Databricks Asset Bundles 延伸項目功能
適用於 Visual Studio Code 的 Databricks 擴充功能提供 Visual Studio Code 中的其他功能,可讓您輕鬆地定義、部署和執行 Databricks 資產套件組合,以將 CI/CD 最佳做法套用至 Azure Databricks 作業、Delta Live Tables 管線和 MLOps Stack。 請參閱什麼是 Databricks Asset Bundles?。
若要安裝適用於 Visual Studio Code 的 Databricks 擴充功能,請參閱 安裝適用於 Visual Studio Code 的 Databricks 擴充功能。
專案中的 Databricks 資產配套支援
適用於 Visual Studio Code 的 Databricks 延伸模組會為您的 Databricks 資產套件組合專案新增下列功能:
- 透過 Visual Studio Code UI 輕鬆驗證和設定 Databricks 資產組合,包括 AuthType 設定檔選取專案。 請參閲 適用於 Visual Studio Code 的 Databricks 延伸項目的驗證設定。
- Databricks 擴充面板中的目標選取器,可快速切換套件組合目標環境。 請參閱 變更目標部署工作區。
- 延伸模組面板中的 [ 覆寫作業叢集 ] 選項,以啟用簡單的叢集覆寫。
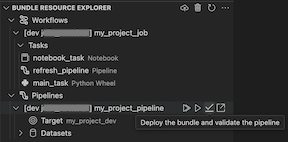
- [ 套件組合資源 總管] 檢視可讓您使用 Visual Studio Code UI 瀏覽套件組合資源、使用單鍵將本機 Databricks 資產組合的資源部署到遠端 Azure Databricks 工作區,然後直接從 Visual Studio Code 移至工作區中已部署的資源。 請參閱 套件組合資源總管。
- 套件 組合變數檢視,可讓您使用 Visual Studio Code UI 來瀏覽和編輯套件組合變數。 請參閱 套件組合變數檢視。
套件組合資源總管
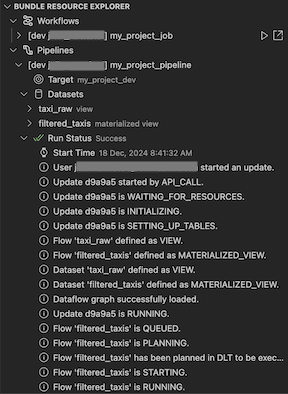
Visual Studio Code Databricks 延伸模組中的 套件資源總管 檢視會使用專案的套件組態中的作業和管線定義來顯示資源,包括管線數據集及其架構。 它也可讓您部署和執行資源、驗證和執行管線的部分更新、檢視管線執行事件和診斷,以及瀏覽至遠端 Azure Databricks 工作區中的資源。 如需套件組合組態資源的相關信息,請參閱 資源。
例如,假設有簡單的作業定義:
resources:
jobs:
my-notebook-job:
name: "My Notebook Job"
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
延伸模組中的 [ 套件組合資源 總管] 檢視會顯示筆記本作業資源:
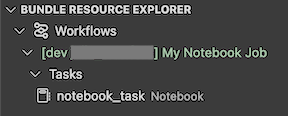
若要部署套件組合,請按兩下雲端 (部署套件組合) 圖示。
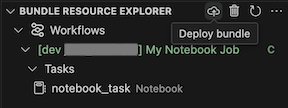
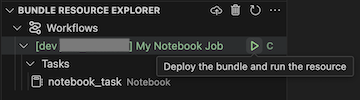
若要執行作業,請在 [套件組合資源總 管] 檢視中,選取作業的名稱,在此範例中為 [我的筆記本作業 ]。 接下來,按兩下播放 [部署套件組合並執行資源] 圖示。
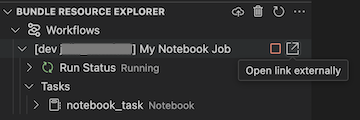
若要檢視執行中的作業,請在 [套件組合資源 總管] 檢視中,展開作業名稱,按兩下 [執行狀態],然後按兩下連結 (外部開啟連結) 圖示。
要對管線進行驗證和部分更新,您可以先選取該管線,然後點擊 [部署套件組合並驗證管線] 的圖示。 執行過程中的事件會顯示出來,並且可以在 Visual Studio Code PROBLEMS 面板中診斷任何失敗。
套件組合變數檢視
Visual Studio Code Databricks 延伸模組中的 [ 套件組合變數檢視] 檢視] 檢視 會顯示套件組合組態中定義的任何自定義變數和相關聯的設定。 您也可以使用 套件組合變數檢視直接定義變數。 這些值會覆寫套件組合組態檔中設定的值。 如需自定義變數的相關信息,請參閱 自定義變數。
例如,延伸模組中的 [ 組合變數檢視 ] 檢視會顯示下列內容:

針對此套件組合元件中定義的變數 my_custom_var :
variables:
my_custom_var:
description: "Max workers"
default: "4"
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}