2020 年 7 月
這些功能和 Azure Databricks 平台改善功能於 2020 年 7 月發行。
注意
分階段發行。 您的 Azure Databricks 帳戶可能要到初始發行日期後至多一週才會更新。
網路終端機 (公開預覽)
2020 年 7 月 29 日至 8 月 4 日:版本 3.25
網路終端機為具有叢集上的 CAN ATTACH TO 權限的使用者提供一種便捷且高度互動的方式來執行殼層命令,包括 Vim 或 Emacs 等編輯器。 使用網路終端機的範例包括監視資源使用狀況和安裝 Linux 套件。
如需詳細資料,請參閱在 Azure Databricks 網路終端機中執行殼層命令。
更安全的全新全域 init 指令架構 (公開預覽)
2020 年 7 月 29 日至 8 月 4 日:版本 3.25
新的全域 init 指令碼架構相對於舊的全域 init 指令碼進行了大幅改善:
- Init 指令碼更安全,需要系統管理員權限才能進行建立、檢視和刪除作業。
- 記錄與指令碼相關的啟動失敗。
- 您可以設定多個 init 指令碼的執行順序。
- Init 指令碼可以參考叢集相關的環境變數。
- 您可以使用系統管理員設定頁面或新的全域 Init 指令碼 REST API 建立和管理 init 指令碼。
Databricks 建議您將現有的舊版全域 init 指令碼移轉至新架構,以利用這些改善。
如需詳細資訊,請參閱 全域 init 腳本。
IP 存取清單現已正式發行
2020 年 7 月 29 日 - 8 月 4 日:版本 3.25
IP 存取清單 API 現已正式推出。
GA 版本包含一項變更,即重新命名 list_type 值:
- 按
WHITELIST移至ALLOW - 按
BLACKLIST移至BLOCK
