什麼是自動載入器檔案通知模式?
在檔案通知模式中,自動載入器會自動設定通知服務和佇列服務,以訂閱輸入目錄中的檔案事件。 您可以使用檔案通知,將自動載入器調整為每小時擷取數百萬個檔案。 相較於目錄清單模式,對於大型輸入目錄或大量檔案,檔案通知模式會更有效能且可調整,但需要額外的雲端許可權。
您可以隨時在檔案通知和目錄列表之間切換,並仍維持一次完全一次的數據處理保證。
注意
Azure 進階記憶體帳戶不支援檔案通知模式,因為進階帳戶不支援佇列記憶體。
警告
檔案通知模式不支援變更自動載入器 的來源路徑。 如果使用檔案通知模式並變更路徑,您可能無法擷取在目錄更新時已存在於新目錄中的檔案。
自動載入器檔案通知模式中使用的雲端資源
重要
您需要提高的許可權,才能自動設定檔案通知模式的雲端基礎結構。 請連絡您的雲端系統管理員或工作區管理員。看:
當您設定 選項cloudFiles.useNotificationstrue並提供建立雲端資源所需的許可權時,自動載入器可以為您設定檔案通知。 此外,您可能需要提供 其他選項 ,以授與自動載入器授權以建立這些資源。
下表摘要說明自動載入器所建立的資源。
| 雲端存放裝置 | 訂用帳戶服務 | 佇列服務 | 前置碼* | 限制** |
|---|---|---|---|---|
| Amazon S3 | AWS SNS | AWS SQS | databricks-auto-ingest | 每個 S3 貯體 100 個 |
| ADLS Gen2 | 事件格線 | Azure 佇列儲存體 | databricks | 每個記憶體帳戶 500 個 |
| GCS | Google Pub/Sub | Google Pub/Sub | databricks-auto-ingest | 每個 GCS 貯體 100 個 |
| Azure Blob 儲存體 | 事件格線 | Azure 佇列儲存體 | databricks | 每個記憶體帳戶 500 個 |
- 自動載入器會使用此前置詞來命名資源。
** 可以啟動多少個並行檔案通知管線
如果您需要針對指定的記憶體帳戶執行超過有限的檔案通知管線數目,您可以:
- 利用像 AWS Lambda、Azure Functions 或 Google Cloud Functions 這類服務,將從接收整個容器或儲存桶的單一佇列中收到的通知分發到特定目錄的佇列中。
檔案通知事件
Amazon S3 會在檔案上傳至 S3 儲存桶時觸發 ObjectCreated 事件,無論檔案是透過 PUT 或多部分上傳方式上傳。
ADLS Gen2 會針對出現在 Gen2 容器中的檔案提供不同的事件通知。
- 自動載入器會接
FlushWithClose聽事件以處理檔案。 - 自動載入器數據流支援
RenameFile探索檔案的動作。RenameFile動作需要記憶體系統的 API 要求,才能取得重新命名檔案的大小。 - 使用 Databricks Runtime 9.0 建立的自動載入器數據流,以及支援探索檔案的
RenameDirectory動作之後。RenameDirectory動作需要記憶體系統的 API 要求,才能列出重新命名目錄的內容。
Google Cloud Storage 會在上傳檔案時提供 OBJECT_FINALIZE 事件,其中包括覆寫和檔案複本。 上傳失敗時不會產生此事件。
注意
雲端提供者不保證在非常罕見的情況下,100% 傳遞所有檔案事件,也不會針對檔案事件的延遲提供嚴格的 SLA。 Databricks 建議您使用 選項來觸發自動載入器 cloudFiles.backfillInterval 一般回填,以確保在數據完整性是必要條件時,在指定的 SLA 內探索到所有檔案。 觸發一般回填不會造成重複。
設定 ADLS Gen2 和 Azure Blob 儲存體 檔案通知的必要許可權
