改善 RAG 資料管線品質
本文討論如何從實作資料管線變更的實際觀點,實驗各種資料管線選擇。
資料管線的主要元件
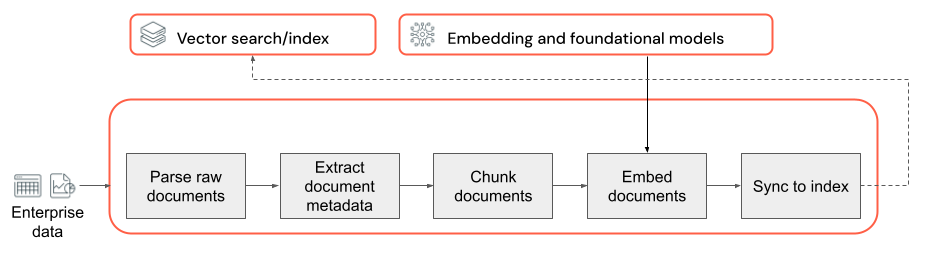
任何具有非結構化資料之 RAG 應用程式的基礎都是資料管線。 這個管線負責以 RAG 應用可有效利用的格式準備非結構化資料。 雖然此資料管線可能複雜費解,但一開始建置 RAG 應用程式時需要考慮的重要元件如下:
- 主體組合:根據特定使用案例,選取正確的資料來源和內容。
- 剖析:使用適當的剖析技術,從原始資料擷取相關資訊。
- 區塊處理:將剖析的資料細分為較小的可管理區塊,提高擷取效率。
- 內嵌:將區塊化文字資料轉換成可擷取其語意意義的數值向量表示法。
主體組合
若沒有正確的資料主體,RAG 應用程式就無法擷取解答使用者查詢所需的資訊。 正確的資料完全取決於應用程式的特定需求和目標,因此請務必花時間了解可用資料的細微差別 (如需相關指導,請參閱需求收集章節)。
例如,建置客戶支援 Bot 時,不妨考慮包含:
- 知識庫文件
- 常見問題集 (FAQ)
- 產品手冊和規格
- 疑難排解指南
任何專案從一開始就請連絡領域專家和利害關係人協助,找出能改善資料主體品質與涵蓋範圍的內容,並且精心規劃。 他們能就使用者可能提交的查詢類型提供深入解析,並協助優先處理要納入的最重要資訊。
剖析
識別出RAG應用程式的數據源後,下一個步驟是從原始數據擷取所需的資訊。 這個流程稱為剖析,過程將非結構化資料轉換成 RAG 應用程式可有效利用的格式。
您使用的特定剖析技術和工具,取決於處理的資料類型。 例如:
- 文字文件 (PDF、Word 檔案):非結構化和 PyPDF2 等現成的程式庫可處理各種檔案格式,並提供自訂剖析流程的選項。
- HTML 文件:HTML 剖析程式庫,例如 BeautifulSoup 可用於從網頁擷取相關內容。 透過它們,您可以流覽 HTML 結構、選取特定元素,以及擷取所需的文字或屬性。
