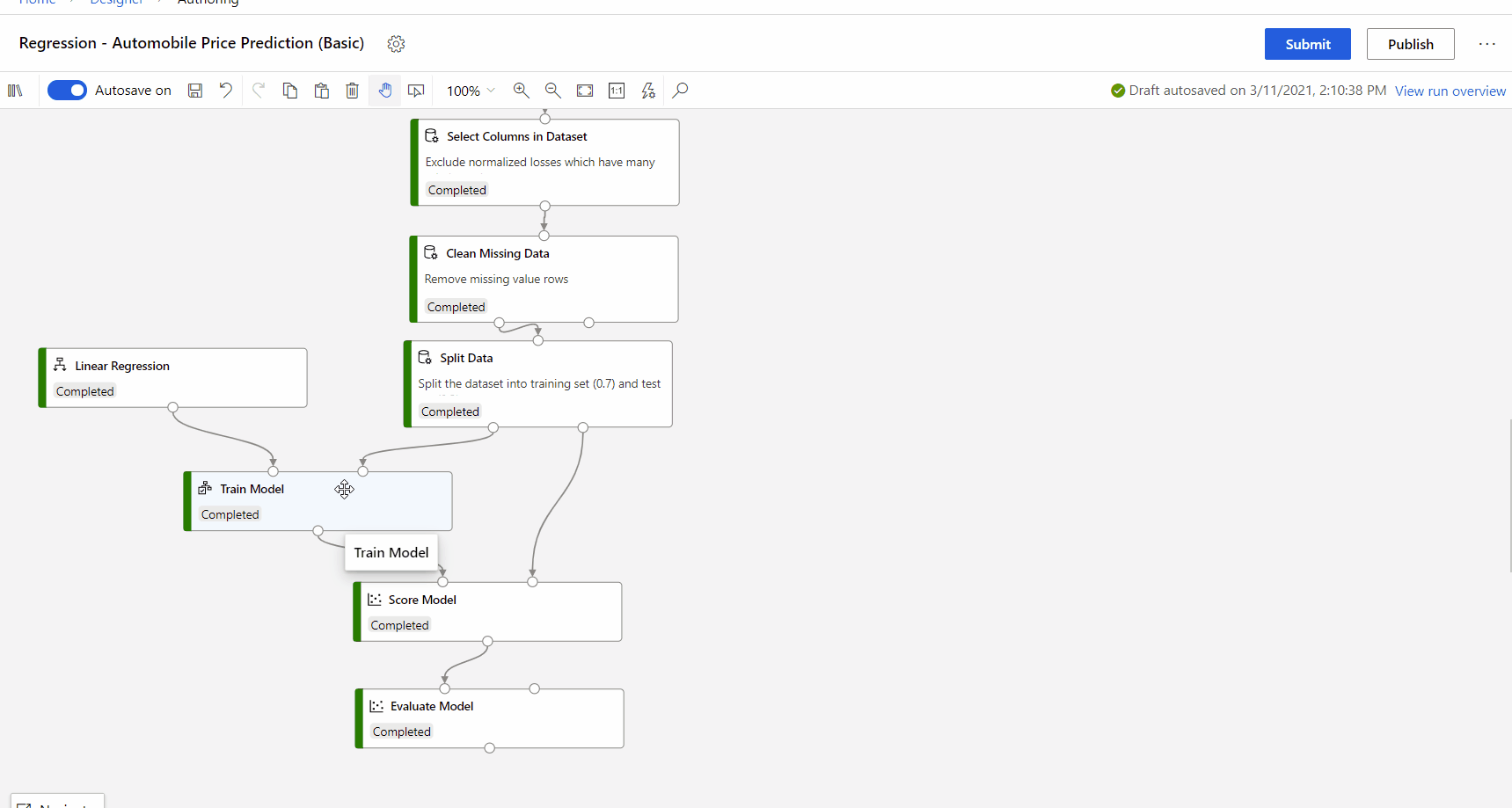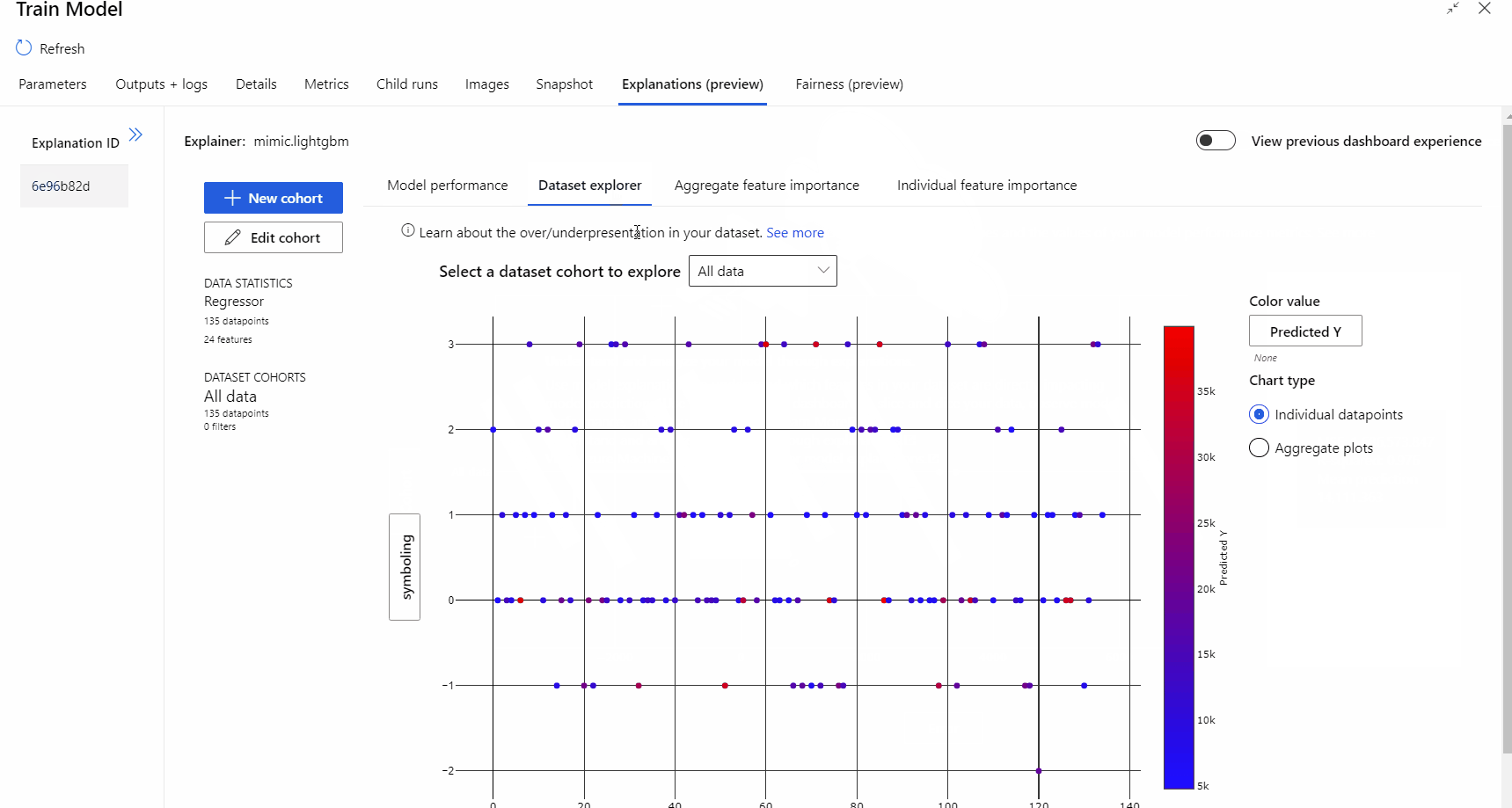