您必須具有輸入目錄的讀取許可權。 請參閱 Azure Blob 儲存體。
若要使用檔案通知模式,您必須提供驗證認證,才能設定和存取事件通知服務。
您可以使用下列其中一種方法進行驗證:
- Databricks 服務認證(建議):使用受控識別和 Databricks 存取連接器建立 服務認證。
- 服務主體:以用戶端標識符和客戶端密碼的形式,建立 Microsoft Entra ID(先前稱為 Azure Active Directory)應用程式和服務 主體。
取得驗證認證之後,請將必要的許可權指派給 Databricks 存取連接器(適用於服務認證)或Microsoft Entra ID 應用程式(適用於服務主體)。
使用 Azure 內建角色
將下列角色指派給輸入路徑所在記憶體帳戶的存取連接器:
- 參與者:此角色適用於在您的記憶體帳戶中設定資源,例如佇列和事件訂用帳戶。
- 記憶體佇列數據參與者:此角色適用於執行佇列作業,例如從佇列擷取和刪除訊息。 只有在您提供不含 連接字串 的服務主體時,才需要此角色。
將此存取連接器指派給相關的資源群組:
- EventGrid EventSubscription 參與者:此角色適用於執行 Azure 事件方格(事件方格)訂用帳戶作業,例如建立或列出事件訂用帳戶。
如需詳細資訊,請參閱使用 Azure 入口網站指派 Azure 角色。
使用自定義角色
如果您擔心上述角色所需的許可權過多,您可以建立 至少具有下列許可權的自定義角色 ,如下所列的 Azure 角色 JSON 格式:
"permissions": [ { "actions": [ "Microsoft.EventGrid/eventSubscriptions/write", "Microsoft.EventGrid/eventSubscriptions/read", "Microsoft.EventGrid/eventSubscriptions/delete", "Microsoft.EventGrid/locations/eventSubscriptions/read", "Microsoft.Storage/storageAccounts/read", "Microsoft.Storage/storageAccounts/write", "Microsoft.Storage/storageAccounts/queueServices/read", "Microsoft.Storage/storageAccounts/queueServices/write", "Microsoft.Storage/storageAccounts/queueServices/queues/write", "Microsoft.Storage/storageAccounts/queueServices/queues/read", "Microsoft.Storage/storageAccounts/queueServices/queues/delete" ], "notActions": [], "dataActions": [ "Microsoft.Storage/storageAccounts/queueServices/queues/messages/delete", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/read", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/write", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/process/action" ], "notDataActions": [] } ]然後,您可以將此自定義角色指派給您的存取連接器。
