在服務端點的模型上設定 AI 閘道
在本文中,您將了解如何在服務端點的模型上設定 Mosaic AI 閘道。
需求
- 外部模型支援的區域中的 Databricks 工作區, 或 已配置的輸送量支援區域。
- 提供端點的模型。
- 若要建立外部模型的端點,請完成步驟 1 和 2 建立服務端點的外部模型。
- 若要建立已佈建輸送量的端點,請參閱 布建的輸送量基礎模型 API。
使用UI設定 AI 閘道
在端點建立頁面的 [AI 閘道] 區段中,您可以個別設定 AI 閘道功能。 請參閱 支援的功能,以了解哪些功能可用於外部模型服務端點和已配置輸送量端點。
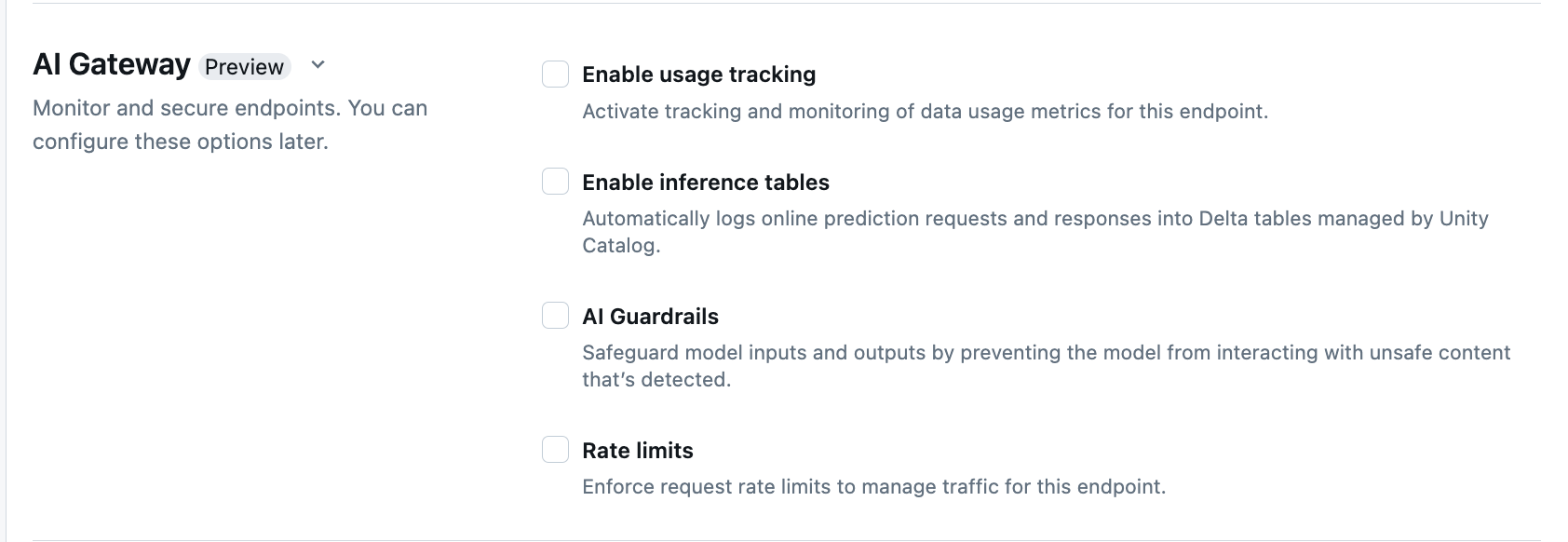
下表摘要說明如何使用服務UI在端點建立期間設定 AI 閘道。 如果您想要以程式設計方式執行這項操作,請參閱 Notebook 範例。
| 功能 | 如何啟用 | 詳細資料 |
|---|---|---|
| 使用狀況追蹤 | 選取 [啟用使用量追蹤] 以啟用數據使用量的追蹤和監控。 |
|
| 負載記錄 | 選取 啟用推論資料表,自動將端點的請求和回應記錄到由 Unity 目錄管理的 Delta 資料表中。 |
|
| AI 護欄 | 請參閱在 UI 中設定 AI 護欄。 |
|
| 速率限制 | 選取 速率限制,以強制執行每位使用者和每個端點的請求速率限制,來管理端點的流量。 |
|
| 流量切分 | 在 [服務實體] 區段中,指定您想將多少百分比的流量 路由至特定模型。 若要以程式設計方式在端點上設定流量分割,請參閱 將多個外部模型服務至端點。 |
|
| 後援 | 選取 啟用後援 在 AI 網關區段中,以便將您的要求作為後援傳送至端點上的其他服務模型。 |
|
下方圖示顯示了一個例子,
- 有三個服務實體在模型服務端點上被提供。
- 要求原本會路由傳送至 服務實體 3。
- 如果請求返回 200 回應,則表示請求在 Served 實體 3 上成功,且請求及其回應將被記錄到端點的使用追蹤和負載記錄表中。
- 如果請求在 服務實體 3上返回 429 或 5xx 錯誤,則請求將回退至端點的下一個服務實體,服務實體 1。
- 如果要求 服務實體 1傳回 429 或 5xx 錯誤,則要求會回復至端點上的下一個服務實體,服務實體 2。
- 如果請求在 服務實體 2傳回 429 或 5xx 錯誤,則請求會失敗,因為這是後備實體數目上限。 失敗的要求和回應錯誤會記錄到使用量追蹤和承載記錄數據表。

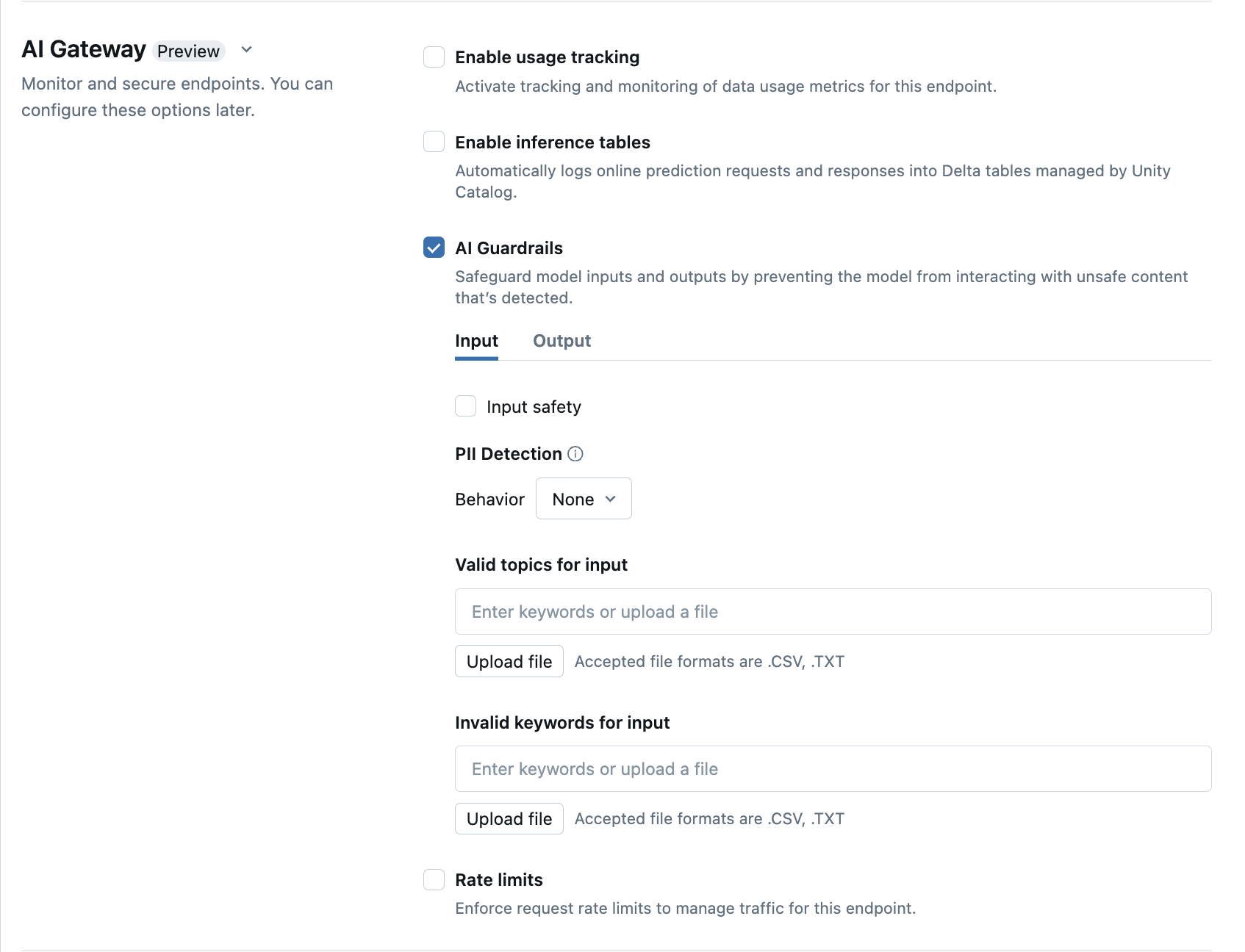
