SAP CDC 進階主題
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
了解 SAP CDC 連接器的進階主題,例如中繼資料驅動資料整合、偵錯等等。
參數化 SAP CDC 對應數據流
Azure Data Factory 和 Azure Synapse Analytics 中管線和對應資料流的主要優點之一是對中繼資料驅動資料整合的支援。 透過此功能,您可以設計單一 (或數個) 參數化管線,以用來處理數百或甚至數千個來源的整合。 SAP CDC 連接器是以此原則為考量所設計:所有相關屬性,無論是來源物件、執行模式、索引鍵資料行等等,都可以透過參數提供,以將 SAP CDC 對應資料流的彈性和重複使用潛力最大化。
若要了解參數化對應數據流的基本概念,請閱讀 參數化對應數據流。
在 Azure Data Factory 和 Azure Synapse Analytics 的範本資源庫中,您會找到範本管線和資料流程,其示範如何將 SAP CDC 資料擷取參數化。
參數化來源和執行模式
對應資料流不一定需要資料集成品:來源和接收轉換都會提供來源類型 (或接收類型) 內嵌。 在此情況下,ADF 資料集中定義的所有來源屬性都可以在來源轉換的 [來源選項] 中 (或接收轉換的 [設定] 索引標籤中) 設定。 使用內嵌數據集可提供更佳的概觀,並簡化對應數據流的參數化,因為完整來源(或接收)組態是在一個地方維護。
針對 SAP CDC,最常透過參數設定的屬性位於 [來源選項] 和 [最佳化] 索引標籤中。 當 [來源類型] 是 [內嵌] 時,可在 [來源選項] 中對下列屬性進行參數化。
-
ODP 內容:有效參數值是
- ABAP_CDS,適用於 ABAP Core Data Services Views
- BW,適用於 SAP BW 或 SAP BW/4HANA InfoProviders
- HANA,適用於 SAP HANA Information Views
- SAPI,適用於 SAP DataSources/Extractors