使用 IP 存取清單 API 設定 Azure Databricks 工作區,以便使用者僅透過具有安全界限的現有公司網路連線至服務。 Azure Databricks 系統管理員可以使用 IP 存取清單 API 來定義一組已核准的 IP 位址,包括允許清單和封鎖清單。 對 Web 應用程式和 REST API 的所有傳入存取都要求使用者從經授權的 IP 位址進行連線,從而保證使用者只有使用 VPN 才能從咖啡店或機場等公用網路存取工作區。
此功能需要進階版方案。
如需詳細資訊,請參閱設定工作區的 IP 存取清單。
新增檔案上傳對話方塊
2020 年 7 月 29 日 - 8 月 4 日:版本 3.25
現在,您可以上傳小型表格式資料檔案 (例如 CSV),並透過筆記本進行存取,方法是從筆記本 [檔案] 功能表選取 [新增資料]。 產生的程式碼會說明如何將資料載入到 Pandas 或 DataFrames 中。 系統管理員可以在管理主控台的 [進階] 索引標籤上停用此功能。
如需詳細資訊,請參閱瀏覽 DBFS 中的檔案。
SCIM API 篩選和排序改良
2020 年 7 月 29 日至 8 月 4 日:版本 3.25
SCIM API 現在包含以下篩選和排序改善:
- 管理使用者可以根據
active屬性篩選使用者。 - 所有使用者都可以使用
sortBy和sortOrder查詢參數對結果進行排序。 預設值為 [依識別碼排序]。
已新增 Azure Government 區域
2020 年 7 月 25 日
最近,我們在 US Gov 亞利桑那州和 US Gov 維吉尼亞州區域為美國政府機構及其合作夥伴提供了 Azure Databricks。
Databricks Runtime 7.1 已正式發行
2020 年 7 月 21 日