如需詳細資訊,請參閱使用 Azure 入口網站指派 Azure 角色。
Amazon S3 設定檔案通知的必要許可權
您必須具有輸入目錄的讀取許可權。 如需詳細資訊,請參閱 S3 連線詳細 數據。
若要使用檔案通知模式,請將下列 JSON 原則檔附加至您的 IAM 使用者或角色。 需要此 IAM 角色,才能建立服務認證,讓自動載入器進行驗證。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderSetup",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:SetTopicAttributes",
"sns:CreateTopic",
"sns:TagResource",
"sns:Publish",
"sns:Subscribe",
"sqs:CreateQueue",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:SetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
},
{
"Sid": "DatabricksAutoLoaderList",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "*"
},
{
"Sid": "DatabricksAutoLoaderTeardown",
"Effect": "Allow",
"Action": [
"sns:Unsubscribe",
"sns:DeleteTopic",
"sqs:DeleteQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
}
]
}
何處:
-
<bucket-name>:您的數據流將讀取檔案的 S3 貯體名稱,例如auto-logs。 您可以使用*作為通配符,例如databricks-*-logs。 若要找出 DBFS 路徑的基礎 S3 貯體,您可以執行%fs mounts來列出筆記本中的所有 DBFS 裝入點。 -
<region>:S3 貯體所在的 AWS 區域,例如us-west-2。 如果您不想指定區域,請使用*。 -
<account-number>:擁有 S3 貯體的 AWS 帳戶號碼,例如123456789012。 如果不想指定帳戶號碼,請使用*。
SQS 和 SNS ARN 規格中的字串 databricks-auto-ingest-* 是來源在建立 SQS 和 SNS 服務時所使用的名稱前置詞 cloudFiles 。 由於 Azure Databricks 會在數據流的初始執行中設定通知服務,因此您可以在初始執行之後使用具有縮減許可權的原則(例如,停止數據流,然後重新啟動它)。
注意
上述原則只涉及設定檔案通知服務所需的許可權,也就是 S3 貯體通知、SNS 和 SQS 服務,並假設您已經具有 S3 貯體讀取許可權。 如果您需要新增 S3 唯讀許可權,請將下列內容新增至 Action JSON 檔案中語句中的清單 DatabricksAutoLoaderSetup :
s3:ListBuckets3:GetObject
初始設定之後的許可權已減少
上述資源設定許可權只有在數據流的初始執行期間才需要。 第一次執行之後,您可以切換至具有縮減許可權的下列 IAM 原則。
重要
由於許可權降低,您無法在發生失敗時啟動新的串流查詢或重新建立資源(例如,SQS 佇列已被意外刪除):您也無法使用雲端資源管理 API 來列出或卸除資源。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderUse",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:TagResource",