- 使用 SAP 架構轉換複寫伺服器 (SLT) 作為來源時,ODP 內容名稱為 SLT~<佇列別名>。 佇列別名值可以在 SLT Cockpit (SAP 交易 LTRC) 之 SLT 設定中的 [系統管理資料] 下找到。
- ODP_SELF 和 RANDOM 是用於技術驗證和測試的 ODP 內容,且通常並不相關。
- ODP 名稱:提供您想要從中擷取資料的 ODP 名稱。
-
執行模式:有效參數值是
- fullAndIncrementalLoad for Full 在第一次執行時,接著累加,這會起始異動數據擷取程式,並擷取目前的完整數據快照集。
- fullLoad,適用於 [每次執行時均已滿],其會在不起始異動資料擷取流程的情況下,擷取目前的完整資料快照集。
- incrementalLoad,適用於 [僅累加變更],其會在不擷取目前完整快照集的情況下,起始異動資料擷取流程。
- 索引鍵資料行:索引鍵資料行會以 (雙引號) 字串陣列的形式提供。 例如,使用 SAP 資料表 VBAP (銷售訂單項目) 時,索引鍵定義必須是 ["VBELN", "POSNR"] (在考量用戶端欄位的情況下,必須是 ["MANDT","VBELN","POSNR"])。
參數化來源數據分割的篩選條件
在 [最佳化] 索引標籤中,可以透過參數定義來源資料分割配置 (請參閱針對完整或初始載入的效能最佳化 (部分機器翻譯))。 通常會需要採取兩個步驟:
- 定義來源數據分割配置。
- 將資料分割參數內嵌至對應資料流。
定義來源數據分割配置
步驟 1 中的格式遵循 JSON 標準,其是由分割區定義陣列所組成,每個陣列本身都是個別篩選條件的陣列。 這些條件本身是 JSON 物件,其結構符合 SAP 中所謂的選取選項。 事實上,SAP ODP 架構所需的格式基本上與 SAP BW 中的動態 DTP 篩選相同:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
例如:
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