- 影像和掃描的文件:若要從影像擷取文字,通常必須有光學字元辨識 (OCR) 技術。 熱門 OCR 程式庫包括 Tesseract、Amazon Textract、Azure AI 視覺 OCR 和 Google Cloud Vision API。
剖析資料的最佳做法
剖析資料時,請考慮下列最佳做法:
- 數據清除: 預先處理擷取的文字,以移除任何無關或嘈雜的資訊,例如頁首、頁尾或特殊字元。 請了解,務必減少 RAG 鏈結必須處理的不必要資訊量或格式錯誤資訊量。
- 處理錯誤和例外:實作錯誤處理和記錄機制,識別及解決剖析流程遇到的任何問題。 這樣一來便可快速找出問題並修正。 這個方法通常指向來源資料品質的上游問題。
- 自訂剖析邏輯:視資料的結構和格式而定,您可能必須自訂剖析邏輯,才能擷取最相關的資訊。 雖然自訂可能事前比較費工,但卻是不可或缺的環節,因為通常可防範大量的下游品質問題。
- 評估剖析品質: 手動檢閱輸出範例,即可定期評估已剖析資料的品質。 這個作法協助您在剖析流程識別有改善空間的任何問題或領域。
區塊化
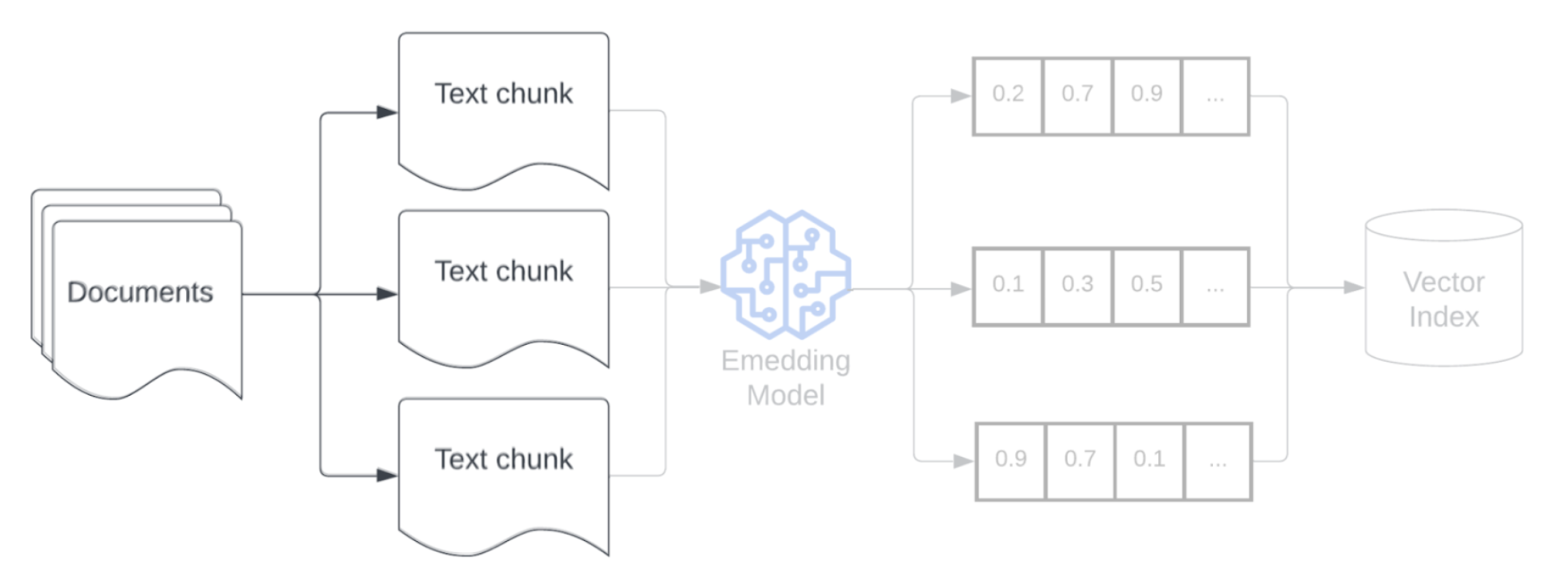
將未經處理資料剖析為較結構化的格式之後,下一個步驟是將該資料分解為更小的可管理單位,稱為區塊。 將大型文件分割成較小的語意濃縮區塊,可確保擷取的資料符合 LLM 的內容,同時儘量減少納入分散注意力或無關的資訊。 對區塊化所做的選擇,將直接影響為 LLM 提供哪些擷取的資料,因此是 RAG 應用程式最佳化的第一層。
將資料區塊化時,請考慮下列因素:
- 區塊化策略:您用來將原始文字分割成區塊的方法。 這個方法可能會用到基本技術,例如依句子、段落或特定字元/權杖計數分割,以及更進階的特定文件分割策略。