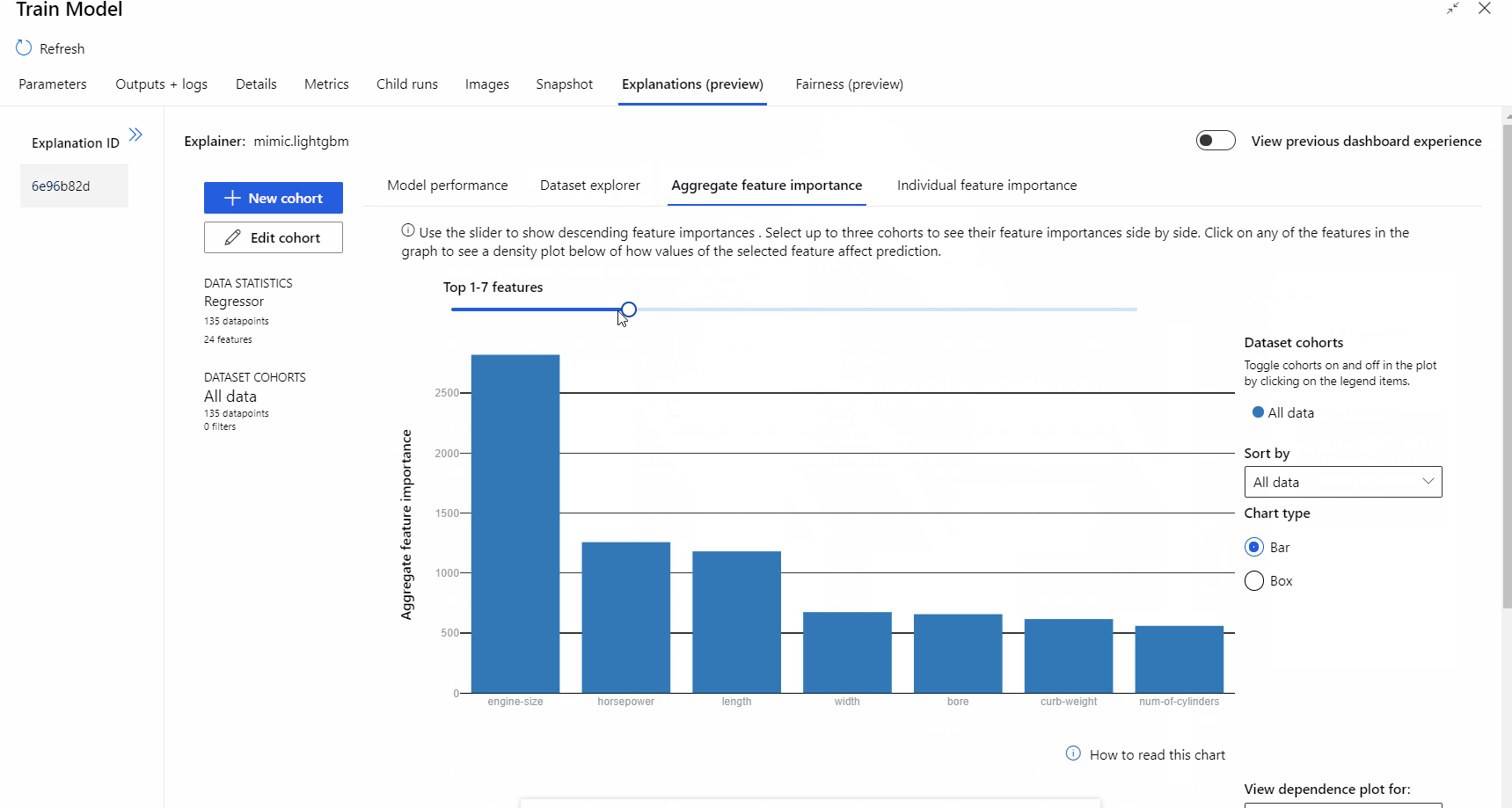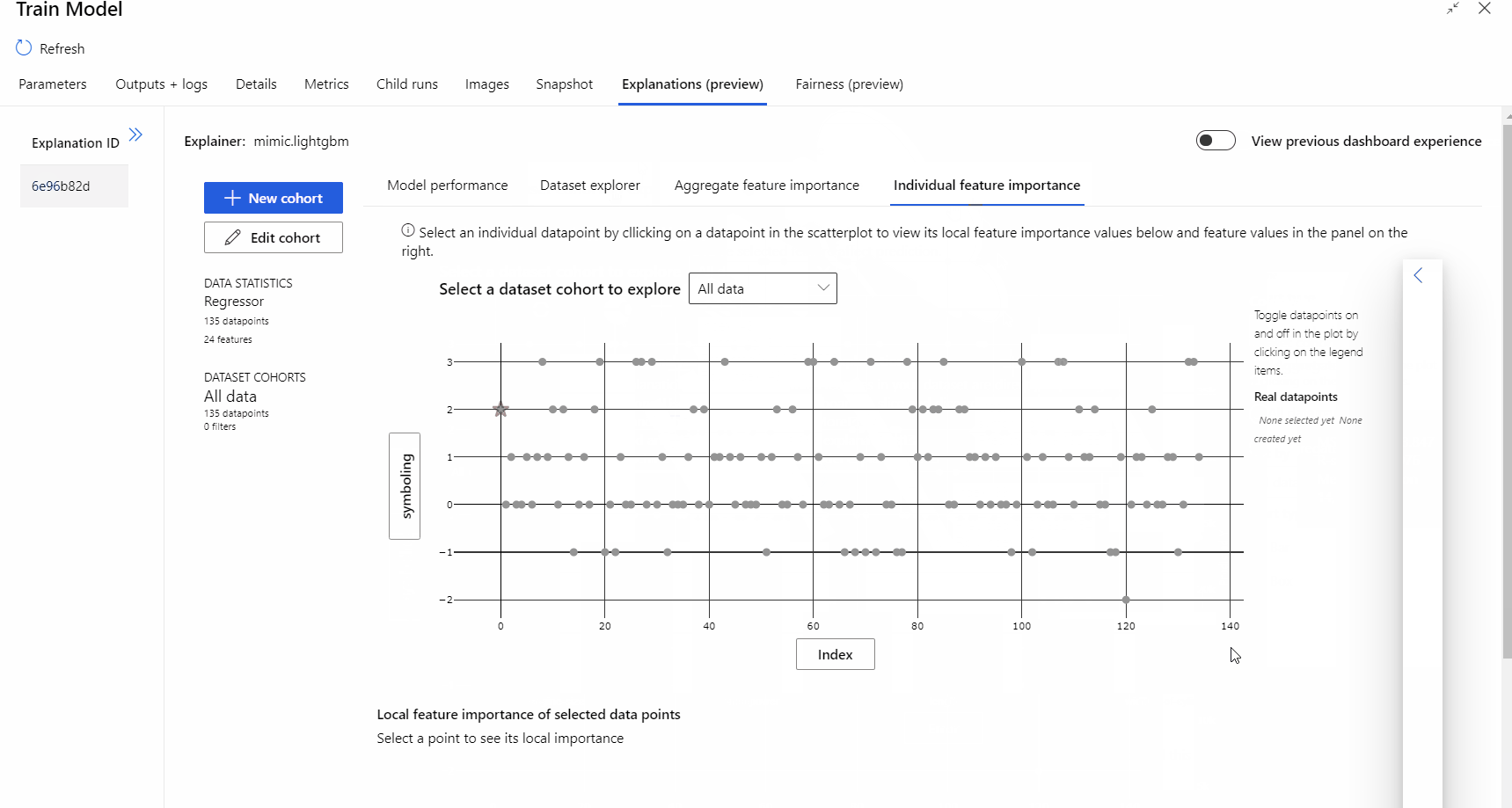
管線執行完成之後,您可以流覽 [定型模型] 元件右窗格中的 [說明] 索引卷標,並探索模型效能、數據集和特徵重要性。
若要深入瞭解如何在 Azure 機器學習 中使用模型說明,請參閱解譯 ML 模型的操作說明文章。
結果
定型模型之後:
若要在其他管線中使用模型,請選取元件,然後在右面板中的 [輸出] 索引卷標下選取 [註冊數據集] 圖示。 您可以在 [資料集] 底下的 元件選擇區中存取已儲存的模型。
若要在預測新值時使用模型,請將它 連接到評分模型 元件,以及新的輸入數據。