用於監視和偵錯模型的推斷數據表
重要
這項功能處於公開預覽狀態。
重要
本文說明適用於 自定義模型推斷數據表的主題。 針對外部模型或已配置的吞吐量工作負載,請使用 已啟用 AI 閘道的推論資料表。
本文說明監視服務模型的推斷數據表。 下圖顯示具有推斷數據表的一般工作流程。 推論表格會自動擷取模型提供的端點的連入請求和回傳響應,並將其記錄為 Unity Catalog Delta 表。 您可以使用此資料表中的數據來監視、偵錯及改善 ML 模型。
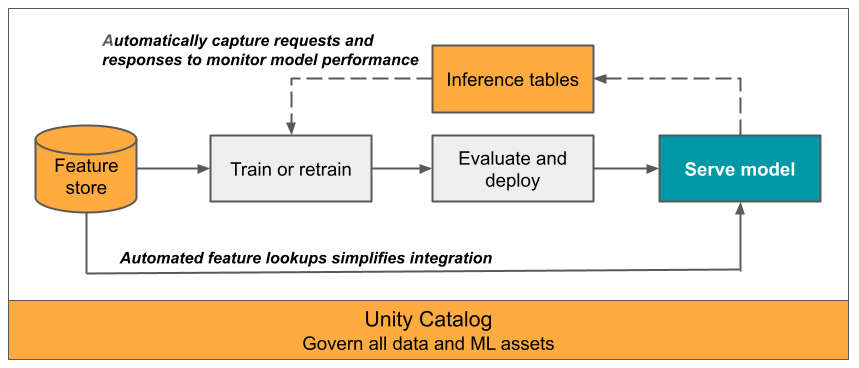
什麼是推斷數據表?
監視實際執行工作流程中的模型效能,是 AI 和 ML 模型生命週期的重要層面。 推斷數據表會持續記錄來自馬賽克 AI 模型服務端點的要求輸入和回應(預測),並將其儲存到 Unity 目錄中的 Delta 數據表,藉以簡化模型的監視和診斷。 然後,您可以使用 Databricks 平臺的所有功能,例如 Databricks SQL 查詢、筆記本和 Lakehouse 監視來監視、偵錯及優化您的模型。
您可以在任何現有或新建的模型服務端點上啟用推斷表,然後該端點的請求會自動記錄到 UC 中的數據表中。
推斷資料表的一些常見應用程式如下:
- 監視資料和模型品質。 您可以使用 Lakehouse Monitoring 持續觀察模型效能及資料漂移。 Lakehouse Monitoring 會自動產生您可以與項目關係人共用的資料和模型品質儀表板。 此外,您可以啟用警示,以便知道何時需要根據輸入資料的變動重新訓練模型,或因模型效能的下降而進行調整。
- 偵錯實際執行問題。 推斷數據表記錄數據,例如 HTTP 狀態代碼、模型運行時間,以及要求和回應 JSON 程式代碼。 您可以將這個效能數據用於偵錯。 您也可以使用推斷數據表中的歷程記錄數據來比較歷程記錄要求的模型效能。
- 建立訓練語料庫。 藉由聯結推論表與標籤的真實值,您可以建立訓練資料集,進而用來重新訓練或微調並改善您的模型。 使用 Databricks 任務,您可以設定連續的反饋迴圈,並自動重新訓練。
需求
- 您的工作區必須已啟用 Unity Catalog。
- 端點和修飾元的建立者都必須擁有端點的 Can Manage 權限。 請參閱存取控制清單。
- 端點的建立者和修改者都必須在 Unity 目錄中具有下列許可權:
-
USE CATALOG指定目錄的權限。 -
USE SCHEMA指定架構的許可權。 -
CREATE TABLE架構中的許可權。
-
啟用和停用推斷數據表
本節說明如何使用 Databricks UI 來啟用或停用推斷數據表。 您也可以使用 API;如需指示,請參閱 使用 API 在模型服務端點上啟用推論表格。
推斷數據表的擁有者是建立端點的使用者。 數據表上的所有訪問控制清單 (ACL) 都遵循標準 Unity 目錄許可權,而且可由數據表擁有者修改。
警告
如果您執行下列任何動作,推斷數據表可能會損毀:
- 變更數據表架構。
- 變更數據表名稱。
- 刪除資料表。
- 失去 Unity Catalog 目錄或配置架構的許可權。
在此情況下,端點狀態 auto_capture_config 會顯示承載數據表的 FAILED 狀態。 如果發生這種情況,您必須建立新的端點,才能繼續使用推斷數據表。
若要在端點建立期間啟用推斷數據表,請使用下列步驟:
按一下 Databricks Mosaic AI UI 中的 [服務]。