- 區塊大小:較小的區塊或許專注於特定詳細資料,但是會損失部分周圍資訊。 較大的區塊或許擷取更多內容,但也可能包含不相關的資訊。
- 區塊重疊:為了確保將資料分割成區塊時不會損失重要資訊,請考慮讓相鄰區塊部分重疊。 重疊可確保跨區塊實現連續性和內容保留。
- 語意連貫性:儘可能建立語意連貫的區塊,亦即區塊包含相關資訊,可單獨作為有意義的文字單位。 為此,您可以考慮原始資料的結構,例如段落、區段或主題邊界。
- 中繼資料:在每個區塊包含相關的中繼資料,例如來源文件名稱、章節標題或產品名稱,有助於改善擷取流程。 區塊中這項額外資訊有助於擷取查詢與區塊之間的比對。
資料區塊化策略
尋找正確的區塊化方法,過程反覆,而且依內容有所不同。 不存在一體適用的方法;最佳區塊大小和方法取決於處理之資料的特定使用案例與本質。 簡而言之,區塊化策略可分為下列幾類:
- 固定大小的區塊化:將文字分割成預先決定大小的區塊,例如固定的字元數或權杖數 (例如 LangChain CharacterTextSplitter)。 雖然以任意數目的字元/令牌分割是快速且容易設定的,但通常不會產生一致的語意連貫區塊。
- 以段落為基礎的區塊化:使用文字的自然段落邊界定義區塊。 這個方法有助於保留區塊的語意連貫性,因為段落通常包含相關資訊 (例如 LangChain RecursiveCharacterTextSplitter)。
- 特定格式的區塊化:Markdown 或 HTML 等格式固有的結構,可用於定義區塊邊界 (例如 Markdown 標頭)。 LangChain 的 MarkdownHeaderTextSplitter 或 HTML 標頭/區段型分隔器等工具可用於這項用途。
- 語意區塊化:套用主題模型化等技術,可識別字裡行間語意連貫的區段。 這些方法會分析每份文件的內容或結構,根據主題轉變判斷最適當的區塊邊界。 語意區塊化雖然比基本方法複雜,但有助於建立與文字自然語意分割更一致的區塊 (如需這類範例,請參閱 LangChain SemanticChunker)。