在 Databricks Runtime 7.0 的基礎上,Databricks Runtime 7.1 引入了許多額外的功能和改進,包括:
- Google BigQuery 連接器
%pip命令用於管理在筆記本工作階段中安裝的 Python 程式庫- 已安裝 Koalas
- 許多 Delta Lake 改善,包括:
- 設定使用者定義的認可中繼資料
- 取得由目前
SparkSession編寫的最後一個認可的版本 - 使用
_spark_metadata交易記錄由結構化串流建立的 Parquet 資料表 MERGE INTO效能改善
如需詳細資料,請參閱完整的 Databricks Runtime 7.1 (EoS) 版本資訊。
Databricks Runtime 7.1 ML 已正式發行
2020 年 7 月 21 日
適用於機器學習的 Databricks Runtime 7.1 基於 Databricks Runtime 7.1 組建,並引入了下列新功能和程式庫變更:
- 預設啟用 pip 和 conda magic 命令
- spark-tensorflow-distributor:0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
如需詳細資料,請參閱完整的適用於 ML 的 Databricks Runtime 7.1 (EoS) 版本資訊。
Databricks Runtime 7.1 Genomics 已正式發行
2020 年 7 月 21 日
適用於 Genomics 的 Databricks Runtime 7.1 基於 Databricks Runtime 7.1 組建,並引入了下列新功能:
- LOCO 轉換
- GloWGR 輸出重塑函數
- RNASeq 輸出未配對對齊
Databricks Connect 7.1 (公開預覽)
2020 年 7 月 17 日
