使用管線設定來管理數據品質
使用預期來套用品質條件約束,以在數據流經 ETL 管線時驗證數據。 預期值提供對數據品質指標的更深入見解,並允許您在偵測到無效記錄時更新失敗或刪除記錄。
本文提供預期的概觀,包括語法範例和行為選項。 如需更進階的使用案例和建議的最佳做法,請參閱 預期建議和進階模式。
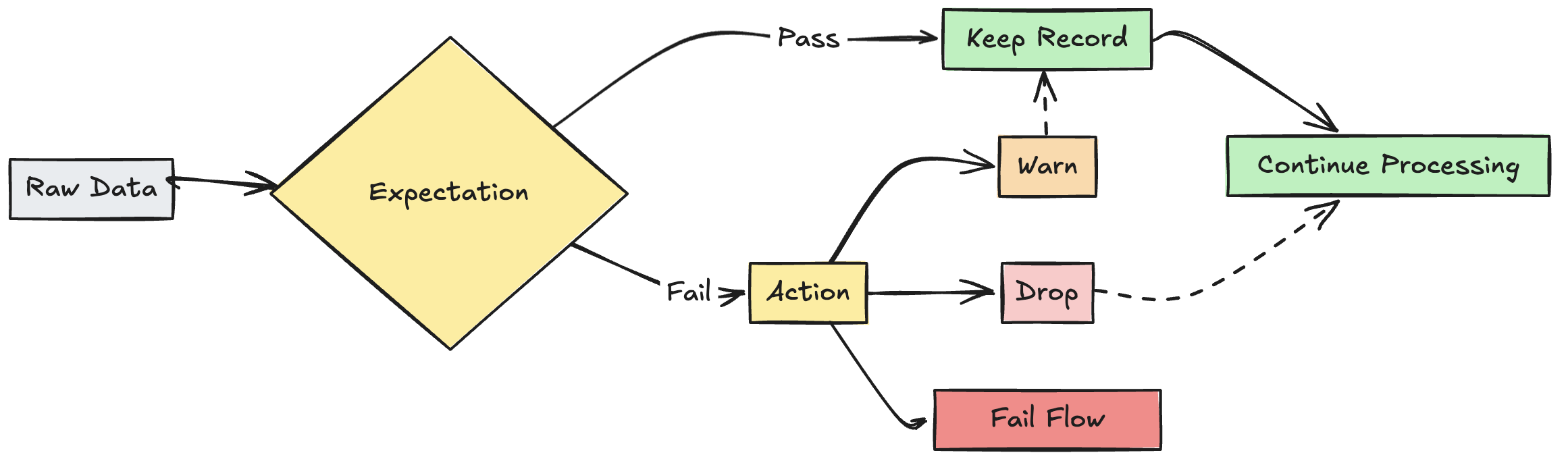
什麼是期望?
在管線具體化檢視、串流資料表或檢視建立語句中,期望是選擇性子句,這些語句會在傳遞查詢的每個記錄上套用資料品質檢查。 預期會使用標準 SQL 布爾語句來指定條件約束。 您可以合併單個數據集的多個預期,並在管線中所有數據集宣告中設定預期。
下列各節介紹期望的三個元件,並提供語法範例。
預期名稱
每個期望都必須有一個名稱,此名稱會作為標識符來追蹤及監視預期。 選擇用來傳達所驗證計量的名稱。 下列範例會定義預期 valid_customer_age,以確認年齡在 0 到 120 歲之間:
重要
指定數據集的預期名稱必須是唯一的。 您可以在管線中的多個資料集之間重複使用預期。 請參閱 可攜式且可重複使用的期望。
蟒
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
需要評估的約束條件
條件約束子句是一個 SQL 條件語句,每個記錄都必須評估為 true 或 false。 條件約束包含正在驗證之專案的實際邏輯。 當記錄失敗此條件時,就會觸發預期。
限制條件必須使用有效的 SQL 語法,且不能包含下列內容:
- 自定義 Python 函式
- 外部服務呼叫
- 參考其他數據表的子查詢
以下是可新增至數據集建立語句的條件約束範例:
蟒
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0)
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
針對無效記錄的處理措施
您必須指定動作,以判斷記錄失敗驗證檢查時會發生什麼情況。 下表描述可用的動作:
| 行動 | SQL 語法 | Python 語法 | 結果 |
|---|---|---|---|