範例:大小固定的區塊化
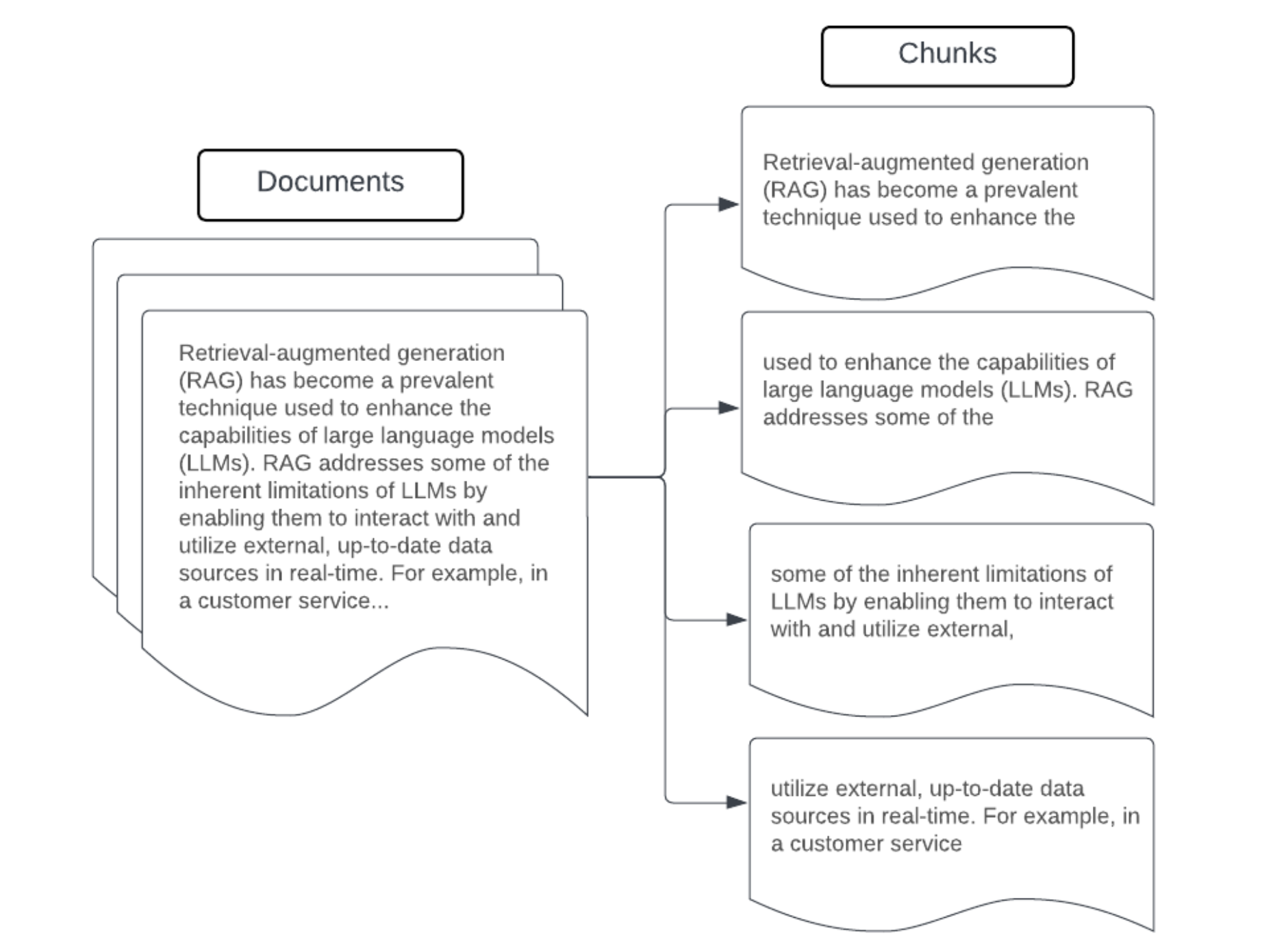
使用 LangChain 的 RecursiveCharacterTextSplitter 搭配 chunk_size=100 和 chunk_overlap=20 之大小固定區塊化範例。
ChunkViz 提供一種互動方式,以可視化不同區塊大小和區塊重疊值如何通過 Langchain 的字元分割器影響生成的區塊。
內嵌模型
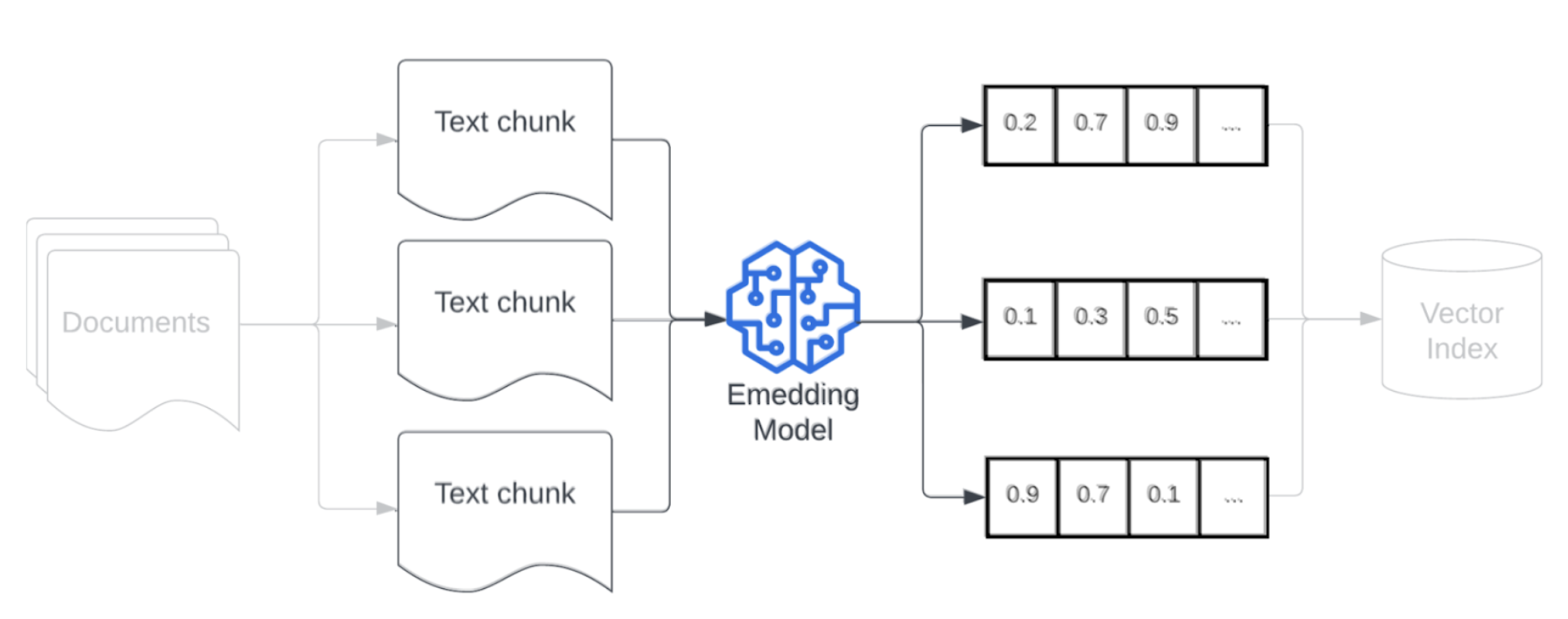
將資料區塊化之後,下一個步驟是使用內嵌模型,將文字區塊轉換為向量表示法。 內嵌模型用於將每個文字區塊轉換為可擷取其語意意義的向量表示法。 內嵌以密集向量的方式表示區塊,可根據擷取查詢的語意相似性,快速準確擷取最相關的區塊。 查詢時,過程使用用於在資料管線內嵌區塊的相同內嵌模型,轉換擷取查詢。
選取內嵌模型時,請考慮下列因素:
- 模型選擇:每個內嵌模型都有細微差別,而且可用的基準可能無法擷取資料的特定特性。 實驗不同的現成內嵌模型,甚至是標準排行榜排名可能較低的模型,例如 MTEB。 幾個可考慮的例子包括:
- 最大令牌: 請注意所選內嵌模型的最大令牌限制。 如果您傳遞超過此限制的區塊,這些區塊將會遭到截斷,可能會遺失重要資訊。 例如,bge-large-en-v1.5 的令牌限制上限為 512。
- 模型大小:較大的內嵌模型通常效能較優異,但需要更多運算資源。 根據特定使用案例和可用資源,在效能與效率之間取得平衡。
- 微調:如果 RAG 應用程式處理特定領域語言 (例如內部公司縮略字或術語),請考慮微調特定領域資料的內嵌模型。 這有助於模型更妥善擷取特定領域的細微差別和術語,而且通常可提升擷取效能。