Databricks Connect 7.1 現在為公開預覽版。
IP 存取清單 API 更新
2020 年 7 月 15 日至 21 日:版本 3.24
下列 IP 存取清單 API 屬性已變更:
- 按
updator_user_id移至updated_by - 按
creator_user_id移至created_by
Python 筆記本現在支援每個儲存格的多個輸出
2020 年 7 月 15 日至 21 日:版本 3.24
Python 筆記本現在支援每個儲存格多個輸出。 這意味著一個儲存格中可以有任何數量的 display、displayHTML 或 print 陳述式。 利用此功能,可以在相同儲存格中檢視未經處理資料和繪圖,或檢視在遇到錯誤之前成功列印的所有輸出。
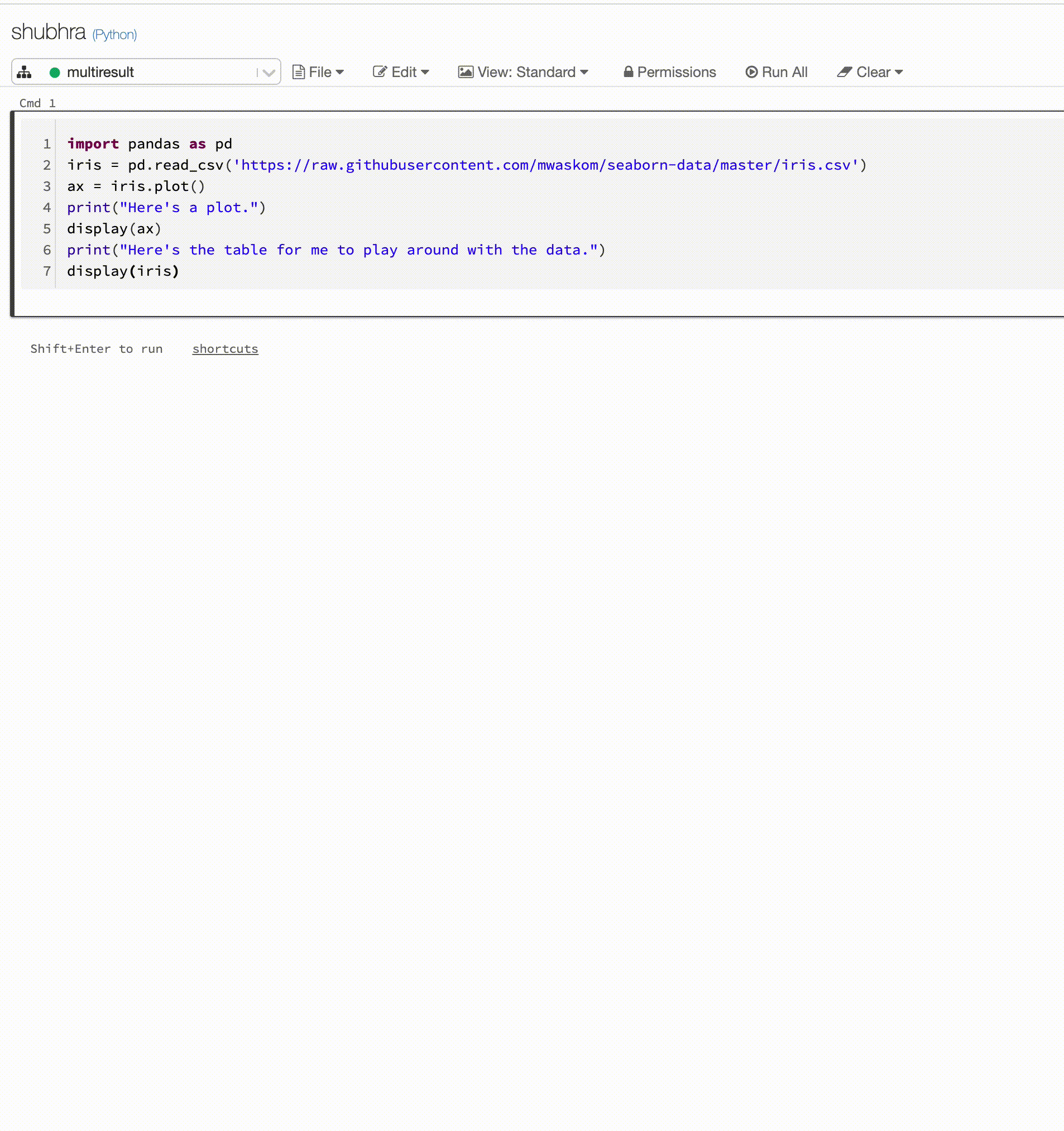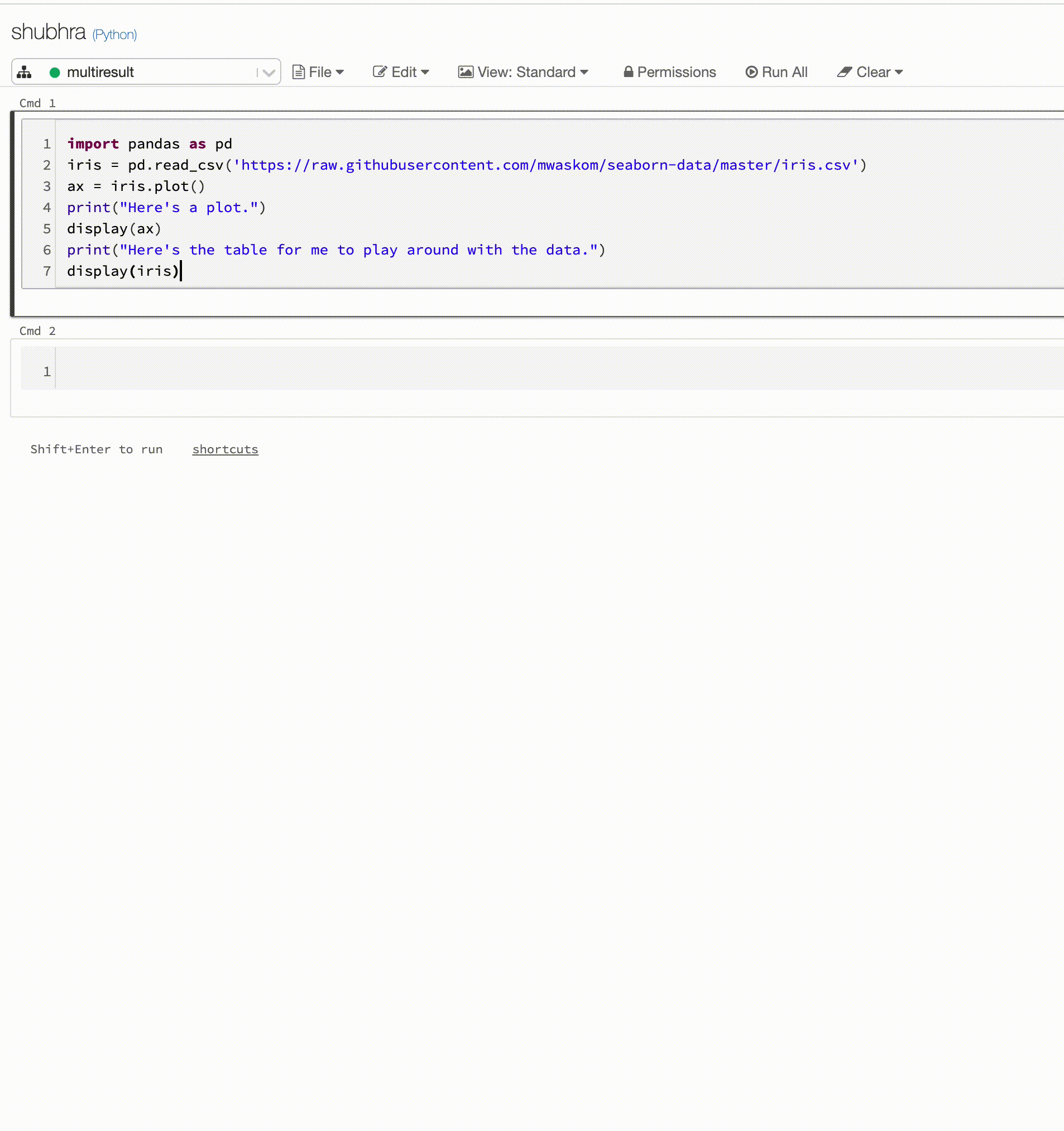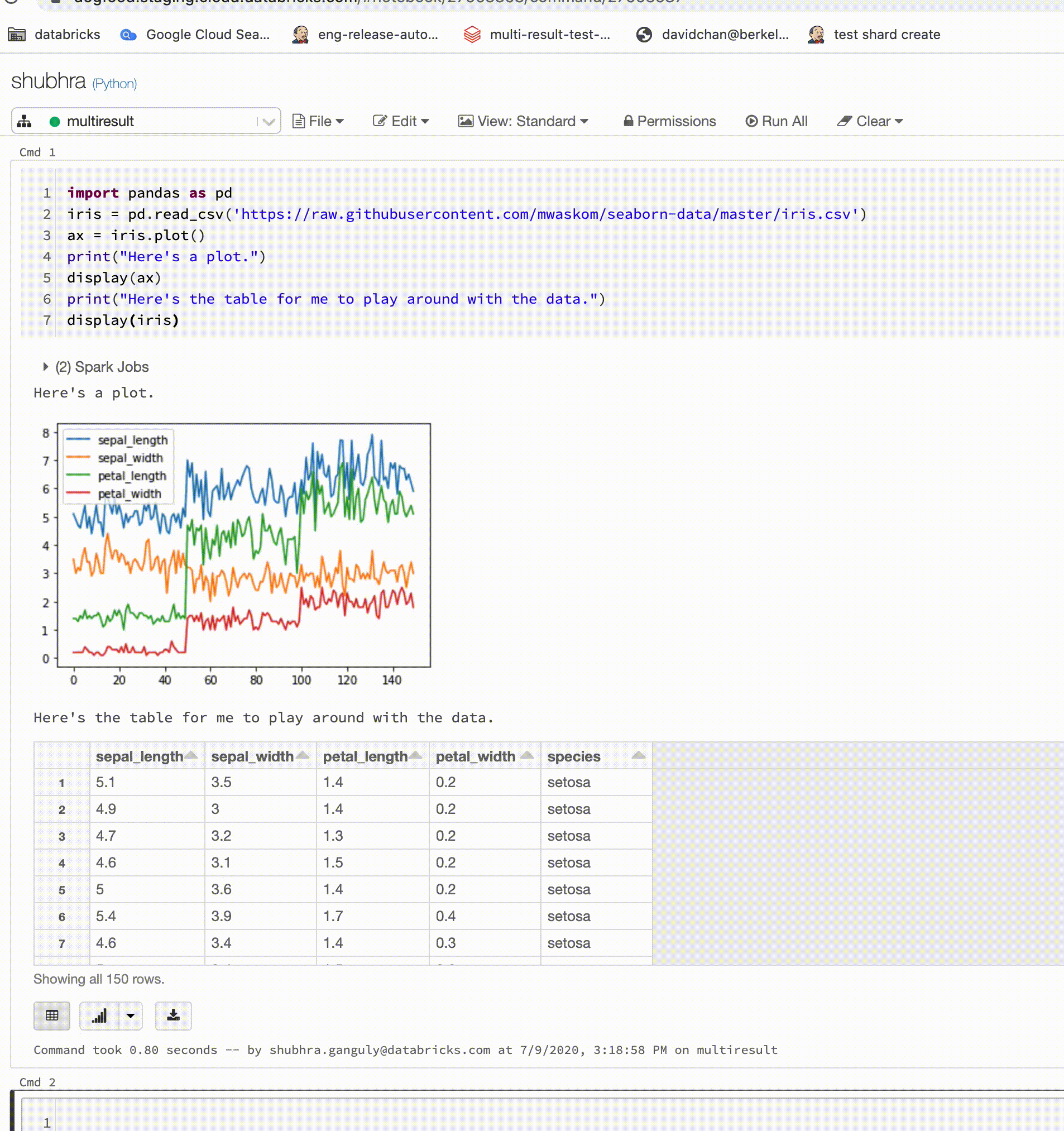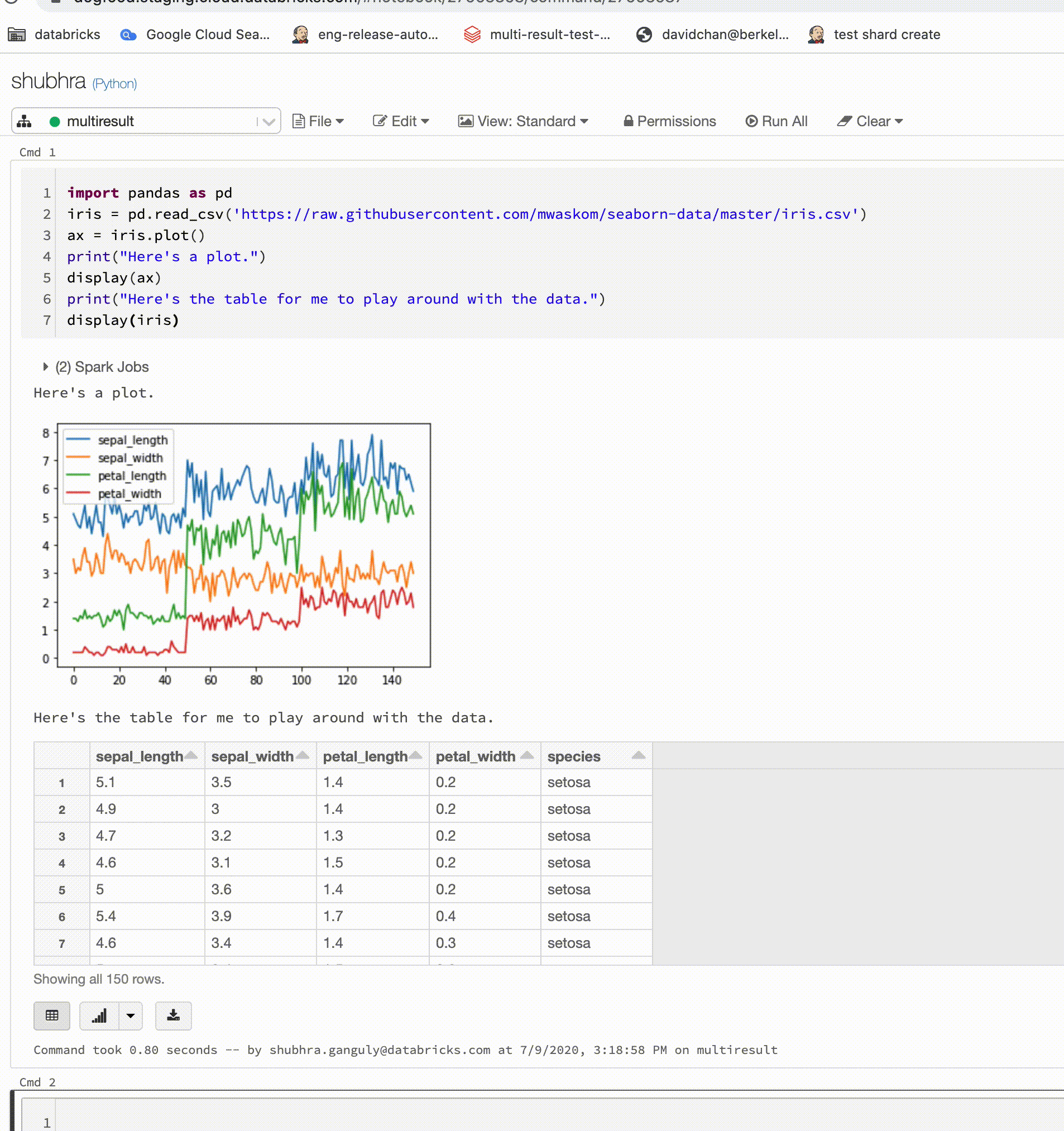
此功能需要 Databricks Runtime 7.1 或更新版本,並且在 Databricks Runtime 7.1 中預設處於停用狀態。 透過設定 spark.databricks.workspace.multipleResults.enabled true 來加以啟用。
並排檢視筆記本程式碼和結果儲存格
2020 年 7 月 15 日至 21 日:版本 3.24
新的 [並排] 筆記本顯示選項可讓您檢視彼此相鄰的程式碼和結果。 此顯示選項將 [標準] 選項 (先前稱為「程式碼」) 和 [僅限結果] 選項結合在一起。
暫停工作排程