| 警告 (預設值) | EXPECT |
dlt.expect |
無效的記錄會寫入目標。 有效和無效的記錄計數會與其他數據集計量一起記錄。 |
| 卸除 | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
將數據寫入目標之前,會移除無效的記錄。 已丟失的記錄數量會與其他數據集的指標一起記錄。 |
| 失敗 | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
無效的記錄可防止更新成功。 重新處理之前需要手動介入。 此預期會導致單一流程失敗,而且不會造成管線中的其他流程失敗。 |
您也可以執行進階邏輯來隔離保護無效的記錄,而不會導致失敗或刪除資料。 請參閱 隔離無效記錄。
期望追蹤指標
您可以從管線 UI 查看 warn 或 drop 動作的追蹤計量。 由於 fail 導致偵測到無效記錄時更新失敗,因此不會記錄計量。
若要檢視預期計量,請完成下列步驟:
- 在側邊欄中點擊 DLT。
- 點擊您的管線 名稱。
- 單擊一個已定義預期的資料集。
- 選取右側側邊欄中的 [數據品質] 索引標籤。
您可以藉由查詢 DLT 事件記錄檔來檢視數據品質計量。 請參閱 從事件記錄檔查詢數據品質。
保留無效的記錄
保留無效的記錄是預期的預設行為。 當您想要保留違反預期的記錄,但收集通過或不符合限制的記錄數量的計量時,請使用 expect 運算符。 違反預期記錄的記錄會連同有效的記錄一起新增至目標數據集:
蟒
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
卸除無效的記錄
使用 expect_or_drop 運算符來防止進一步處理無效的記錄。 違反預期的記錄會從目標數據集卸除:
蟒
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
在無效記錄上失敗
當無效的記錄無法接受時,請使用 expect_or_fail 運算符,在記錄驗證失敗時立即停止執行。 如果作業是資料表更新,系統將原子性地回復交易。
蟒
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