在UI中設定 AI 護欄
下表顯示如何配置 支援的護欄。
| 護欄 | 如何啟用 | 詳細資料 |
|---|---|---|
| 安全性 | 選取 [[安全],以啟用保護措施,以防止您的模型與不安全和有害的內容互動。 | |
| 個人識別資訊 (PII) 偵測 | 選取 PII 偵測 來偵測 PII 數據,例如名稱、位址、信用卡號碼。 | |
| 有效主題 | 您可以直接在此欄位中輸入主題。 如果您有多個項目,請務必在每個主題之後按 Enter 鍵。 或者,您可以上傳 .csv 或 .txt 檔案。 |
最多可以指定 50 個有效主題。 每個主題不能超過 100 個字元 |
| 無效的關鍵字 | 您可以直接在此欄位中輸入主題。 如果您有多個項目,請務必在每個主題之後按 Enter 鍵。 或者,您可以上傳 .csv 或 .txt 檔案。 |
最多可以指定 50 個無效的關鍵字。 每個關鍵字不能超過 100 個字元。 |
使用量追蹤數據表架構
下列各節摘要說明 system.serving.served_entities 和 system.serving.endpoint_usage 系統數據表的使用追蹤數據表架構。
system.serving.served_entities 使用量追蹤數據表架構
system.serving.served_entities 使用量追蹤系統數據表具有下列架構:
| 欄位名稱 | 描述 | 類型 |
|---|---|---|
served_entity_id |
服務實體的唯一 ID。 | 字串 |
account_id |
Delta Sharing 的客戶帳戶 ID。 | 字串 |
workspace_id |
服務端點的客戶工作區 ID。 | 字串 |
created_by |
創建者的 ID。 | 字串 |
endpoint_name |
服務端點的名稱。 | 字串 |
endpoint_id |
服務端點的唯一 ID。 | 字串 |
served_entity_name |
提供服務的實體名稱。 | 字串 |
entity_type |
服務對象的類型。 可以是 FEATURE_SPEC、EXTERNAL_MODEL、FOUNDATION_MODEL 或 CUSTOM_MODEL |
字串 |
entity_name |
實體的基礎名稱。 與使用者所提供名稱的 served_entity_name 不同。 例如,entity_name 是 Unity 目錄模型的名稱。 |
字串 |