2020 年 7 月 15 日至 21 日:版本 3.24
現在,作業排程具有 [暫停] 和 [取消暫停] 按鈕,可讓您輕鬆地暫停和繼續作業。 現在,您可以對作業排程進行變更,在進行變更時不會啟動額外的作業執行。 目前執行或由 [立即執行] 觸發的執行不受影響。 如需詳細資料,請參閱暫停和繼續工作觸發程序。
工作 API 端點驗證執行 ID
2020 年 7 月 15 日至 21 日:版本 3.24
jobs/runs/cancel 和 jobs/runs/output API 端點現在會驗證 run_id 參數是否有效。 對於無效參數,這些 API 端點現在傳回 HTTP 狀態碼 400,而非程式碼 500。
授權 Databricks REST API 的 Microsoft Entra ID 權杖已正式發行
2020 年 7 月 15 日至 21 日:版本 3.24
現在已正式推出使用 Microsoft Entra ID 權杖向工作區 API 進行驗證的功能。 Microsoft Entra ID 權杖可讓您對新工作區的建立和設定進行自動化。 服務主體是 Microsoft Entra ID 中的應用程式物件。 您還可以使用 Azure Databricks 工作區中的服務主體自動化工作流程。 如需詳細資料,請參閱對 Azure Databricks 資源的存取進行驗證。
自動格式化筆記本中的 SQL
2020 年 7 月 15 日至 21 日:版本 3.24
現在您可以透過鍵盤快速鍵、命令內容功能表和筆記本 [編輯] 功能表 (選取 [編輯] > [格式化 SQL 儲存格]) 來格式化 SQL 筆記本儲存格。 SQL 格式化可讓您輕鬆讀取和維護程式碼。 其適用於 SQL 筆記本以及 %sql 儲存格。

Maven 和 CRAN 程式庫的可重現安裝順序
2020 年 7 月 1 日至 9 日:版本 3.23
