RAG 數據管線描述和處理步驟
在本文中,您將瞭解如何準備非結構化數據以用於RAG應用程式。 非結構化數據是指沒有特定結構或組織的數據,例如可能包含文字和影像的 PDF 檔,或音訊或視訊等多媒體內容。
非結構化數據缺少預先定義的數據模型或架構,因此無法單獨根據結構和元數據進行查詢。 因此,非結構化數據需要技術,才能從原始文字、影像、音訊或其他內容中瞭解和擷取語意意義。
在數據準備期間,RAG 應用程式數據管線會擷取原始的非結構化數據,並將它轉換成可根據使用者查詢的相關性進行查詢的離散區塊。 數據前置處理的主要步驟如下所述。 每個步驟都有各種可微調的旋鈕-如需對這些旋鈕進行更深入的討論,請參閱 改善RAG應用程式品質。
準備非結構化數據以進行擷取
在本節的其餘部分,我們會說明準備非結構化數據以使用語意搜尋進行擷取的程式。 語意搜尋瞭解使用者查詢的內容意義和意圖,以提供更相關的搜尋結果。
語意搜尋是透過非結構化數據實作 RAG 應用程式的擷取元件時,可以採用的數種方法之一。 這些文件涵蓋擷取旋鈕一節中的替代擷取策略。
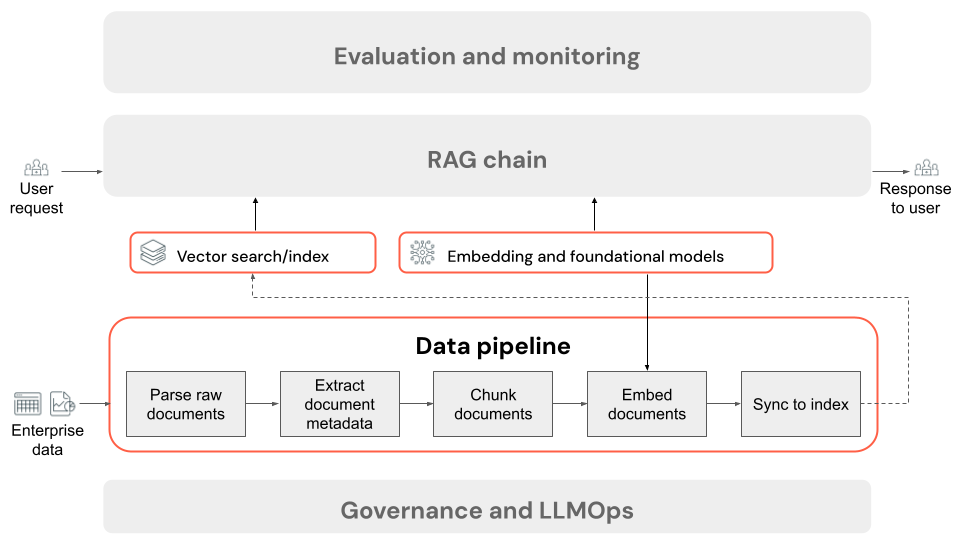
RAG 應用程式數據管線的步驟
以下是使用非結構化資料之 RAG 應用程式中資料管線的一般步驟:
- 剖析原始檔:初始步驟牽涉到將原始數據轉換成可使用的格式。 這可以包括從 PDF 集合擷取文字、表格和影像,或採用光學字元辨識(OCR) 技術從影像中擷取文字。
- 擷取檔元數據(選擇性):在某些情況下,擷取和使用檔元數據,例如文件標題、頁碼、URL 或其他資訊,可協助擷取步驟更精確地查詢正確的數據。
- 區塊檔:為了確保剖析的檔可以放入內嵌模型和 LLM 的內容視窗,我們會將剖析的檔分成較小的離散區塊。 擷取這些焦點區塊,而不是整個檔,可提供 LLM 更多目標內容,以便從中產生其回應。
- 內嵌區塊:在使用語意搜尋的RAG應用程式中,稱為內嵌模型的特殊語言模型類型會將上一個步驟中的每個區塊轉換成數值向量或數字清單,以封裝每個內容片段的意義。 關鍵是,這些向量代表文字的語意意義,而不只是表面層級關鍵詞。 這可根據意義而非常值文字相符項目進行搜尋。
- 向量資料庫中的索引區塊:最後一個步驟是將區塊的向量表示以及區塊的文字載入向量資料庫。 向量資料庫是特製化類型的資料庫,其設計目的是要有效率地儲存和搜尋向量數據,例如內嵌。 為了維持大量區塊的效能,向量資料庫通常會包含使用各種演算法來組織和對應向量內嵌的向量索引,以優化搜尋效率的方式進行組織及對應。 在查詢時,使用者的要求會內嵌至向量,而資料庫會利用向量索引來尋找最類似的區塊向量,並傳回對應的原始文字區塊。
計算相似度的程式可能相當昂貴。 向量索引,例如 Databricks 向量搜尋,藉由提供有效率地組織和瀏覽內嵌的機制,通常透過複雜的近似值方法來加速此程式。 這可讓您快速排名最相關的結果,而不需個別比較每個內嵌與用戶的查詢。
數據管線中的每個步驟都牽涉到會影響RAG應用程式品質的工程決策。 例如,在步驟 3 中選擇正確的區塊大小可確保 LLM 接收特定但內容化的資訊,而在步驟 4 中選取適當的內嵌模型時,會決定擷取期間傳回的區塊正確性。
此數據準備程式稱為離線數據準備,因為它會在系統回答查詢之前發生,與使用者提交查詢時所觸發的在線步驟不同。