按一下建立服務端點。
選擇 [開啟推斷資料表]。
在下拉功能表中,選取您想要放置資料表的所需目錄和架構。
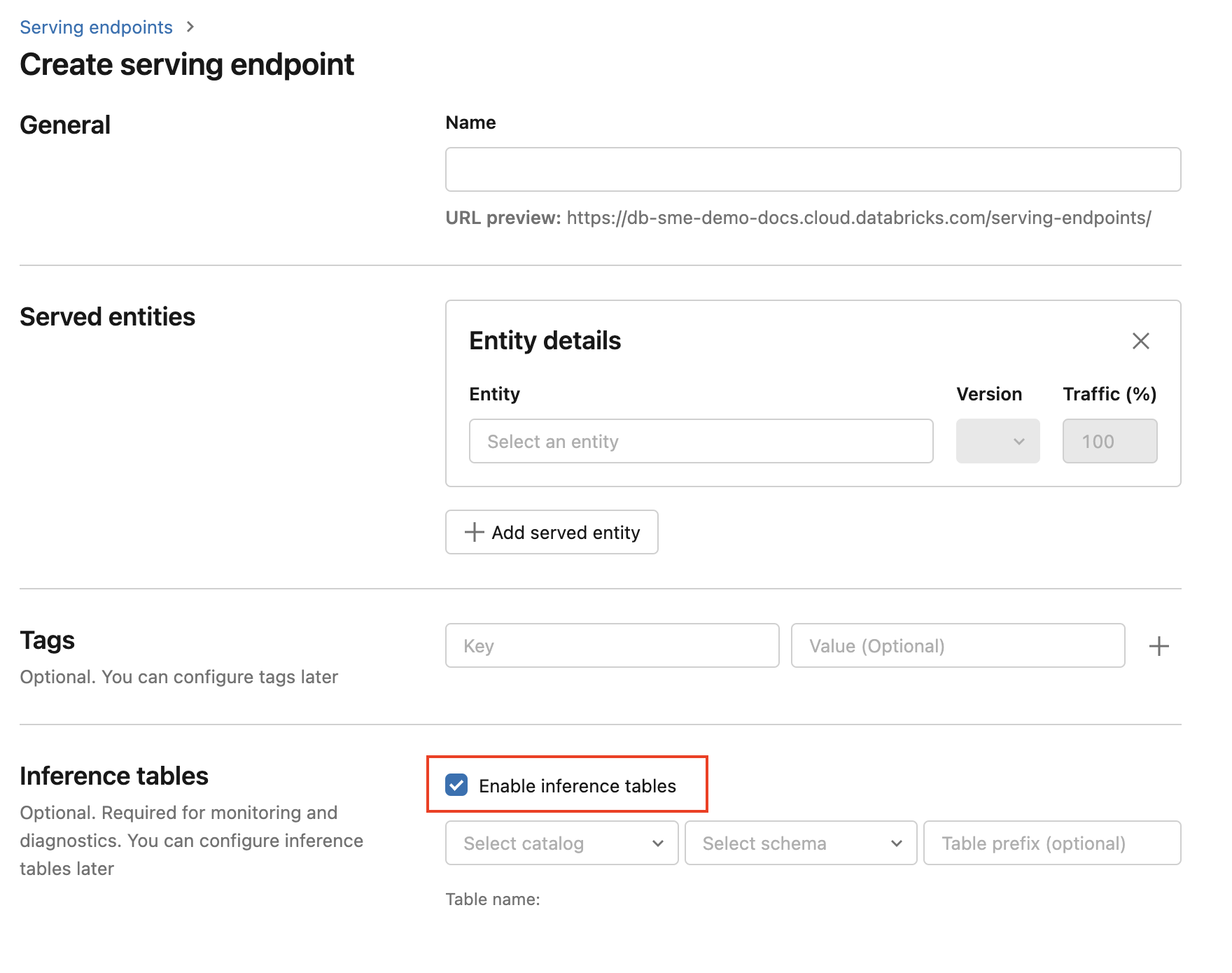 的目錄和架構
的目錄和架構預設資料表名稱
<catalog>.<schema>.<endpoint-name>_payload。 如有需要,您可以輸入自定義數據表前置詞。按一下建立服務端點。
您也可以在現有的端點上啟用推斷數據表。 若要編輯現有的端點組態,請執行下列動作:
- 瀏覽至端點頁面。
- 按下[編輯組態]。
- 遵循先前的指示,從步驟 3 開始。
- 完成時,請點擊 更新服務端點。
請遵循下列指示來停用推斷資料表:
- 瀏覽至端點頁面。
- 按下[編輯組態]。
- 按 [啟用推斷資料表] 以移除 的勾選。
- 當您對端點規格感到滿意後,請按一下 更新。
工作流程:使用推斷數據表監視模型效能
若要使用推斷數據表監視模型效能,請遵循下列步驟:
- 您可以在端點建立期間啟用 推斷數據表,或在之後更新端點設定以啟用它。
- 根據端點的架構,排定一個工作流程,以處理推斷表中的 JSON 負載。
- (選擇性)將解壓縮的請求和回應與真實標籤結合,來進行模型品質評估的計算。
- 透過生成的 Delta 資料表建立監控機制,並刷新指標。
入門筆記本會實作這個工作流程。
用於監控推理數據表的入門筆記本
下列筆記本會實作上述步驟,以拆解 Lakehouse 監控推斷表中的要求。 使用 Databricks 工作可按需或依重複性排程來執行工作筆記。
推斷數據表 Lakehouse 監視入門筆記本
提供 LLM 服務之端點的文字品質監控入門筆記本
下列筆記本會從推斷表中提取請求,計算一組文字評估指標(例如可讀性和毒性),並啟用對這些指標的監控。 使用 Databricks 工作來按需或依週期性排程執行筆記本。
LLM 推斷數據表 Lakehouse 監視入門筆記本
在推斷數據表中查詢和分析結果
當你的模型服務準備就緒後,所有對模型的請求及其回應都會自動記錄在推斷紀錄表中。 您可以在 UI 中檢視數據表、從 DBSQL 或筆記本查詢數據表,或使用 REST API 查詢數據表。
若要在 UI 中檢視資料表: 在端點頁面上,點擊推論資料表的名稱,以在目錄總管中開啟該資料表。

若要從 DBSQL 或 Databricks 筆記本查詢數據表: 您可以執行類似下列的程式代碼來查詢推斷數據表。
SELECT * FROM <catalog>.<schema>.<payload_table>
如果您使用 UI 啟用推斷數據表,payload_table 是您建立端點時指派的數據表名稱。 如果您使用 API 啟用推斷數據表,則會在 payload_table 回應的 state 區段中回報 auto_capture_config。 如需範例,請參閱 使用 API在提供端點的模型上啟用推斷數據表。
效能注意事項
在呼叫端點之後,您可以在發送評分請求的一小時內,看到呼叫已記錄至推斷資料表。 此外,Azure Databricks 保證至少會傳遞一次記錄,因此有可能 (雖然可能性不高) 傳送重複的記錄。
Unity 目錄推斷數據表架構
記錄至推斷數據表的每個要求和響應都會寫入具有下列架構的 Delta 資料表:
注意
如果您使用一批輸入來呼叫端點,整個批次將記錄為一個資料列。
| 欄位名稱 | 描述 | 類型 |