"sns:Publish",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:<queue-name>",
"arn:aws:sns:<region>:<account-number>:<topic-name>",
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket-name>/*"
]
},
{
"Sid": "DatabricksAutoLoaderListTopics",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "arn:aws:sns:<region>:<account-number>:*"
}
]
}
設定 GCS 檔案通知的必要許可權
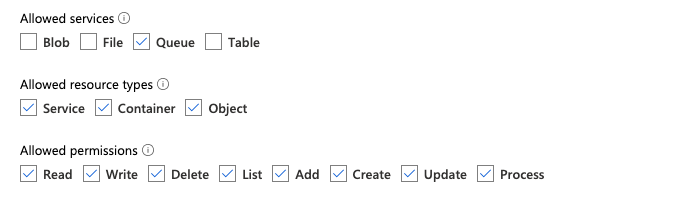
您必須擁有 list GCS 貯體和 get 所有物件的許可權。 如需詳細資訊,請參閱有關 IAM 許可權的 Google 檔。
若要使用檔案通知模式,您必須新增 GCS 服務帳戶的許可權,以及用來存取 Google Cloud Pub/Sub 資源的服務帳戶。
將 Pub/Sub Publisher 角色新增至 GCS 服務帳戶。 這可讓帳戶將來自 GCS 貯體的事件通知訊息發佈至 Google Cloud Pub/Sub。
至於用於Google Cloud Pub/Sub資源的服務帳戶,您需要新增下列許可權。 當您建立 Databricks 服務認證時,系統會自動建立此服務帳戶。
pubsub.subscriptions.consume
pubsub.subscriptions.create
pubsub.subscriptions.delete
pubsub.subscriptions.get
pubsub.subscriptions.list
pubsub.subscriptions.update
pubsub.topics.attachSubscription
pubsub.topics.create
pubsub.topics.delete
pubsub.topics.get
pubsub.topics.list
pubsub.topics.update
若要這樣做,您可以建立具有這些許可權的 IAM 自定義角色,或指派預先存在的 GCP 角色來涵蓋這些許可權。
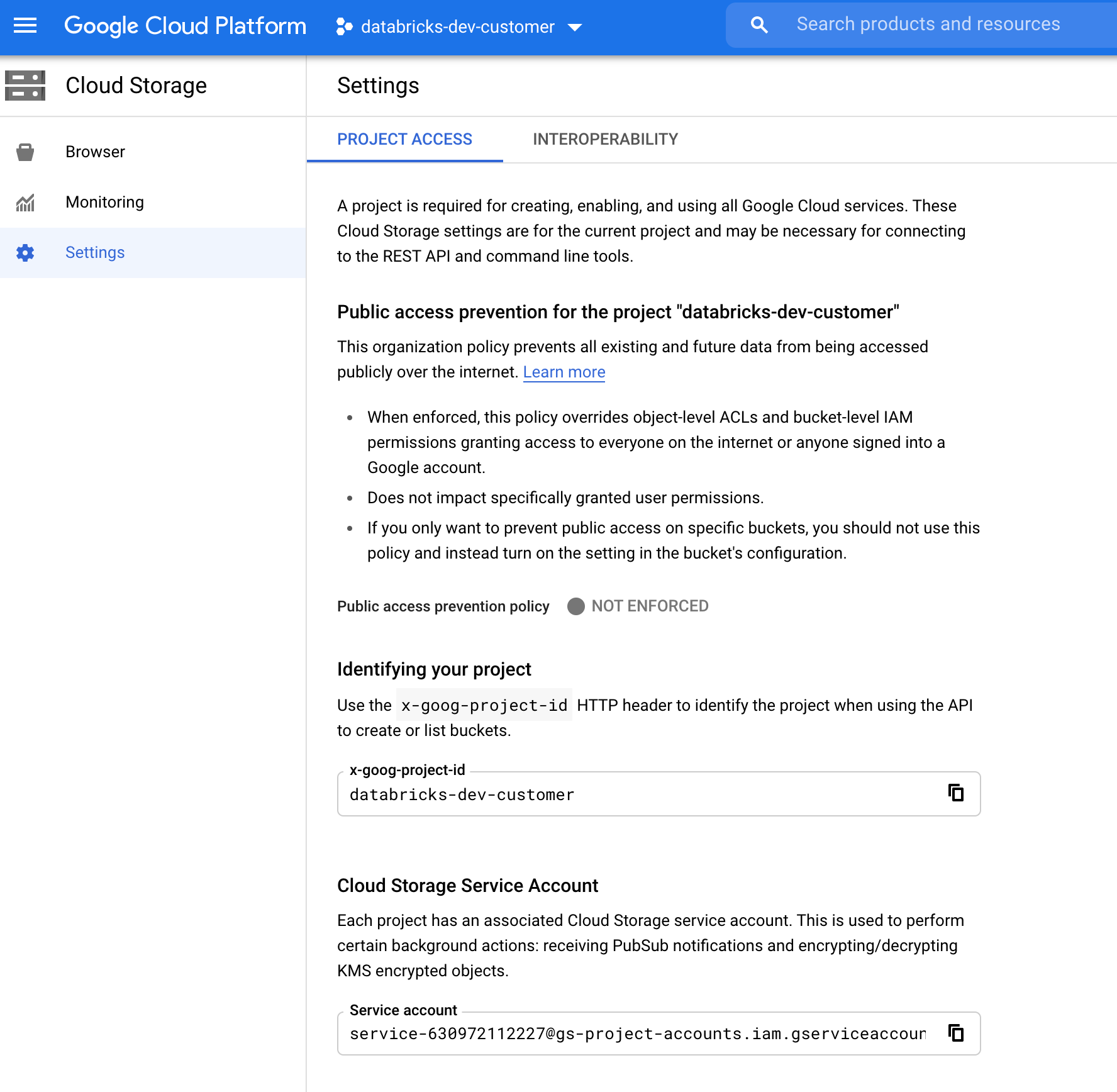
尋找 GCS 服務帳戶
在對應專案的 Google Cloud Console 中,流覽至 Cloud Storage > Settings。
「雲端記憶體服務帳戶」一節包含 GCS 服務帳戶的電子郵件。
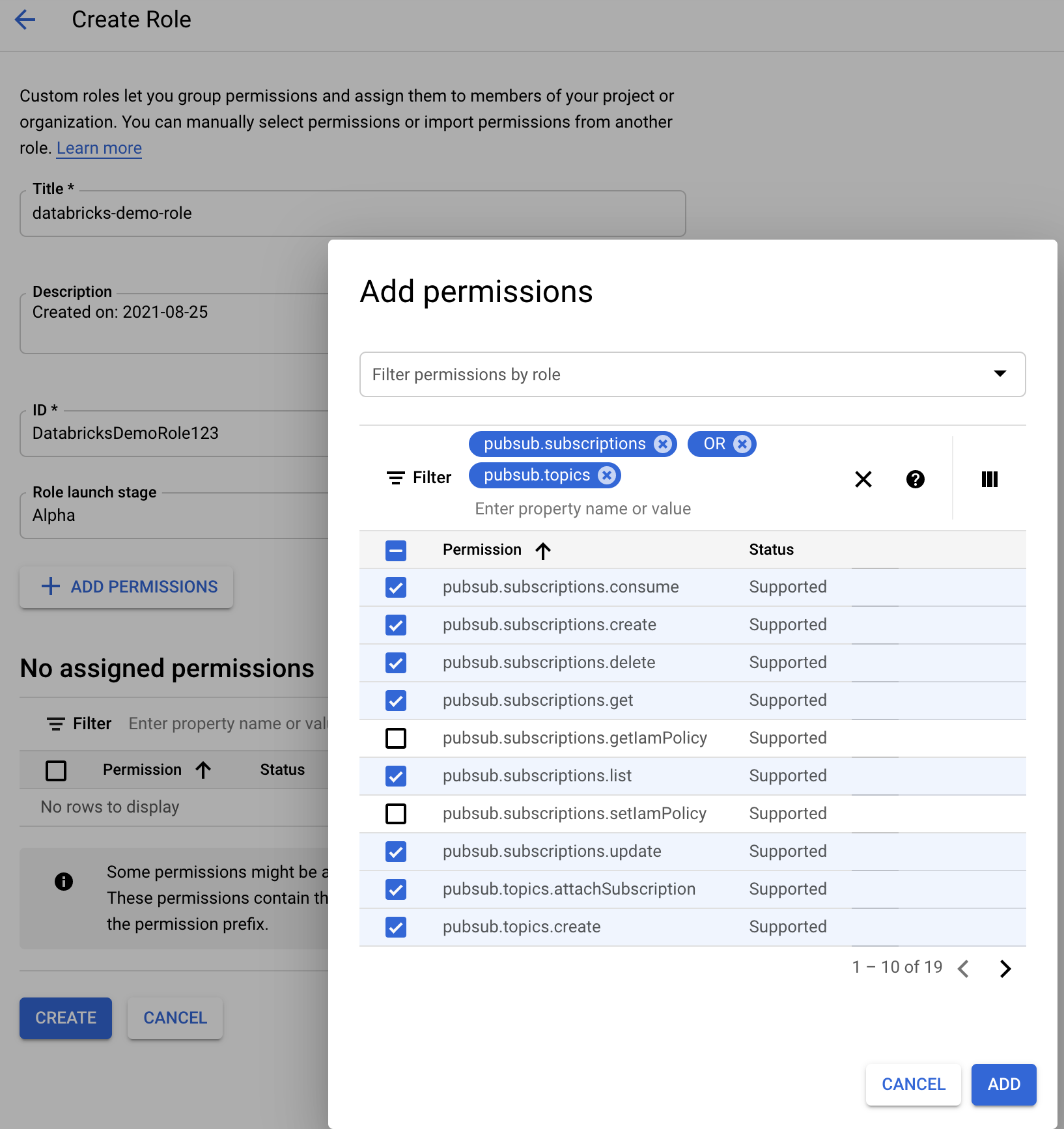
建立檔案通知模式的自定義Google Cloud IAM角色
在對應專案的 Google Cloud 控制台中,瀏覽至 IAM & Admin > Roles。 然後,在頂端建立角色,或更新現有的角色。 在建立或編輯角色的畫面中,按兩下 Add Permissions。 隨即會出現一個功能表,您可以在其中將所需的許可權新增至角色。
手動設定或管理檔案通知資源
特殊許可權使用者可以手動設定或管理檔案通知資源。
- 透過雲端提供者手動設定檔案通知服務,並手動指定佇列標識碼。 如需詳細資訊,請參閱 檔案通知選項 。
- 使用 Scala API 來建立或管理通知和佇列服務,如下列範例所示:
Python
# Databricks notebook source
# MAGIC %md ## Python bindings for CloudFiles Resource Managers for all 3 clouds
# COMMAND ----------
#####################################
## Creating a ResourceManager in AWS
#####################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.create()
# Using AWS access key and secret key
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("cloudFiles.awsAccessKey", <aws-access-key>) \
.option("cloudFiles.awsSecretKey", <aws-secret-key>) \
.option("cloudFiles.roleArn", <role-arn>) \
.option("cloudFiles.roleExternalId", <role-external-id>) \
.option("cloudFiles.roleSessionName", <role-session-name>) \
.option("cloudFiles.stsEndpoint", <sts-endpoint>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in Azure
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
# Using an Azure service principal
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.connectionString", <connection-string>) \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("cloudFiles.tenantId", <tenant-id>) \
.option("cloudFiles.clientId", <service-principal-client-id>) \
.option("cloudFiles.clientSecret", <service-principal-client-secret>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in GCP
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Using a Google service account
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("cloudFiles.client", <client-id>) \
.option("cloudFiles.clientEmail", <client-email>) \
.option("cloudFiles.privateKey", <private-key>) \
.option("cloudFiles.privateKeyId", <private-key-id>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
# List notification services created by <AL>
from pyspark.sql import DataFrame
df = DataFrame(manager.listNotificationServices(), spark)