重要
如果您在管線中定義了多個平行流程,單一流程失敗並不會造成其他流程失敗。
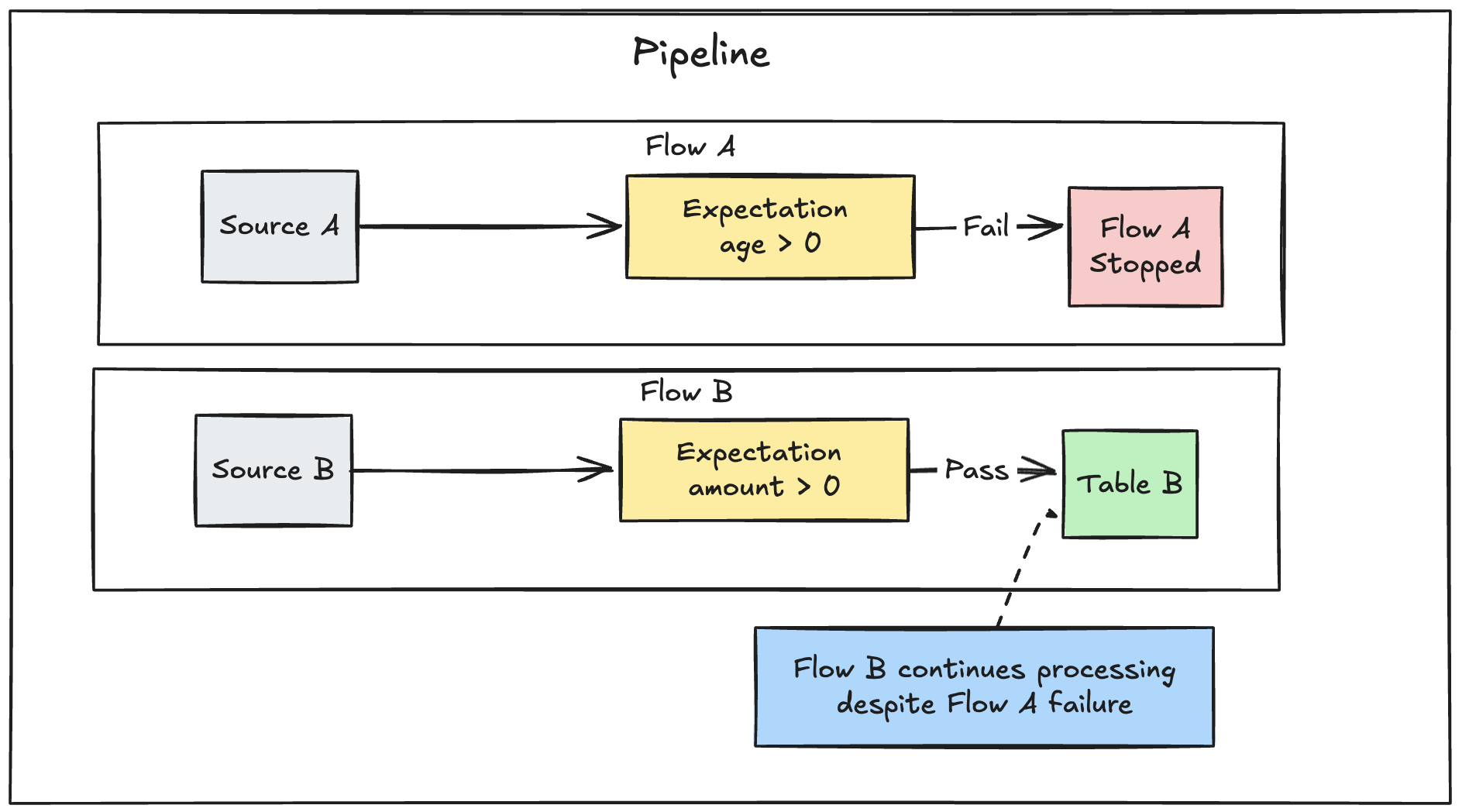
針對預期失敗的更新進行疑難解答
當管線因為預期違反而失敗時,您必須修正管線的程式碼,以在重新執行管線之前正確處理無效的資料。
設為使管線失敗的預期設定會修改您的轉換過程中的 Spark 查詢計劃,以追蹤偵測和報告違規所需的資訊。 您可以使用這項資訊來識別許多查詢導致違規的輸入記錄。 以下是預期範例:
Expectation Violated:
{
"flowName": "sensor-pipeline",
"verboseInfo": {
"expectationsViolated": [
"temperature_in_valid_range"
],
"inputData": {
"id": "TEMP_001",
"temperature": -500,
"timestamp_ms": "1710498600"
},
"outputRecord": {
"sensor_id": "TEMP_001",
"temperature": -500,
"change_time": "2024-03-15 10:30:00"
},
"missingInputData": false
}
}
多元期望管理
注意
雖然 SQL 和 Python 都支援單一數據集內的多個預期,但只有 Python 可讓您將多個個別的期望群組在一起,並指定集體動作。
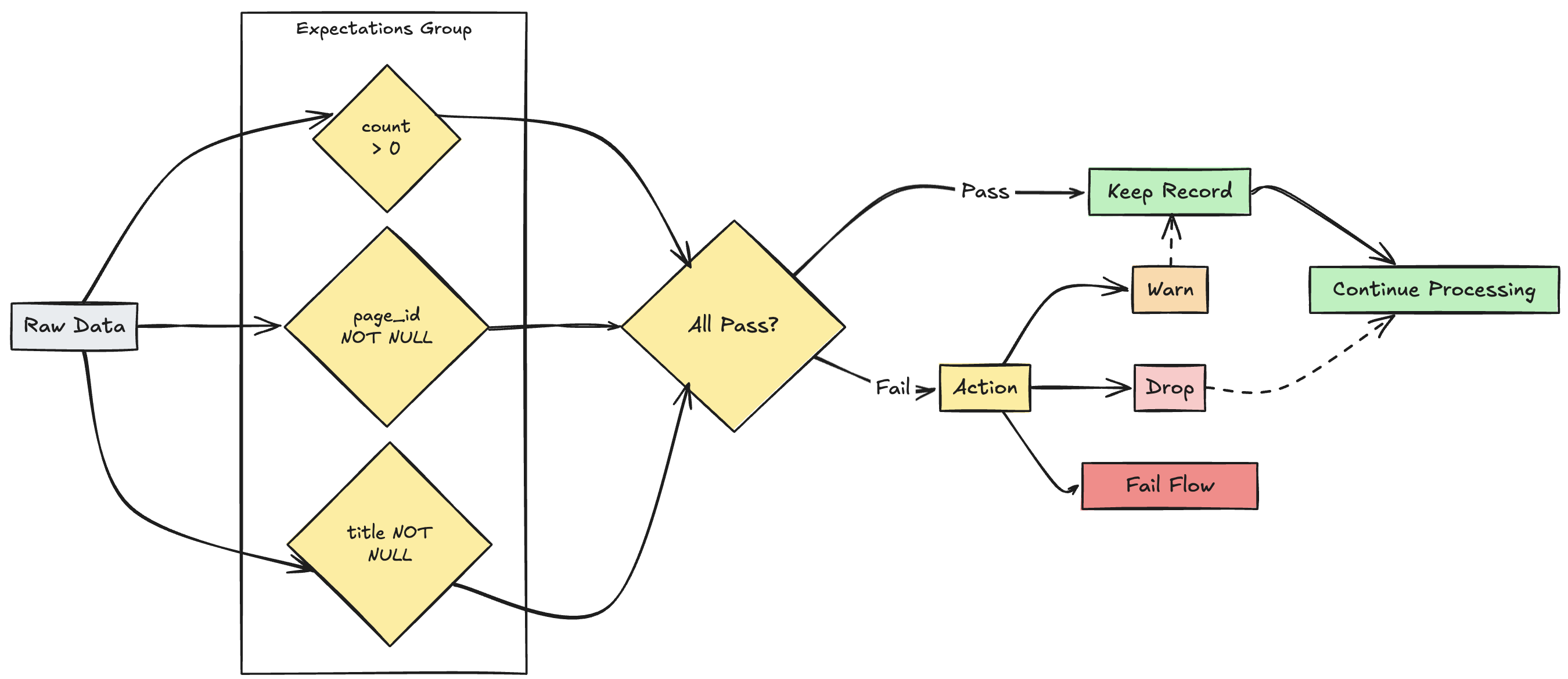
您可以使用函式 expect_all、expect_all_or_drop和 expect_all_or_fail,將多個期望群組在一起,並指定集體動作。
這些裝飾專案接受 Python 字典做為自變數,其中索引鍵是預期名稱,而值是預期條件約束。 您可以在管線中的多個資料集中重複使用相同的預期集。 下列顯示每個 expect_all Python 運算子的範例:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset