使用時間序列特徵資料表的時間點支援
本文說明如何使用時間點正確性來建立定型數據集,以在記錄卷標觀察時正確反映特徵值。 這對於防止 數據外洩很重要,當您針對記錄標籤時無法使用的模型定型使用特徵值時,就會發生這種情況。 這種類型的錯誤可能很難偵測,而且可能會對模型的效能造成負面影響。
時間序列特徵資料表包括時間戳記索引鍵資料行,可確保訓練資料集中的每個資料列都表示截至資料列時間戳記時的最新已知特徵值。 每當特徵值隨著時間變更時,您應該使用時間序列特徵資料表,例如時間序列資料、事件型資料或時間彙總資料。
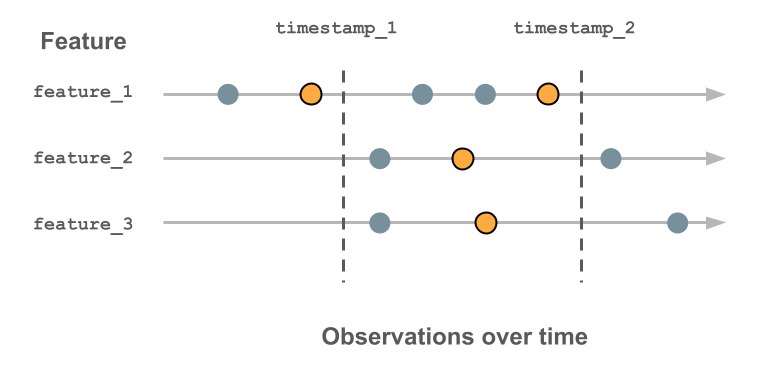
下圖顯示時間戳密鑰的使用方式。 針對每個時間戳記錄的功能值是該時間戳之前的最新值,以外框的橙色圓圈表示。 如果未記錄任何值,則特徵值為 null。 如需詳細資訊,請參閱 時間序列功能數據表的運作方式。
注意
- 使用 Databricks Runtime 13.3 LTS 和更新版本時,Unity Catalog 中具有主索引鍵和時間戳記索引鍵的任何差異資料表都可以用作時間序列特徵資料表。
- 為了提升時間點查詢的效能,Databricks 建議您在時間序列資料表上套用 Liquid 叢集 (適用於
databricks-feature-engineering0.6.0 和更新版本) 或 Z 軸排序 (適用於databricks-feature-engineering0.6.0 和更低版本)。 - 時間點查閱功能有時稱為「時間旅行」。 Databricks 特徵存放區中的時間點功能與 Delta Lake 時間旅行無關。
時間序列功能數據表的運作方式
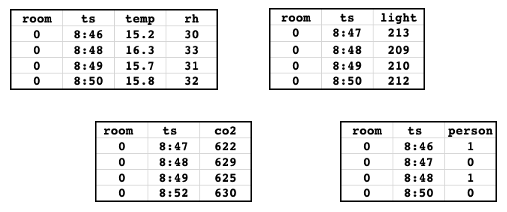
假設您擁有下列特徵資料表。 此資料取自範例筆記本。
資料表包含測量室內的溫度、相對濕度、環境光線和二氧化碳的感應器資料。 基準真實資料表指出房間裡是否有人。 每個資料表都有主索引鍵 ('room') 和時間戳記索引鍵 ('ts')。 為了簡單起見,僅會顯示主索引鍵 ('0') 單一值的資料。
下圖說明如何使用時間戳記索引鍵來確保訓練資料集中的時間點正確性。 使用 AS OF 聯結,根據主索引鍵 (圖表中未顯示) 和時間戳記索引鍵來比對特徵值。 AS OF 聯結可確保在訓練集中使用時間戳記時特徵的最新值。
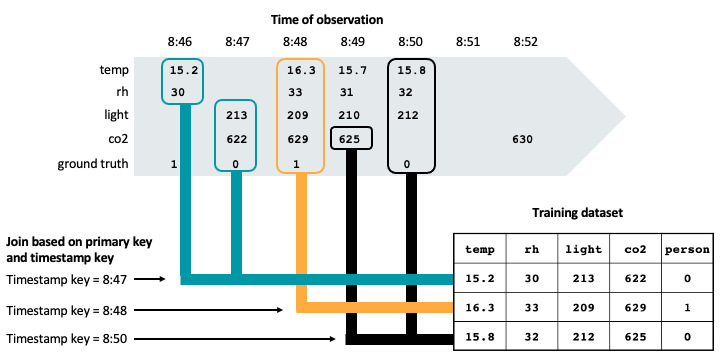
如圖所示,訓練資料集包括每個感應器在觀測的基準真實時間戳記之前的最新特徵值。
如果您建立訓練資料集而不考慮時間戳記索引鍵,您可能會得到一個具有這些特徵值和觀測的基準真實的資料列:
| temp | rh | light | co2 | 基準真實 |
|---|---|---|---|---|
| 15.8 | 32 | 212 | 630 | 0 |
然而,這不是訓練的有效觀測,因為 8:52 擷取的 co2 讀數為 630,而此時間是在基準真實的觀測時間 8:50 之後。 未來的資料會「外洩」到訓練集,而這會影響模型的效能。
需求
- 針對 Unity Catalog 中的特徵工程:Unity 類別目錄中的特徵工程用戶端 (任何版本)。
- 針對工作區特徵存放區 (舊版):特徵存放區客戶端 v0.3.7 及以上版本。
如何指定時間相關的索引鍵
若要使用時間點功能,您必須使用 timeseries_columns 引數 (對於 Unity Catalog 中的特徵工程) 或 timestamp_keys 引數 (對於工作區特徵存放區) 來指定時間相關的索引鍵。 這表示特徵資料表資料列應該藉由比對不晚於 timestamps_keys 資料行值的特定主索引鍵的最新值來聯結,而不是根據確切的時間比對來聯結。
如果您不使用 timeseries_columns 或 timestamp_keys,而且僅將時間序列資料行指定為主索引鍵資料行,則特徵存放區不會在聯結期間將時間點邏輯套用至時間序列資料行。 相反地,其僅會比對具有確切時間比對的資料列,而不是比對時間戳記之前的所有資料列。