entity_version |
提供服務對象的版本。 | 字串 |
endpoint_config_version |
端點組態的版本。 | INT |
task |
工作類型。 可以是 llm/v1/chat、llm/v1/completions 或 llm/v1/embeddings。 |
字串 |
external_model_config |
外部模型組態設定 例如,{Provider: OpenAI} |
結構 |
foundation_model_config |
基礎模型的組態。 例如{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
結構 |
custom_model_config |
自訂模型的組態。 例如{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
結構 |
feature_spec_config |
功能規格的配置。 例如,{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
結構體 |
change_time |
所服務實體的變更時間戳記。 | 時間戳記 |
endpoint_delete_time |
實體刪除的時間戳記。 端點是存放接受服務之執行個體的容器。 端點刪除之後,接受服務之執行個體也會一併刪除。 | 時間戳記 |
system.serving.endpoint_usage 使用量追蹤數據表架構
system.serving.endpoint_usage 使用量追蹤系統數據表具有下列架構:
| 欄位名稱 | 描述 | 類型 |
|---|---|---|
account_id |
客戶帳戶 ID。 | 字串 |
workspace_id |
服務端點的客戶工作區 ID。 | 字串 |
client_request_id |
使用者提供的要求識別碼,可以在模型服務的請求本體中指定。 | 字串 |
databricks_request_id |
Azure Databricks 產生的請求識別碼被附加到所有模型服務的請求中。 | 字串 |
requester |
使用者或服務主體的 ID,其權限會用於服務端點的調用要求。 | 字串 |
status_code |
從模型傳回的 HTTP 狀態碼。 | 整數 |
request_time |
收到請求的時間戳記。 | 時間戳記 |
input_token_count |
輸入的符記計數。 | LONG |
