在 AKS 上運行的 HDInsight 中的 Apache Spark™ 是什麼? (預覽)
重要
AKS 上的 Azure HDInsight 於 2025 年 1 月 31 日淘汰。 透過此公告 深入瞭解。
您必須將工作負載移轉至 Microsoft Fabric 或對等 Azure 產品,以避免突然終止工作負載。
重要
這項功能目前為預覽狀態。 Microsoft Azure 預覽版的補充使用規定 包含適用於 Beta 版、預覽版或尚未正式發行之 Azure 功能的更合法條款。 如需此特定預覽的相關資訊,請參閱 AKS 上 Azure HDInsight 的預覽信息。 如需問題或功能建議,請在 AskHDInsight 提交請求,並關注我們以獲取 Azure HDInsight 社群的更多更新。
Apache Spark™ 是一種平行處理架構,可支援記憶體內部處理,以提升巨量數據分析應用程式的效能。
Apache Spark™ 提供記憶體內部叢集運算的基本類型。 Spark 作業可以將數據載入並快取到記憶體中,並重複查詢。 記憶體內部運算速度比磁碟型應用程式快,例如 Hadoop,其會透過 Hadoop 分散式檔案系統共用數據(HDFS)。 Apache Spark 可讓您整合 Scala 和 Python 程式設計語言,從而像操作本機集合一樣操作分散式數據集。 不需要將所有事物結構化為映射和化簡作業。
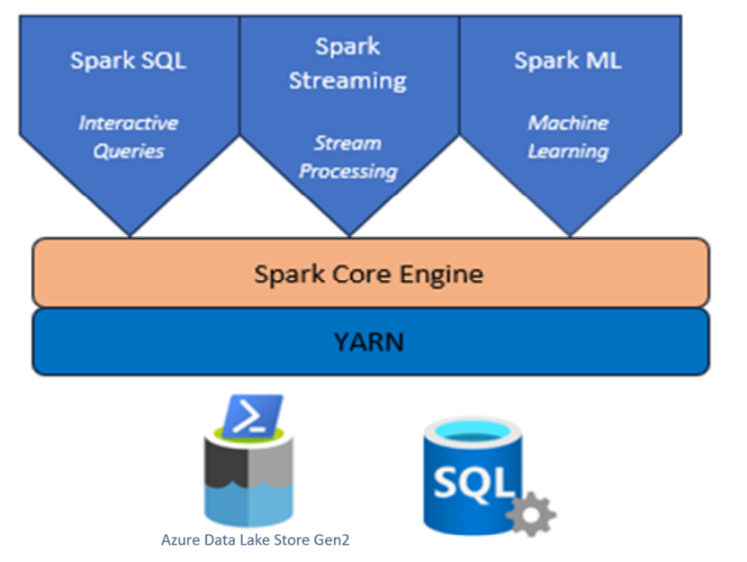
在 AKS 上使用 HDInsight 的 Apache Spark 叢集
Azure HDInsight 是企業受控、全方位、開放原始碼的分析服務。
AKS 上的 Microsoft Azure HDInsight 中的 Apache Spark™ 是 Microsoft Azure 的受管理 Spark 服務。 透過 AKS 上的 Azure HDInsight 中的 Apache Spark,您可以在 Azure 中儲存及處理所有數據。 HDInsight 中的 Spark 叢集與 Azure Data Lake Storage Gen2 相容或,可讓您在現有的數據存放區上套用 Spark 處理。
AKS 上的 HDInsight Apache Spark 架構可使用記憶體內部處理來快速數據分析和叢集運算。 Jupyter Notebook 可讓您與數據互動、將程式代碼與 Markdown 文字結合,以及執行簡單的視覺效果。
在 HDInsight 中的 AKS 上,Apache Spark 由多個作為 Pod 的元件組成。
叢集控制器
叢集控制器負責安裝和管理個別服務。 在Spark叢集中安裝及管理各種控制器。
Apache Spark 服務元件
Zookeeper 服務: 三個節點 Zookeeper 叢集,可作為其他服務的分散式協調器或高可用性記憶體。
Yarn 服務: Hadoop Yarn 叢集,Spark 作業會在叢集中排程為 Yarn 應用程式。
用戶端介面: AKS 上 HDInsight 中的 Apache Spark 叢集提供各種用戶端介面。 Livy Server、Jupyter Notebook、Spark 歷程記錄伺服器,為 AKS 使用者上的 HDInsight 提供 Spark 服務。
參考
- Apache、Apache Spark、Spark 和相關開放原始碼專案名稱 是 Apache Software Foundation (ASF) 商標。