透過 JDBC 驅動程式在 HDInsight 中查詢 Apache Hive
了解如何從 Java 應用程式使用 JDBC 驅動程式。 將 Apache Hive 查詢提交到 Azure HDInsight 中的 Apache Hadoop。 本文件中的資訊會示範如何以程式設計方式連線,以及如何從 SQuirreL SQL 用戶端連線。
如需有關 Hive JDBC 介面的詳細資訊,請參閱 HiveJDBCInterface。
必要條件
- HDInsight Hadoop 叢集。 若要建立,請參閱開始使用 Azure HDInsight。 請確定服務 HiveServer2 在執行中。
- Java Developer Kit (JDK) 第 11 版 或更高版本。
- SQuirreL SQL。 SQuirreL 是 JDBC 用戶端應用程式。
JDBC 連接字串
透過連接埠 443 在 Azure 上建立 HDInsight 叢集的 JDBC 連接。 會使用 TLS/SSL 來保護流量。 背後有叢集的公用閘道器會將流量重新導向至 HiveServer2 實際接聽的連接埠。 下列連接字串會顯示用於 HDInsight 的格式:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
將 CLUSTERNAME 替換為 HDInsight 叢集的名稱。
連接字串中的主機名稱
連接字串中的主機名稱 'CLUSTERNAME.azurehdinsight.net' 與您的叢集 URL 相同。 您可以透過 Azure 入口網站取得。
連接字串中的連接埠
您只能使用連接埠 443從 Azure 虛擬網路外部的某些位置連線到叢集。 HDInsight 是受管理的服務,這表示所有與叢集的連線都會透過安全閘道進行管理。 您無法在連接埠 10001 或 10000 上直接連線到 HiveServer 2。 這些連接埠不會向外界公開。
驗證
建立連線時,請使用 HDInsight 叢集系統管理員名稱和密碼來進行驗證。 從 SQuirreL SQL 之類的 JDBC 用戶端,請在用戶端設定中輸入系統管理員名稱和密碼。
從 Java 應用程式建立連接時,您必須使用該名稱和密碼。 例如,下列 Java 程式碼會開啟新的連接:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
使用 SQuirreL SQL 用戶端連接
SQuirreL SQL 是可用來從遠端以 HDInsight 叢集執行 Hive 查詢的 JDBC 用戶端。 下列步驟假設您已安裝 SQuirreL SQL。
建立目錄以包含要從叢集複製的特定檔案。
在下列指令碼中,請將
sshuser取代為叢集的 SSH 使用者帳戶名稱。 將CLUSTERNAME取代為 HDInsight 叢集名稱。 從命令列,將您的工作目錄變更為在上一個步驟中建立的工作目錄,然後輸入下列命令來從 HDInsight 叢集複製檔案:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .啟動 SQuirreL SQL 應用程式。 從視窗左側選取 [驅動程式]。
![視窗左側的 [驅動程式] 索引標籤。](media/apache-hadoop-connect-hive-jdbc-driver/hdinsight-squirreldrivers.png)
從 [驅動程式] 對話方塊上方的圖示,選取 + 圖示以建立驅動程式。
在 [新增驅動程式] 對話方塊中,新增下列資訊:
屬性 值 名稱 Hive 範例 URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2額外類別路徑 使用 [新增] 按鈕來新增稍早下載的所有 jar 檔案。 類別名稱 org.apache.hive.jdbc.HiveDriver 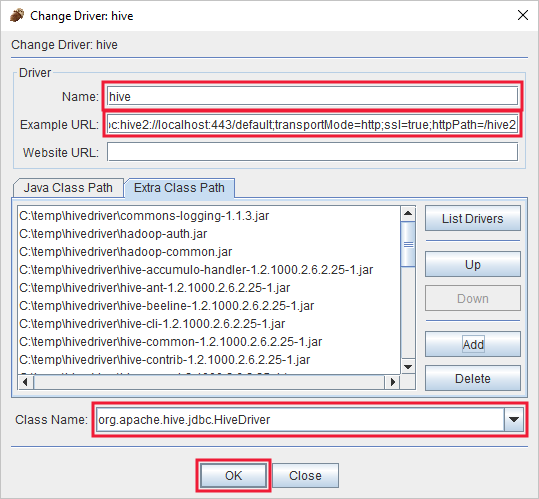