output_token_count |
輸出的記號計數。 | LONG |
input_character_count |
輸入字串或提示的字元計數。 | LONG |
output_character_count |
回應輸出字串的字元計數。 | LONG |
usage_context |
用戶提供的映射中包含發起對端點呼叫的最終用戶或客戶應用程式的識別碼。 請參閱 ,以 usage_context進一步定義使用方式。 |
地圖 |
request_streaming |
請求是否在串流模式中。 | BOOLEAN |
served_entity_id |
用來與 system.serving.served_entities 維度資料表聯結的唯一 ID,以查閱端點及所服務實體的相關資訊。 |
字串 |
使用 usage_context 進一步定義使用方式
當您查詢已啟用使用追蹤的外部模型時,可以提供 usage_context 類型的 Map[String, String] 參數。 使用情境對應會出現在 usage_context 欄的使用追蹤表中。 地圖 usage_context 大小不能超過 10 KiB。
帳戶管理員可以根據使用內容匯總不同的數據列,以取得深入解析,並可將此資訊與承載記錄數據表中的資訊聯結。 例如,您可以新增 end_user_to_charge 至 usage_context,以便追蹤終端使用者的成本屬性。
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
更新端點上的 AI 閘道功能
您可以在那些之前已啟用 AI 閘道功能的模型服務端點,以及那些未啟用的端點上更新 AI 閘道功能。 AI 閘道設定的更新需要約 20-40 秒才能套用,不過速率限制更新最多可能需要 60 秒的時間。
下列示範如何使用服務 UI,在模型服務端點上更新 AI 閘道功能。
在端點頁面的 [閘道] 區段中,您可以看到已啟用哪些功能。 若要更新這些功能,請按一下 編輯 AI 閘道。

筆記本範例
下列筆記本示範如何以程序設計方式啟用及使用 Databricks 馬賽克 AI 閘道功能來管理及控管來自提供者的模型。 如需 REST API 詳細數據,請參閱 PUT /api/2.0/serving-endpoints/{name}/ai-gateway。
啟用 Databricks Mosaic AI 閘道功能筆記本
其他資源
- 馬賽克 AI 閘道簡介。
- 使用已啟用 AI 閘道的推斷資料表監視服務模型。