在 Unity Catalog 中建立時間序列特徵資料表
在 Unity Catalog 中,具有 TIMESERIES 主索引鍵的任何資料表都是時間序列特徵資料表。 請參閱 在 Unity Catalog 中建立特徵資料集,了解如何建立一個。
在本機工作區中建立時間序列特徵資料表
若要在本機工作區特徵存放區中建立時間序列特徵資料表,DataFrame 或結構描述必須包含您指定為時間戳記索引鍵的資料行。
從特徵存放區用戶端 v0.13.4 開始,必須在 primary_keys 引數中指定時間戳記索引鍵資料行。 時間戳記索引鍵是「主索引鍵」的一部分,可唯一識別特徵資料表中的每個資料列。 與其他主索引鍵資料行一樣,時間戳記索引鍵資料行不能包含 NULL 值。
Unity Catalog 中的特徵工程
fe = FeatureEngineeringClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.create_table(
name="ml.ads_team.user_features",
primary_keys=["user_id", "ts"],
timeseries_columns="ts",
features_df=user_features_df,
)
工作區特徵存放區用戶端 v0.13.4 和更新版本
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys=["user_id", "ts"],
timestamp_keys="ts",
features_df=user_features_df,
)
工作區特徵存放區用戶端 v0.13.3 和更低版本
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys="user_id",
timestamp_keys="ts",
features_df=user_features_df,
)
時間序列特徵資料表必須有一個時間戳記索引鍵,而且不能有任何分割區資料行。 時間戳記索引鍵資料行必須是 TimestampType 或 DateType。
Databricks 建議時間序列特徵資料表不得擁有超過兩個主索引鍵資料行,以確保高效能寫入和查詢。
更新時間序列特徵資料表
與一般特徵資料表不同,將特徵寫入時間序列特徵資料表時,您的 DataFrame 必須提供特徵資料表的所有特徵值。 此條件約束可減少時間序列特徵資料表中時間戳記之間的特徵值的稀疏性。
Unity Catalog 中的特徵工程
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
工作區特徵存放區用戶端 v0.13.4 和更新版本
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
支援串流寫入時間序列特徵資料表。
使用時間序列特徵資料表建立訓練
若要對時間序列特徵資料表中的特徵值執行時間點查詢,您必須在特徵的 timestamp_lookup_key 中指定 FeatureLookup,指出包含要查詢時間序列特徵之時間戳記的 DataFrame 資料行名稱。 Databricks 特徵存放區會在 DataFrame 的 timestamp_lookup_key 資料行中指定的時間戳記之前擷取最新的特徵值,且其主索引鍵 (時間戳記索引鍵除外) 符合 DataFrame 的 lookup_key 資料行中的值,或者如果沒有此類特徵值,則為 null。
Unity Catalog 中的特徵工程
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
提示