對應至 SQL WHERE 子句...WHERE "VBELN" = '0000001000',或
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
對應至 SQL WHERE 子句...WHERE "VBELN" BETWEEN '0000000000' AND '0000001000'
包含兩個分割區之資料分割配置的 JSON 定義,其外觀如下所示
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
其中第一個分割區包含會計年度 (GJAHR) 2011 年到 2015 年,而第二個分割區則包含會計年度 2016 年到 2020 年。
注意
Azure Data Factory 不會對這些條件執行任何檢查。 例如,使用者有責任確保分割區條件不會重疊。
分割區條件可能比較複雜,本身由多個基本篩選條件組成。 沒有明確定義如何在一個分割區內合併多個基本條件的邏輯結合。 SAP 中的隱含定義如下所示:
- 針對相同欄位名稱的包括條件 ("sign": "I") 是使用 OR 合併 (請想成將括弧置於所產生條件的周圍)
- 針對相同欄位名稱的排除條件 ("sign": "E") 是使用 OR 合併 (同樣地,請想成將括弧置於所產生條件的周圍)
- 步驟 1 和 2 的結果條件為
- 針對包括條件,與 AND 合併,
- 針對排除條件,與 AND NOT 合併。
例如,分割區條件
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
對應至 SQL WHERE 子句 ... WHERE (“BUKRS” = '1000' 或 “BUKRS” = '1010') 和 (“GJAHR” BETWEEN '2010' 和 '2025') 和 NOT (“GJAHR” = '2021' 或 “GJARH” = '2023')
注意
務必針對低值和高值使用 SAP 內部格式,包括前置零,並以 "YYYYMMDD" 格式的八個字元字串來表示行事曆日期。