選取 [確定] 以儲存這些變更。
在 SQuirreL SQL 視窗的左側選取 [別名]。 然後選取 + 圖示來建立連線別名。

在 [新增別名] 對話方塊中使用下列值:
屬性 值 名稱 HDInsight 上的 Hive 驅動程式 使用下拉式清單來選取 [Hive] 驅動程式。 URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. 將 CLUSTERNAME 取代為 HDInsight 叢集的名稱。使用者名稱 HDInsight 叢集的叢集登入帳戶名稱。 預設值是 admin。 密碼 叢集登入帳戶的密碼。 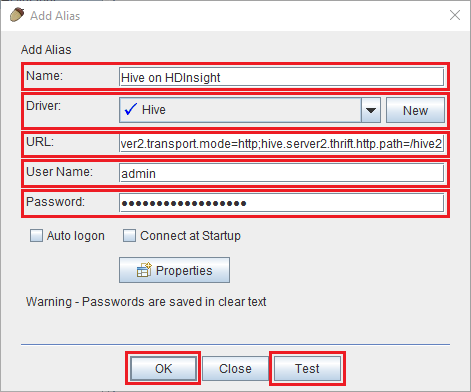
重要
使用 [測試] 按鈕來確認連接能正常運作。 當 [連接到︰HDInsight 上的 Hive] 對話方塊出現時,請選取 [連接] 來執行測試。 如果測試成功,您會看到 [連線成功] 對話方塊。 如果發生錯誤,請參閱疑難排解。
若要儲存連線別名,請使用 [新增別名] 對話方塊底部的 [確定] 按鈕。
從 SQuirreL SQL 頂端的 [連接到] 下拉式清單選取 [HDInsight 上的 Hive]。 出現提示時,請選取 [連接]。
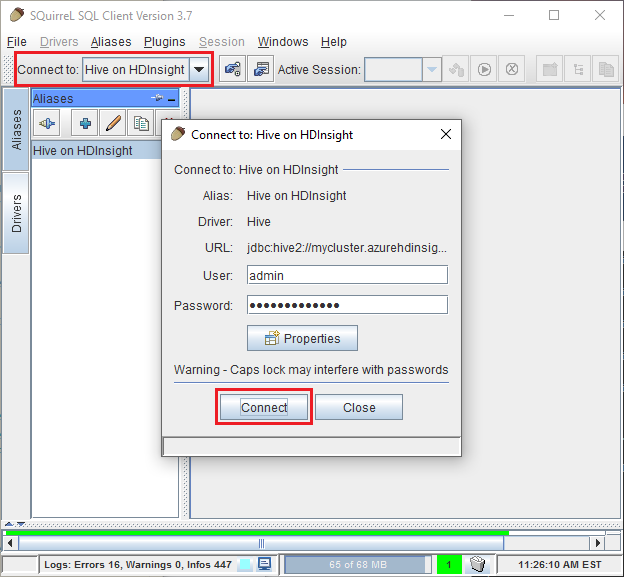
連接後,請在 SQL 查詢對話方塊中輸入下列查詢,然後選取 [執行] 圖示 (一個奔跑的小人)。 結果區域應該會顯示查詢的結果。
select * from hivesampletable limit 10;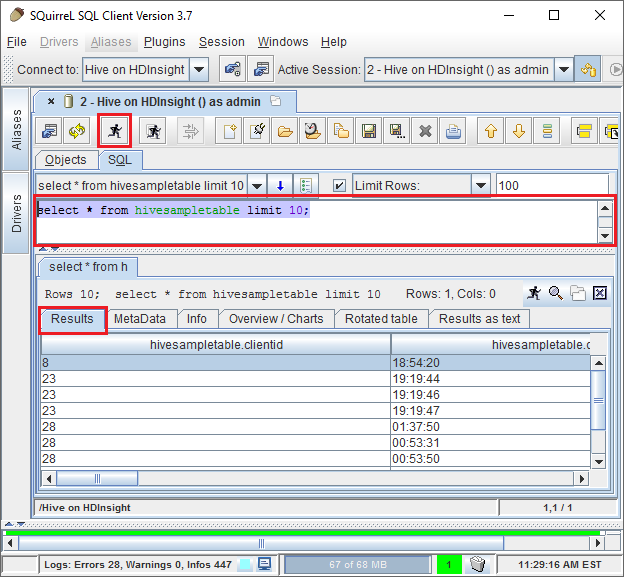
從範例 Java 應用程式連接
您可以在 https://github.com/Azure-Samples/hdinsight-java-hive-jdbc 上找到使用 Java 用戶端,在 HDInsight 上查詢 Hive 的範例。 遵循儲存機制中的指示建置和執行範例。
疑難排解
嘗試開啟 SQL 連線時,發生非預期的錯誤
徵狀︰連線到 HDInsight 叢集 3.3 版或更新版本時,您可能會收到發生非預期錯誤的錯誤。 此錯誤的堆疊追蹤開頭為下列幾行︰
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
原因:此錯誤是由 SQuirreL 所隨附的舊版 commons-codec.jar 檔案所造成。
解決方案︰若要修正此錯誤,請使用下列步驟:
結束 SQuirreL,然後前往系統上安裝 SQuirreL 的目錄,也許是
C:\Program Files\squirrel-sql-4.0.0\lib。 在 SquirreL 目錄的lib目錄下,使用從 HDInsight 叢集下載的版本來取代現有的 commons-codec.jar。重新啟動 SQuirreL。 連接到 HDInsight 上的 Hive 時應該不會再出現此錯誤。
HDInsight 中斷連線
徵兆:HDInsight 在嘗試透過 JDBC/ODBC 下載大量資料 (例如數 GB) 時,意外中斷連線。
原因:網路閘道節點的限制會導致此錯誤。 當您從 JDBC/ODBC 取得數據時,所有數據都必須通過網關節點。 不過,閘道並非設計來下載大量資料的,因此閘道可能會在無法處理流量時關閉連線。
解決方式:避免使用 JDBC/ODBC 驅動程式下載大量資料。 請改為直接從 Blob 儲存體複製資料。
下一步
現在您已學會如何搭配 Hive 使用 JDBC,接著請使用下列連結來探索 Azure HDInsight 的其他使用方式。