# Tear down the notification services created for a specific stream ID.
# Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Scala
/////////////////////////////////////
// Creating a ResourceManager in AWS
/////////////////////////////////////
import com.databricks.sql.CloudFilesAWSResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>) // optional, will use the region of the EC2 instances by default
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using AWS access key and secret key
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>)
.option("cloudFiles.awsAccessKey", <aws-access-key>)
.option("cloudFiles.awsSecretKey", <aws-secret-key>)
.option("cloudFiles.roleArn", <role-arn>)
.option("cloudFiles.roleExternalId", <role-external-id>)
.option("cloudFiles.roleSessionName", <role-session-name>)
.option("cloudFiles.stsEndpoint", <sts-endpoint>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in Azure
///////////////////////////////////////
import com.databricks.sql.CloudFilesAzureResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using an Azure service principal
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.connectionString", <connection-string>)
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("cloudFiles.tenantId", <tenant-id>)
.option("cloudFiles.clientId", <service-principal-client-id>)
.option("cloudFiles.clientSecret", <service-principal-client-secret>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in GCP
///////////////////////////////////////
import com.databricks.sql.CloudFilesGCPResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
/**
* Using a Google service account
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("cloudFiles.client", <client-id>)
.option("cloudFiles.clientEmail", <client-email>)
.option("cloudFiles.privateKey", <private-key>)
.option("cloudFiles.privateKeyId", <private-key-id>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
// Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
// List notification services created by <AL>
val df = manager.listNotificationServices()
// Tear down the notification services created for a specific stream ID.
// Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
使用 setUpNotificationServices(<resource-suffix>) 來建立具有名稱<prefix>-<resource-suffix>的佇列和訂用帳戶(前置詞取決於自動載入器檔案通知模式中使用的雲端資源摘要的記憶體系統。 如果有具有相同名稱的現有資源,Azure Databricks 會重複使用現有的資源,而不是建立新的資源。 此函式會傳回佇列標識碼,您可以使用檔案通知選項cloudFiles標識碼傳遞至來源。 這可讓 cloudFiles 來源用戶擁有的許可權比建立資源的使用者少。
"path"只有在呼叫 newManager時,才提供 選項setUpNotificationServices;或 listNotificationServices不需要tearDownNotificationServices此選項。 這與您在執行串流查詢時所使用的相同 path 。
下列矩陣指出每種記憶體類型的 Databricks Runtime 支援哪些 API 方法:
| 雲端存放裝置 | 設定 API | 列出 API | 卸除 API |
|---|---|---|---|
| Amazon S3 | 所有版本 | 所有版本 | 所有版本 |
| ADLS Gen2 | 所有版本 | 所有版本 | 所有版本 |
| GCS | Databricks Runtime 9.1 和更新版本 | Databricks Runtime 9.1 和更新版本 | Databricks Runtime 9.1 和更新版本 |
| Azure Blob 儲存體 | 所有版本 | 所有版本 | 所有版本 |
| ADLS Gen1 | 不支援 | 不支援 | 不支援 |
針對常見錯誤進行疑難解答
本節說明搭配檔案通知模式使用自動載入器時常見的錯誤,以及如何加以解決。
無法建立事件方格訂用帳戶
如果您在第一次執行自動載入器時看到下列錯誤訊息,事件方格不會註冊為 Azure 訂用帳戶中的資源提供者。
java.lang.RuntimeException: Failed to create event grid subscription.
若要將事件方格註冊為資源提供者,請執行下列動作:
- 在 Azure 入口網站中,進入您的訂閱。
- 按兩下 [設定] 區段底下的 [資源提供者 ]。
- 註冊
Microsoft.EventGrid提供者。
執行事件方格訂用帳戶作業所需的授權
如果您在首次執行 Auto Loader 時看到下列錯誤訊息,請確認已將 參與者 角色指派給事件網格和儲存帳戶的服務主體。
403 Forbidden ... does not have authorization to perform action 'Microsoft.EventGrid/eventSubscriptions/[read|write]' over scope ...
事件網格客戶端略過代理伺服器
在 Databricks Runtime 15.2 及以上版本中,自動載入器默认为事件網格連線使用系統屬性的代理設定。 在 Databricks Runtime 13.3 LTS、14.3 LTS 和 15.0 到 15.2 中,您可以通過設定 Spark Config 屬性 spark.databricks.cloudFiles.eventGridClient.useSystemProperties true,手動配置 Event Grid 連接以使用代理伺服器。 請參閱在 Azure Databricks上設定 Spark 組態屬性