若要在啟用 Photon 時獲得更快的查詢效能,請將 use_spark_native_join=True 傳遞至 FeatureEngineeringClient.create_training_set。 這需要 databricks-feature-engineering 或 0.6.0 版或更新版本。
工作區特徵存放區
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
時間序列特徵資料表上的任何 FeatureLookup 都必須是時間點查詢,因此它必須指定要在 DataFrame 中使用的 timestamp_lookup_key 資料行。 時間點查詢不會略過時間序列特徵資料表中具有 null 特徵值的資料列。
設定歷程記錄特徵值的使用時間限制
使用特徵存放區用戶端 v0.13.0 或更新版本,或 Unity Catalog 用戶端中的任何特徵工程版本,您可以從訓練集中排除時間戳記較舊的特徵值。 若要這樣做,請使用 lookback_window 中的參數 FeatureLookup。
lookback_window 的資料類型必須是 datetime.timedelta,且預設值為 None (不論年齡為何,都會使用所有特徵值)。
例如,下列程式碼會排除任何超過 7 天的特徵值:
Unity Catalog 中的特徵工程
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
工作區特徵存放區
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
當您使用上述 create_training_set 呼叫 FeatureLookup 時,其會自動執行時間點聯結,並排除超過 7 天的特徵值。
回顧視窗會在訓練和批次推斷期間套用。 在線上推斷期間,不論回顧視窗為何,一律會使用最新的特徵值。
使用時間序列特徵資料表為模型評分
當您為使用時間序列特徵資料表中的特徵訓練的模型進行評分時,Databricks 特徵存放區會搭配使用時間點查詢和訓練期間與模型封裝的中繼資料,來擷取適當的特徵。 您提供給 FeatureEngineeringClient.score_batch 的 DataFrame (對於 Unity Catalog 中的特徵工程) 或 FeatureStoreClient.score_batch (對於工作區特徵存放區) 必須包含時間戳記資料行,且名稱和 DataType 與提供給 timestamp_lookup_key 或FeatureLookup 的 FeatureEngineeringClient.create_training_set 的 FeatureStoreClient.create_training_set 相同。
提示
若要在啟用 Photon 時獲得更快的查詢效能,請將 use_spark_native_join=True 傳遞至 FeatureEngineeringClient.score_batch。 這需要 databricks-feature-engineering 或 0.6.0 版或更新版本。
將時間序列特徵發佈至線上存放區
您可以使用 FeatureEngineeringClient.publish_table (對於 Unity Catalog 中的特徵工程) 或 FeatureStoreClient.publish_table (對於工作區特徵存放區) 將時間序列特徵資料表發佈至線上存放區。 Databricks 特徵存放區會將特徵資料表中每個主索引鍵的最新特徵值快照發佈至線上存放區。 線上存放區支援主索引鍵查詢,但不支援時間點查詢。
筆記本範例:時間序列特徵資料表
這些範例筆記本說明時間序列特徵資料表的時間點查詢。
在已啟用 Unity Catalog 的工作區中使用此筆記本。
時間序列特徵資料表範例筆記本 (Unity Catalog )
下列筆記本設計用於未針對 Unity Catalog 啟用的工作區。 其會使用工作區特徵存放區。