將資料分割參數內嵌至對應資料流
若要將資料分割配置內嵌至對應資料流,請建立資料流程參數 (例如 "sapPartitions")。 若要將 JSON 格式傳遞至此參數,必須使用 @string() 函式將其轉換成字串:
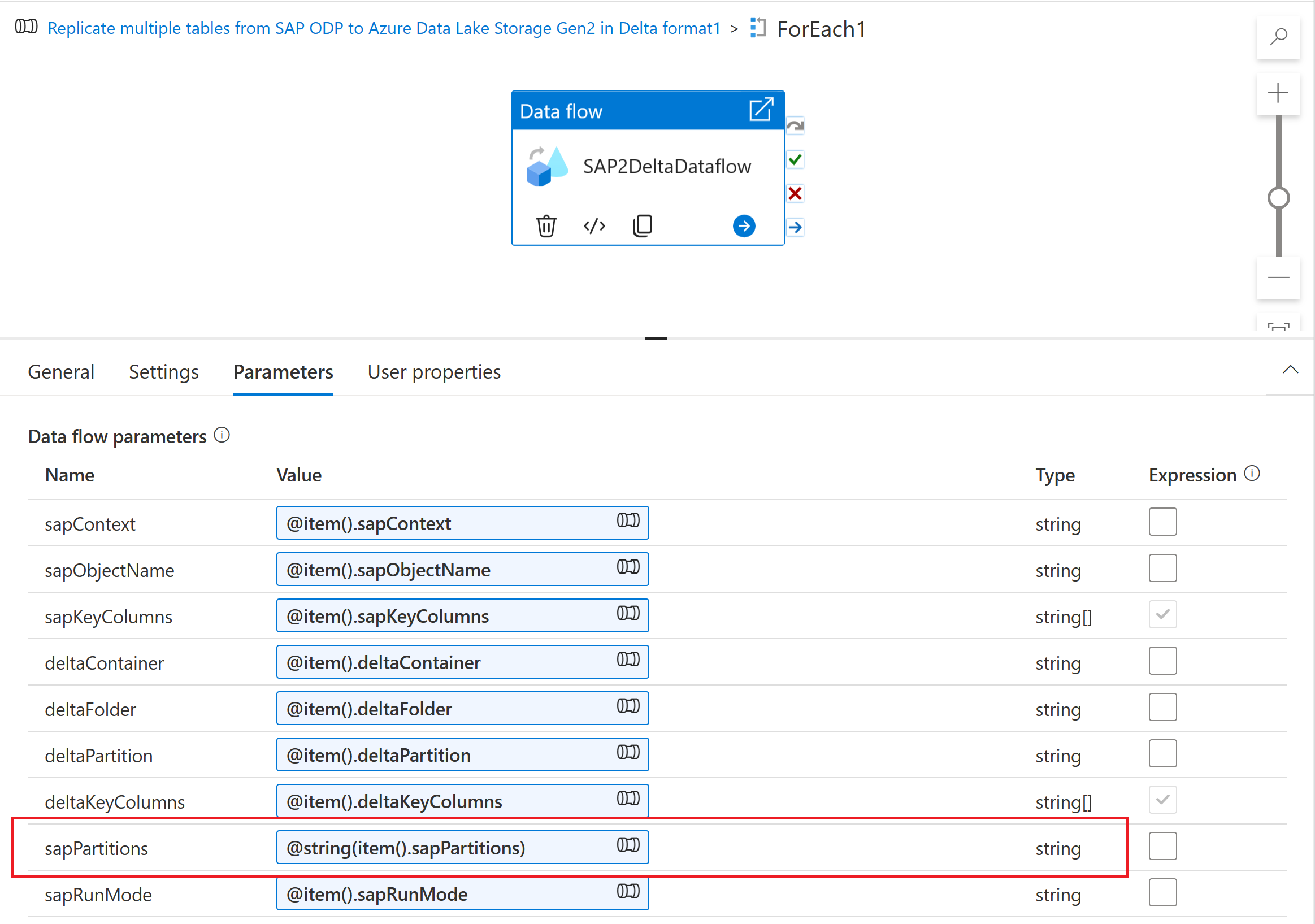
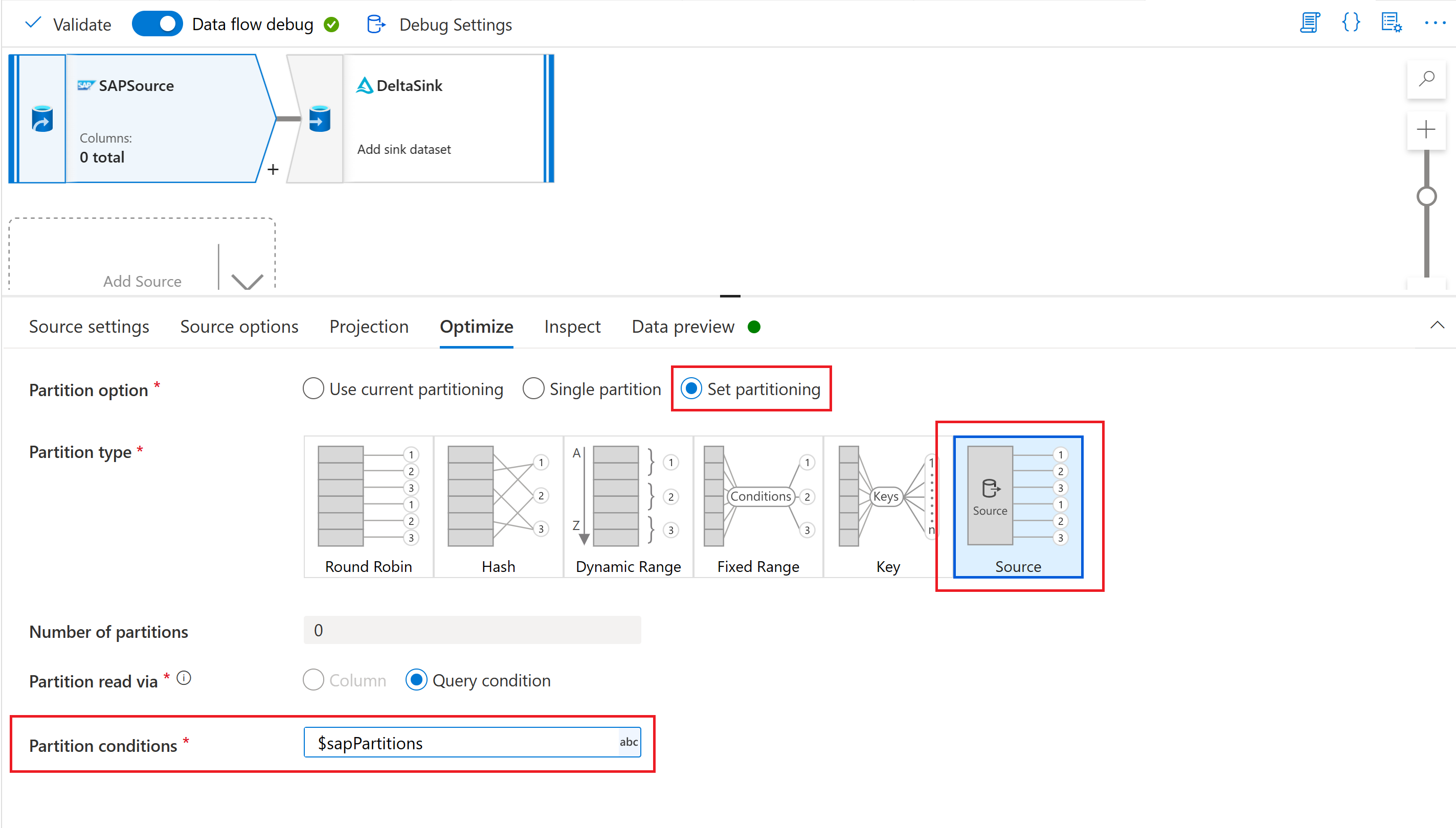
最後,在對應資料流中來源轉換的 [最佳化] 索引標籤中,針對 [分割區類型] 選取 [來源],然後在 [分割區條件] 屬性中輸入資料流程參數。
參數化檢查點金鑰
使用參數化的資料流程從多個 SAP CDC 來源擷取資料時,請務必在管線的資料流程活動中將檢查點索引鍵參數化。 Azure Data Factory 會使用檢查點索引鍵來管理異動資料擷取流程的狀態。 若要避免某個 CDC 處理序的狀態覆寫另一個處理序的狀態,請確定檢查點索引鍵值對於資料流程中使用的每個參數集而言都是唯一的。
注意
若要確保檢查點索引鍵的唯一性,最佳做法是將檢查點索引鍵值新增至您資料流程的參數集。
如需檢查點索引鍵的詳細資訊,請參閱使用 SAP CDC 連接器轉換資料 (部分機器翻譯)。
偵錯
Azure Data Factory 管線可以透過觸發執行或偵錯執行來執行。 這兩個選項之間的基本差異在於,偵錯執行會根據在使用者介面中模型化的目前的版本執行資料流程和管線,而觸發執行則會執行資料流程程和管線最後發佈的版本。
針對 SAP CDC,還有一個需要了解的層面:若要避免偵錯執行對現有異動資料擷取流程的影響,偵錯執行會使用與觸發執行不同的「訂閱者處理序」值 (請參閱監視 SAP CDC 資料流程)。 因此,其會在 SAP 系統內建立個別的訂用帳戶 (也就是異動資料擷取流程)。 此外,偵錯執行的「訂閱者處理序」值的存留期僅限於瀏覽器 UI 工作階段。
注意
若要在較長的時間內 (例如數天) 使用 SAP CDC 測試異動資料擷取流程的穩定性,必須發佈資料流程和管線,且必須執行觸發執行。