使用 AutoML 預測 (無伺服器)
重要
這項功能 公開預覽版。
本文說明如何使用馬賽克 AI 模型訓練 UI 執行無伺服器預測實驗。
馬賽克 AI 模型定型 - 預測可藉由自動選取最佳演算法和超參數來簡化預測時間序列數據,同時在完全受控的計算資源上執行。
若要瞭解無伺服器預測與傳統計算預測之間的差異,請參閱 無伺服器預測與傳統計算預測。
要求
使用時間序列 column定型資料,並儲存為 Unity Catalogtable。
如果工作區已啟用安全輸出閘道 (SEG),則必須將
pypi.org新增至 允許的網域list。 請參閱 管理無伺服器輸出控制的網路原則。
使用UI建立預測實驗
前往您的 Azure Databricks 登入頁面,然後按下側邊欄中的 [實驗]。
在 [預測] 圖格中,select[開始訓練]。
Unity
的 訓練數據 ,您可以存取。 -
時間 column:Select 包含時間序列時間週期的 column。
columns 的類型必須是
timestamp或date。 - 預測頻率:Select 代表輸入數據頻率的時間單位。 例如,分鐘、小時、天、月。 這會決定時間序列的數據粒度。
- 預測地平線:指定要預測未來所選頻率的單位數目。 連同預測頻率,這會同時定義要預測的時間單位和時間單位數目。
注意
若要使用 自動 ARIMA 演算法,時間序列必須具有固定頻率,where 且在整個時間序列中,任何兩個點之間的間隔都必須相同。 AutoML 透過用先前的值填入那些遺漏的時間步驟 values 來進行處理。
-
時間 column:Select 包含時間序列時間週期的 column。
columns 的類型必須是
Select 您想要模型預測的 預測目標 column。
您可以選擇性地指定 Unity Catalogtable預測資料路徑 來儲存輸出預測。
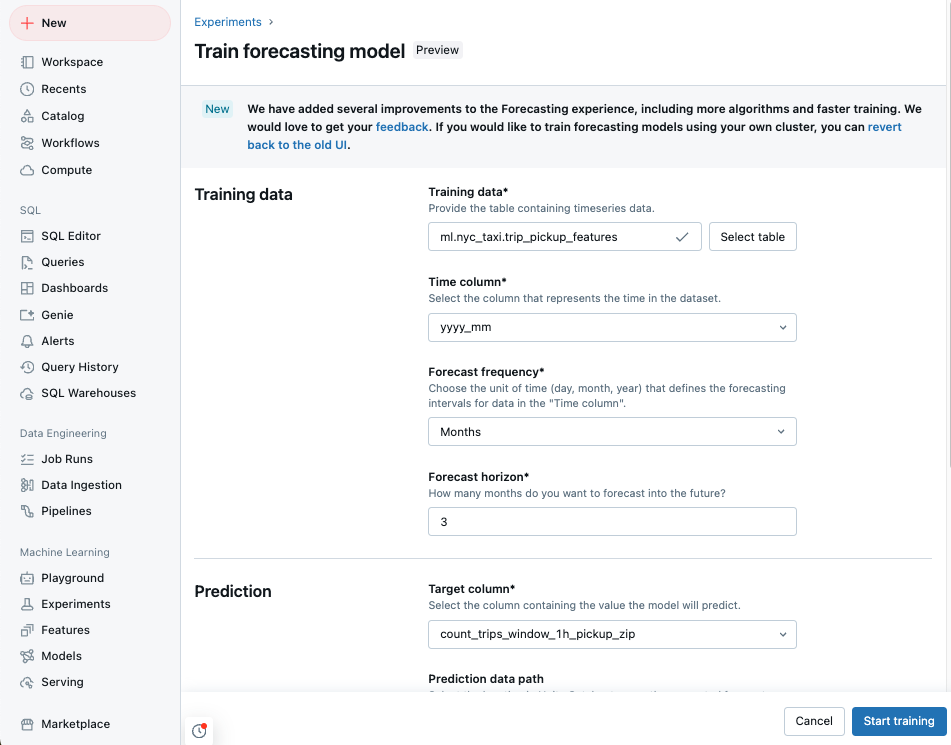
Select 模型註冊 Unity Catalog 位置和名稱。
選擇性 set進階選項:
- 實驗名稱:提供 MLflow 實驗名稱。
- 時間序列 identifiercolumns - 針對多序列預測,select 識別個別時間序列的 column(s) 。 Databricks 會將這些 columns 的數據分組為不同的時間序列,並個別定型每個數列的模型。
- 主要計量:選擇用來評估和 select 最佳模型的主要計量。
- 訓練架構:選擇要探索的 AutoML 架構。
- 分割 column:Select 包含自定義數據分割的 column。 Values 必須是 “train”、“validate”、“test”
- 權數 column:指定要用於加權時間序列的 column。 指定時間序列的所有範例都必須具有相同的權數。 重量必須介於[0-10000]範圍內。
- 假日區域:Select 用於模型訓練中作為共變量的假日區域。
- 逾時:Set AutoML 實驗的最大持續時間。
執行實驗並監視結果
若要啟動 AutoML 實驗,請按兩下 [開始訓練] 。 您可以從實驗訓練頁面執行下列動作:
- 隨時停止實驗。
- 監控正在運行。
- 流覽至任何回合的執行頁面。
檢視結果或使用最佳模型
訓練完成之後,預測結果會被儲存在指定的 Delta table,並且將最佳模型註冊到 Unity Catalog。
從實驗頁面,您可以選擇下列後續步驟:
- Select 檢視預測 以查看預測結果 table。
- Select 批次推斷筆記本,開啟自動生成的筆記本以使用最佳模型進行批次推斷。
- Select 建立服務端點,將最佳模型部署至模型服務端點。
無伺服器預測與傳統計算預測
下列 table 摘要說明無伺服器預測與傳統計算 預測之間的差異
| 特徵 | 無伺服器預測 | 傳統計算預測 |
|---|---|---|
| 計算基礎結構 | Azure Databricks 會管理計算組態,並自動針對成本和效能進行優化。 | 用戶設定的運算 |
| 統轄 | 向 Unity 註冊的模型和工件 Catalog | 用戶設定的工作區檔案儲存庫 |
| 演算法選擇 | 統計模型 加上深度學習類神經網路演算法,DeepAR | 統計模型 |
| 功能存放區整合 | 不支援 | 支援 |
| 自動產生的筆記本 | 批次推斷筆記本 | 所有試用版的原始程式碼 |
| 單鍵模型服務部署 | 支援 | 不支援 |
| 自定義訓練/驗證/測試分割 | 支援 | 不支援 |
| 個別時間序列的自訂權重 | 支援 | 不支援 |