|---|---|---|
databricks_request_id |
Azure Databricks 產生的請求識別碼附加至所有模型服務請求。 | 字串 |
client_request_id |
選擇性由客戶端產生的請求識別符,可以在模型服務請求主體中指定。 如需詳細資訊,請參閱指定功能client_request_id。 |
字串 |
date |
收到模型服務要求的 UTC 日期。 | 日期 |
timestamp_ms |
收到模型服務請求時的時間戳記(以紀元毫秒為單位)。 | 長時間 |
status_code |
從模型傳回的 HTTP 狀態碼。 | INT |
sampling_fraction |
在請求被降採樣時所使用的取樣比例。 此值介於 0 到 1 之間,其中 1 代表包含了 100% 的傳入請求。 | 雙倍 |
execution_time_ms |
模型執行推斷的執行時間 (以毫秒為單位)。 這不包括額外的網路等待時間,而且只代表模型產生預測所花費的時間。 | LONG |
request |
傳送至模型服務端點的原始要求 JSON 主體。 | 字串 |
response |
模型服務端點傳回的原始回覆 JSON 主體。 | 字串 |
request_metadata |
與請求相關的模型服務端點中繼資料圖。 這個圖包含端點名稱、模型名稱和端點使用的模型版本。 | MAP<STRING, STRING> |
指定 client_request_id
client_request_id 欄位是使用者可以在模型服務要求主體提供的選用值。 這可讓使用者提供自己的標識符,使其顯示在client_request_id 下的最終推斷數據表中的請求中,並可用於將您的請求與其他使用client_request_id的數據表聯結,例如真實標籤聯結。 若要指定 client_request_id,請在請求承載中作為頂層鍵包含它。 如果未指定,client_request_id則該值會在與要求對應的資料列中顯示為 null。
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
如果有其他與 client_request_id相關聯的表格標籤,那麼 client_request_id 之後可以用來進行真實標籤的聯結。
限制
- 不支援客戶自控金鑰。
- 針對裝載 基礎模型的端點,推理表格僅支援 已配置的吞吐量 作業負載。
- Azure 防火牆可能會導致建立 Unity Catalog Delta 表格失敗,因此預設情況下不支援。 若要啟用,請連絡 Databricks 客戶團隊。
- 啟用推斷數據表時,單一端點中所有服務模型的最大並行總數限製為128。 請連絡您的 Azure Databricks 帳戶小組,要求增加此限制。
- 如果推斷數據表包含超過 500K 個檔案,則不會記錄其他數據。 若要避免超過此限制,請刪除較舊的數據,在數據表上執行 OPTIMIZE 或設定保留期。 若要檢查資料表中的檔案數目,請執行
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>。 - 推論表日誌傳遞目前是盡力而為,但您可以預期在提出要求後的 1 小時內日誌會可供使用。 如需詳細資訊,請連絡 Databricks 客戶團隊。
如需一般模型服務端點限制,請參閱模型服務限制和區域。