Azure Databricks 現在會依叢集上安裝 Maven 和 CRAN 程式庫的順序對其進行處理。
使用權杖管理 API 控制使用者的個人存取權杖 (公開預覽)
2020 年 7 月 1 日至 9 日:版本 3.23
現在,Azure Databricks 系統管理員可以使用權杖管理 API 來管理使用者的 Azure Databricks 個人存取權杖:
- 監視和撤銷使用者的個人存取權杖。
- 控制工作區中未來權杖的存留期。
- 控制哪些使用者可以建立和使用權杖。
請參閱 監視和撤銷個人存取令牌。
還原剪接的筆記本儲存格
2020 年 7 月 1 日至 9 日:版本 3.23
現在,您可以使用 (Z) 鍵盤快速鍵或選取 [編輯] > [復原剪下的儲存格],來還原已剪下的筆記本儲存格。 此功能類似於復原已刪除儲存格的功能。
將工作 CAN MANAGE 權限指派給非系統管理員使用者
2020 年 7 月 1 日至 9 日:版本 3.23
現在您可以向非管理使用者和群組指派作業的 CAN MANAGE 權限。 此權限等級可讓使用者管理作業上的所有設定,包括指派權限、變更擁有者和變更叢集組態 (例如,新增程式庫和修改叢集規格)。 請參閱控制對作業的存取。
非管理 Azure Databricks 使用者可以使用 SCIM API 依使用者名稱檢視和篩選
2020 年 7 月 1 日至 9 日:版本 3.23
現在,非管理使用者可以使用 SCIM/使用者端點檢視使用者名稱並依使用者名稱篩選使用者。
檢視工作執行詳細資料時檢視叢集規格的連結
2020 年 7 月 1 日至 9 日:版本 3.23
現在,檢視作業執行的詳細資料時,您可以按一下叢集組態頁面的連結,以檢視叢集規格。 以前,您必須從 URL 複製作業識別碼,然後移至叢集清單進行搜尋。